
R1类模型推理能力评测手把手实战
随着DeepSeek-R1模型的广泛应用,越来越多的开发者开始尝试复现类似的模型,以提升其推理能力。
随着DeepSeek-R1模型的广泛应用,越来越多的开发者开始尝试复现类似的模型,以提升其推理能力。目前已经涌现出不少令人瞩目的成果。然而,这些新模型的推理能力是否真的提高了呢?EvalScope框架是魔搭社区上开源的评估工具(https://github.com/modelscope/evalscope),提供了对R1类模型的推理性能的评测能力。
在本最佳实践中,我们通过728道推理题目(与R1技术报告一致)进行演示。评测数据具体包括:
-
MATH-500:一组具有挑战性的高中数学竞赛问题数据集,涵盖七个科目(如初等代数、代数、数论)共500道题。
-
GPQA-Diamond:该数据集包含物理、化学和生物学子领域的硕士水平多项选择题,共198道题。
-
AIME-2024:美国邀请数学竞赛的数据集,包含30道数学题。
具体的流程包括安装相关依赖、准备模型、评测模型以及评测结果的可视化。让我们开始吧。
01.安装依赖
安装EvalScope模型评估框架:
pip install 'evalscope[app,perf]' -U02.模型准备
接下来,我们以DeepSeek-R1-Distill-Qwen-1.5B模型为例,介绍评估的过程。首先将模型的能力通过一个OpenAI API兼容的推理服务接入,来进行模型的评测。EvalScope也支持通过transformers推理来进行模型评测,具体可见EvalScope文档。
除了将模型部署到云端支持OpenAI接口的服务使用以外,也可以在本地直接用vLLM,ollama等框架直接拉起模型。这里介绍基于vLLM和lmdeploy推理框架的使用,因为这些推理框架能较好的支持并发多个请求,以加速评测过程,同时R1类模型的输出包含较长的思维链,输出token数量往往超过1万,使用高效的推理框架部署模型,可以提高推理速度。
-
使用vLLM:
VLLM_USE_MODELSCOPE=True CUDA_VISIBLE_DEVICES=0 python -m vllm.entrypoints.openai.api_server --model deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B --served-model-name DeepSeek-R1-Distill-Qwen-1.5B --trust_remote_code --port 8801-
使用lmdeploy:
LMDEPLOY_USE_MODELSCOPE=True CUDA_VISIBLE_DEVICES=0 lmdeploy serve api_server deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B --model-name DeepSeek-R1-Distill-Qwen-1.5B --server-port 8801(可选) 测试推理服务性能
在开始正式模型评测前,可以测试一下模型推理服务的性能,以选择性能更好的推理引擎,使用evalscope的perf子命令即可进行测试:
evalscope perf \
--parallel 10 \
--url http://127.0.0.1:8801/v1/chat/completions \
--model DeepSeek-R1-Distill-Qwen-1.5B \
--log-every-n-query 5 \
--connect-timeout 6000 \
--read-timeout 6000 \
--api openai \
