
小语种多模态数据集万卷·丝路2.0开源!ms-swift韩语继续预训练与指令微调教程
上海人工智能实验室发布了全新升级的“万卷·丝路2.0”多语言多模态语料库,在阿语、俄语、韩语、越南语、泰语5个语种基础上,新增塞尔维亚语、匈牙利语、捷克语3个稀缺语料数据,涵盖四大数据模态共计1,15
3月22日,上海人工智能实验室发布了全新升级的“万卷·丝路2.0”多语言多模态语料库,在阿语、俄语、韩语、越南语、泰语5个语种基础上,新增塞尔维亚语、匈牙利语、捷克语3个稀缺语料数据,涵盖四大数据模态共计1,150万条数据。在小语种场景下,利用该语料库对通用大模型进行微调,使轻量化模型在多语言处理领域展现出超越大模型的卓越表现。
数据集地址:https://www.modelscope.cn/collections/wanjuansilu-20-a3d1a96dad6042
一键微调框架:https://github.com/modelscope/ms-swift
数据集介绍
“万卷·丝路2.0”具有多语言、大规模、多模态、高质量的特点:
1. 语种数量扩充:在阿拉伯语、俄语、韩语、越南语、泰语5个语种基础上,新增塞尔维亚语、匈牙利语、捷克语等3个稀缺语料数据。
2. 数据模态、总量全面升级:在纯文本数据基础上,新增图片-文本、音频-文本、视频-文本、特色指令微调SFT四大模态数据,覆盖多模态研究全链路;整体数据总量超过1150万条,音视频时长超过2.6万小时,满足多种研究任务的需求。
3. 超精细数据,多场景适用:经成熟数据生产管线及安全加固,结合过滤算法与当地专家人工精细化地标注质检,“万卷·丝路2.0” 已成为覆盖多模态、多领域的大规模高质量数据集,含20余种细粒度多维分类标签及详细的文本描述,适配文化旅游、商业贸易、科技教育等不同场景,为开发者提供得力助手。
开源内容
图片-文本累计开源超过200W条; 音频-文本开源超过1600小时; 音频-文本开源超过2.5w小时; SFT数据开源18w条;
开源数据详情:
|
语种名称 |
图文模块数据量(张数) |
音频模块时长(小时) |
视频模块时长(小时) |
SFT模块数据量 |
|
阿语 |
220,000 |
200 |
1738 |
23,000 |
|
俄语 |
250,000 |
212 |
3491 |
23,000 |
|
韩语 |
530,000 |
202 |
3412 |
23,000 |
|
越南语 |
450,000 |
205 |
2901 |
23,000 |
|
泰语 |
100,000 |
201 |
5684 |
23,000 |
|
塞尔维亚语 |
80,000 |
206 |
2578 |
23,000 |
|
匈牙利语 |
220,000 |
208 |
3470 |
23,000 |
|
捷克语 |
270,000 |
202 |
2453 |
23,000 |
数据样例
数据集详细介绍及数据样例,请参考这篇👇
https://mp.weixin.qq.com/s/cZ6TiF4tOtSBHONQ5Lsr9A
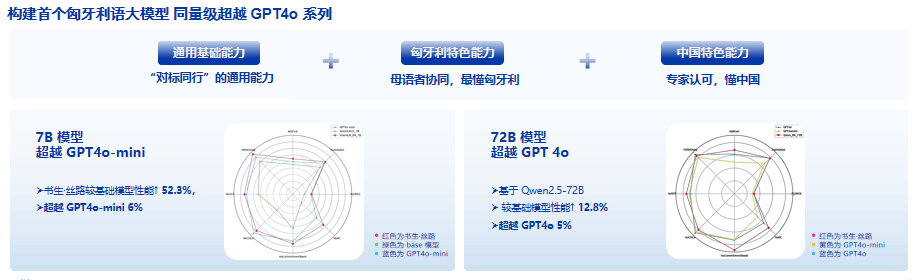
数据集赋能大模型性能跃迁
经严格评测验证,"万卷·丝路"展现出显著的模型赋能效应:基于7B参数基础模型训练,实现综合性能跃升52.3%;在700亿参数的大模型训练中,仍保持12.8%的性能增益。值得注意的是,依托”万卷·丝路”,使轻量化模型在多语言处理领域展现出超越大模型的卓越表现。
我们从“万卷·丝路2.0”多语言多模态语料库中抽取了部分韩语SFT数据,并精心开发了韩语数据集继续预训练与指令微调实践教程。欢迎大家动手实践。
韩语数据集继续预训练与指令微调实践
我们将介绍使用Megatron-SWIFT和ms-swift分别对OpenDataLab/WanJuan-Korean和OpenDataLab/WanJuanSiLu2_sft_ko进行继续预训练和指令微调的实践。
ms-swift是魔搭社区官方提供的大模型与多模态大模型训练部署框架。
ms-swift开源地址:https://github.com/modelscope/ms-swift。
Megatron-SWIFT在ms-swift的基础上引入了Megatron的并行技术来加速大模型的训练,包括数据并行、张量并行、流水线并行、序列并行,上下文并行,具有更快的训练速度。
