
字节Seed开源统一多模态理解和生成模型 BAGEL!
近期,字节跳动Seed推出了 BAGEL—— 一个开源的多模态理解和生成础模型,具有70亿个激活参数(总共140亿个),并在大规模交错多模态数据上进行训练。
01.前言

近期,字节跳动Seed推出了 BAGEL—— 一个开源的多模态理解和生成础模型,具有70亿个激活参数(总共140亿个),并在大规模交错多模态数据上进行训练。BAGEL 在标准多模态理解排行榜上超越了当前顶级的开源VLMs,如Qwen2.5-VL和InternVL-2.5,并且提供了与强大的专业生成器如SD3竞争的文本到图像质量。
此外,BAGEL 在经典的图像编辑场景中展示了比领先的开源模型更好的定性结果。更重要的是,它扩展到了自由形式的视觉操作、多视图合成和世界导航,这些能力构成了超出以往图像编辑模型范围的“世界建模”任务。

Github:
https://github.com/bytedance-seed/BAGEL
模型:
https://www.modelscope.cn/models/ByteDance-Seed/BAGEL-7B-MoT
论文:
https://arxiv.org/abs/2505.14683
02.方法
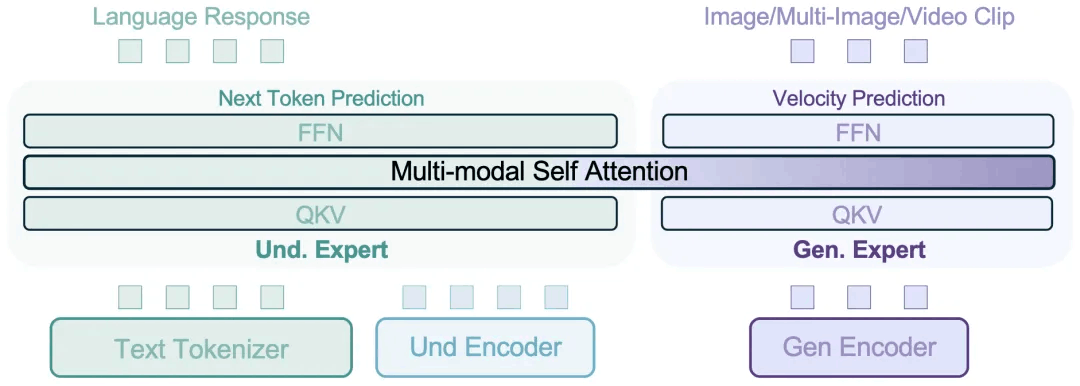
BAGEL 采用了一种混合变压器专家(MoT)架构,以最大化模型从丰富多样的多模态信息中学习的能力。遵循同样的容量最大化原则,它利用两个独立的编码器来捕捉图像的像素级和语义级特征。整个框架遵循下一个令牌组预测范式,其中模型被训练为将下一组语言或视觉令牌作为压缩目标进行预测。
BAGEL 通过在数万亿交织的多模态令牌上进行预训练、继续训练和监督微调,扩展了 MoT 的能力,这些令牌涵盖了语言、图像、视频和网络数据。它在标准的理解和生成基准测试中超越了开放模型,并展示了先进的上下文多模态能力,如自由形式的图像编辑、未来帧预测、3D 操作、世界导航和序列推理。
03.涌现特性
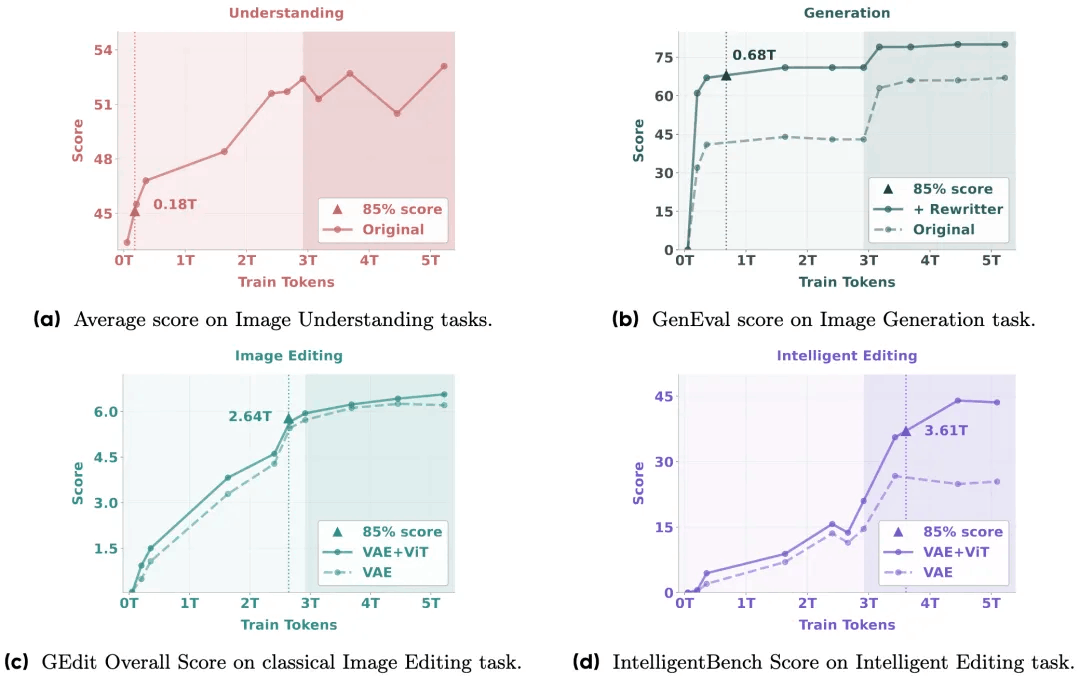
随着研究团队在BAGEL预训练中引入更多多模态标记,观察到模型在理解、生成和编辑任务上呈现持续性能提升。不同能力在不同训练阶段涌现:多模态理解与生成能力早期显现,基础编辑能力随后出现,而复杂的智能编辑能力则后期形成。这种阶段性进展表明存在涌现模式——高级多模态推理能力建立在完善的基础技能之上。