--prompt '写一个科幻小说,不少于2000字,请开始你的表演' \
-n 100参数说明具体可参考性能评测
Benchmarking summary:
+-----------------------------------+-------------------------------------------------------------------------+
| Key | Value |
+===================================+=========================================================================+
| Time taken for tests (s) | 92.66 |
+-----------------------------------+-------------------------------------------------------------------------+
| Number of concurrency | 10 |
+-----------------------------------+-------------------------------------------------------------------------+
| Total requests | 100 |
+-----------------------------------+-------------------------------------------------------------------------+
| Succeed requests | 100 |
+-----------------------------------+-------------------------------------------------------------------------+
| Failed requests | 0 |
+-----------------------------------+-------------------------------------------------------------------------+
| Throughput(average tokens/s) | 1727.453 |
+-----------------------------------+-------------------------------------------------------------------------+
| Average QPS | 1.079 |
+-----------------------------------+-------------------------------------------------------------------------+
| Average latency (s) | 8.636 |
+-----------------------------------+-------------------------------------------------------------------------+
| Average time to first token (s) | 8.636 |
+-----------------------------------+-------------------------------------------------------------------------+
| Average time per output token (s) | 0.00058 |
+-----------------------------------+-------------------------------------------------------------------------+
| Average input tokens per request | 20.0 |
+-----------------------------------+-------------------------------------------------------------------------+
| Average output tokens per request | 1600.66 |
+-----------------------------------+-------------------------------------------------------------------------+
| Average package latency (s) | 8.636 |
+-----------------------------------+-------------------------------------------------------------------------+
| Average package per request | 1.0 |
+-----------------------------------+-------------------------------------------------------------------------+
| Expected number of requests | 100 |
+-----------------------------------+-------------------------------------------------------------------------+
| Result DB path | outputs/20250213_103632/DeepSeek-R1-Distill-Qwen-1.5B/benchmark_data.db |
+-----------------------------------+-------------------------------------------------------------------------+
Percentile results:
+------------+----------+----------+-------------+--------------+---------------+----------------------+
| Percentile | TTFT (s) | TPOT (s) | Latency (s) | Input tokens | Output tokens | Throughput(tokens/s) |
+------------+----------+----------+-------------+--------------+---------------+----------------------+
| 10% | 5.4506 | nan | 5.4506 | 20 | 1011 | 183.7254 |
| 25% | 6.1689 | nan | 6.1689 | 20 | 1145 | 184.9222 |
| 50% | 9.385 | nan | 9.385 | 20 | 1741 | 185.5081 |
