
小米又放大招!MiMo-VL 多模态大模型开源,魔搭推理微调全面解读来了!
今天,小米开源发布两款 7B 规模视觉-语言模型 MiMo-VL-7B-SFT 和 MiMo-VL-7B-RL。
01.引言
今天,小米开源发布两款 7B 规模视觉-语言模型 MiMo-VL-7B-SFT 和 MiMo-VL-7B-RL。
MiMo-VL-7B的模型架构为:
① 保持细粒度视觉细节的原生分辨率ViT编码器
② 用于高效跨模态对齐的MLP projector
③ 专为复杂推理任务优化的MiMo-7B语言模型
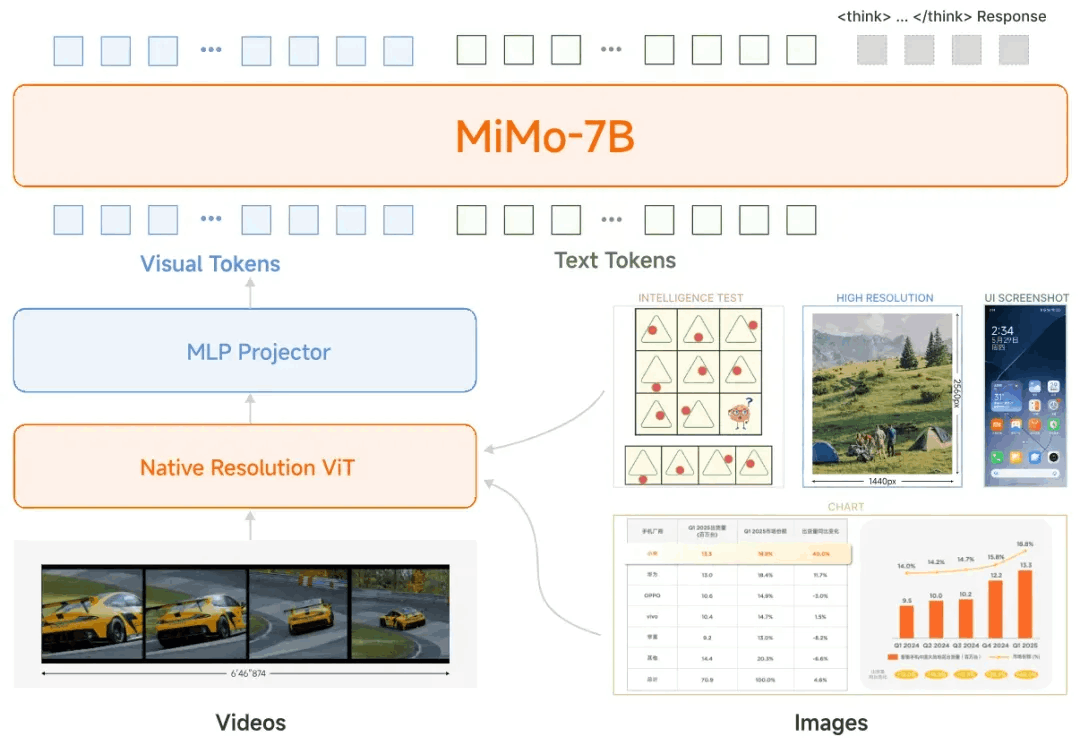
MiMo-VL-7B的开发涉及两个连续的训练过程:
1、预训练阶段
数据规模:
总计约 2.4 万亿 tokens,涵盖图像描述、文本-图像交错、OCR/定位、视频、GUI 操作与合成推理数据等多模态语料。
阶段划分:
- Projector预热:仅训练Project head,使用图文对齐数据。
- 视觉-语言对齐:解冻 ViT;引入混合网页、书籍等交错数据。
- 通用多模态预训练:全面开放所有组件,加入 OCR、定位、视频与 GUI 数据,并少量引入推理与指令数据。
- 长上下文微调:将最大序列长度扩展至 32K,引入更长文本、视频与高分辨率图像,提高长上下文与深度推理能力。
2、后训练阶段
在此阶段研究团队引入了混合在线强化学习(MORL),这是一种新颖的框架,能够无缝集成涵盖感知准确性、视觉基础精度、逻辑推理能力和人机偏好的多种奖励信号。具体步骤如下:
-RLVR 部分:设计视觉推理、文本推理、图像/GUI 定位、视觉计数与视频时序定位等可规则化验证的奖励函数,实现自动打分与反馈。
-RLHF 部分:构建双模态与文本奖励模型,经 GPT-4o 排序标注,保证生成结果符合人类偏好并降低有害输出。
-混合在线策略:基于 GRPO 的全在线变体,统一通过 Reward-as-a-Service 提供低延迟多任务奖励,消除 KL 惩罚以提升训练稳定性。
