
通义实验室开源发布QwenLong-L1 与 QwenLong-CPRS 双模型
近年来,随着大规模预训练语言模型(LLM)在短文本理解与生成任务中的成功,如何让模型在超长文本场景(如学术论文、法规文档、长视频字幕等)中保持高效、准确地推理与理解,成为下一代应用的核心挑战。
01.前言
近年来,随着大规模预训练语言模型(LLM)在短文本理解与生成任务中的成功,如何让模型在超长文本场景(如学术论文、法规文档、长视频字幕等)中保持高效、准确地推理与理解,成为下一代应用的核心挑战。通义实验室最新发布的两项前沿技术——QwenLong-L1(长上下文推理强化学习框架)和 QwenLong-CPRS(动态上下文压缩系统),开源了系列模型和数据集,展现如何带来长上下文处理能力的飞跃。
02.QwenLong-L1:从“短思考”到“长思考”的强化学习
背景与挑战
大多数现有的长文本任务依赖模型参数内隐存储的知识,面对 120K 级别的上下文时,模型往往出现训练效率低、优化不稳定的问题:
-训练收敛缓慢:因输出长度大、熵值下降快,策略探索受限;
-优化不稳定:长输出带来 KL 散度剧烈波动,策略更新易陷入振荡。
核心思路
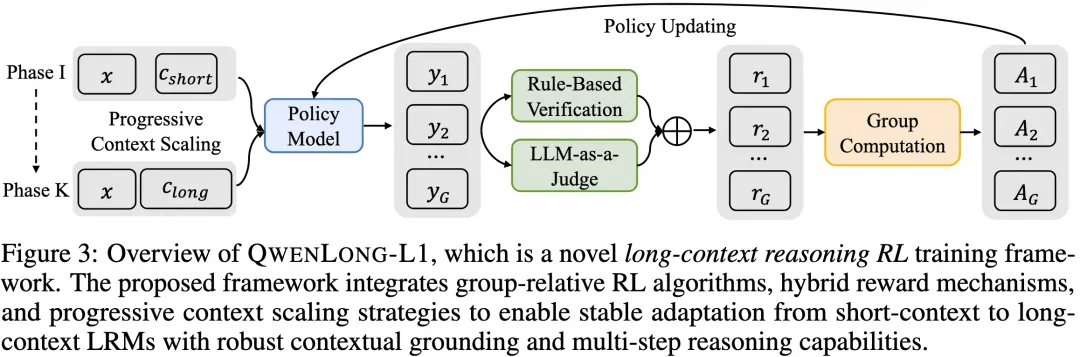
QwenLong-L1 针对上述难题,提出“渐进式上下文扩展”的 RL 训练框架,包含三大关键策略:
-
Warm-up SFT(监督精调):以 20K Token 的短上下文示例,进行高质量示例微调,为策略初始化提供稳定基础;
-
Curriculum-Guided 分阶段 RL:将训练分为多个阶段,逐步从短上下文 (20K) 过渡到长上下文 (60K+),每阶段只使用对应长度的数据,避免一次性大跨度优化导致的不稳定;
-
Difficulty-Aware 追溯采样:针对前一阶段表现最差的“难例”进行重点回放,使模型在长上下文阶段继续探索高难度样本,提升策略的鲁棒性。
