
告别‘人海战术’!基于EvalScope 的文生图模型智能评测新方案
01.前言
生成式模型在文本生成图片等领域的快速发展,为社区带来了日新月异的诸多文生图模型。如何对这些多样化的模型进行模型效果上的客观评估,已经成为技术选型与优化的关键。传统的模型评测方法高度依赖人工标注与主观判断,往往需投入大量人力进行样本筛选、质量评分及结果分析,不仅周期长、成本高,还可能因评审者主观偏好导致结果偏差,这在图片生成领域尤为突出。例如,在文本-图像对齐度评测中,人工评分过程会涉及到组织多人团队,对数千张生成图像逐条打分,耗时数天且难以保证评测的一致性。此外,人工评测对于许多复杂指标(如生成图像的真实感、文本图像匹配度)也难以进行准确量化,这也限制了模型迭代的精细化指导。
为了解决这些问题,EvalScope 作为一站式模型评测框架,提供了从自动化评测到智能分析的完整解决方案。其核心优势在于:
-自动化评测能力 :支持Stable Diffusion、Flux等主流文生图模型的批量推理与指标计算,使用MPS[1]、HPSv2.1Score [2]等模型,评估图像真实性、文本-图像对齐度等方面的指标,通过脚本化流程来替代传统人工标注。更多支持的指标和数据集请参考文档:https://evalscope.readthedocs.io/zh-cn/latest/user_guides/aigc/t2i.html
-智能报告与可视化 :借助大模型自动生成多维度分析报告,结合雷达图、柱状图等交互式可视化工具,直观展示模型在不同场景下的性能差异,辅助开发者快速定位模型瓶颈。
本文档以FLUX.1-dev [3]与HiDream-I1-Dev [4]两款模型为评测对象,在EvalMuse [5]评测数据集上,结合EvalScope的智能报告分析与可视化功能,为开发者提供从环境搭建到结果解读的完整实践指南。
02.安装依赖
首先,安装EvalScope (https://github.com/modelscope/evalscope) 模型评估框架:
pip install 'evalscope[app]' -U为了方便使用包括HiDream-I1-Dev在内的最新的文生图模型,还需要安装最新的diffusers库:
pip install git+https://github.com/huggingface/diffusers
03.运行评测任务
接下来我们将通过EvalMuse评测基准对文生图模型进行全面测试。EvalMuse是一个聚焦“文本-图像”对齐能力的细粒度评测基准,包含近200条多样化Prompt,覆盖物体、颜色、数量、动作等语义标签,并通过结构化标注实现多维度性能分析。您可以通过ModelScope社区的数据集页面查看prompt样例:EvalMuse数据集样例(https://modelscope.cn/datasets/AI-ModelScope/T2V-Eval-Prompts/summary)。
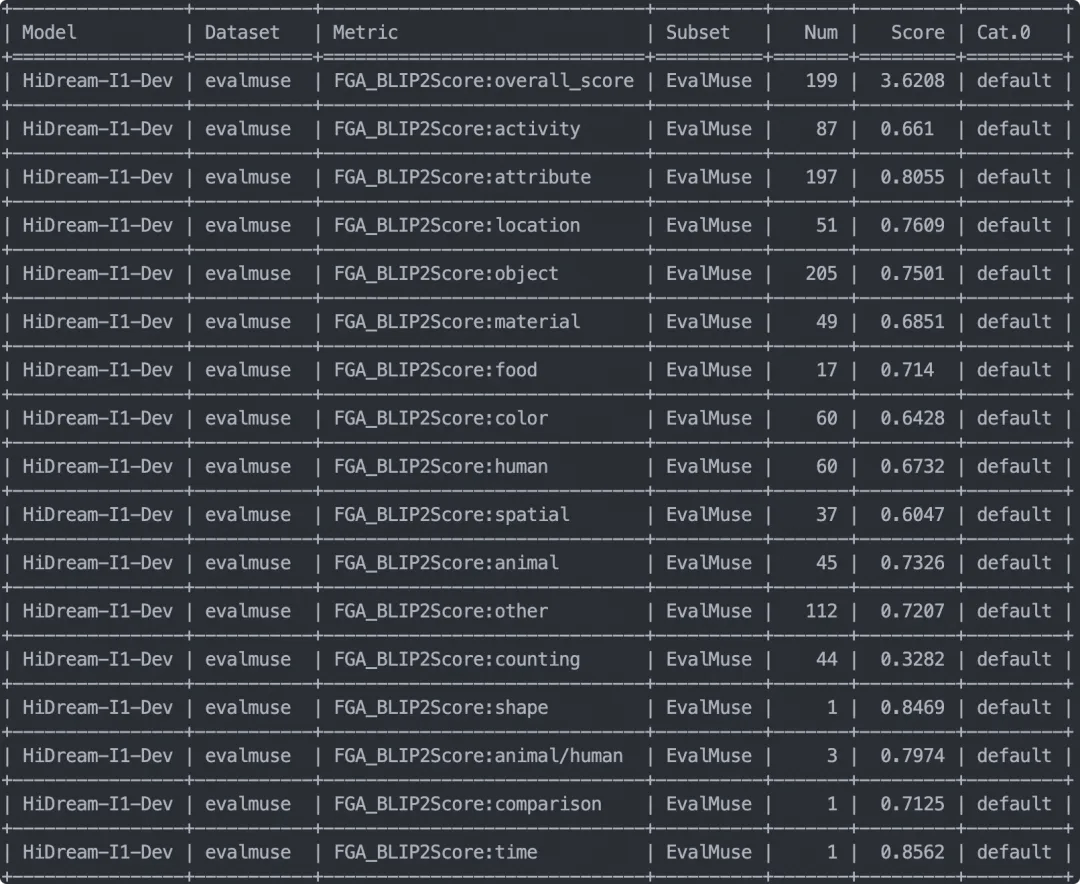
本次评测采用FGA-BLIP2作为自动化评分模型,替代传统人工标注,大幅提升效率。评分体系分为两部分:整体得分 (0-5分)用于评估生成图像的综合质量与文本匹配度,而子类别得分 (0-1分)则细化到物体、颜色、数量等维度,量化模型在具体语义标签上的表现。这一方法既避免了主观偏差,又确保结果可复现,尤其适用于大规模的模型对比测试。
运行以下代码即可启动全流程评测:系统将自动下载文生图模型、评测数据集及评分模型(首次运行需较长下载时间,请耐心等待),并在约60GB显存支持下完成推理。
注:评测结束后将调用Qwen3-235B-A22B大模型API生成智能报告,请提前通过ModelScope社区获取MODELSCOPE_SDK_TOKEN并配置至环境变量,获取地址:Token页面(https://modelscope.cn/my/myaccesstoken)。
from evalscope.constants import ModelTask
from evalscope import TaskConfig, run_task