研究团队开源了MiMo-VL-7B系列,包括SFT和RL模型的CheckPoint。 研究团队相信这份报告连同这些模型将为开发强大推理能力的VLM提供宝贵的见解,从而惠及更广泛的社区。
模型链接:
https://modelscope.cn/collections/MiMo-VL-bb651017e02742
代码仓库:
https://github.com/XiaomiMiMo/MiMo-VL
技术报告:
https://github.com/XiaomiMiMo/MiMo-VL/blob/main/MiMo-VL-Technical-Report.pdf
🛤️ 在这个过程中,研究团队发现在预训练阶段纳入高质量、广泛覆盖的推理数据对于提升模型性能至关重要
- 研究团队通过识别多样化的查询,使用大型推理模型重新生成带有长CoT的响应,并应用拒绝采样以确保质量,从而策划高质量的推理数据。
- 研究团队将大量这种合成推理数据直接纳入后期预训练阶段,而不是将其视为补充微调数据。延长训练时间可以持续提高性能而不会饱和。
混合在线策略强化学习进一步增强了模型性能,但同时实现稳定改进仍然具有挑战性
- 研究团队在多种能力上应用RL,包括推理、感知、接地和人类偏好对齐,涵盖文本、图像和视频等多种模态。虽然这种混合训练方法进一步释放了模型的潜力,但跨数据域的干扰仍然是一个挑战。
02.模型评估
通用能力
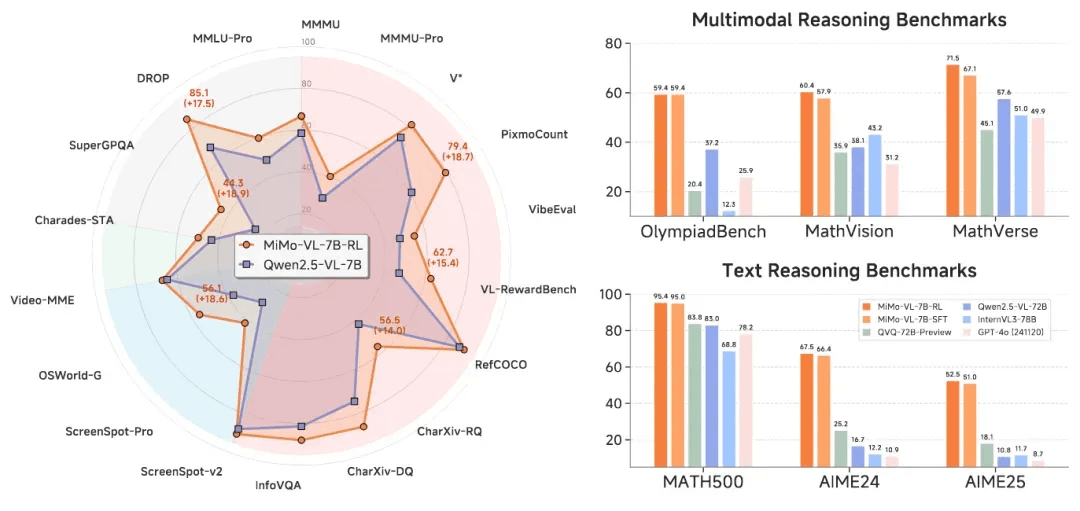
在通用视觉语言理解中,MiMo-VL-7B 达到了当前开源模型性能的SOTA水平
推理任务
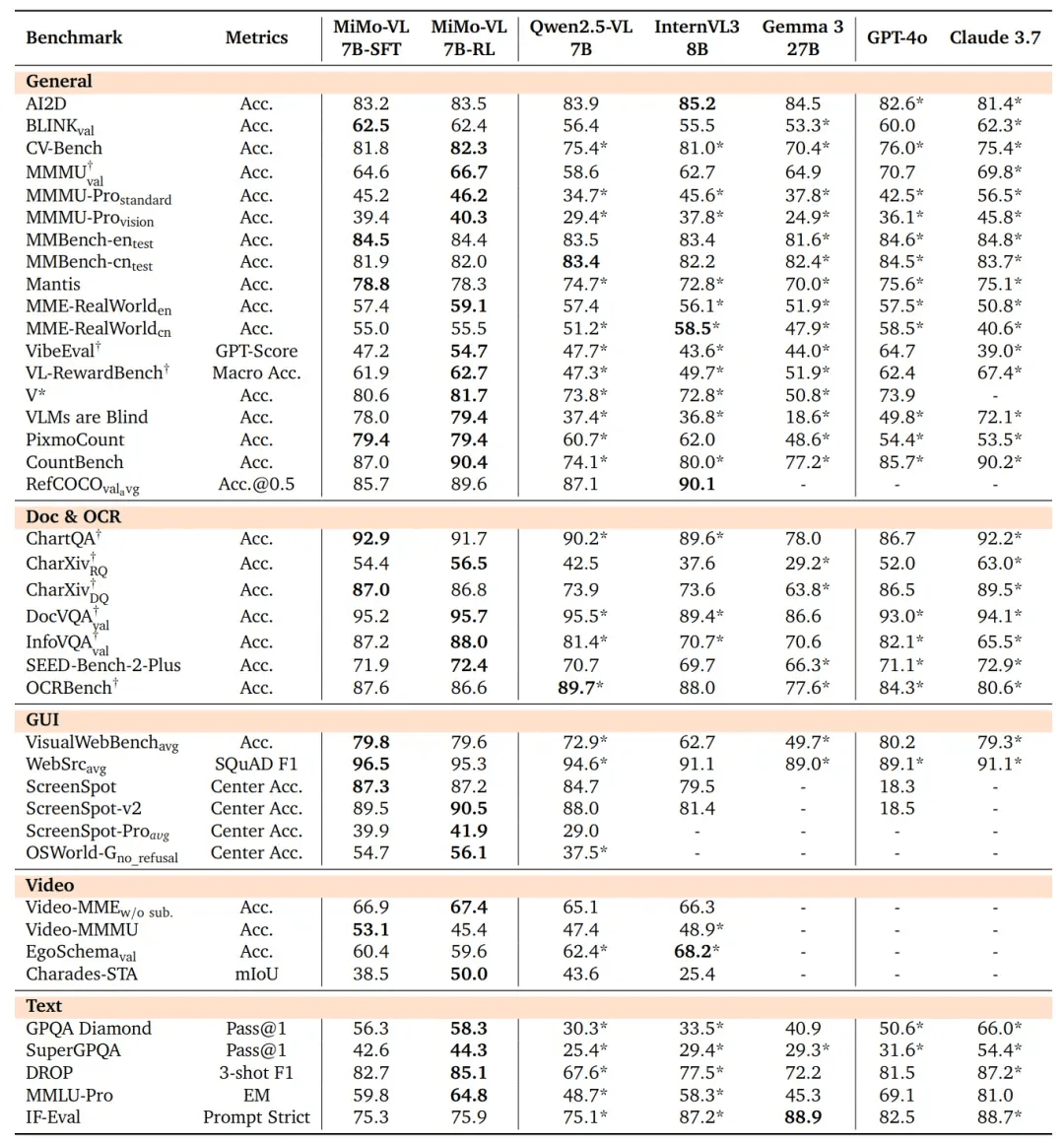
在多模态推理中,SFT和RL模型在这几个基准测试中都显著优于所有比较的开源基线。
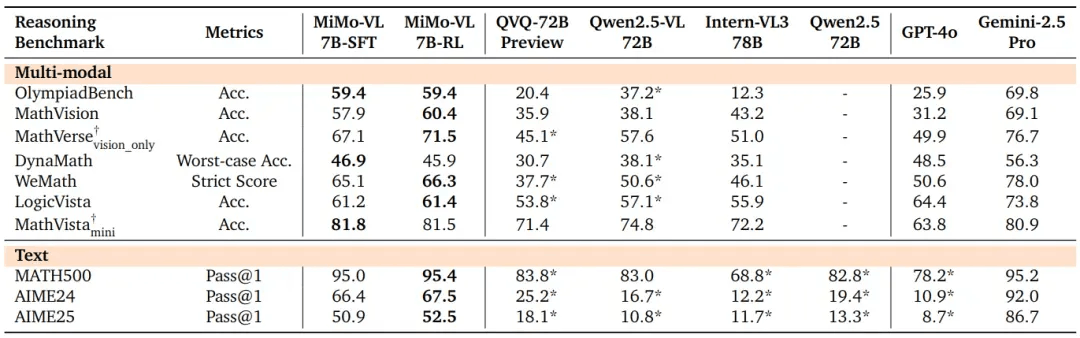
标有 * 的结果是使用研究团队的评估框架获得的。 带有 †{\dagger}† 的任务由 GPT-4o 评估。
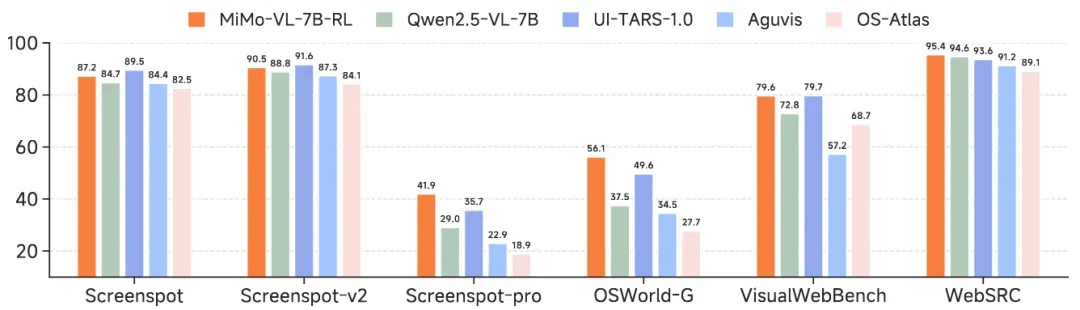
GUI 任务