Megatron-SWIFT文档查看:https://swift.readthedocs.io/zh-cn/latest/Instruction/Megatron-SWIFT训练.html
环境准备
在开始微调之前,请确保您的环境已准备妥当。
git clone https://github.com/modelscope/ms-swift.git
cd ms-swift
pip install -e .使用Megatron-SWIFT对OpenDataLab/WanJuan-Korean数据集进行继续预训练
首先,你需要额外安装Megatron-SWIFT依赖:
pip install pybind11
# transformer_engine
# 若出现安装错误,可以参考该issue解决: https://github.com/modelscope/ms-swift/issues/3793
pip install git+https://github.com/NVIDIA/TransformerEngine.git@stable
# apex
git clone https://github.com/NVIDIA/apex
cd apex
pip install -v --disable-pip-version-check --no-cache-dir --no-build-isolation --config-settings "--build-option=--cpp_ext" --config-settings "--build-option=--cuda_ext" ./当然你也可以直接使用镜像:
modelscope-registry.us-west-1.cr.aliyuncs.com/modelscope-repo/modelscope:ubuntu22.04-cuda12.4.0-py311-torch2.5.1-modelscope1.25.0-swift3.2.2由于数据集很大,这里只下载部分数据集进行训练。
# 下载数据集
mkdir my_dataset
cd my_dataset
wget "https://www.modelscope.cn/datasets/OpenDataLab/WanJuan-Korean/resolve/master/raw/culture/common_crawl/part-677f75d865d8-000260.jsonl.gz"
cd ..关于HF权重格式与mcore格式转换,参考Megatron-SWIFT文档:https://swift.readthedocs.io/zh-cn/latest/Instruction/Megatron-SWIFT%E8%AE%AD%E7%BB%83.html
Megatron-SWIFT训练脚本如下(更快的训练速度):
NPROC_PER_NODE=4 \
CUDA_VISIBLE_DEVICES=0,1,2,3 \
megatron pt \
--load Qwen2.5-7B-mcore \
--dataset './my_dataset' \
--tensor_model_parallel_size 4 \
--micro_batch_size 1 \
--global_batch_size 8 \
--packing true \
--recompute_granularity selective \
--train_iters 10000 \
--eval_iters 50 \
--finetune true \
--cross_entropy_loss_fusion true \
--lr 1e-5 \
--streaming true \
--lr_warmup_iters 100 \
--min_lr 1e-6 \
--save megatron_output/Qwen2.5-7B \
--eval_interval 500 \
--save_interval 500 \
--max_length 8192 \
--num_workers 8 \
--dataset_num_proc 8 \
--no_save_optim true \
--no_save_rng true \
--sequence_parallel true \
--use_flash_attn true训练显存资源:

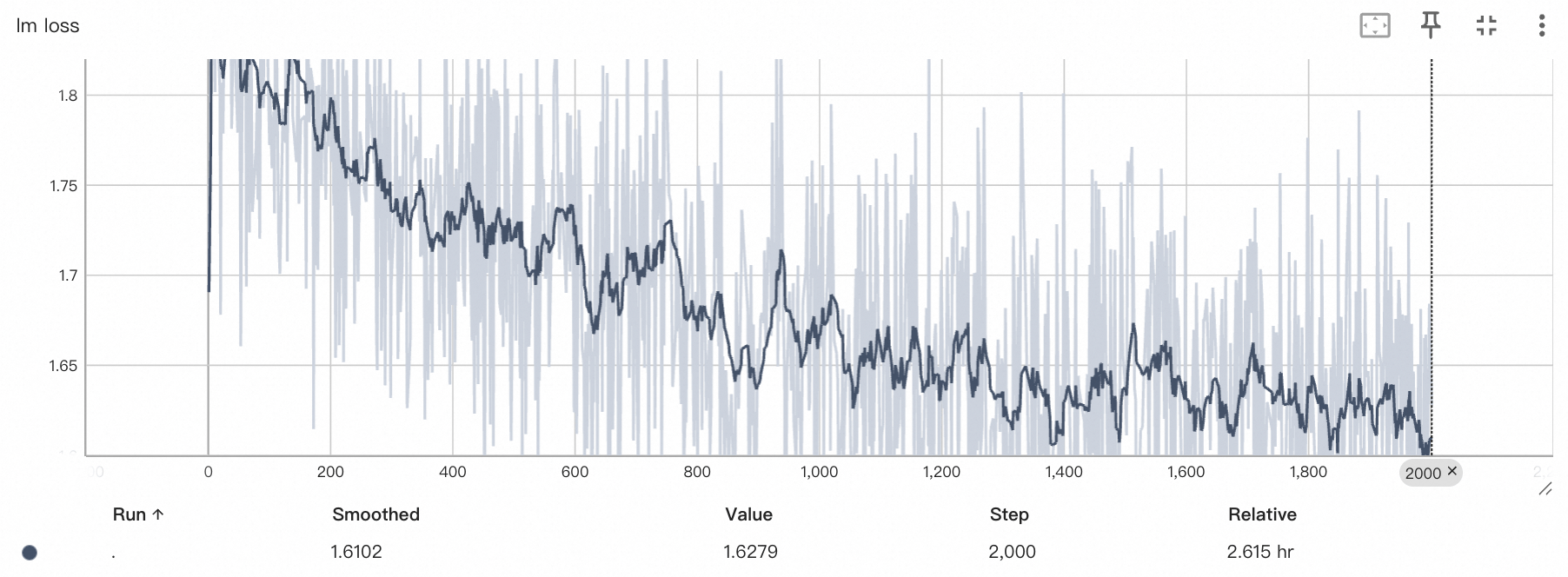
训练loss曲线:
使用ms-swift对OpenDataLab/WanJuanSiLu2_sft_ko数据集进行指令微调
NPROC_PER_NODE=4 \
CUDA_VISIBLE_DEVICES=0,1,2,3 \
swift sft \
--model Qwen/Qwen2.5-7B \
--train_type full \
--dataset OpenDataLab/WanJuanSiLu2_sft_ko \
--torch_dtype bfloat16 \
--max_steps 2000 \
--streaming true \
--per_device_train_batch_size 1 \
--per_device_eval_batch_size 1 \
--learning_rate 1e-5 \
--gradient_accumulation_steps 2 \
--packing true \
--eval_steps 200 \
--save_steps 200 \
--logging_steps 5 \
--max_length 8192 \
--warmup_ratio 0.05 \
--dataloader_num_workers 8 \
--dataset_num_proc 8 \
--save_total_limit 2 \
--save_only_model true \
--output_dir output/Qwen2.5-7B \
--deepspeed zero3 \
--attn_impl flash_attn效果评估
目前主流的大语言模型大多具备多语言能力,在多种不同语言上都展现出了强大的生成能力。目前评估多语言任务效果的数据集有以下几个:
-
belebele数据集:仅关注多项选择形式的阅读理解。
-
BenchMAX数据集:关注大模型的核心性能,这些能力包括但不限于指令遵循能力、推理能力、长文本理解能力、代码生成能力、工具使用能力以及翻译能力。
BenchMAX是一个包含多语言,覆盖多种重要任务和17种多样化的语言的评测基准。对于每个能力,BenchMAX包含了一至两个不同的测试集,并且绝大多数测试集都经过母语使用者的标注,保证了数据集的高质量。
论文地址:https://arxiv.org/pdf/2502.07346
数据集地址:https://huggingface.co/collections/LLaMAX/benchmax-674d7a815a57baf97b5539f4Github地址:https://github.com/CONE-MT/BenchMAX
引用: @article{huang2025benchmax, title={BenchMAX: A Comprehensive Multilingual Evaluation Suite for Large Language Models}, author={Huang, Xu and Zhu, Wenhao and Hu, Hanxu and He, Conghui and Li, Lei and Huang, Shujian and Yuan, Fei}, journal={arXiv preprint arXiv:2502.07346}, year={2025} }
诚邀您扫码提交"万卷·丝路"数据集使用反馈。您的建议将支持"万卷·丝路"多语言多模态语料库成为更质量的AI基础设施,助力全球开发者构建跨语言智能工具与应用,以人工智能赋能高质量共建“一带一路”。

您的邮箱:xxx@google.com
模型类型: Llama-3.1-8B-Instruct
训练的数据及量级:韩语指令微调数据18w
改进效果: 韩语阅读理解任务指标提升2个点
数据需求:增加商贸领域的韩语SFT数据;扩增商品场景的韩语视觉文本SFT数据更多交流请添加小助手微信获取更多高质量、大规模、安全可信的数据集沟通更多关于数据集的合作事项👇


ModelScope旨在打造下一代开源的模型即服务共享平台,为泛AI开发者提供灵活、易用、低成本的一站式模型服务产品,让模型应用更简单!
更多推荐



 0
0 0
0- 0



 已为社区贡献633条内容
已为社区贡献633条内容

所有评论(0)