from modelscope import AutoTokenizer, AutoModelForCausalLM
import torch
# HiDream模型需要llama-3.1-8b-instruct模型作为Encoder
tokenizer_4 = AutoTokenizer.from_pretrained("LLM-Research/Meta-Llama-3.1-8B-Instruct")
text_encoder_4 = AutoModelForCausalLM.from_pretrained(
"LLM-Research/Meta-Llama-3.1-8B-Instruct",
output_hidden_states=True,
output_attentions=True,
torch_dtype=torch.bfloat16,
)
# 配置评测参数
task_cfg = TaskConfig(
model='HiDream-ai/HiDream-I1-Dev', # 指定modelscope上的 model id
model_task=ModelTask.IMAGE_GENERATION, # 需要为 IMAGE_GENERATION
# 配置模型参数,具体支持的参数参考对应的Pipeline
model_args={
'pipeline_cls': 'HiDreamImagePipeline', # 指定使用 HiDreamImagePipeline
'torch_dtype': 'torch.bfloat16', # 使用 bfloat16 精度
'tokenizer_4': tokenizer_4, # 指定 tokenizer
'text_encoder_4': text_encoder_4, # 指定 text encoder
},
# 配置评测数据集
datasets=[
'evalmuse',
],
# 配置模型生成参数,具体支持的参数参考对应的Pipeline
generation_config={
'height': 1024, # 生成图片的高度
