
“一丹一世界”三等奖 | 灵犀共生 经验分享&浅谈AI对摄影的帮助
“一丹一世界”三等奖 | 灵犀共生 经验分享&浅谈AI对摄影的帮助

介绍
大家好我叫得一,是一名职业摄影师,也是一位专注于AIGC视觉领域的创作者。不论是摄影还是AI创作,我都旨在将自己理解的“真善美”用视觉的方式呈现出来。虽然接触AI已经两年多了,但我更多的时候是在学习与沉淀。魔搭活动的出现,对我来说是一个很好的契机,电影风格模型训练大赛是我参加的第一个活动,从那开始,我也陆续获得了一些奖项与肯定。
以下是我的简单自我介绍:
很荣幸我的lora模型灵犀共生获得了魔搭社区一丹一世界风格lora大赛的三等奖,感谢魔搭社区邀请我来分享这次训练模型的经验。其实,我训练模型起步算晚的,跳过了SD1.5和XL,直接从FLUX开始。一方面,FLUX模型的质感较之前的模型有了明显的提升,另一方面,魔搭社区的出现也让训练的便捷性大大地提高了。而在FLUX模型里,我最喜欢的是麦橘超然majicFlus这个大模型,后面自己训练的lora几乎也都是以此为底模。
以下是我的部分模型和所获奖项。



我是怎么开始训练第一个模型的?
因为是摄影师的缘故,我在模型训练时总会想去呈现真实的摄影感!所以我在最初训练第一个模型(麦橘工笔画)的时候,就是想把摄影里的工笔画写真融入到AI里。这里推荐一个我喜欢的国内著名摄影师孙郡,他的新文人画摄影作品给了我许多灵感。
模型训练数据是这样的:

生成出来的作品是这样的:

我的lora都是什么类型的?
后来,我训练的模型更倾向于风格化,比如油画、浮世绘、抽象涂鸦等等。就拿这次获奖的灵犀共生的lora模型来讲,它是以浮世绘的平面装饰性构图与自然主题为基底,构建出独特的生态美学体系。模型通过解构葛饰北斋的浪纹笔触,在数字画布上重现山岳叠层、流水渐变等传统技法。该模型特别强化生物共生关系表现:仙鹤与老翁同匿田间、青蛙与淑女翩翩起舞、狗熊与大叔和平共处,鸟儿停在女孩头顶、兔子跑到姑娘脚下、小狗躺在女子怀里……充分体现万物互联理念,即一丹一世界。该模型突破传统浮世绘的静态叙事框架,使每幅作品既是独立画卷,又是持续演化的生态寓言。

我是怎么去收集训练素材的?
常规的方法是在Midjourney里先去生图,这里可以借助P值和sref去确定风格,然后再将生成的图片筛选出一些适合的内容。还有一个方法是用SD模型生图,生成同一个风格类型的图片,这里可以借用一些lora去增强效果。如果摄影或者绘画技术好,也可以拿自己的作品来试试。但有一点需要注意,为了模型的泛化性更好,建议增加素材的丰富性,比如有人也有动植物,有大景也有特写……
下面是我的部分训练素材:
动物素材

人物素材

大场景

横版构图

我的模型训练习惯有哪些?
首先在素材打标上,我选用的是魔搭自带的JoyCaption打标,打标长度选择short,在这基础上稍作调整,保证用自然语言去描述。这里我有个踩坑经验,供大家参考。如果模型的风格明显,需要触发词,那么触发词千万别写的太随意。我曾经训练模型随意写了触发词(自己的名字deyi),结果出不来效果。如果你训练浮世绘风格模型,最好把触发词设置成Ukiyo-e style,然后在每个打标的素材prompt里都添加这个词!

添加图片注释,不超过 140 字(可选)
图片尺寸,不是越大越好,最好是64的倍数,一般不要超过1536*1536。素材太大了一个是增加训练时长,另一方面出图的质量也并不一定会好。
关于训练次数和轮数,我的习惯是单张训练次数:10,训练轮数:20
至于多少轮保存一个lora,每个人的习惯不一样,这里很自由。如果需要精细化测试哪轮模型更好,可以每2轮就保存一个lora,然后放到stable diffusion的x/Y轴中去测试。要求不高的话,默认5轮保存一个,对比下15轮和20轮的效果即可。
总学习率我选择默认的0.0001,一般是在1e-5到1e-4之间。
如果有长宽不同的素材,记得打开arb桶,这是允许不同宽高比例的图像训练,让训练的数据更丰富。
网络大小rank dim与 Alpha值,一般都选默认的16,记得Alpha值多为rank dim的一半或相同,切记搞反了。
我想说的是,如果你不是拥有超级显卡和有着特殊训练需求,建议都在线上训练吧。比如在魔搭社区这样的平台,这里已经调试好了很棒的丹炉,就等着你用素材来浇灌了。还有很重要的一点,这么好的丹炉现在居然还是免费的!
个人分享
AI的出现冲击了很多的行业,就我所在的摄影行业来看,冲击也是不小的,且影响会越来越大,甚至会逐渐淘汰、取代部分摄影!
尤其是需要布景类的摄影,包括婚纱照、写真等等,首当其冲的就是影楼。比如新人拍婚纱照,以往所需要的各种室内布景现在完全用不着,只需要先在影棚拍摄好白底的照片,然后放到SD里背景重绘就可以了,能节约一大笔的成本。这个技术在一年多前就可以实现了,且市面上已经有一些做的不错的创作者了。

