
MiniMax-M1开源:支持百万级上下文窗口的混合MoE推理模型!
01.前言
MiniMax最新发布了全球首个开源大规模混合架构的推理模型——MiniMax-M1!
M1在面向生产力的复杂工作场景,包括软件工程、长上下文与工具使用上表现优异,超过国内的闭源模型,接近海外的最领先模型,同时又有业内最高的性价比。

M1支持目前业内最高的100万上下文的输入,与Gemini 2.5 Pro 一致,以及业内最长的8万Token的推理输出,长于Gemini 2.5的 64K。

MiniMax-M1总参数量4560亿,单次激活459亿Tokens,此次开源包括两个版本,具有 4 万和 8 万的 COT长度,其中 4 万 COT的模型代表了 8万 COT版本训练过程中的一个中间阶段。
MiniMax-M1在业内主流的 17 个评测集上详细评测了M1。结果显示,M1在面向生产力的复杂工作场景,包括软件工程、长上下文与工具使用上具备显著优势,是开源模型中最好的一档。
具体的结果如下:
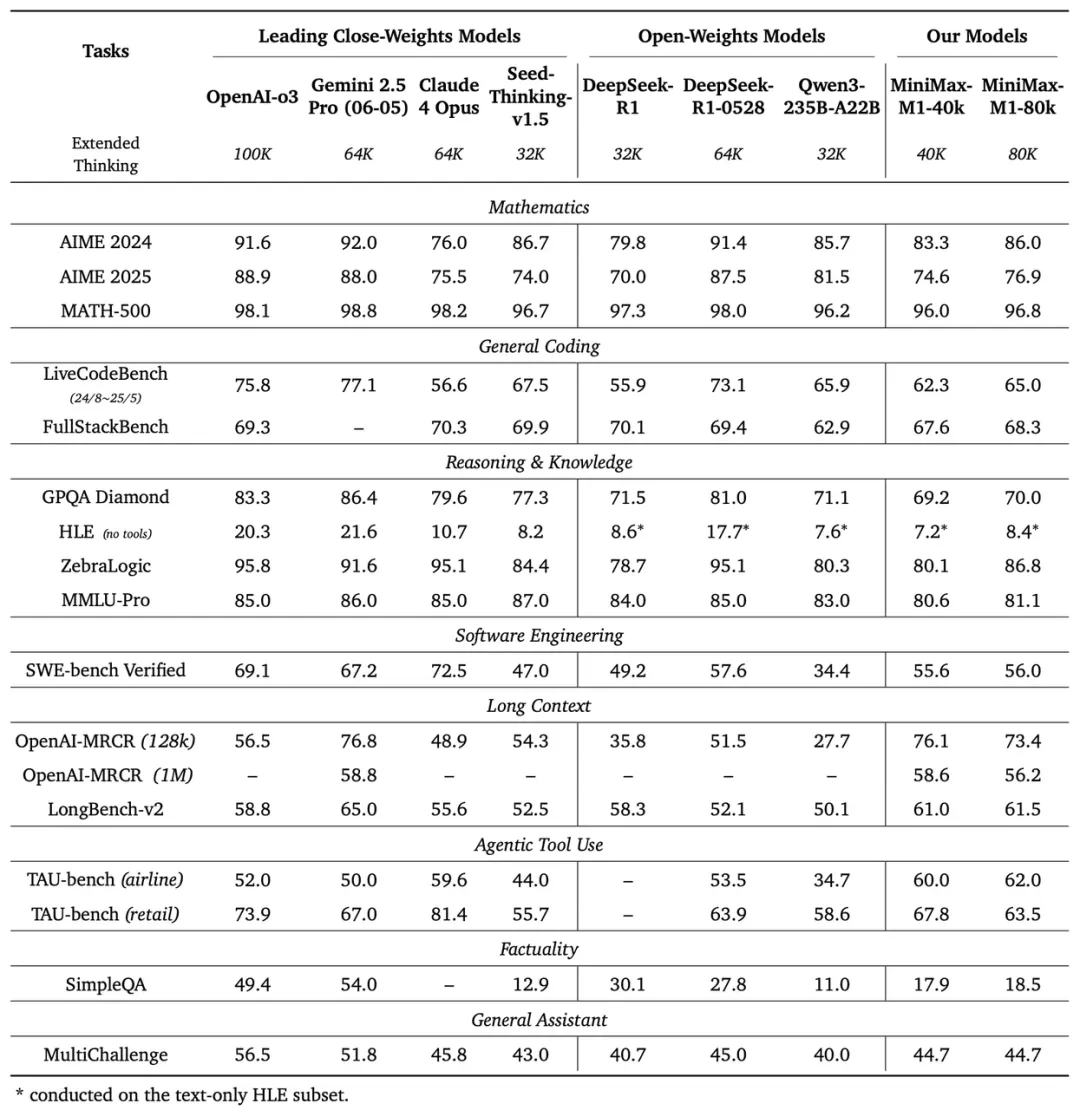
-依托百万级上下文窗口,M1系列在长上下文理解任务中表现卓越,不仅全面超越所有开源权重模型,甚至超越OpenAI o3和Claude 4 Opus,全球排名第二,仅以微弱差距落后于Gemini 2.5 Pro。
-在代表解决实际软件工程编码问题SWE-bench验证基准上,MiniMax-M1-40k和MiniMax-M1-80k分别取得55.6%和56.0%的优异成绩,这一成绩略逊于DeepSeek-R1-0528的57.6%,显著超越其他开源权重模型。
-在代理工具使用场景(TAU-bench)中,MiniMax-M1-40k同样领跑所有开源权重模型,并战胜Gemini-2.5 Pro。
MiniMax的整个RL训练非常高效。得益于架构创新以及提出的新算法CISPO,整个RL阶段只用到512块H800 3周时间,租赁成本只有53.7万美金。这比一开始的预期少了一个数量级。
MiniMax-M1采用以flash attention机制为主的混合架构,在计算长上下文输入以及深度推理时显著高效。例如,在使用8万Token深度推理的时候,只需要使用DeepSeek R1约30%的算力。这个特性,使得研究团队在训练推理模型的时候有极大的速度和成本优势。
除此之外,研究团队提出了强化学习算法CISPO,这一算法通过裁剪重要性采样权重(而非传统token更新)提升强化学习效率。在AIME 的实验中,研究团队发现这比包括字节提出的 DAPO 等强化学习算法收敛性快了一倍,并且显著优于 DeepSeek 早期使用的 GRPO。

