
"一丹一世界"二等奖 | TPSZ_二次元卡通梦幻插画风格-童梦拾光 创作分享
"一丹一世界"二等奖 | TPSZ_二次元卡通梦幻插画风格-童梦拾光 创作分享
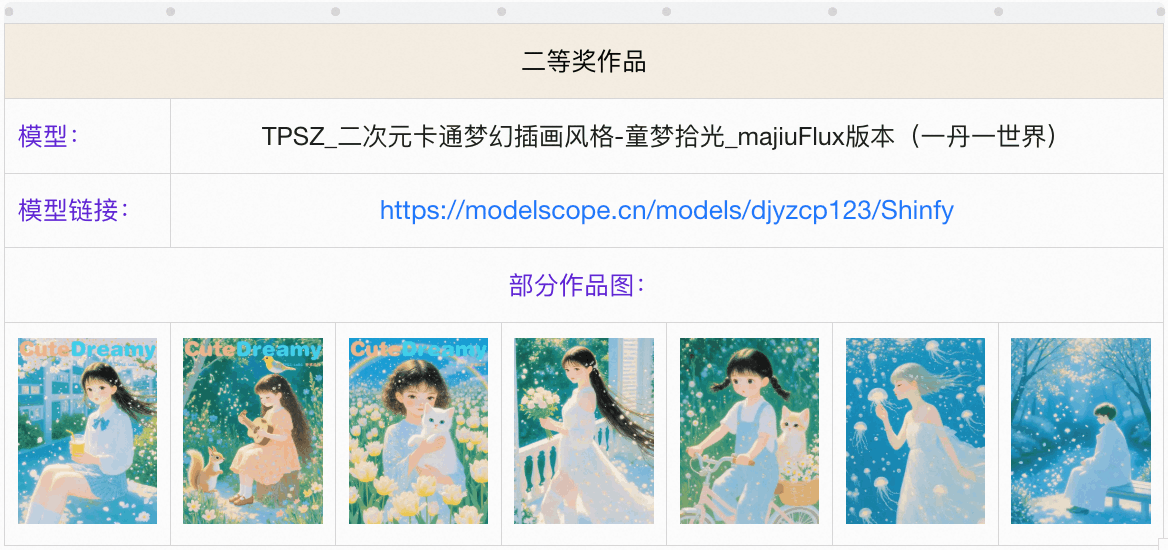
一.写在前面

大家好,我是 “琳的画”,大家也可以叫我琳。我是一名AIGC领域艺术创作者。
前段时间参加了魔搭平台举办的“一丹一世界”风格LoRA大赛,很荣幸获得了二等奖。
感谢魔搭官方的邀请,让我有机会跟大家分享我的创作过程和想法。
说实话,当时魔搭官方找到我,希望我分享一些经验和心得时,我心里实属有些忐忑。一是我对于做过的东西,不太擅长整理和输出;二是我文采一般,担心不能把这部分内容很好的分享出来。