MiMo-VL-7B-RL 具备卓越的 GUI 理解和定位能力。作为一个通用的视觉语言模型,MiMo-VL 在性能上与专门针对 GUI 的模型相当,甚至更优。
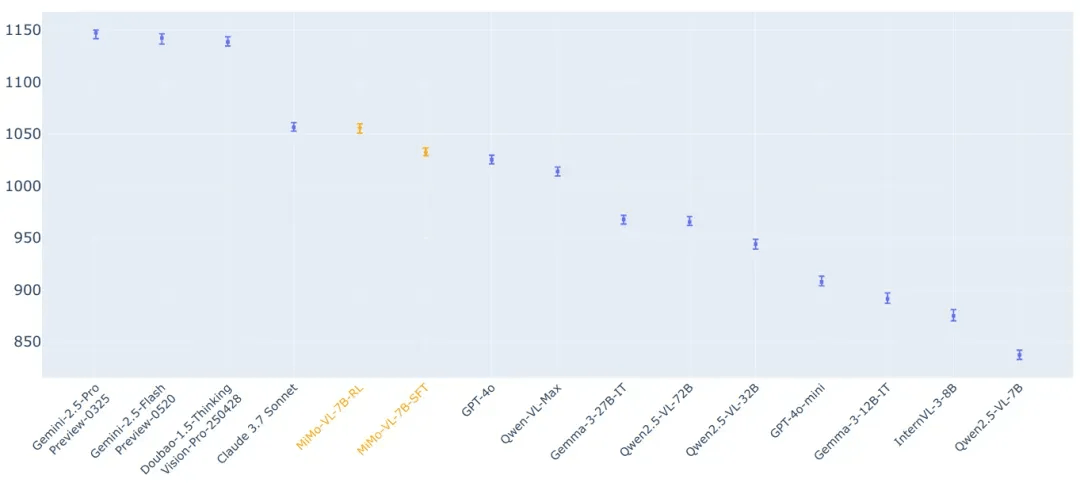
Elo 评分
通过研究团队内部的评估数据集和 GPT-4o 的评判,MiMo-VL-7B-RL 在所有被评估的开源视觉语言模型中获得了最高的 Elo 评分,在从 7B 到 72B 参数范围内的模型中排名第一。
03.模型推理
MiMo-VL-7B 系列在部署和推理时完全兼容 Qwen2_5_VLForConditionalGeneration 架构。
使用transformers推理
from modelscope import Qwen2_5_VLForConditionalGeneration, AutoTokenizer, AutoProcessor
from qwen_vl_utils import process_vision_info
# default: Load the model on the available device(s)
model = Qwen2_5_VLForConditionalGeneration.from_pretrained(
"XiaomiMiMo/MiMo-VL-7B-SFT", torch_dtype="auto", device_map="auto"
)
# default processer
processor = AutoProcessor.from_pretrained("XiaomiMiMo/MiMo-VL-7B-SFT")
messages = [
{
"role": "user",
"content": [
{
"type": "image",
"image": "https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen-VL/assets/demo.jpeg",
},