| 66% | 11.0023 | nan | 11.0023 | 20 | 2048 | 185.8063 |
| 75% | 11.0374 | nan | 11.0374 | 20 | 2048 | 186.1429 |
| 80% | 11.047 | nan | 11.047 | 20 | 2048 | 186.3683 |
| 90% | 11.075 | nan | 11.075 | 20 | 2048 | 186.5962 |
| 95% | 11.147 | nan | 11.147 | 20 | 2048 | 186.7836 |
| 98% | 11.1574 | nan | 11.1574 | 20 | 2048 | 187.4917 |
| 99% | 11.1688 | nan | 11.1688 | 20 | 2048 | 197.4991 |
+------------+----------+----------+-------------+--------------+---------------+----------------------+03.模型评测
我们将MATH-500、GPQA-Diamond和AIME-2024三个数据集整合为一个数据集合,放置于modelscope/R1-Distill-Math-Test数据集中,可以直接使用该数据集的ID进行评测操作。如果希望了解数据集的生成过程或者自行定制数据集合,可以参考使用教程。
数据集:
https://modelscope.cn/datasets/modelscope/R1-Distill-Math-Test
配置评测任务
通过以下Python代码,您可以评测DeepSeek-R1-Distill-Qwen-1.5B模型在推理数据集上的表现:
from evalscope import TaskConfig, run_task
from evalscope.constants import EvalType
task_cfg = TaskConfig(
model='DeepSeek-R1-Distill-Qwen-1.5B', # 模型名称
api_url='http://127.0.0.1:8801/v1/chat/completions', # 推理服务地址
api_key='EMPTY',
eval_type=EvalType.SERVICE, # 评测类型,SERVICE表示评测推理服务
datasets=[
'data_collection', # 数据集名称(固定为data_collection表示使用混合数据集)
],
dataset_args={
'data_collection': {
'dataset_id': 'modelscope/R1-Distill-Math-Test' # 数据集ID 或 数据集本地路径
}
},
eval_batch_size=32, # 发送请求的并发数
generation_config={ # 模型推理配置
'max_tokens': 20000, # 最大生成token数,建议设置为较大值避免输出截断
'temperature': 0.6, # 采样温度 (deepseek 报告推荐值)
'top_p': 0.95, # top-p采样 (deepseek 报告推荐值)
'n': 5 # 每个请求产生的回复数量 (注意 lmdeploy 目前只支持 n=1)
},
)
run_task(task_cfg=task_cfg)输出结果:
这里的计算指标是AveragePass@1,每个样本重复生成了5次,最终的评测结果是5次的平均值。由于模型生成时进行了采样,输出结果可能会有一定的波动。
