
微软Phi-4系列开源:多模态与文本处理的创新突破
微软近期推出 Phi-4-multimodal 和 Phi-4-mini,这些模型是 Microsoft Phi 系列小型语言模型 (SLM) 中的最新模型。Phi-4-multimodal 能够同时
00.前言
微软近期推出 Phi-4-multimodal 和 Phi-4-mini,这些模型是 Microsoft Phi 系列小型语言模型 (SLM) 中的最新模型。Phi-4-multimodal 能够同时处理语音、视觉和文本,为创建创新且具有上下文感知能力的应用程序开辟了新的可能性。另一方面,Phi-4-mini 在基于文本的任务方面表现出色,以紧凑的形式提供高精度和可扩展性。
01.什么是 Phi-4-multimodal?
Phi-4-multimodal 是Phi系列的第一个多模态语言模型,标志着微软人工智能发展的一个新里程碑。Phi-4-multimodal是一个5.6B参数模型,它将语音、视觉和文本处理无缝集成到一个统一的架构中。
通过利用先进的跨模态学习技术,该模型可实现更自然、更情境感知的交互,使设备能够同时理解和推理多种输入模态。无论是解释口头语言、分析图像还是处理文本信息,它都能提供高效、低延迟的推理,同时优化设备执行并降低计算开销。
专为多模式体验而构建
Phi-4-multimodal 是一个混合了 LoRA 的单一模型,包括语音、视觉和语言,所有这些都在同一个表示空间内同时处理。结果是一个能够处理文本、音频和视觉输入的单一统一模型——无需复杂的管道或针对不同模态的单独模型。
Phi-4-multimodal 采用一种可提高效率和可扩展性的新架构。它整合了更大的词汇量以改进处理能力,支持多语言功能,并将语言推理与多模式输入相结合。所有这些都是在强大、紧凑、高效的模型中实现的,该模型适合部署在设备和边缘计算平台上。
该模型代表了 Phi 系列模型的进步,在小巧的封装中提供增强的性能。无论您是在寻找移动设备还是边缘系统上的高级 AI 功能,Phi-4-multimodal 都能提供高效且多功能的高性能选项。
解锁新功能