显著成果
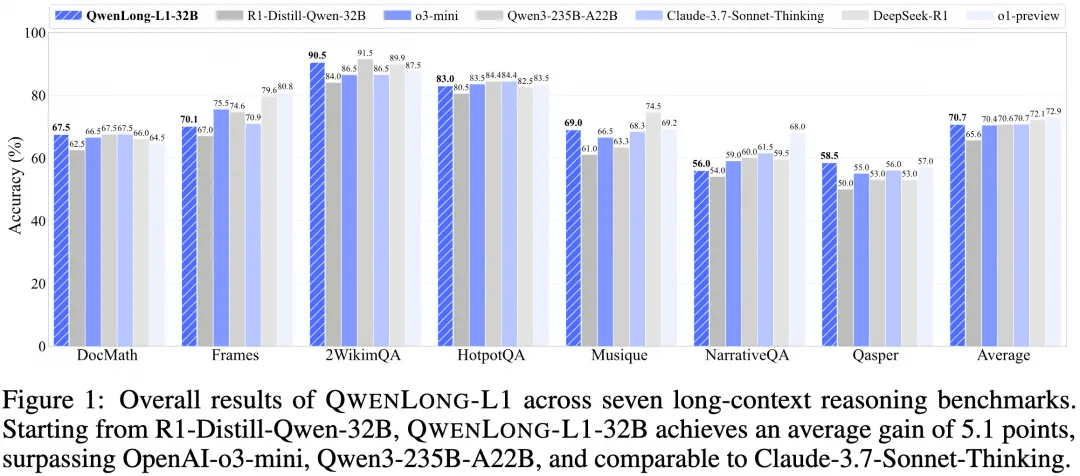
在七个长上下文文档问答基准(DocMath、Frames、2WikiMultihopQA、HotpotQA、Musique、NarrativeQA、Qasper)上,QWENLONG-L1-32B 模型:
-平均性能提升 5.1 个百分点,超过 OpenAI-o3-mini、Qwen3-235B-A22B,并与 Claude-3.7-Sonnet-Thinking 持平;
-14B 版本也有 4.1 个百分点增益,展现了小模型在 RL 微调后逼近大模型的潜力;
-Pass@K 曲线显示,随着采样数的增加,长模型的探索能力与利用能力齐头并进。
开源链接
模型:
https://modelscope.cn/models/iic/QwenLong-L1-32B
数据集:
https://modelscope.cn/datasets/iic/DocQA-RL-1.6K
03.QwenLong-CPRS:动态压缩、无限长上下文
动态上下文优化范式
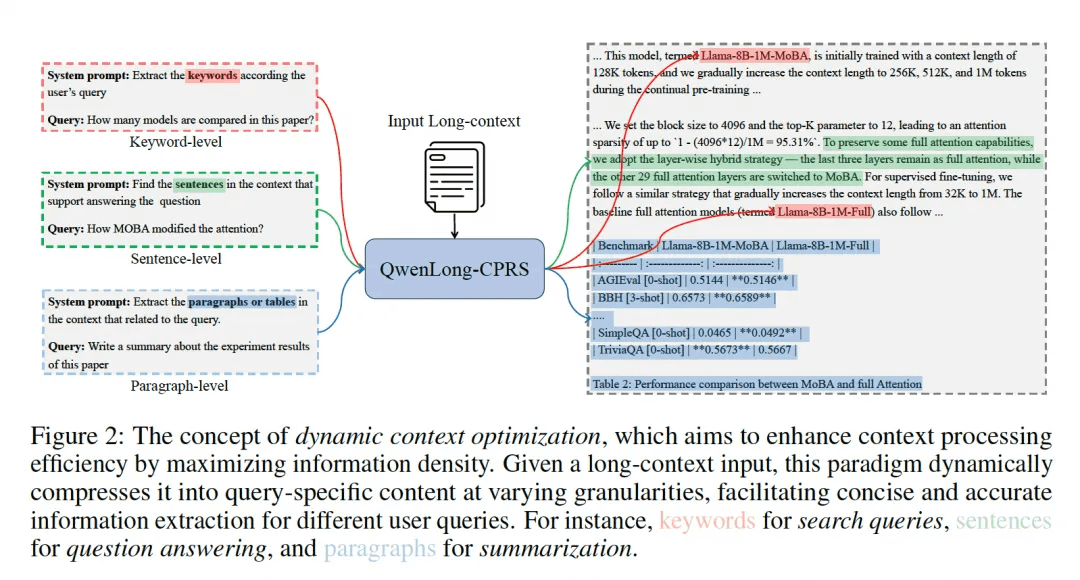
针对超远程上下文(可达 2M Token),QwenLong-CPRS 提出“动态上下文优化”新范式,通过自然语言指令控制多粒度压缩,最大程度保留关键信息:
-关键词级:抽取命名实体、关键词;
-句子级:抽取“干草堆中的针”句子;
-段落级:抽取完整段落或表格块。
用户只需在系统提示中指定所需粒度,如“请提取支持答案的段落”,即可实现无需重训、即插即用的上下文压缩。
模型架构与机制
-
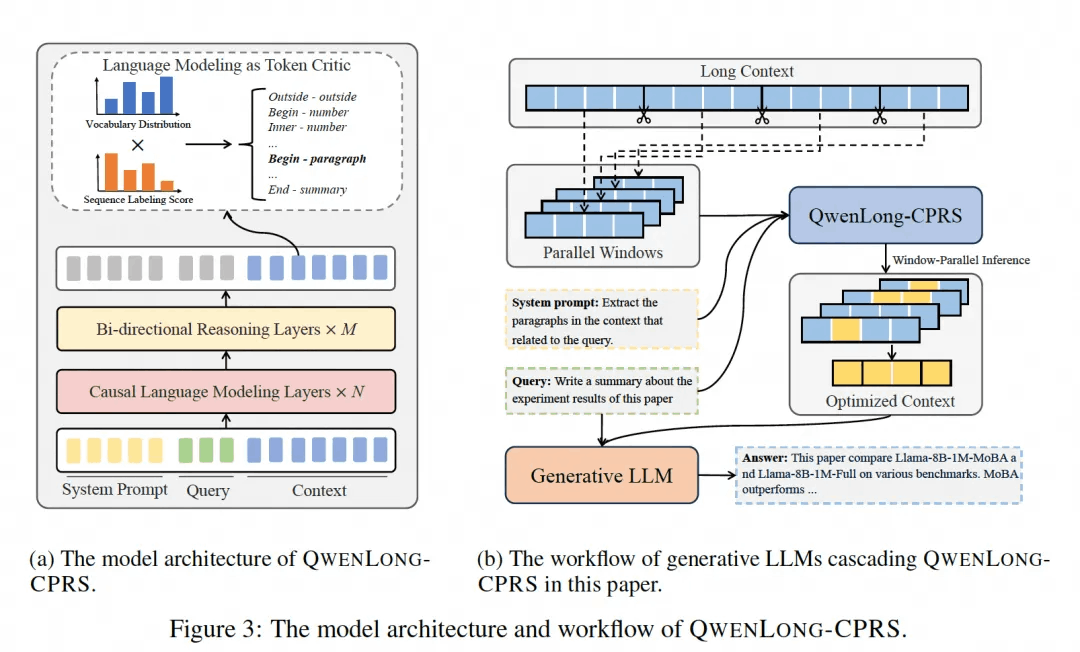
双向定位推理层:下层保留因果注意力,上层改为双向注意力,实现边界位置的全局感知;
-
语言建模即 Token Critic:复用语言模型头为令牌打分,二合一预测语义类别与位置标签;
-
