
全新GLM模型登场:9B/32B系列模型全面开源,性能媲美顶尖选手,MIT协议商用无忧!
模型介绍
智谱开源 32B/9B 系列 GLM 模型,涵盖基座、推理、沉思模型,均遵循 MIT 许可协议。该系列模型现已发布魔搭社区。其中,推理模型 GLM-Z1-32B-0414 性能媲美 DeepSeek-R1 等顶尖模型,实测推理速度可达 200 Tokens/秒。
模型链接:https://modelscope.cn/collections/GLM-4-0414-e4ecc89c179d4c
本次开源的所有模型均采用宽松的 MIT 许可协议。这意味着可以免费用于商业用途、自由分发,为开发者提供了极大的使用和开发自由度。开源了 9B 和 32B 两种尺寸的模型,包括基座模型、推理模型和沉思模型,具体信息如下:
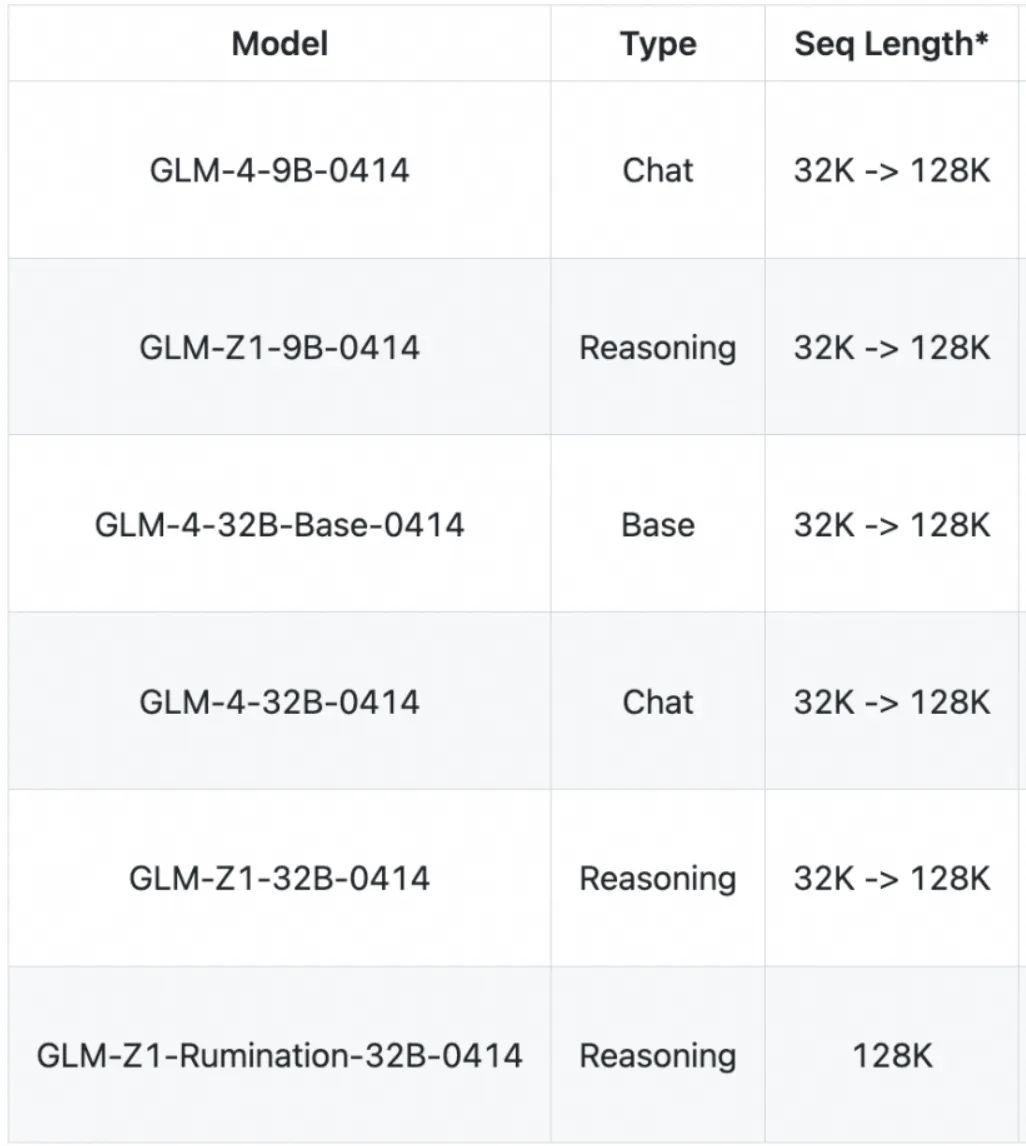
模型链接:https://modelscope.cn/collections/GLM-4-0414-e4ecc89c179d4c
体验页面:https://modelscope.cn/studios/ZhipuAI/GLM-Z1-9B-0414 (小程序)
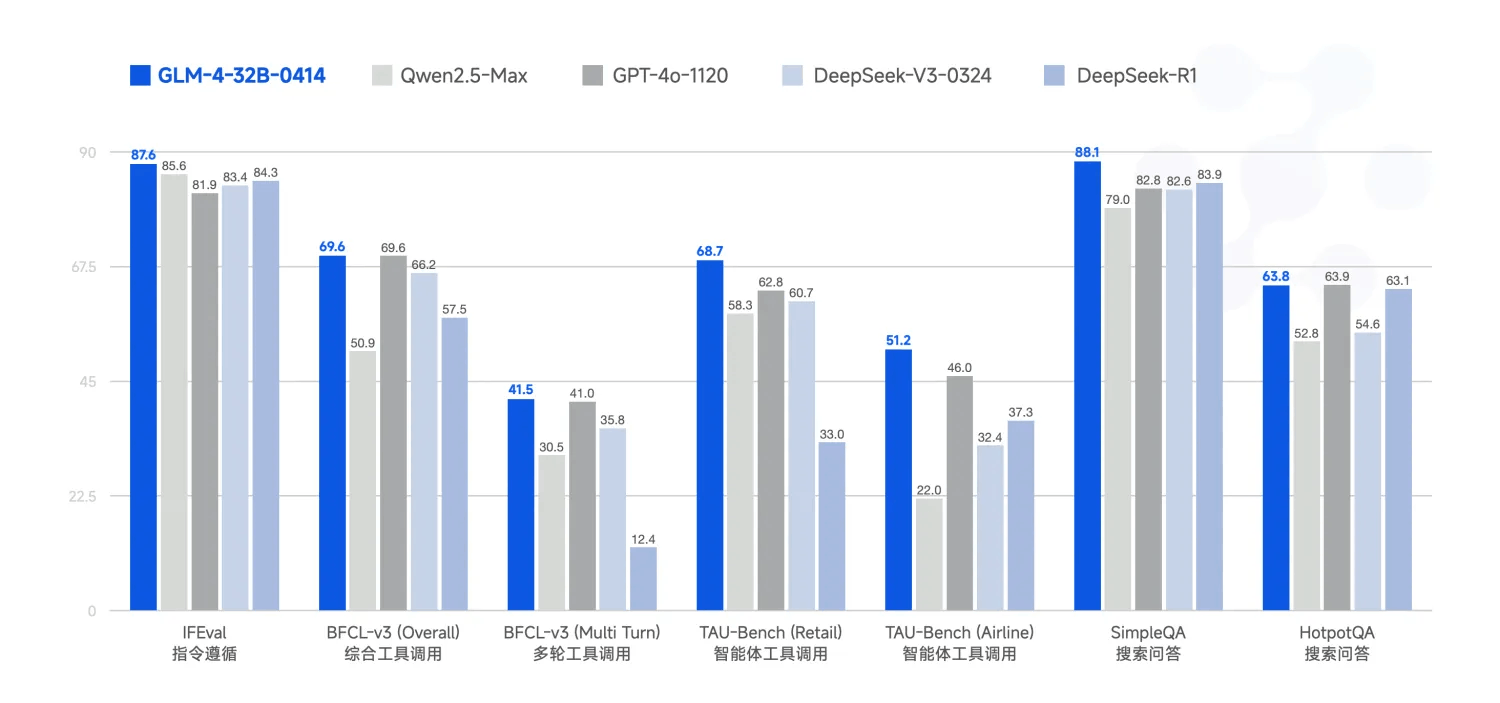
基座模型 GLM-4-32B-0414 拥有 320 亿参数,其性能可与国内、外参数量更大的主流模型相媲美。该模型利用 15T 高质量数据进行预训练,特别纳入了丰富的推理类合成数据,为后续的强化学习扩展奠定了基础。在后训练阶段,除了进行面向对话场景的人类偏好对齐,研究团队还通过拒绝采样和强化学习等技术,重点增强了模型在指令遵循、工程代码生成、函数调用等任务上的表现,以强化智能体任务所需的原子能力。