Phi-4-multimodal 的功能范围和灵活性不断扩大,为希望以创新方式利用 AI 力量的应用开发者、企业和行业开辟了令人兴奋的新可能性。多模态 AI 的未来已然到来,它已准备好改变您的应用。
Phi-4-multimodal 能够同时处理视觉和音频。下表显示了当视觉内容的输入查询是合成语音时,在图表/表格理解和文档推理任务中的模型质量。与其他现有的能够将音频和视觉信号作为输入的最先进的全向模型相比,Phi-4-multimodal 在多个基准测试中实现了更强大的性能。

添加图片注释,不超过 140 字(可选)
图 1:Phi-4-多模式音频和视觉基准。
Phi-4-multimodal 在语音相关任务中表现出了卓越的能力,成为多个领域领先的开放模型。它在自动语音识别 (ASR) 和语音翻译 (ST) 方面都优于 WhisperV3 和 SeamlessM4T-v2-Large 等专业模型。它是少数几个成功实现语音摘要并达到与 GPT-4o 模型相当的性能水平的开放模型之一。该模型在语音问答 (QA) 任务上与 Gemini-2.0-Flash 和 GPT-4o-realtime-preview 等接近的模型存在差距,因为模型尺寸较小导致保留事实 QA 知识的能力较弱。正在开展工作以在下一次迭代中改进此功能。
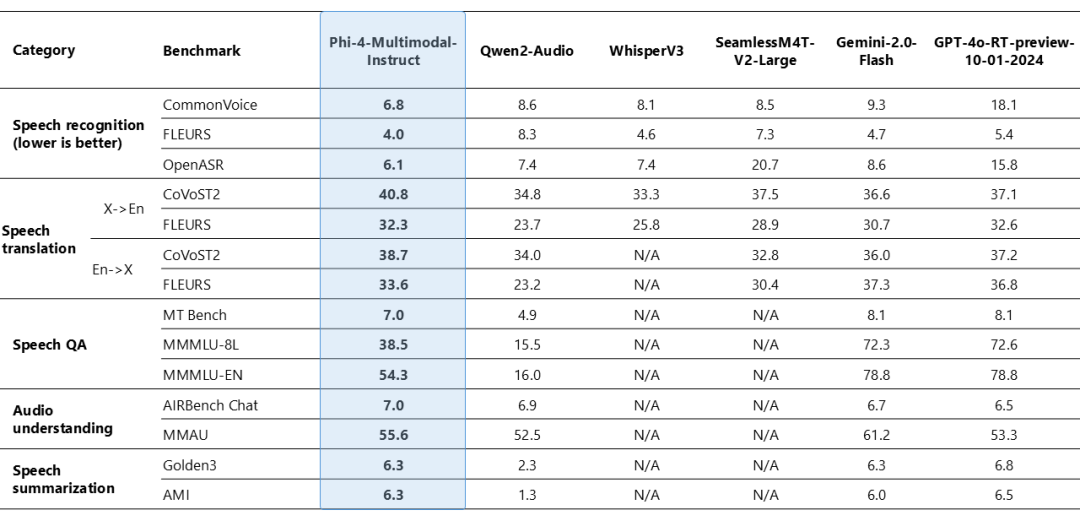
添加图片注释,不超过 140 字(可选)
图 2:Phi-4 多模式语音基准。
Phi-4-multimodal 仅具有 5.6B 个参数,但在各种基准测试中都表现出了卓越的视觉能力,最显著的是在数学和科学推理方面取得了优异的表现。尽管规模较小,但该模型在一般多模态能力(如文档和图表理解、光学字符识别 (OCR) 和视觉科学推理)方面仍保持着竞争性的表现,与 Gemini-2-Flash-lite-preview/Claude-3.5-Sonnet 等接近的模型相当或超过它们。
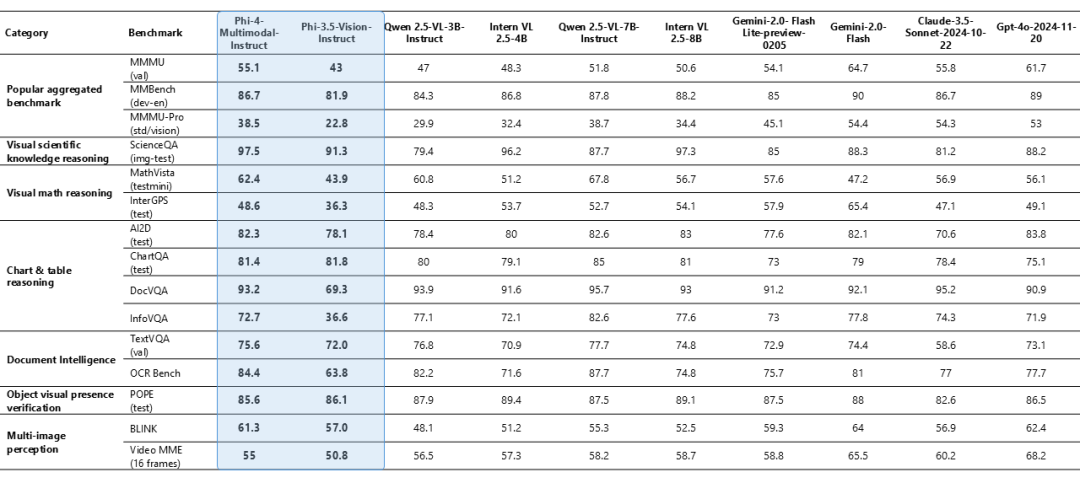
添加图片注释,不超过 140 字(可选)
图 3:Phi-4 多模式视觉基准。
02.什么是 Phi-4-mini?