此配图由获奖LoRA“童梦拾光”生成。
Prompt:A girl wearing round-frame glasses bites a pencil and looks out the window. A fluffy hairpin secures her bangs. On the log-colored desk piled high with stationery, draft papers are scattered. It is in the style of a Japanese campus watercolor hand-drawn illustration. The light green wall paint contrasts with the projection of sunlight. Mathematical formulas are reflected on the glass window. The pencil presses a small dent on her cheek.
把这些担心说给对方后,对方建议我可以给“不知如何踏出第一步的新手“写一个轻教程,这让我想起了刚开始炼丹时的自己,无论如何,就抱着分享的态度来和大家随便聊聊,也趁此机会好好梳理一下。教程谈不上,能有一点帮助和启发我就心满意足了。如有不准确或可优化之处 ,也欢迎大家随时与我交流指正。
二.在探索中前行
我本身是一位设计师,本着让新工具更好的辅助传统设计的目的,我在2023年底接触了AI。那段时间我开始大量的学习、研究这方面的知识。过程中我会参加一些比赛,来验证自己阶段性的学习成果,从而发现自己优势和不足。像这次比赛,收获鼓励的同时,也学习到了其它小伙伴各有亮点的优秀风格,这也是一种很好的成长方式,供大家参考。
有段时间我沉迷于AI作图,慢慢的我发现,让AI天马行空的出图固然有意思,但如果想要某种特定的画风和角色IP形象还是自己训练出趁手的模型会更方便。于是我开始学习“炼丹”。
记得刚开始,训练LoRA的过程对我来说非常的艰辛、枯燥和无聊,由于没经验、工具的不完善,大概几十张图片的训练集,光打标就需要一个周左右。那时主要是基于SD1.5训练模型,我是用一个个标签来给图片打标。我往往会打的特别详细,比如人物表情我会分她是抿嘴笑还是露齿笑,是大笑还是喜悦的笑;人物的发型,我会写清楚是中分刘海还是齐刘海,测试下来整体画风效果还不错,但总体上SD1.5还是有很大的局限性。特别是在生成细节(如手部、复杂结构)容易出错,经常会出现六指、关节扭曲等问题,对提示词精准度依赖较高。
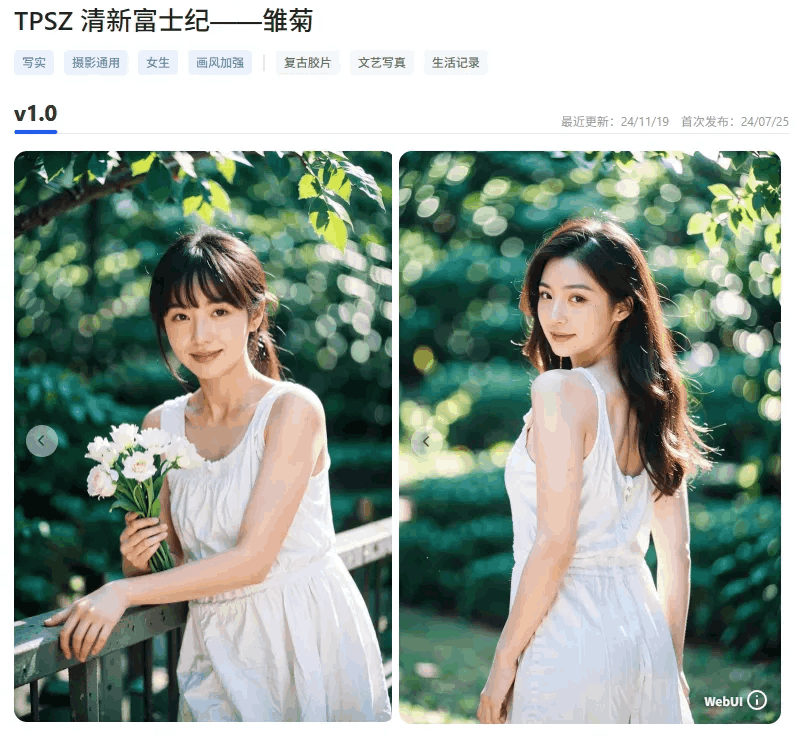
这是我训练的一个SD1.5的LoRA,背景的景深光斑都会打在标签里。当时这个模型参加了lib平台的活动也获了奖。
如今的FLUX大模型,有着优秀的画质和对自然语言的理解能力,让LoRA的质量和泛化性得到跨越式提升,极大拓宽了创作者的表达边界。