GLM-4-32B-0414 在工程代码、Artifacts 生成、函数调用、搜索问答及报告撰写等任务上均表现出色,部分 Benchmark 指标已接近甚至超越 GPT-4o、DeepSeek-V3-0324(671B)等更大模型的水平。
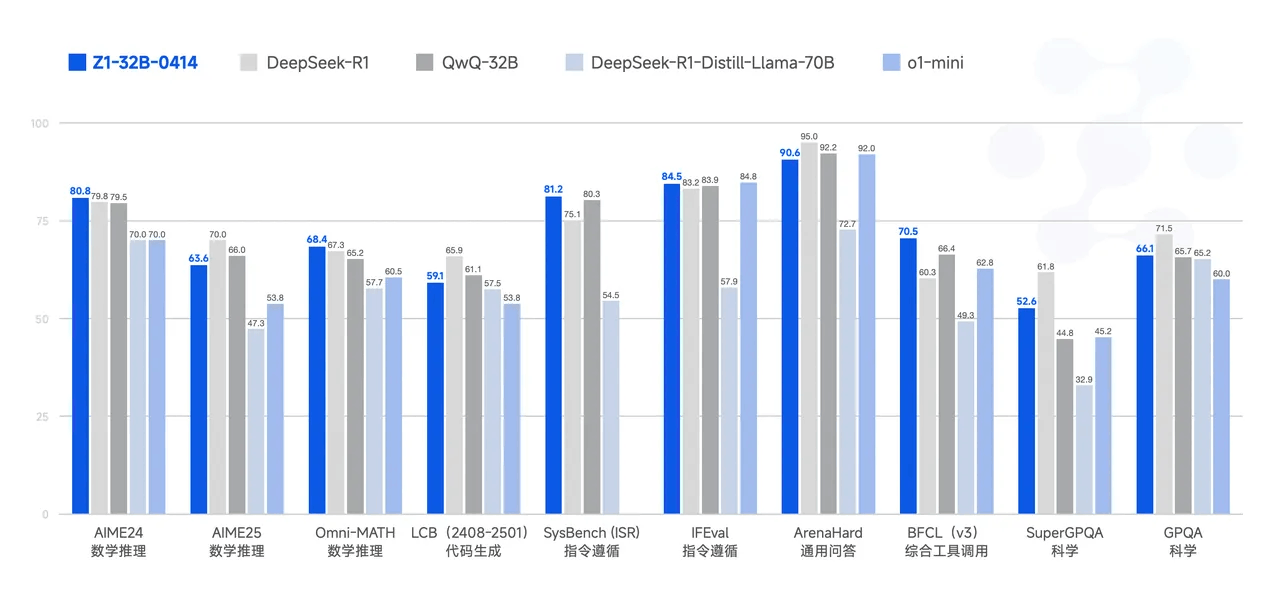
GLM-Z1-32B-0414 是一款具备深度思考能力的推理模型。该模型在 GLM-4-32B-0414 的基础上,采用了冷启动与扩展强化学习策略,并针对数学、代码、逻辑等关键任务进行了深度优化训练。与基础模型相比,GLM-Z1-32B-0414 的数理能力和复杂问题解决能力得到显著增强。此外,训练中整合了基于对战排序反馈的通用强化学习技术,有效提升了模型的通用能力。
在部分任务上,GLM-Z1-32B-0414 凭借 32B 参数,其性能已能与拥有 671B 参数的 DeepSeek-R1 相媲美。通过在 AIME 24/25、LiveCodeBench、GPQA 等基准测试中的评估,GLM-Z1-32B-0414 展现了较强的数理推理能力,能够支持解决更广泛复杂任务。
模型推理
transformers
源码安装
pip install git+https://github.com/huggingface/transformers.git模型推理
from modelscope import AutoModelForCausalLM, AutoTokenizer
MODEL_PATH = "ZhipuAI/GLM-4-Z1-Rumination-32B-0414"
tokenizer = AutoTokenizer.from_pretrained(MODEL_PATH)