在需要模特出镜的产品拍摄上,不仅可以生成全新的AI模特,还可以换上你需要的模特的脸来辅助拍摄。如果说直接换脸会有些失真感以及融合的问题,那么训练人脸模型就可以解决这一顾虑,呈现更加细腻的写实感!
但AI也不是万能的,纪实类的摄影在很长一段时间内还是安全的,比如新闻摄影、活动拍摄等等,这些都需要摄影师现场拍摄。婚礼摄影师会微笑着告诉你,再聪明的AI也无法模拟结婚当天的现场,也读不懂父亲转身抹泪时微微抖动的嘴角。
AI是一把双刃剑,它的出现是大势所趋。作为摄影师,我觉得当务之急是提早学习,去利用它为摄影服务。据我所知,很多摄影师已经利用AI在提升效率和辅助创作了。除了商业摄影的置景部分,AI在照片直播和后期修图上也提供了不小的帮助。
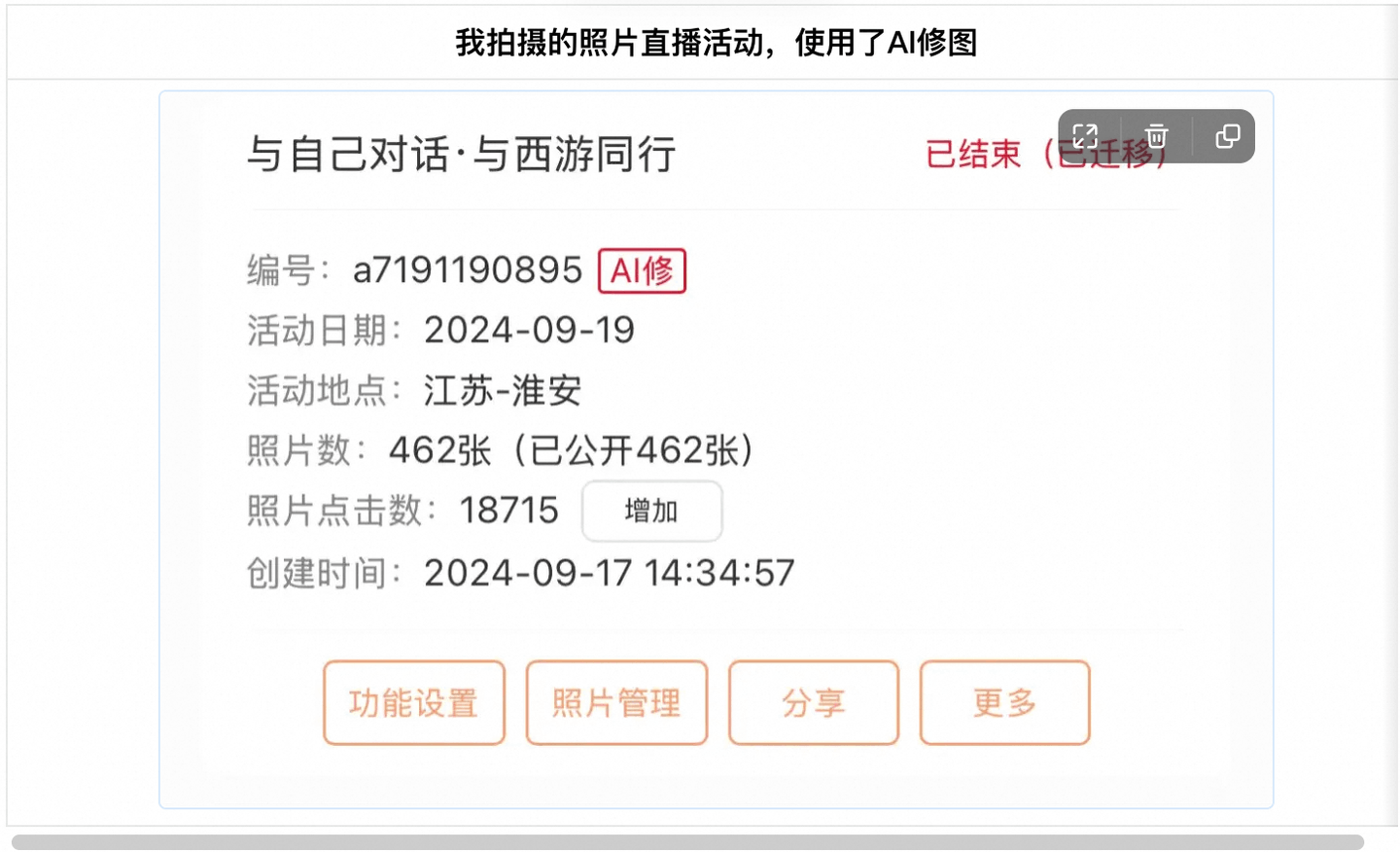
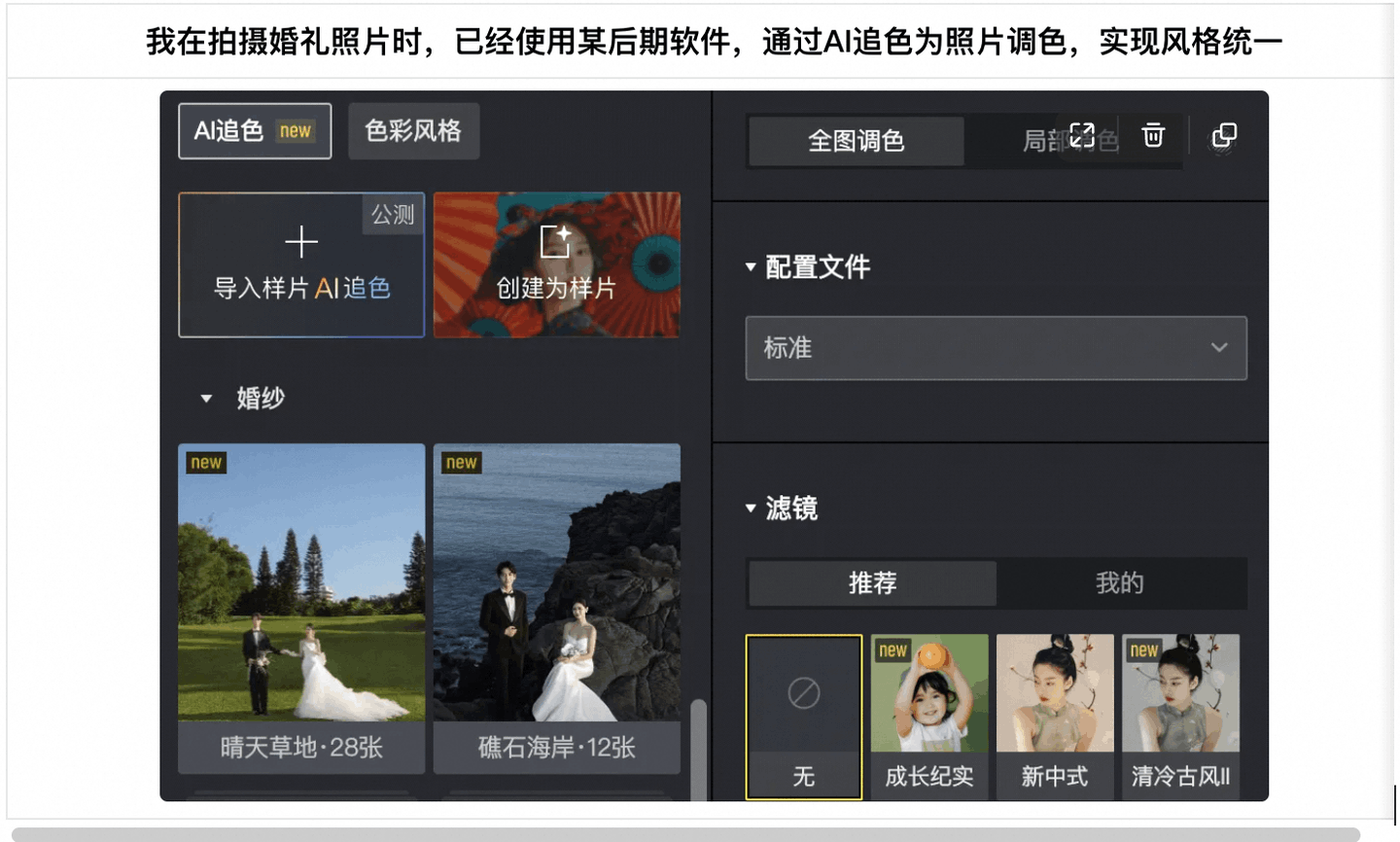
AI的出现不是为了取代摄影,而是给你配备一个拥有超能力的助理,帮助你更好地去完成脑子里的创作。就像当初摄影的诞生,并不是为了取代绘画一样。虽然十九世纪的画家曾视摄影为洪水猛兽,却未曾想到莫奈因此挣脱了“写实”的枷锁,在睡莲池里捕捉流动的光影。摄影没有杀死绘画,反而逼着艺术长出新的翅膀。
每一次的技术革命,都像是给艺术家的调色盘里添了新颜料。从绘画到胶片,从胶片到数码,从数码到AI,变的只是工具,不变的是工具的背后,那双渴望创造的眼睛和追求真善美的大脑。最后,我想用一句话与大家共勉:路漫漫其修远兮,吾将上下而求索!

ModelScope旨在打造下一代开源的模型即服务共享平台,为泛AI开发者提供灵活、易用、低成本的一站式模型服务产品,让模型应用更简单!
更多推荐



 0
0 0
0- 0



 已为社区贡献629条内容
已为社区贡献629条内容

所有评论(0)