这是基于FLUX大模型训练的软糖主体+实景的LoRA,受到了很多朋友的喜欢。也被lib公号推荐。

三.LoRA的训练过程
训练LoRA简单来说就是:构思—训练集—打标—参数设置—测试,这套流程。
拿“童梦拾光”这个模型为例,前期构思:我想要一种柔和、清透、闪耀的氛围。
围绕这个思路,我开始在mj上生成相关的图片(图片集的收集不局限于MJ生成,比如我之前的一个LoRA:“北海道の冬天”,训练图片集来自于我一段时间的摄影图片。在收集素材的过程中大家要注意版权问题,确保我们的训练成果走得更稳更远)。
我用相同的sref和p统一了我整个图片集的风格。有瑕疵的地方,再导入PS里精修。
我认为图片集的质量很重要,想训练出好的效果,一定要在图片集上多花点功夫,本着“宁缺毋滥”的原则来挑选图片,求质不求量。
分享一个小技巧:大部分抽卡图都没那么完美,比如这张素材图,有的手好,有的蝴蝶不错,我们可以在PS里保留每张图可取的部分(我用蒙版擦出保留部分),最后合并到一起再做微调。如果有不协调的地方,再在SD里图生图跑一遍,让其融合的更自然,这样即便不会画画也可快速修改。
我一共挑选了41张图片来训练,尽可能挑选主体、角度、动作、景别多样化的图片,让图片集更加丰富,从而增加模型的泛化性。(比如这个模型中主体有男有女有老人和小孩还有动物;有中景、远景、特写,有侧视、正视、俯视等。
