
UGPhysics:本科物理推理评估基准发布,助力AI+Physics交叉研究
01.摘要
近年来,人工智能快速发展,大语言模型(LLM)在数学、代码等领域展现出强大的推理和生成能力,正在被广泛应用于各种场景。为了更准确评估LLM 的推理能力,之前有研究者们陆续构建了多个标准化数据集,以数学领域为例,如GSM8K、MATH、UGMathBench 等,用于衡量模型解决数学问题的准确性。
然而,与数学相比,物理推理任务更具挑战性:不仅依赖数学推导能力,更需掌握物理法则、理解物理语境、处理单位换算和数量级等复杂知识。尽管已有部分面向高中或竞赛水平的物理评测集,但在覆盖本科物理课程、支持开放问答和系统推理等方面仍存在显著空白。这导致当前主流LLM 在实际物理任务中的表现尚不理想,亟需更具代表性的评测集对其能力进行深入评估。
为填补这一空白,香港科技大学联合清华大学构建并发布了UGPhysics:一个大规模、覆盖广、结构严谨的本科物理推理评估基准。该数据集由来自高校物理教材与题库的5,520 道题目组成,覆盖13 个学科、59 个子主题,题型丰富、语言双语(中英),并引入四类物理推理技能标签。同时,UGPhysics 团队设计了MARJ(Model-Assistant Rule-based Judgment)框架,结合规则和模型判别的优势,提升答案判别可靠性。
UGPhysics 团队还对31 个主流语言模型进行了系统评估,结果表明:即使是DeepSeek-R1 这样的推理模型在UGPhysics 上的准确率也才56% 左右,凸显出当前LLM 在物理领域仍存在显著提升空间。UGPhysics 将作为“物理推理能力”评估基准,为推动AI+Physics 交叉研究与模型发展提供重要支持。
主要贡献总结如下:
• 发布UGPhysics:目前规模最大、覆盖最广、结构最完整的中文+ 英文本科物理推理数据集,内容来自高校正式教材题库,质量可靠。
• 构建MARJ 框架:针对物理答案评估难的问题,提出融合规则与模型的自动评测框架,支持单位换算、表达式等价、多种答案形式。

图1: UGphysics 的概览
• 评估31 个主流大模型:系统对比通用模型、数学特化模型和闭源模型在UGPhysics上的推理能力。
项目地址:
https://github.com/YangLabHKUST/UGPhysics
技术报告地址:
https://arxiv.org/pdf/2502.00334
模型链接:
https://modelscope.cn/datasets/xinxu02/UGPhysics
值得一提的是,该工作已被国际顶级人工智能会议ICML 2025 正式接收
02.UGPhysics 的组成与构建
为系统评估大语言模型在本科物理推理任务中的能力,团队提出并构建了UGPhysics —— 一个结构规范、覆盖全面、具挑战性的本科物理推理基准数集。该数据集旨在填补现有评估体系在物理领域的空白,通过涵盖丰富课程体系、多样题型结构和细粒度标签体系,为物理推理能力的全面测评提供有力支撑。
2.1 数据来源与处理流程
UGPhysics 的题目数据主要来源于多本高校本科物理教材及其配套练习册,涵盖力学、电磁学、热学、量子力学、统计物理、固体物理等核心课程。UGPhysics 团队采用 Mathpix 工具对原始PDF 文档进行数学公式级别的OCR 识别,并通过人工校对修正转换过程中的语法与排版错误,最终得到统一格式的LaTeX 表达。
为便于自动化评估与结构分析,UGPhysics 团队将所有题目整理为标准化的三段式结构:
-
Problem:题干部分,描述问题情境与求解目标;
-
Solution:详细的物理解题过程,包括定律调用与数学推导;
-
Answer:最终标准答案,形式统一、便于比对。
此外,UGPhysics 团队对题干语义进行嵌入表示,并在每门学科内使用余弦相似度进行聚类去重,剔除重复或近似问题,确保数据多样性与有效性。
2.2 覆盖范围与基本统计
UGPhysics 覆盖本科物理教学的三大核心领域:力学与热学、电磁学、现代物理,下设 13 个一级学科与59 个具体主题。数据集主要统计指标如下:
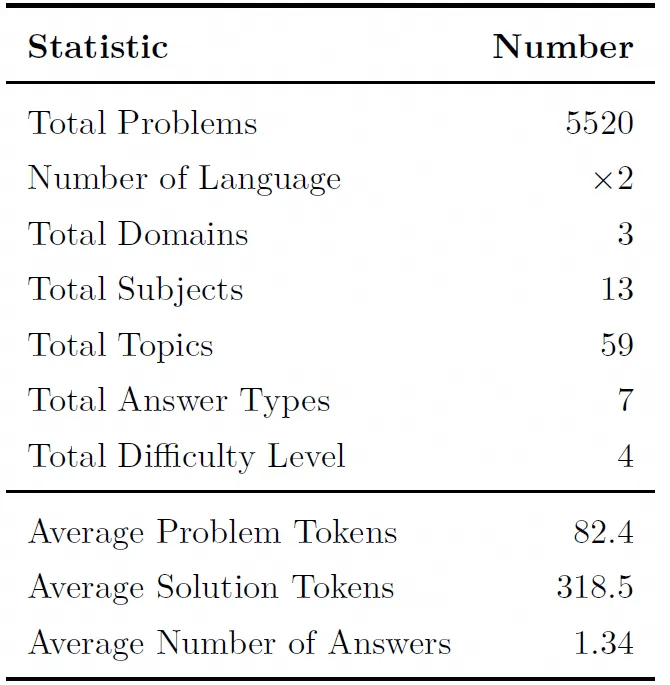
表1: Benchmark Statistics
答题类型详细如下:

表2: Examples of different answer types.
该设计突破传统物理QA 系列多为单选的局限,使UGPhysics 更贴近真实教学与考试中的答题形式,也为大模型能力提供多维评估视角。
2.3 推理技能分类与标签体系
为深入剖析语言模型在物理任务中表现出的不同推理能力,UGPhysics 团队引入了物理技能标签体系,对每道题进行推理能力划分。共设定四类核心技能:
-
知识回忆(Knowledge Recall):考查基础概念、公式记忆与直觉判断;
-
定律应用(Laws Application):要求准确调用相应物理定律或方程;
-
数学推导(Math Derivation):涉及多个数学步骤与公式变换;
-
实际应用(Practical Application):将物理理论与具体情景相结合进行建模或估算。
技能标签由GPT-4o 模型生成,并经过人工抽查验证,确保准确性与一致性。这些标签有助于模型微调方向选择、能力差异定位以及训练集设计优化。
2.4 数据构造原则与过滤策略
UGPhysics 所有题目均为文本输入输出形式,不依赖图像信息或外部上下文。UGPhysics 团队特别处理了教材中常见的“多问连答”型综合题,将其拆解为多个自洽的独立问题,确保每道题均可独立求解且自带上下文信息。
UGPhysics 团队还过滤掉了以下类型问题,以保证自动评估的可行性:
-
无法确定标准答案的问题(如开放性解释题、概念比较等);
-
仅依赖图示、图片或图表才能解答的问题;
-
解题路径含不确定推理跳跃、难以统一答案形式的题目。
最终构成的UGPhysics 数据集,兼具完整性、准确性与评估适配性,适合用于构建严谨的基准评估体系。
2.5. 评估方法:MARJ 自动评判框架
传统的评估方法难以处理物理问题中的多个答案表达(如单位变换、等价表达式、容差容忍等),为此UGPhysics 团队提出MARJ(Model-Assistant Rule-based Judgment)框架:
-
精度适应:考虑有效数字、物理常数、单位换算等;