消融研究表明,结合 VAE 和 ViT 特征显著提高了智能编辑,强调了视觉-语义上下文在实现复杂多模态推理中的重要性,并进一步支持其在高级能力出现中的作用。
04.基准测试
1. 视觉理解
|
模型 |
MME ↑ |
MMBench ↑ |
MMMU ↑ |
MM-Vet ↑ |
MathVista ↑ |
|
Janus-Pro-7B |
- |
79.2 |
41.0 |
50.0 |
– |
|
Qwen2.5-VL-7B |
2347 |
83.5 |
58.6 |
67.1 |
68.2 |
|
BAGEL |
2388 |
85.0 |
55.3 |
67.2 |
73.1 |
2. 文本到图像生成 · GenEval
|
模型 |
总体 ↑ |
|
FLUX-1-dev |
0.82 |
|
SD3-Medium |
0.74 |
|
Janus-Pro-7B |
0.80 |
|
BAGEL |
0.88 |
3. 图像编辑
|
模型 |
GEdit-Bench-EN (SC) ↑ |
GEdit-Bench-EN (PQ) ↑ |
GEdit-Bench-EN (O) ↑ |
IntelligentBench ↑ |
|
Step1X-Edit |
7.09 |
6.76 |
6.70 |
14.9 |
|
Gemini-2-exp. |
6.73 |
6.61 |
6.32 |
57.6 |
|
BAGEL |
7.36 |
6.83 |
6.52 |
44.0 |
|
BAGEL+CoT |
– |
– |
– |
55.3 |
05.模型使用
1. 下载代码仓库,并安装依赖
git clone https://github.com/bytedance-seed/BAGEL.git
cd BAGEL
pip install -r requirements.txt2. 下载模型
modelscope download ByteDance-Seed/BAGEL-7B-MoT --local_dir ./models/BAGEL-7B-MoT/3. 开启WebUI
pip install gradio
python app.py显存占用:
点击阅读原文,即可跳转模型~

ModelScope旨在打造下一代开源的模型即服务共享平台,为泛AI开发者提供灵活、易用、低成本的一站式模型服务产品,让模型应用更简单!
更多推荐



 0
0 0
0- 0



 已为社区贡献662条内容
已为社区贡献662条内容

所有评论(0)