目前,vLLM和Transformer已经实现了对M1的部署支持,和SGLang的部署支持也在推动中。
因为相对高效的训练和推理算力使用,研究团队在 MiniMax APP 和 Web 上都保持不限量免费使用,并以业内最低的价格在官网提供API。在0-32k的输入长度的时候,输入0.8元/百万token, 输出8元/百万token;在32k-128k的输入长度的时候,输入1.2元/百万token, 输出16元/百万token;在最长的 128k-1M 的输入长度的时候,输入2.4元/百万token, 输出24元/百万token。前面两种模式都比 DeepSeek-R1 性价比更高,后面一种模式 DeepSeek 模型不支持。
模型链接:
https://modelscope.cn/models/MiniMax/MiniMax-M1-80k
体验空间:
https://modelscope.cn/studios/MiniMax/MiniMax-M1
02.模型推理
我们介绍使用ms-swift对MiniMax-M1-40k进行推理。在推理之前,请确保您的环境已准备妥当。
git clone https://github.com/modelscope/ms-swift.git
cd ms-swift
pip install -e .使用transformers作为推理后端:
显存占用: 8 * 80GiB
import os
os.environ['CUDA_VISIBLE_DEVICES'] = '0,1,2,3,4,5,6,7'
from transformers import QuantoConfig
from swift.llm import PtEngine, RequestConfig, InferRequest
quantization_config = QuantoConfig(weights='int8')
messages = [{
'role': 'system',
'content': 'You are a helpful assistant.'
}, {
'role': 'user',
'content': 'who are you?'
}]
engine = PtEngine('MiniMax/MiniMax-M1-40k', quantization_config=quantization_config)
infer_request = InferRequest(messages=messages)
request_config = RequestConfig(max_tokens=128, temperature=0)
resp = engine.infer([infer_request], request_config=request_config)
response = resp[0].choices[0].message.content
print(f'response: {response}')
"""
<think>
Okay, the user asked "who are you?" I need to respond in a way that's helpful and clear. Let me start by introducing myself as an AI assistant. I should mention that I'm here to help with information, answer questions, and assist with tasks. Maybe keep it friendly and open-ended so they know they can ask for more details if needed. Let me make sure the response is concise but informative.
</think>
I'm an AI assistant designed to help with information, answer questions, and assist with various tasks. Feel free to ask me anything, and I'll do my best to help! 😊
"""使用vllm作为推理后端:
显存占用: 8 * 80GiB
注意:你需要手动修改config.json文件,`config['architectures'] =
["MiniMaxM1ForCausalLM"]`修改为`config['architectures'] =
["MiniMaxText01ForCausalLM"]`
import os
os.environ['CUDA_VISIBLE_DEVICES'] = '0,1,2,3,4,5,6,7'
os.environ['VLLM_USE_V1'] = '0'
if __name__ == '__main__':
from swift.llm import VllmEngine, RequestConfig, InferRequest
messages = [{
'role': 'system',
'content': 'You are a helpful assistant.'
}, {
'role': 'user',
'content': 'who are you?'
}]
engine = VllmEngine('MiniMax/MiniMax-M1-40k', tensor_parallel_size=8,
quantization='experts_int8', max_model_len=4096, enforce_eager=True)
infer_request = InferRequest(messages=messages)
request_config = RequestConfig(max_tokens=128, temperature=0)
resp = engine.infer([infer_request], request_config=request_config)
response = resp[0].choices[0].message.content
print(f'response: {response}')使用命令行:
CUDA_VISIBLE_DEVICES=0,1,2,3,4,5,6,7 \
swift infer \
--model MiniMax/MiniMax-M1-40k \
--tensor_parallel_size 8 \
--vllm_quantization experts_int8 \
--max_model_len 4096 \
--enforce_eager true \
--infer_backend vllm \
--stream true \
--max_new_tokens 2048 \
--temperature 0.7
显存占用:

点击链接, 即可跳转模型连接~

ModelScope旨在打造下一代开源的模型即服务共享平台,为泛AI开发者提供灵活、易用、低成本的一站式模型服务产品,让模型应用更简单!
更多推荐



 0
0 0
0- 0



 已为社区贡献651条内容
已为社区贡献651条内容

所有评论(0)