窗口并行推理:将超长文本分片并行打分,再汇总最优子集进行后续生成。
性能与效率大跃进
-在 Ruler-128K、InfiniteBench、LongBench 等 5 个超长基准上,QWENLONG-CPRS 为 Qwen2.5-7B/32B/72B 带来平均 19.15 个百分点性能增益,压缩率最高达 290×;
-相比 RAG、稀疏注意力(Minference、MOBA、NSA)均有显著优势,尤其在多跳推理与高相似度场景中优势更明显;
-系统端延迟仅随分片数量线性增长,大规模上下文的端到端部署成本与传统全 attention 相比大幅降低。
开源链接
模型链接:
https://modelscope.cn/models/iic/QwenLong-CPRS-7B
后续还会在魔搭上线体验QwenLong-CPRS能力的创空间,以及阿里云百炼Qwen-Long上也会开放调用QwenLong-CPRS模型API的能力。
通过QwenLong的这两个技术的结合,为未来“无限长上下文”时代的自然语言处理提供了从训练到推理的全链路解决方案,助力各行业实现知识密集型场景下的智能化升级。
04.模型使用
这里是如何使用ModelScope运行模型的方法:
from modelscope import AutoModelForCausalLM, AutoTokenizer
model_name = "iic/QwenLong-L1-32B"
# load the tokenizer and the model
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype="auto",
device_map="auto"
)
# prepare the model input
template = """Please read the following text and answer the question below.