-
等价判别:支持表达式变换、近似量替换;
-
结合模型柔性:对难以判别的表达式使用LLM 模型评估辅助判断;
-
误判率显著下降:比纯规则或纯模型更稳定。
03.实验评估
为全面评估当前主流语言模型在本科物理推理任务中的表现,团队在UGPhysics 数据集上测试了涵盖闭源与开源的共31 个大语言模型,比较它们在中文与英文版本数据上的准确率表现。主要有以下发现:
-
DeepSeek-R1 取得最佳表现,但整体准确率仍不足60%;大多数模型准确率低于50%,远未达到本科生平均水平;长推理模型虽有很强的推理能里,但在UGPhysics测试下仍显吃力,表明物理任务仍是LLM 的关键挑战。
-
多数模型在英文测试集上的准确率显著高于中文版本;中文任务中表现更弱,提示模型在双语平衡方面仍有待提升。
-
尽管数学继续预训练和监督微调可以显著提升模型的数学推理能力,但是对于物理推理的迁移有限;意味着可能需要专门的“物理继续预训练和监督微调”才能对物理推理有提升;对于长推理模型来说,他们只在数学和代码数据上进行强化学习训练,在物理推理上有较好的泛化性。
-
不同题型与推理技能类型下的模型准确率有差异:“知识回忆”类题目准确率最高;“定律应用”与“实际应用”类题目准确率最低;数值与表达式类型题目准确率高于复合或方程类型;复杂题型与高阶推理技能组合下,准确率普遍不足40%。
-
与数学推理不同,模型在物理推理任务上主要的错误类型是推理过程逻辑有问题,物理知识缺乏和错误运用物理定律。
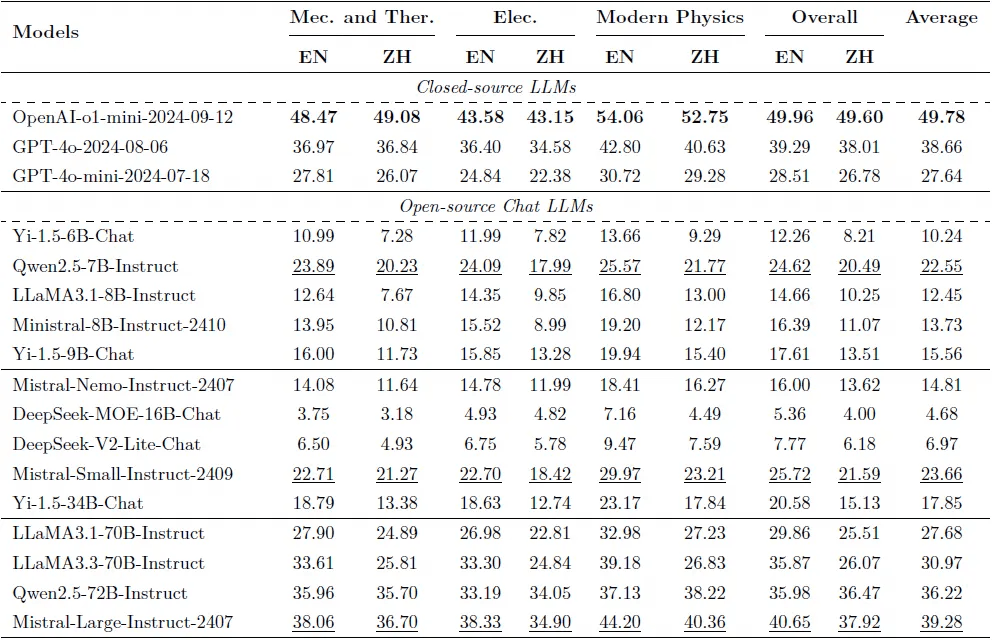
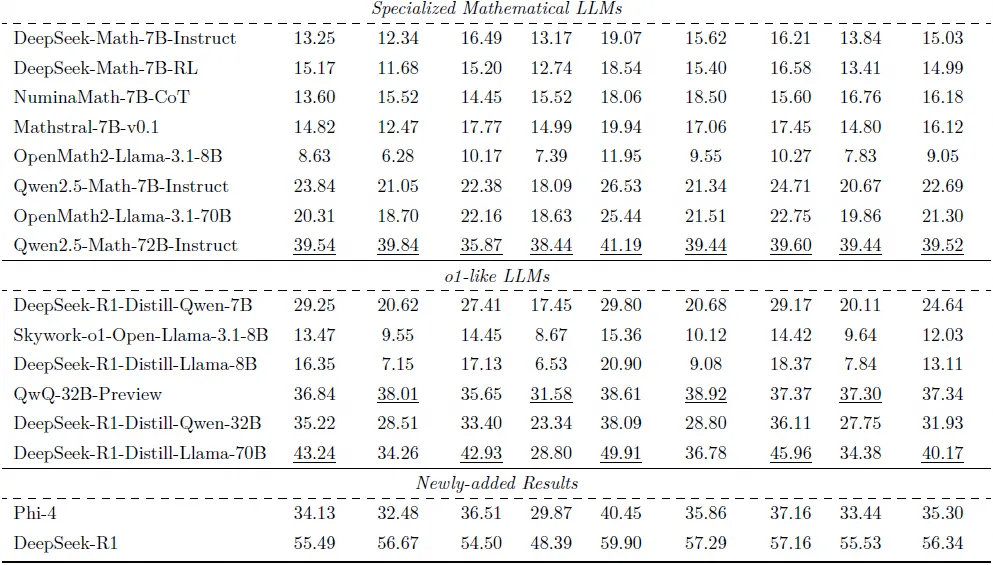
表3: 主要的实验结果
点击链接,即可跳转模型~

ModelScope旨在打造下一代开源的模型即服务共享平台,为泛AI开发者提供灵活、易用、低成本的一站式模型服务产品,让模型应用更简单!
更多推荐



 0
0 0
0- 0



 已为社区贡献649条内容
已为社区贡献649条内容

所有评论(0)