model = AutoModelForCausalLM.from_pretrained(MODEL_PATH, device_map="auto")
message = [{"role": "user", "content": "Let a, b be positive real numbers such that ab = a + b + 3. Determine the range of possible values for a + b."}]
inputs = tokenizer.apply_chat_template(
message,
return_tensors="pt",
add_generation_prompt=True,
return_dict=True,
).to(model.device)
generate_kwargs = {
"input_ids": inputs["input_ids"],
"attention_mask": inputs["attention_mask"],
"max_new_tokens": 128,
"do_sample": False,
}
out = model.generate(**generate_kwargs)
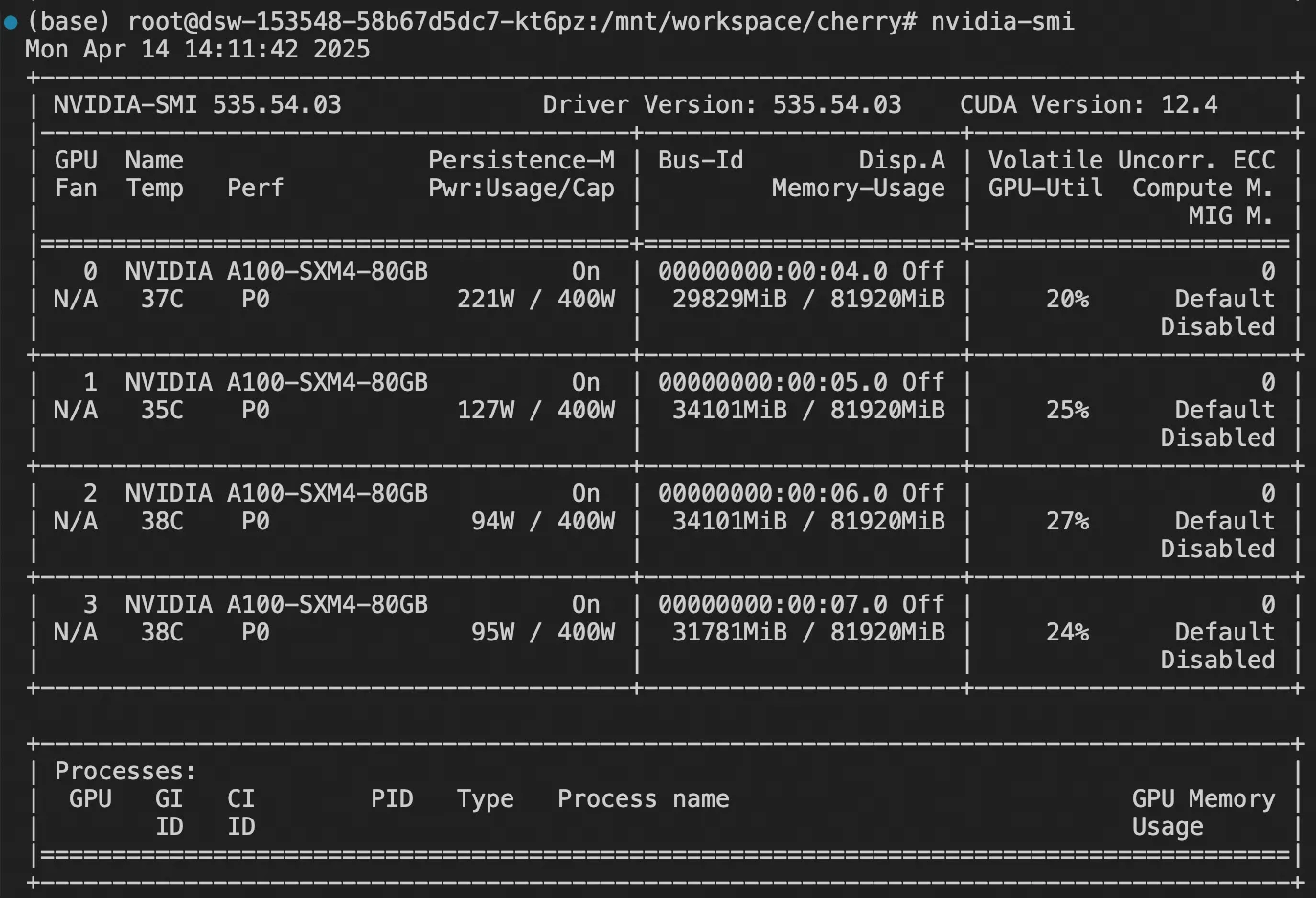
print(tokenizer.decode(out[0][inputs["input_ids"].shape[1]:], skip_special_tokens=True))显存占用:
模型微调
ms-swift已经支持了GLM4-0414系列模型的微调。ms-swift是魔搭社区官方提供的大模型与多模态大模型训练部署框架。ms-swift开源地址:https://github.com/modelscope/ms-swift