{"type": "text", "text": "Describe this image."},
],
}
]
# Preparation for inference
text = processor.apply_chat_template(
messages, tokenize=False, add_generation_prompt=True
)
image_inputs, video_inputs = process_vision_info(messages)
inputs = processor(
text=[text],
images=image_inputs,
videos=video_inputs,
padding=True,
return_tensors="pt",
)
inputs = inputs.to("cuda")
# Inference: Generation of the output
generated_ids = model.generate(**inputs, max_new_tokens=128)
generated_ids_trimmed = [
out_ids[len(in_ids) :] for in_ids, out_ids in zip(inputs.input_ids, generated_ids)
]
output_text = processor.batch_decode(
generated_ids_trimmed, skip_special_tokens=True, clean_up_tokenization_spaces=False
)
print(output_text)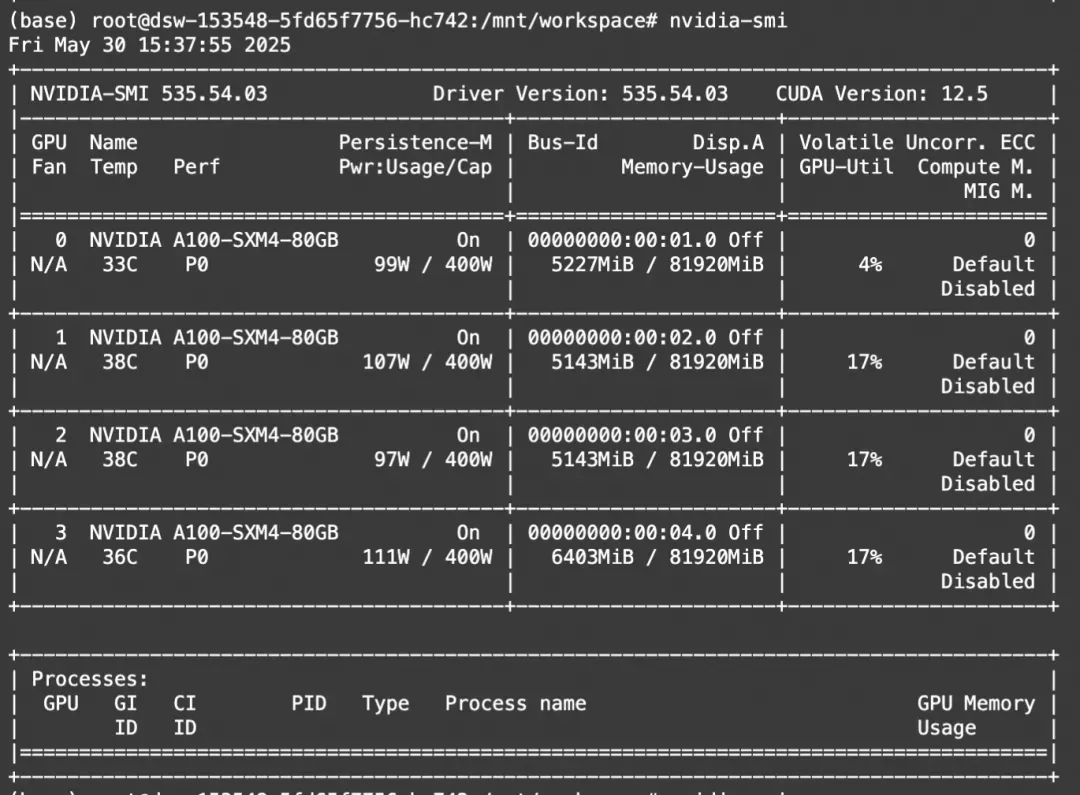
04.模型微调
我们介绍使用ms-swift对XiaomiMiMo/MiMo-VL-7B-RL进行微调。ms-swift是魔搭社区官方提供的大模型与多模态大模型训练部署框架。
ms-swift开源地址:
https://github.com/modelscope/ms-swift