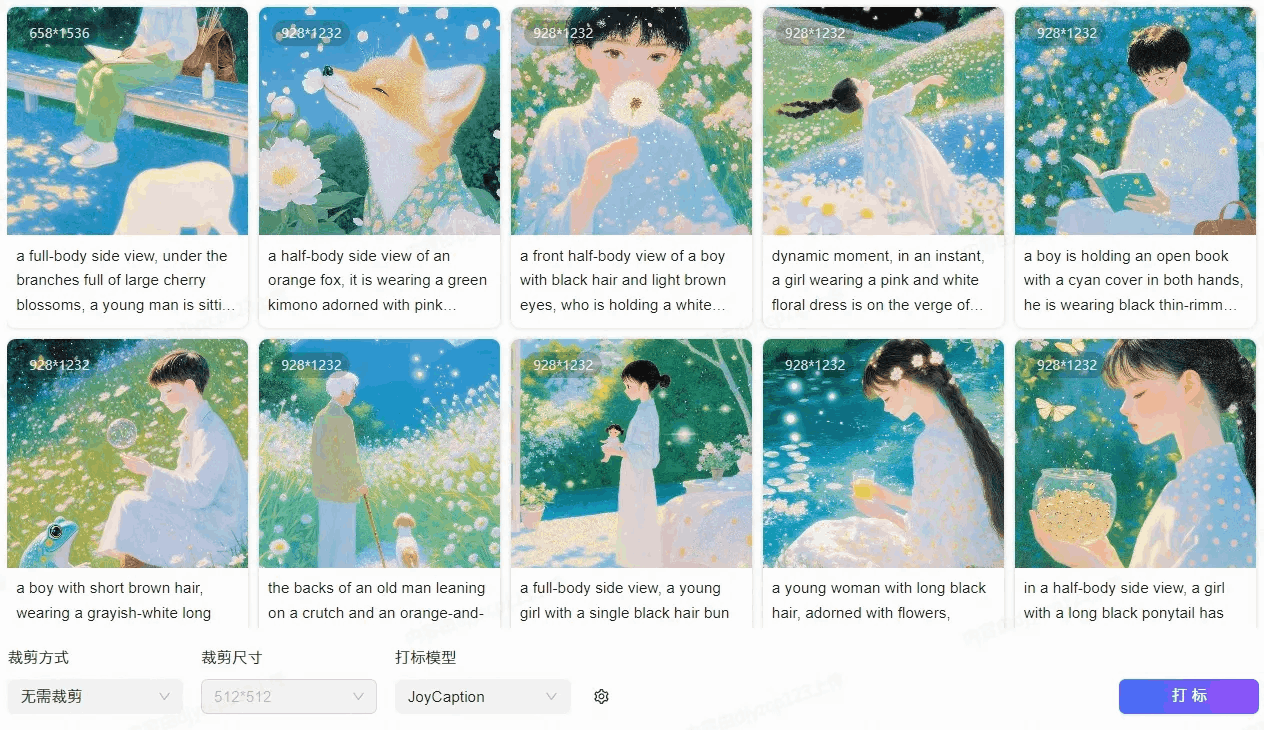
部分训练集素材
接下来我们把图片上传打标。flux大模型对于自然语言的识别非常好,我倾向于自然语言打标。我用的魔搭自带的JoyCaption打标模型,打标长度我选的medium-length。自动打标后导入记事本修改(注意语句尽可能精简,删掉一些形容词堆砌的废话,纠正明显的识别错误,去除掉风格描述。这里分享一个公式:需要什么就去掉什么)。
参数部分,因为每个“丹炉“都有自己脾性,第一次用魔搭丹炉,我是根据以往训练经验,设置了每张图学习15次,一共学习20轮,没两轮保存一个LoRA。我的经验是宁可让它过拟合一点也别欠拟合。如果过拟合,一个是它的整个学习过程都呈现出来,你选择起来更直观,而且过拟合可以调低权重,但要是欠拟合就不好处理了。
这次训练用的是素材集里的一组提示词,方便对照判断学习效果。从训练实时样图来看,第二、四轮明显没有学到原素材图的画风,而且手部都有畸变,大约到第6轮基本就学习到了,但一些细节元素,比如手、背景中的蝴蝶还是有些形状模糊不明。从第八轮开始,第10轮、12轮、14轮、16轮、18轮、20轮看上去都还可以,也就是说,在总步数大概4920步应该就差不多了(后面的xyz测试也印证了我的推测,从12-20效果差别不大,所以如果再次训练同样的LoRA,就可以减少总步数、提升训练效率。)。