我们将展示可运行的微调demo,并给出自定义数据集的格式。
在开始微调之前,请确保您的环境已准备妥当。
# pip install git+https://github.com/modelscope/ms-swift.git
git clone https://github.com/modelscope/ms-swift.git
cd ms-swift
pip install -e .以GLM-4-9B-Chat-0414模型为例,使用文本数据集进行训练
CUDA_VISIBLE_DEVICES=0 \
swift sft \
--model ZhipuAI/GLM-4-9B-Chat-0414 \
--train_type lora \
--dataset 'AI-ModelScope/alpaca-gpt4-data-zh#5000' \
'AI-ModelScope/alpaca-gpt4-data-en#5000' \
--torch_dtype bfloat16 \
--num_train_epochs 1 \
--per_device_train_batch_size 1 \
--per_device_eval_batch_size 1 \
--learning_rate 1e-4 \
--lora_rank 8 \
--lora_alpha 32 \
--target_modules all-linear \
--gradient_accumulation_steps 16 \
--eval_steps 50 \
--save_steps 50 \
--save_total_limit 5 \
--logging_steps 5 \
--max_length 2048 \
--output_dir output \
--warmup_ratio 0.05 \
--dataloader_num_workers 4训练显存占用:

如果要使用自定义数据集进行训练,你可以参考以下格式,并指定`--dataset <dataset_path>`。
{"messages": [{"role": "user", "content": "浙江的省会在哪?"}, {"role": "assistant", "content": "浙江的省会在杭州。"}]}训练完成后,使用以下命令对训练后的权重进行推理,这里的`--adapters`需要替换成训练生成的last checkpoint文件夹。
CUDA_VISIBLE_DEVICES=0 \
swift infer \
--adapters output/vx-xxx/checkpoint-xxx \
--stream false \
--max_batch_size 1 \
--load_data_args true \
--max_new_tokens 2048推送模型到ModelScope:
CUDA_VISIBLE_DEVICES=0 \
swift export \
--adapters output/vx-xxx/checkpoint-xxx \
--push_to_hub true \
--hub_model_id '<your-model-id>' \
--hub_token '<your-sdk-token>'
ModelScope旨在打造下一代开源的模型即服务共享平台,为泛AI开发者提供灵活、易用、低成本的一站式模型服务产品,让模型应用更简单!
更多推荐



 0
0 0
0- 0



 已为社区贡献629条内容
已为社区贡献629条内容

所有评论(0)