我们将展示可运行的微调demo,并给出自定义数据集的格式。
在开始微调之前,请确保您的环境已准备妥当。
git clone https://github.com/modelscope/ms-swift.git
cd ms-swift
pip install -e .
pip install "transformers<4.52" liger_kernel -U图像OCR微调脚本如下。更多任务可以参考这里:https://github.com/modelscope/ms-swift/tree/main/examples/train/multimodal
MAX_PIXELS=1003520 \
CUDA_VISIBLE_DEVICES=0 \
swift sft \
--model XiaomiMiMo/MiMo-VL-7B-RL \
--dataset AI-ModelScope/LaTeX_OCR:human_handwrite#20000 \
--train_type lora \
--torch_dtype bfloat16 \
--num_train_epochs 2 \
--per_device_train_batch_size 16 \
--per_device_eval_batch_size 16 \
--learning_rate 1e-4 \
--lora_rank 8 \
--lora_alpha 32 \
--target_modules all-linear \
--freeze_vit true \
--gradient_accumulation_steps 1 \
--eval_steps 50 \
--save_steps 50 \
--save_total_limit 2 \
--logging_steps 5 \
--max_length 2048 \
--output_dir output \
--warmup_ratio 0.05 \
--padding_free true \
--attn_impl flash_attn \