'width': 1024, # 生成图片的宽度
'num_inference_steps': 28, # 对于HiDream-Dev,建议生成步数为28
'guidance_scale': 0.0, # 对于HiDream-Dev,建议使用0.0
},
# 是否需要生成分析报告
analysis_report=True,
)
# 运行评测任务
run_task(task_cfg=task_cfg)评测结束输出评测指标如下,可以看到模型在不同维度的打分:
若想进一步测试FLUX.1-dev模型,可运行如下代码:
task_cfg = TaskConfig(
model='black-forest-labs/FLUX.1-dev', # model id
model_task=ModelTask.IMAGE_GENERATION, # must be IMAGE_GENERATION
model_args={
'pipeline_cls': 'FluxPipeline',
'torch_dtype': 'torch.float16',
},
datasets=[
'evalmuse',
],
generation_config={
'height': 1024,
'width': 1024,
'num_inference_steps': 50,
'guidance_scale': 3.5
},
analysis_report=True,
)
run_task(task_cfg=task_cfg)此外EvalScope框架还支持指定prompt和image path实现自定义的模型评测,不拘泥于本地运行文生图推理,具体使用参考modelscope的notebook,点击即可运行:https://modelscope.cn/notebook/share/ipynb/c997f3d5/t2i_eval.ipynb
04.评测结果可视化
运行如下命令可以启动可视化界面,直观展现模型评测效果以及分析模型的输出:
evalscope app评测结果中包括智能分析报告、模型得分分布、生成图片case等部分。从分析报告可以看出HiDream-I1-Dev 模型的图像描述与理解能力表现较好,但在处理复杂语义、空间关系和数量推理等方面仍需提升。
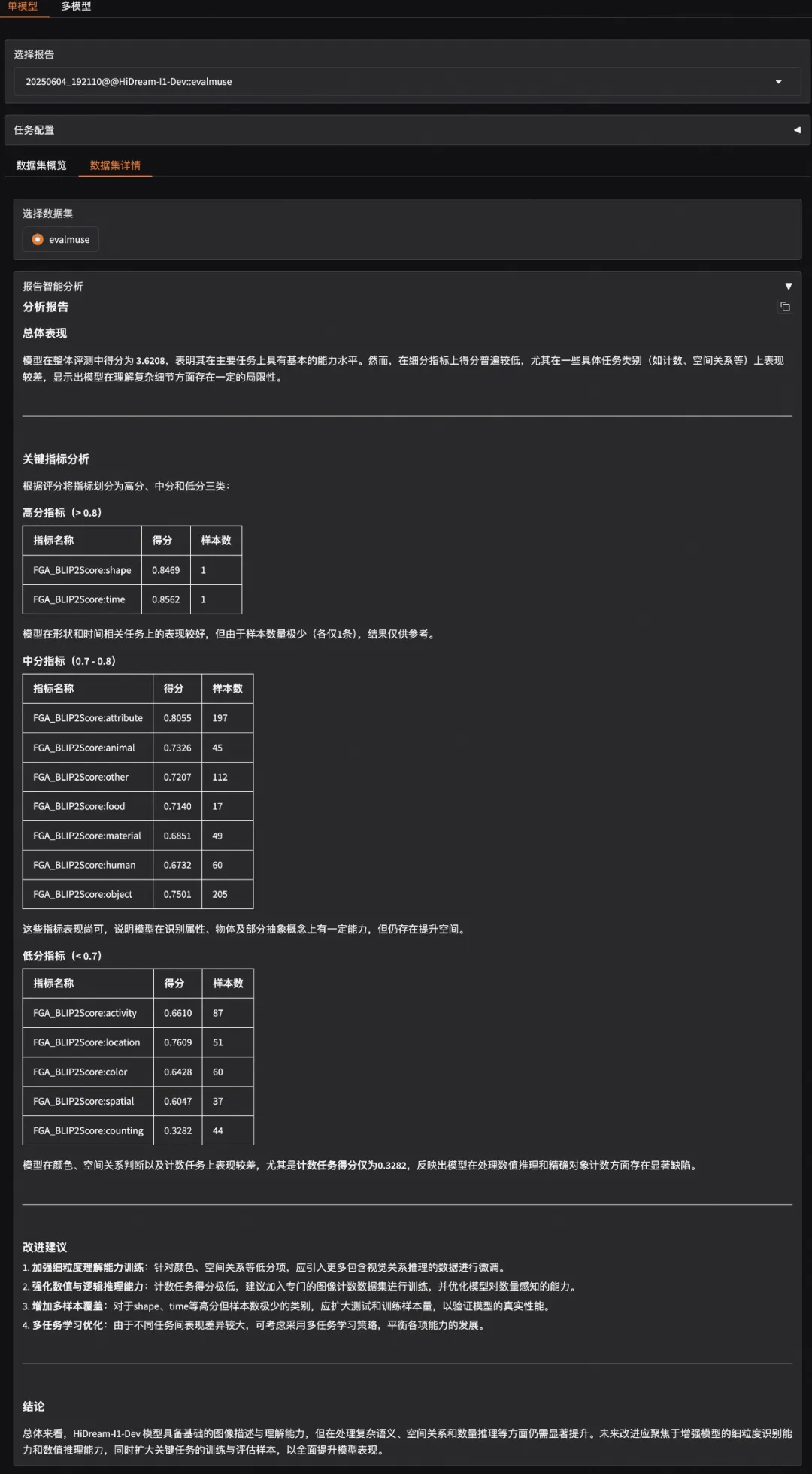
智能报告分析
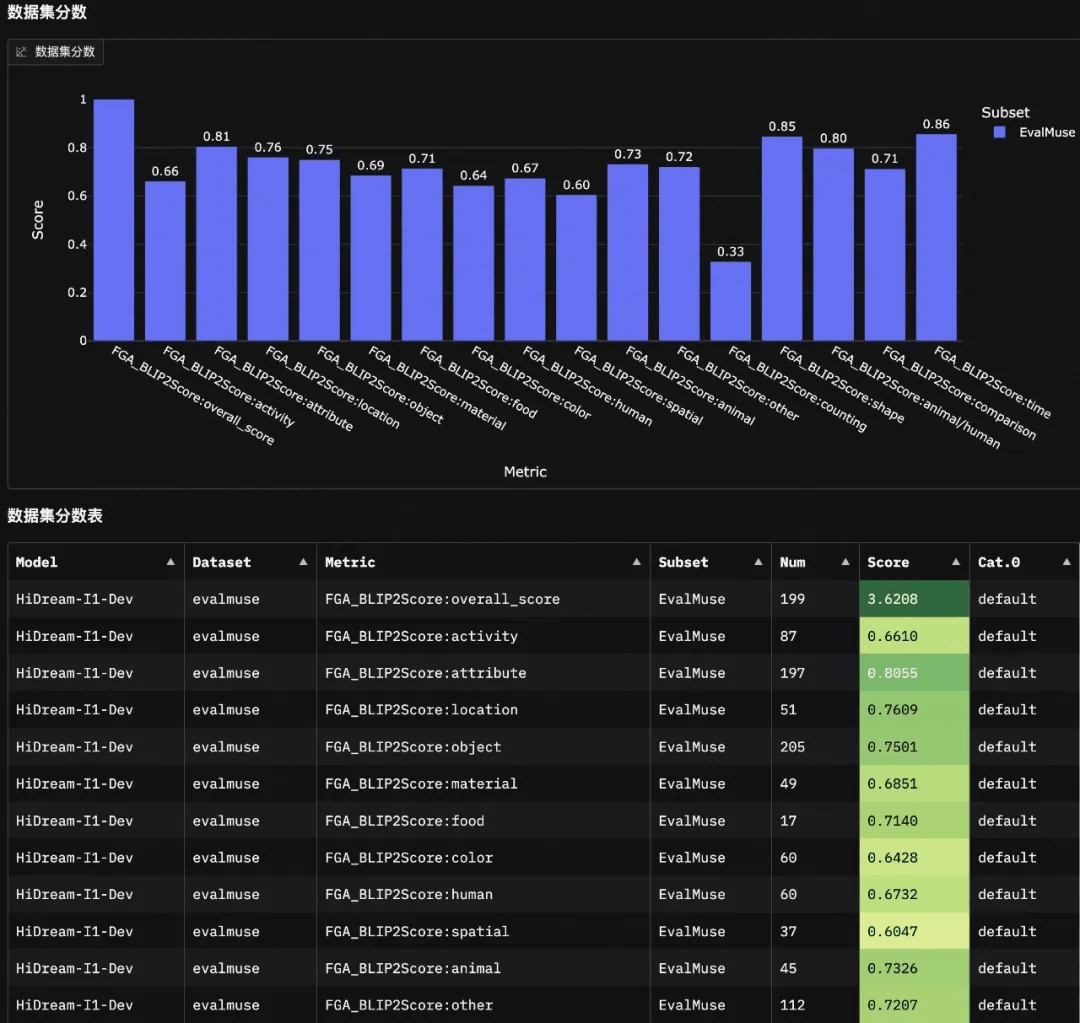
模型得分分布
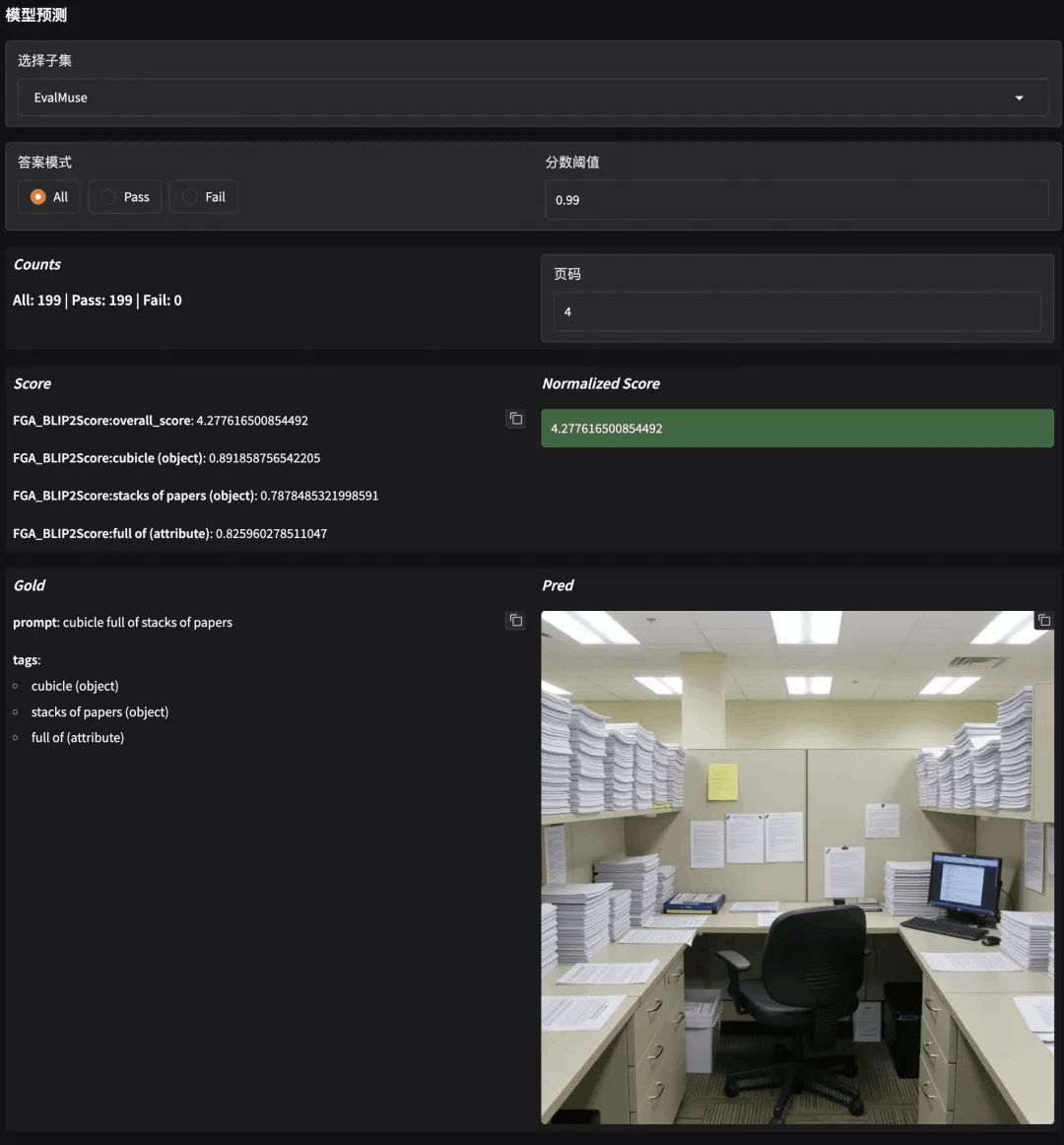
生成图片case查看
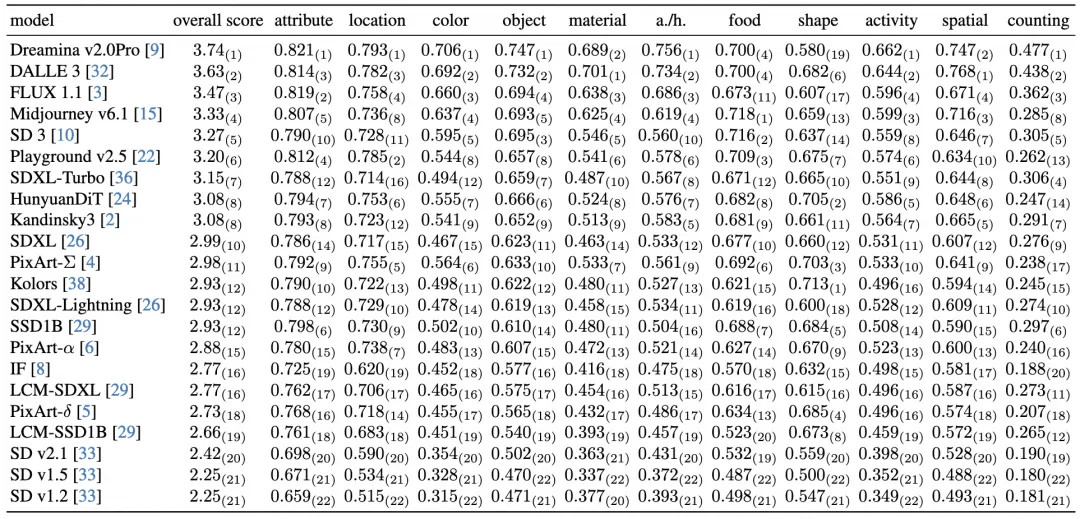
此外我们可以横向对比一下EvalMuse官方给出的测试结果,HiDream-I1-Dev在本框架中的测试结果在表格中可以排到第三名,说明该模型的整体性能不错。虽然表格中未收录该模型数据,但这一外部验证结果表明我们的评测框架能够有效反映模型真实性能水平,与EvalMuse官方基准测试具有可比性。
05.总结
基于EvalScope框架提供的自动化评测,客观上实现了从批量推理到多维度分析的全流程自动化。结合智能报告分析和结果可视化,能够显著提升对文生图模型效果评测的效率及客观性。我们希望这些工作能够协助解决传统人工评测里存在的依赖大量人力进行样本筛选与主观打分所带来的问题,从而降低评测周期、成本,并避免主观偏差的存在而影响评测结果。在这个基础上,我们会进一步完善EvalScope的评测框架的能力,并引进能覆盖更多方面的评测标准,方便开发者对于模型效果能在不同场景做更全面,以及有针对性的评测。
06.参考文献
-
Zhang, S. et al. Learning Multi-dimensional Human Preference for Text-to-Image Generation. Preprint at https://doi.org/10.48550/arXiv.2405.14705(2024).
-