Phi-4-mini是一个 3.8B 参数模型和一个密集的解码器专用转换器,具有分组查询注意、200,000 个词汇表和共享输入输出嵌入,专为提高速度和效率而设计。尽管体积小巧,但它在基于文本的任务(包括推理、数学、编码、指令跟踪和函数调用)中的表现仍然优于大型模型。它支持多达 128,000 个标记的序列,具有高准确度和可扩展性,使其成为高级 AI 应用程序的强大解决方案。
为了了解模型质量,下图Phi-4-mini 与一系列基准上的模型进行了比较,如图 4 所示。
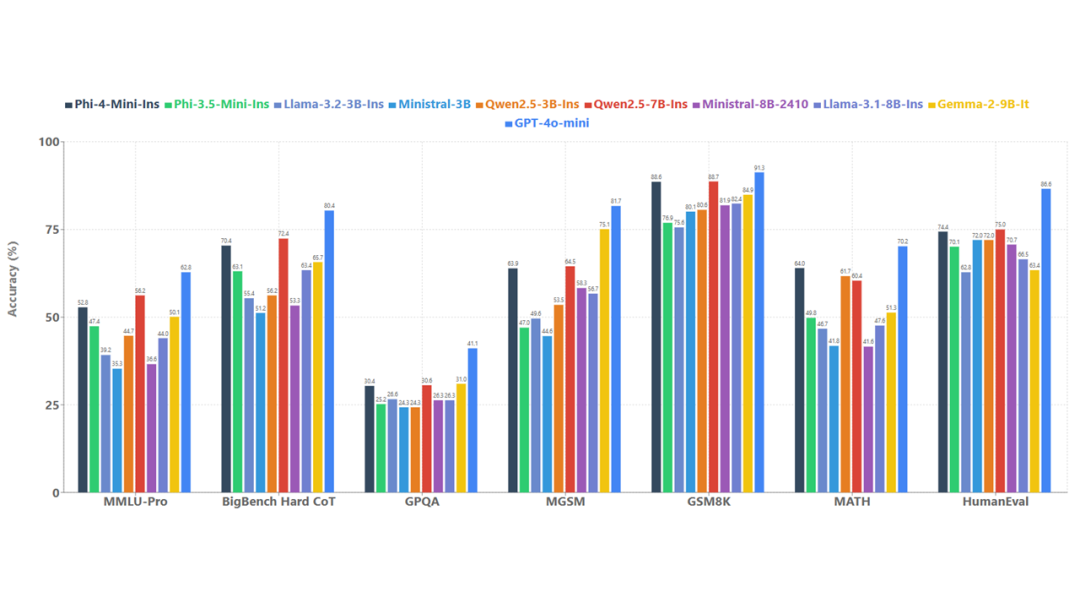
添加图片注释,不超过 140 字(可选)
图 4:Phi-4-mini 语言基准。
函数调用、指令跟踪、长上下文和推理是强大的功能,使 Phi-4-mini 等小型语言模型能够访问外部知识和功能,尽管其容量有限。通过标准化协议,函数调用允许模型与结构化编程接口无缝集成。当用户发出请求时,Phi-4-Mini 可以推理查询,识别并调用具有适当参数的相关函数,接收函数输出,并将这些结果合并到其响应中。这创建了一个可扩展的基于代理的系统,通过明确定义的函数接口将模型连接到外部工具、应用程序编程接口 (API) 和数据源,可以增强模型的功能。以下示例使用 Phi-4-mini 模拟智能家居控制代理。
03.定制和跨平台
由于尺寸较小,Phi-4-mini 和 Phi-4-multimodal 模型可用于计算受限的推理环境。这些模型可以在设备上使用,尤其是在使用 ONNX Runtime 进一步优化以实现跨平台可用性时。它们较低的计算需求使它们成为一种成本更低且延迟更低的选择。较长的上下文窗口可以接收和推理大量文本内容(文档、网页、代码等)。Phi-4-mini 和 multimodal 表现出强大的推理和逻辑能力,使其成为分析任务的理想选择。它们的小尺寸也使微调或定制更容易、更实惠。下表显示了使用 Phi-4-multimodal 进行微调的场景示例。
|
任务 |
基础模型 |
微调模型 |
计算 |
|
英语至印尼语的语音翻译 |
17.4 |
35.5 |
3小时,16 A100 |
|
医学视觉问答 |
47.6 |
56.7 |
5 小时,8 A100 |
04.模型结构
Phi-4-Mini和Phi-4-Multimodal共享相同的语言模型backbone。Phi-4-Mini由32个transformers layers组成,隐藏状态大小为3,072,并绑定了输入/输出embedding,与Phi-3.5相比,显着降低了内存消耗,同时提供了更广泛的词汇表覆盖范围。每个transformers块包括基于组查询注意力 (GQA) 的注意力机制,其优化用于长上下文生成的key和value存储器 (KV高速缓存) 使用。具体来说,该模型采用24个query头和8个key/value head,将KV缓存消耗减少到其标准大小的3分之1。Phi-4-Mini型号使用tokenizer o200k base tiktoken,词汇量为200,064,旨在更有效地支持多语言和多模式输入和输出。
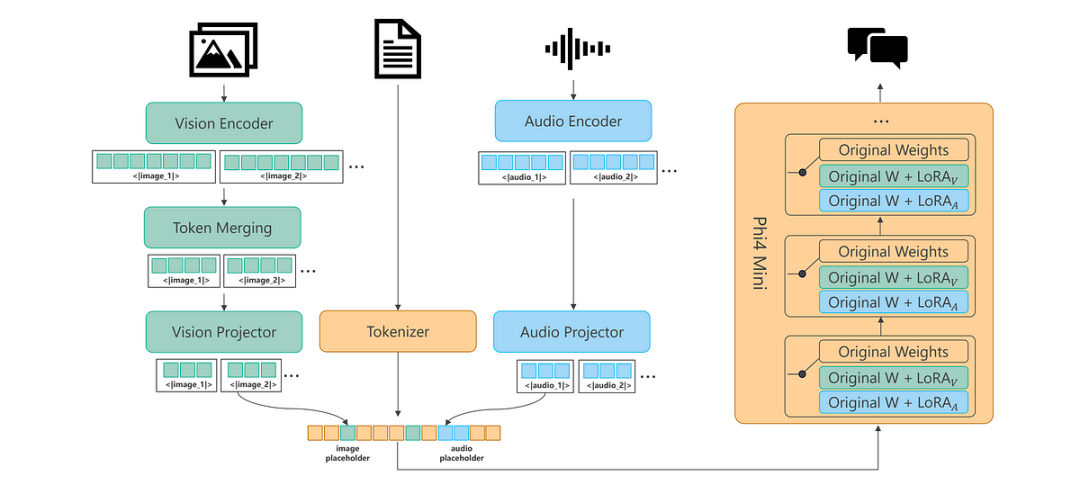
添加图片注释,不超过 140 字(可选)
为了实现特定于模态的功能,多模态模型通常需要对基本语言模型进行微调,这通常会降低其原始语言能力。为了解决这个问题,llamam-vision采用了受Flamingo启发的策略,在保留核心语言模型的同时添加了额外的交叉注意层。但是,与完全微调的模型相比,这种方法将导致视觉语言基准测试的性能降低。为了填补性能差距,NVLM进一步探索了一种混合框架,采用了高质量文本SFT数据的联合监督微调。然而,这种方法只检查有限的语言基准,没有解决SFT之后通常需要的额外培训阶段。Phi-4-Multimodal体系结构采用LoRAs设计的混合,以支持不同的多模态用例。训练不同的lora以处理不同模态之间的相互作用。
05.模型推理
Phi-4-mini-instruct推理代码:
from vllm import LLM, SamplingParams
llm = LLM(model="LLM-Research/Phi-4-mini-instruct", trust_remote_code=True)
messages = [
{"role": "system", "content": "You are a helpful AI assistant."},
{"role": "user", "content": "Can you provide ways to eat combinations of bananas and dragonfruits?"},
{"role": "assistant", "content": "Sure! Here are some ways to eat bananas and dragonfruits together: 1. Banana and dragonfruit smoothie: Blend bananas and dragonfruits together with some milk and honey. 2. Banana and dragonfruit salad: Mix sliced bananas and dragonfruits together with some lemon juice and honey."},