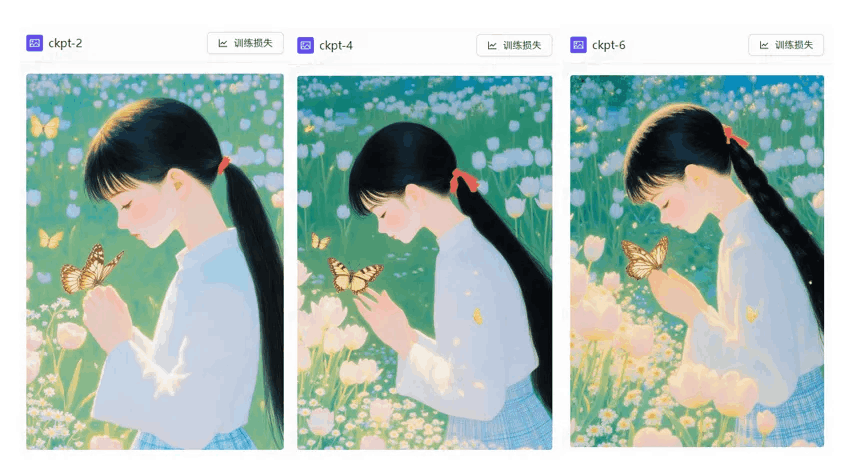
第二轮(ckpt-2)、第四轮(ckpt-4)、第六轮(ckpt-6)的实时样图,第二、四轮明显没有学到原素材图的画风,而且手部都有畸变,大约到第6轮就可以学习到了,但一些细节元素,比如手、背景中的蝴蝶还是有些形状模糊不明。)
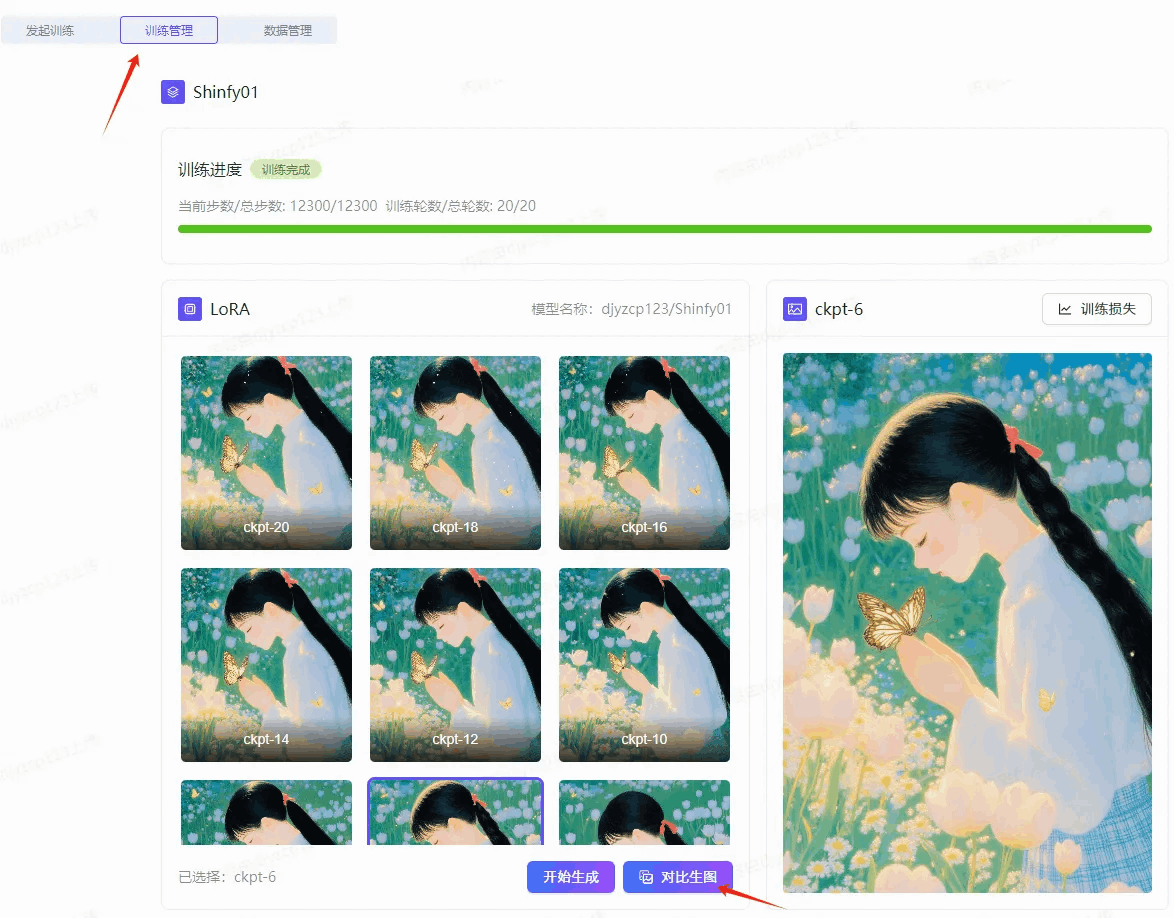
我了解到,大家一般都是用本地部署或者云端部署的SD中的 XYZ Plot 进行模型的测试,可以一键快速查看不同权重、提示词组合下的风格表现,有的小伙伴没这个条件,只能通过实时样图和loss值来估计,如果想要精确些,只能挨个调参数、生图,做大量的测试,非常耗时耗力! 现在,我惊喜的发现在魔搭里也有了XYZ这个功能,具体操作:在“训练管理“,也就是你训练完成的页面里,找到“对比生图“这个按钮点开就可以对LoRA进行各项测试啦~不得不说,真的太方便了!
以下是操作图示:
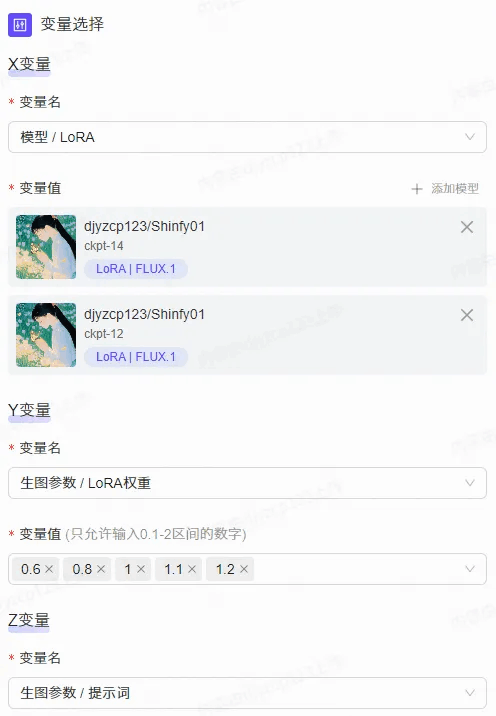
下面是“童梦拾光”这个LoRA详细的测试图表:

本次测试了生成的全部10个LoRA,x轴是LoRA名称(或者轮数),y代表LoRA权重(变量值分别为:0.6,0.8,1,1.1,1.2)。
Prompt:Medium shot, profile view: a woman with long hair cascading down her shoulders, her crimson tresses falling like a smooth waterfall over her back. She holds a small white rabbit in her arms, her gaze gentle and a soft smile gracing her lips. Clad in a pale lavender dress that flutters in the wind, she resembles a blooming flower come to life. The foreground features a field of vibrant lavender in full bloom, while the background showcases an ancient castle, its imposing structure standing as a timeless backdrop to the serene scene.
通过测试分析发现:LoRA2、4、6没有完全学习到我们原素材图的画风,直接pass掉;0.6时欠拟合导致画风偏写实,1.1、1.2时过拟合导致不清晰;权重为“0.8-1”时相对效果最优。其中LoRA12-20效果大同小异。
最终,经过生图测试和仔细比对,我选择了LoRA8,权重:1,它在拟合度、泛化度、清晰度等方面表现相对均衡。

这就是我训练这个模型的整个过程,如果还有什么问题没讲到的也可私聊我。
想起一件事,“童趣的小世界”是我的另一个入围的LoRA,也得到了大家积极的返图,我看到其中有个小伙伴在用这个模型生成绘本,非常有趣,这令我感到很有成就感。这可能也是炼丹的意义之一吧。

四.心得体会
对于想尝试 LoRA 训练的小伙伴,千万不要觉得门槛高。现在线上训练模型已经非常方便了,我们就像搭积木一样,照着步骤来,多实践几次,一定能做出满意的模型。而且以后技术门槛只会越来越低,比技术更重要的是你的创意和审美。就像魔搭举办的这次比赛,平台会给大家提前准备好所需的知识和工具,大家可以更加便捷快速的学习技能,从而把更多精力放在创作本身。
技术的进步不是为了让热爱变得廉价,而是让更多人有机会触摸到创造的温度。
从 Stable Diffusion 开源,到到魔搭平台众多创作者的贡献,再到社区里大家毫无保留的经验交流,我想,正是这些 “开源的星火”,汇聚成了照亮大家前行的温暖火炬。
我的小红书名是:琳的画,一个在 AIGC 世界里追光的创作者。虽然现在粉丝不多,但我始终相信,热爱与分享的力量能让我们相遇。关注我吧!让我们一起聊聊趣事、分享创作心得,在 AIGC 的浩瀚海洋里结伴同行,探索更多可能!
再次感谢魔搭平台和麦乐园,这份认可将激励我继续前行!

ModelScope旨在打造下一代开源的模型即服务共享平台,为泛AI开发者提供灵活、易用、低成本的一站式模型服务产品,让模型应用更简单!
更多推荐



 0
0 0
0- 0



 已为社区贡献629条内容
已为社区贡献629条内容

所有评论(0)