<text>
$DOC$
</text>
$Q$
Format your response as follows: "Therefore, the answer is (insert answer here)"."""
context = "<YOUR_CONTEXT_HERE>"
question = "<YOUR_QUESTION_HERE>"
prompt = template.replace('$DOC$', context.strip()).replace('$Q$', question.strip())
messages = [
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
# conduct text completion
generated_ids = model.generate(
**model_inputs,
max_new_tokens=10000,
temperature=0.7,
top_p=0.95
)
output_ids = generated_ids[0][len(model_inputs.input_ids[0]):].tolist()
# parsing thinking content
try:
# rindex finding 151649 (</think>)
index = len(output_ids) - output_ids[::-1].index(151649)
except ValueError:
index = 0
thinking_content = tokenizer.decode(output_ids[:index], skip_special_tokens=True).strip("\n")
content = tokenizer.decode(output_ids[index:], skip_special_tokens=True).strip("\n")
print("thinking content:", thinking_content)
print("content:", content)05.模型训练和评估
以DeepSeek-R1-Distill-Qwen-1.5B模型为例,展示使用ms-swift框架实现论文中的两阶段训练路径
环境安装
# pip install git+https://github.com/modelscope/ms-swift.git
git clone https://github.com/modelscope/ms-swift.git
cd ms-swift
pip install -e .第一阶段Warm-up SFT中,以 AI-ModelScope/LongAlpaca-12k 数据集为例,使用长文本数据集对模型进行监督训练
CUDA_VISIBLE_DEVICES=0,1,2,3,4,5,6,7 \
NPROC_PER_NODE=8 \
swift sft \
--model deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B \
--train_type lora \
--dataset AI-ModelScope/LongAlpaca-12k \
--torch_dtype bfloat16 \
--num_train_epochs 1 \
--per_device_train_batch_size 1 \
--per_device_eval_batch_size 1 \
--learning_rate 5e-6 \
--lora_rank 8 \
--lora_alpha 32 \
--target_modules all-linear \
--gradient_accumulation_steps 16 \
--save_steps 200 \
--save_total_limit 2 \
--logging_steps 5 \
--output_dir output \
--warmup_ratio 0.05 \
--dataloader_num_workers 64 \
--deepspeed zero3 \
--sequence_parallel_size 4 \
--use_liger_kernel true lora训练后,使用以下命令合并lora层(如果是全参训练则跳过)
swift export \
--ckpt_dir /path/to/sft_checkpoint
--merge_lora第二阶段,基于sft得到的checkpoint,进行GRPO训练。论文中使用Qwen2.5-1.5B-Instruct模型作为评估模型,判断模型生成的回答和数据集中的ground_truth是否等价。