{"role": "user", "content": "What about solving an 2x + 3 = 7 equation?"},
]
sampling_params = SamplingParams(
max_tokens=500,
temperature=0.0,
)
output = llm.chat(messages=messages, sampling_params=sampling_params)
print(output[0].outputs[0].text)Phi-4-multimodal-instruct推理代码
import requests
import torch
import os
import io
from PIL import Image
import soundfile as sf
from transformers import AutoModelForCausalLM, AutoProcessor, GenerationConfig
from urllib.request import urlopen
from modelscope import snapshot_download
# Define model path
model_path = snapshot_download("LLM-Research/Phi-4-multimodal-instruct")
# Load model and processor
processor = AutoProcessor.from_pretrained(model_path, trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(
model_path,
device_map="cuda",
torch_dtype="auto",
trust_remote_code=True,
#attn_implementation='flash_attention_2',
).cuda()
# Load generation config
generation_config = GenerationConfig.from_pretrained(model_path)
# Define prompt structure
user_prompt = '<|user|>'
assistant_prompt = '<|assistant|>'
prompt_suffix = '<|end|>'
# Part 1: Image Processing
print("\n--- IMAGE PROCESSING ---")
image_url = 'https://www.ilankelman.org/stopsigns/australia.jpg'
prompt = f'{user_prompt}<|image_1|>What is shown in this image?{prompt_suffix}{assistant_prompt}'
print(f'>>> Prompt\n{prompt}')
# Download and open image
image = Image.open(requests.get(image_url, stream=True).raw)
inputs = processor(text=prompt, images=image, return_tensors='pt').to('cuda:0')
# Generate response
generate_ids = model.generate(
**inputs,
max_new_tokens=1000,
generation_config=generation_config,
)
generate_ids = generate_ids[:, inputs['input_ids'].shape[1]:]
response = processor.batch_decode(
generate_ids, skip_special_tokens=True, clean_up_tokenization_spaces=False
)[0]
print(f'>>> Response\n{response}')
# Part 2: Audio Processing
print("\n--- AUDIO PROCESSING ---")
audio_url = "https://upload.wikimedia.org/wikipedia/commons/b/b0/Barbara_Sahakian_BBC_Radio4_The_Life_Scientific_29_May_2012_b01j5j24.flac"
speech_prompt = "Transcribe the audio to text, and then translate the audio to French. Use <sep> as a separator between the original transcript and the translation."