--use_liger_kernel true \
--dataloader_num_workers 4训练显存资源:
![]()
自定义数据集格式如下(system字段可选),只需要指定`--dataset <dataset_path>`即可:
{"messages": [{"role": "user", "content": "浙江的省会在哪?"}, {"role": "assistant", "content": "浙江的省会在杭州。"}]}
{"messages": [{"role": "user", "content": "<image><image>两张图片有什么区别"}, {"role": "assistant", "content": "前一张是小猫,后一张是小狗"}], "images": ["/xxx/x.jpg", "/xxx/x.png"]}训练完成后,使用以下命令对训练时的验证集进行推理:
CUDA_VISIBLE_DEVICES=0 \
swift infer \
--adapters output/vx-xxx/checkpoint-xxx \
--stream false \
--max_batch_size 1 \
--load_data_args true \
--max_new_tokens 2048推送模型到ModelScope:
CUDA_VISIBLE_DEVICES=0 \
swift export \
--adapters output/vx-xxx/checkpoint-xxx \
--push_to_hub true \
--hub_model_id '<your-model-id>' \
--hub_token '<your-sdk-token>'点击阅读原文,即可跳转模型~

ModelScope旨在打造下一代开源的模型即服务共享平台,为泛AI开发者提供灵活、易用、低成本的一站式模型服务产品,让模型应用更简单!
更多推荐



 0
0 0
0- 0



 已为社区贡献652条内容
已为社区贡献652条内容

所有评论(0)