You are an expert in verifying if two answers are the same. Your input is a problem and two answers, Answer 1 and Answer 2. You need to check if they are equivalent. Your task is to determine if two answers are equivalent, without attempting to solve the original problem. Compare the answers to verify they represent identical values or meaning, even when written in different forms or notations. Your output must follow the following format: 1) Provide an explanation for why the answers are equivalent or not. 2) Then provide your final answer in the form of: [[YES]] or [[NO]] Problem: question Answer 1: predicted answer Answer 2: gold answer同时获取rule-based verification reward,取二者的最大值作为最终奖励
基于ms-swift,我们可以通过自定义reward_model_plugin来实现以上奖励逻辑,相关实现可以参考 swift/examples/train/grpo/plugin/plugin.py 中的 QwenLongPlugin。
训练之前,首先通过以下命令部署 vLLM 服务器,以加速训练过程中的采样流程
CUDA_VISIBLE_DEVICES=6,7 \
swift rollout \
--model /path/to/sft_checkpoint \
--data_parallel_size 2 \
--tensor_parallel_size 1基于 DocQA-RL-1.6K 数据集,使用以下命令对SFT后的模型进行 GRPO 训练
可以按照长度对数据集进行排序,然后设置参数 --dataset_shuffle false 以确保不打乱数据集,从而进行课程学习。
CUDA_VISIBLE_DEVICES=0,1,2,3,4,5 \
NPROC_PER_NODE=6 \
swift rlhf
--rlhf_type grpo \
--model /path/to/sft_checkpoint \
--dataset iic/DocQA-RL-1.6K \
--external_plugins examples/train/grpo/plugin/plugin.py \
--reward_model Qwen/Qwen2.5-1.5B-Instruct \
--reward_model_plugin qwenlong \
--use_vllm true \
--vllm_mode server \
--vllm_server_host 127.0.0.1 \
--vllm_server_port 8000 \
--per_device_train_batch_size 1 \
--gradient_accumulation_steps 8 \
--num_generations 8 \
--eval_strategy no \
--split_dataset_ratio 0 \
--deepspeed zero2 \
--log_completions true \训练完成后,使用以下命令对训练后的权重进行推理,这里的`--adapters`需要替换成训练生成的last checkpoint文件夹。
CUDA_VISIBLE_DEVICES=0 \
swift infer \
--adapters /path/to/grpo_checkpoint \
--stream true \
--max_new_tokens 2048 \
--temperature 0推送模型到ModelScope:
CUDA_VISIBLE_DEVICES=0 \
swift export \
--adapters /path/to/grpo_checkpoint \
--push_to_hub true \
--hub_model_id '<your-model-id>' \
--hub_token '<your-sdk-token>'使用EvalScope评测训练后的模型性能:
运行下面命令安装EvalScope:
pip install evalscope运行下面命令即可在指定benchmark上测试模型性能:
evalscope eval \
--model /path/to/grpo_checkpoint \
--datasets iquiz下面以Qwen2.5-7B-Instruct 模型为例,展示评测结果:

下面我们运行EvalScope的可视化界面启动命令,来具体看看模型对每个问题是如何回答的。
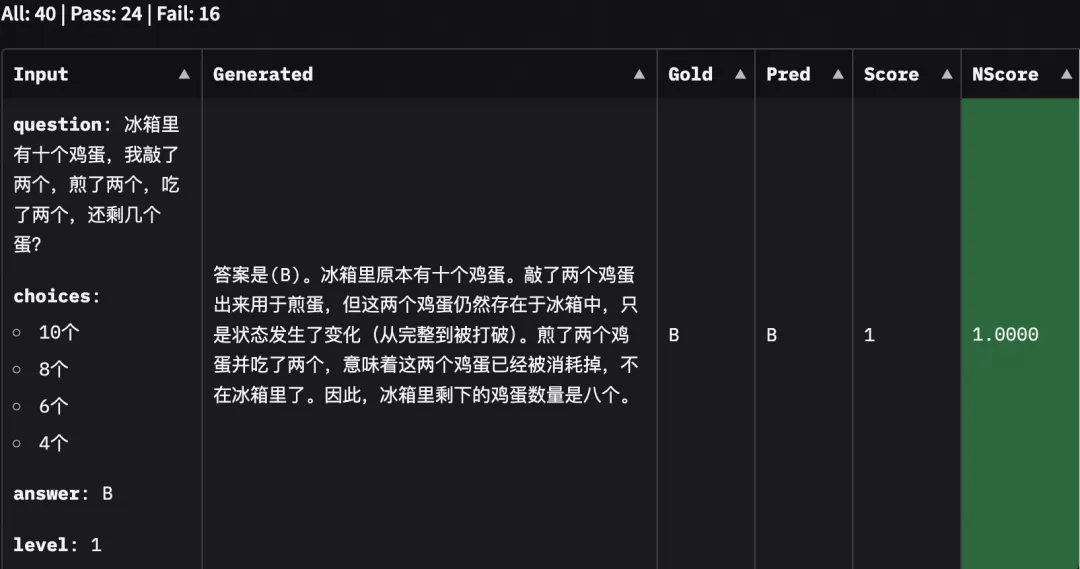
evalscope app先选择评测报告然后点击加载,再选择对应的子数据集就可以看到模型对每个问题的回答了:
点击阅读原文,即可查看更多支持的评测基准参考~
https://evalscope.readthedocs.io/zh-cn/latest/get_started/supported_dataset.html

ModelScope旨在打造下一代开源的模型即服务共享平台,为泛AI开发者提供灵活、易用、低成本的一站式模型服务产品,让模型应用更简单!
更多推荐



 0
0 0
0- 0



 已为社区贡献652条内容
已为社区贡献652条内容

所有评论(0)