prompt = f'{user_prompt}<|audio_1|>{speech_prompt}{prompt_suffix}{assistant_prompt}'
print(f'>>> Prompt\n{prompt}')
# Downlowd and open audio file
audio, samplerate = sf.read(io.BytesIO(urlopen(audio_url).read()))
# Process with the model
inputs = processor(text=prompt, audios=[(audio, samplerate)], return_tensors='pt').to('cuda:0')
generate_ids = model.generate(
**inputs,
max_new_tokens=1000,
generation_config=generation_config,
)
generate_ids = generate_ids[:, inputs['input_ids'].shape[1]:]
response = processor.batch_decode(
generate_ids, skip_special_tokens=True, clean_up_tokenization_spaces=False
)[0]
print(f'>>> Response\n{response}')模型微调
ms-swift已经支持了Phi-4-multimodal-instruct的微调,包括图像和音频。ms-swift是魔搭社区官方提供的大模型与多模态大模型训练部署框架。
ms-swift开源地址:
https://github.com/modelscope/ms-swift
我们将展示可运行的微调demo,并给出自定义数据集的格式。
在开始微调之前,请确保您的环境已准备妥当。
# pip install git+https://github.com/modelscope/ms-swift.git
git clone https://github.com/modelscope/ms-swift.git
cd ms-swift
pip install -e .微调脚本如下:
CUDA_VISIBLE_DEVICES=0 \
swift sft \
--model LLM-Research/Phi-4-multimodal-instruct \
--dataset 'AI-ModelScope/LaTeX_OCR:human_handwrite#20000' \
--train_type dummy \
--torch_dtype bfloat16 \
--num_train_epochs 1 \
--per_device_train_batch_size 1 \
--per_device_eval_batch_size 1 \
--learning_rate 1e-4 \
--gradient_accumulation_steps 16 \
--eval_steps 200 \
--save_steps 200 \
--save_total_limit 5 \
--logging_steps 5 \
--max_length 2048 \
--output_dir output \
--warmup_ratio 0.05 \
--dataloader_num_workers 4训练显存占用:

添加图片注释,不超过 140 字(可选)
如果要使用自定义数据集进行训练,你可以参考以下格式,并指定`--dataset <dataset_path>`。
{"messages": [{"role": "user", "content": "浙江的省会在哪?"}, {"role": "assistant", "content": "浙江的省会在杭州。"}]}
{"messages": [{"role": "user", "content": "<image><image>两张图片有什么区别"}, {"role": "assistant", "content": "前一张是小猫,后一张是小狗"}], "images": ["/xxx/x.jpg", "/xxx/x.png"]}
{"messages": [{"role": "user", "content": "<audio>语音说了什么"}, {"role": "assistant", "content": "今天天气真好呀"}], "audios": ["/xxx/x.mp3"]}训练完成后,使用以下命令对训练后的权重进行推理,这里的`--adapters`需要替换成训练生成的last checkpoint文件夹。
CUDA_VISIBLE_DEVICES=0 \
swift infer \
--adapters output/vx-xxx/checkpoint-xxx \
--stream false \
--max_batch_size 1 \
--load_data_args true \
--max_new_tokens 2048推送模型到ModelScope:
CUDA_VISIBLE_DEVICES=0 \
swift export \
--adapters output/vx-xxx/checkpoint-xxx \
--push_to_hub true \
--hub_model_id '<your-model-id>' \
--hub_token '<your-sdk-token>'点击链接即可跳转模型体验~

ModelScope旨在打造下一代开源的模型即服务共享平台,为泛AI开发者提供灵活、易用、低成本的一站式模型服务产品,让模型应用更简单!
更多推荐



 1
1 0
0- 0



 已为社区贡献649条内容
已为社区贡献649条内容

所有评论(0)