Wu, X. et al. Human Preference Score v2: A Solid Benchmark for Evaluating Human Preferences of Text-to-Image Synthesis. Preprint at https://doi.org/10.48550/arXiv.2306.09341(2023).
-
Chang, L.-W. et al. FLUX: Fast Software-based Communication Overlap On GPUs Through Kernel Fusion. Preprint at https://doi.org/10.48550/arXiv.2406.06858(2024).
-
Cai, Q. et al. HiDream-I1: A High-Efficient Image Generative Foundation Model with Sparse Diffusion Transformer. Preprint at https://doi.org/10.48550/arXiv.2505.22705(2025).
-
Han, S. et al. EvalMuse-40K: A Reliable and Fine-Grained Benchmark with Comprehensive Human Annotations for Text-to-Image Generation Model Evaluation. Preprint at https://doi.org/10.48550/arXiv.2412.18150(2024).
点击链接,即可跳转notebook链接~
https://modelscope.cn/notebook/share/ipynb/c997f3d5/t2i_eval.ipynb

ModelScope旨在打造下一代开源的模型即服务共享平台,为泛AI开发者提供灵活、易用、低成本的一站式模型服务产品,让模型应用更简单!
更多推荐



 0
0 0
0- 0



 已为社区贡献649条内容
已为社区贡献649条内容

所有评论(0)