

AI故事随心绘:多主体ID保留,个性化生成
近期通义实验室提出了一种AnyStory的方法,旨在实现高质量的个性化文本到图像生成,支持单个和多个主体。
00.前言
近期通义实验室提出了一种AnyStory的方法,旨在实现高质量的个性化文本到图像生成,支持单个和多个主体。
01.在线体验
小程序链接:
https://modelscope.cn/studios/iic/AnyStory
该方法通过结合强大的通用图像编码器(如ReferenceNet)与CLIP视觉编码器来实现高保真度的主题特征编码,并利用一个解耦的实例感知主题路由器来精确预测并引导主题条件的注入,从而实现了灵活且可控的个性化生成。实验结果表明,该方法在保持主题细节、文本描述一致性以及多主题个性化方面表现出色。
此外,AnyStory还展示了任何故事框架的潜力,不仅限于人脸或特定类别物体的个性化,而且能够处理更广泛的主题,包括非人类实体和复杂背景下的场景生成。尽管存在一些限制,如无法为图像生成定制背景,但研究团队展望未来的研究方向,包括扩展对背景控制的能力和进一步减少复制粘贴效应,以提升生成图像的质量。

课代表划重点
-
AnyStory提出了一种增强的主题表示编码器和解耦的实例感知路由模块,用于实现灵活可控的个性化图像生成。
-
相较于现有方法,AnyStory能够更准确地感知并预测主题的潜在条件区域,从而提高生成效果。
-
AnyStory采用了CLIP视觉编码器和轻量级ReferenceNet来高保真度地对一般主题进行细节编码。
-
解耦的实例感知路由模块可以适应单或多主题的个性化生成需求。
-
AnyStory通过使用路由主题的方法实现了一致性和多样性的平衡,并且不需要预先定义布局掩模。
02.模型结构
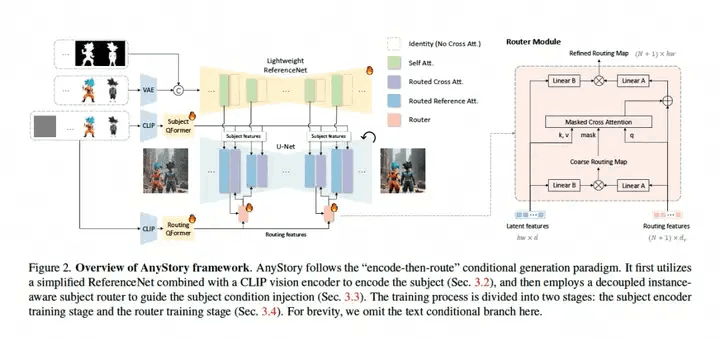
AnyStory遵循“encode-then-route”的传统条件生成范式,首先利用简化的ReferenceNet 结合 CLIP视觉编码器结合subject编码,然后采用解耦的instance-aware subject router来引导subject条件注入,训练过程分为2个阶段,subject Encoder训练阶段和Router训练阶段,为了简单起见,图中省略了文本分支。
模型效果:




点击链接,即可跳转体验~

ModelScope旨在打造下一代开源的模型即服务共享平台,为泛AI开发者提供灵活、易用、低成本的一站式模型服务产品,让模型应用更简单!
更多推荐



 0
0 0
0- 0



 已为社区贡献606条内容
已为社区贡献606条内容

所有评论(0)