+-----------+--------------+---------------+-------+
| task_type | dataset_name | average_score | count |
+-----------+--------------+---------------+-------+
| math | math_500 | 0.7832 | 500 |
| math | gpqa | 0.3434 | 198 |
| math | aime24 | 0.2 | 30 |
+-----------+--------------+---------------+-------+如果您只想运行单独其中的某些数据集,可以修改上述配置中的datasets和dataset_args参数,例如如下配置将只评测GPQA-Diamond和AIME-2024两个数据集:
datasets=[
# 'math_500', # 数据集名称
'gpqa',
'aime24'
],
dataset_args={ # EvalScope内置支持,无需指定数据集ID
'math_500': {'few_shot_num': 0 } ,
'gpqa': {'subset_list': ['gpqa_diamond'], 'few_shot_num': 0},
'aime24': {'few_shot_num': 0}
},04.评测结果可视化
EvalScope支持可视化结果,可以查看模型具体的输出。
运行以下命令,可以启动可视化界面:
evalscope app终端将输出如下链接内容:
* Running on local URL: http://0.0.0.0:7860点击链接即可看到如下可视化界面,我们需要先选择评测报告然后点击加载:
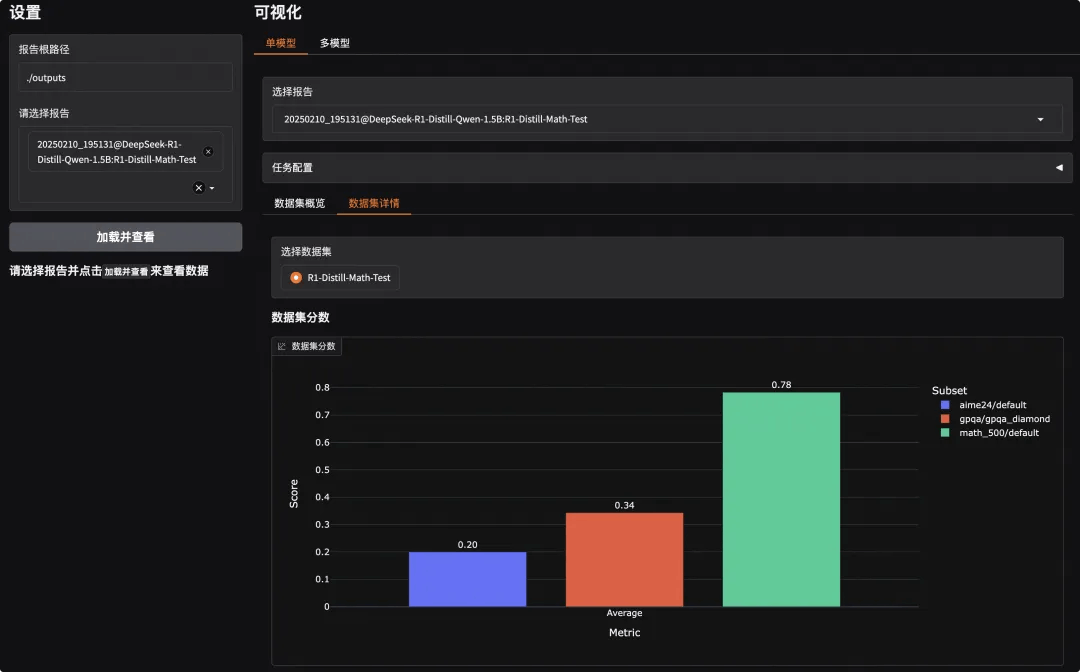
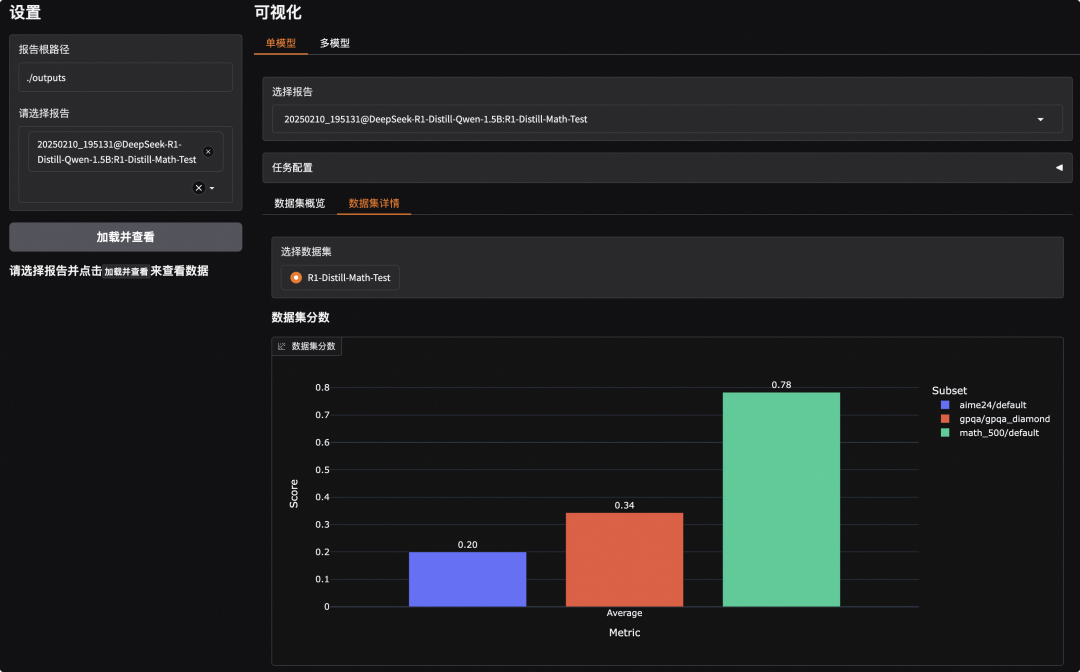
此外,选择对应的子数据集,我们也可以查看模型的输出内容,观察模型输出是否正确(或者是答案匹配是否存在问题)。可以看到,在下面的例子中模型确实输出了正确的答案:
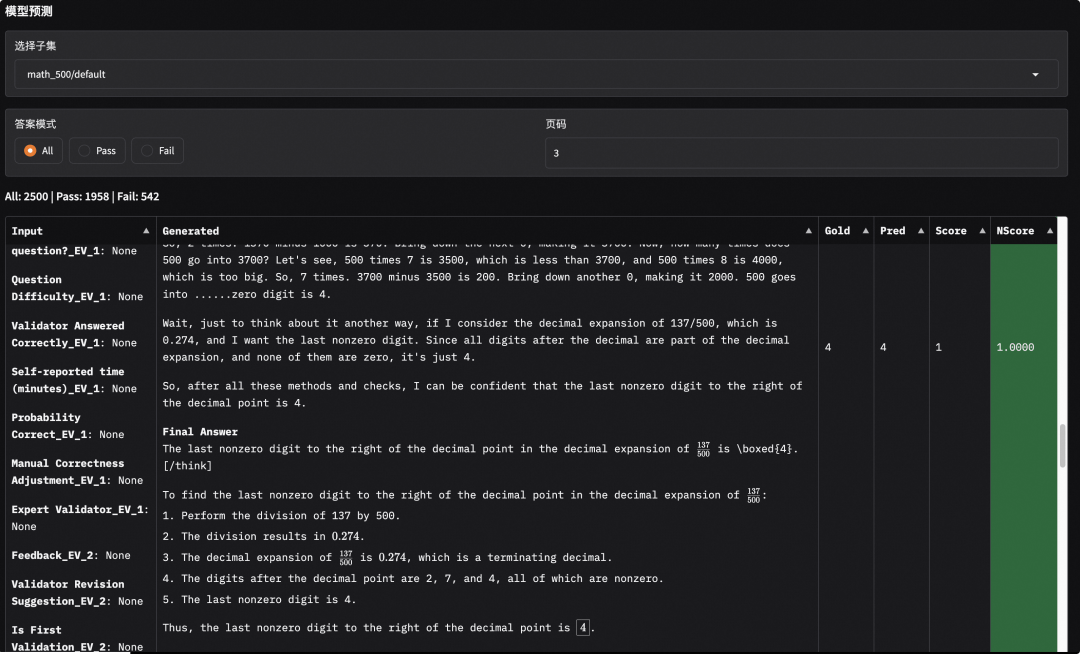
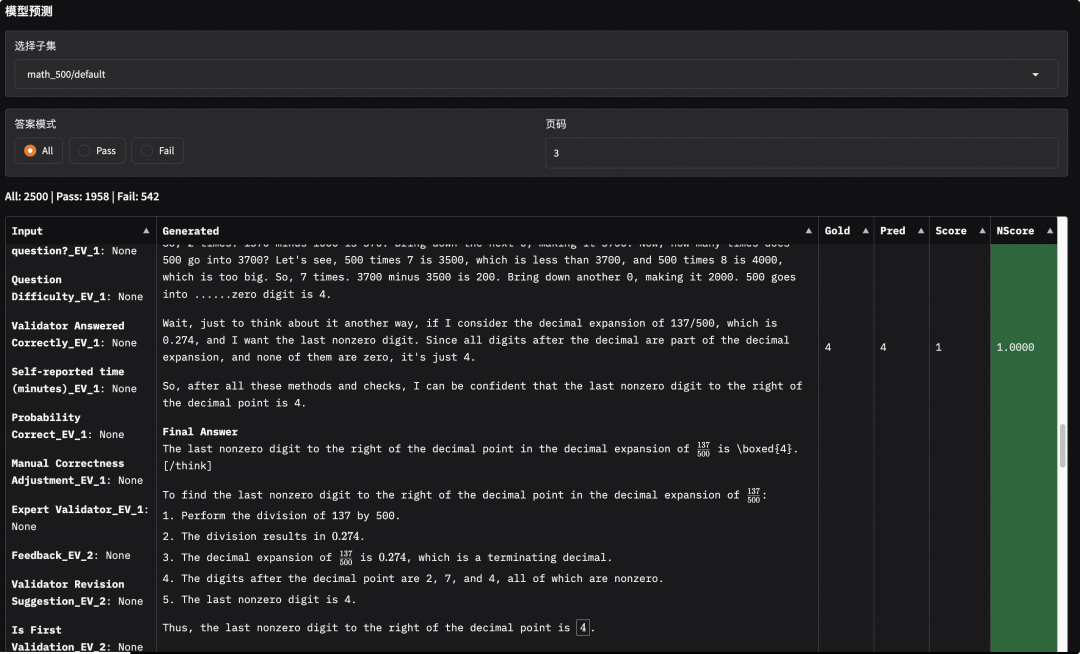
05.Tips


在这里分享一下评测时可能会踩的一些“坑”:
-
模型生成配置:
-
max_tokens设置:确保将max_tokens设置为较大的值(通常需要在8000以上)。如果设置过低,模型可能会在输出完整答案前被截断。
-
回复数量n配置:在本次评测中,每个请求生成的回复数量n设置为5,而在R1报告中,n为64。读者可以根据需求调整此参数来平衡评测速度与结果的多样性。
-
数据集的提示模版设置:
-
本文采用了R1报告中的推荐设置,提示模版为:"Please reason step by step, and put your final answer within \boxed{}.";同时,未设置system prompt。确保提示模版的正确性对于生成预期的结果至关重要。
-
评测Reasoning模型需要设置0-shot,过于复杂的prompt或者few-shot都有可能降低模型的性能。
-
生成答案的解析和匹配:
-
我们复用了Qwen-Math工作中的解析方法,该方法基于规则进行答案解析。然而,这种基于规则的解析可能会导致匹配错误,从而对报告的指标产生轻微影响。建议在使用结果时,多使用评测结果可视化功能,查看解析结果是否存在误差。
06.总结
通过这个流程,开发者可以有效地评测R1类模型在多个数学和科学推理数据集上的表现,从而客观评估具体模型的实际表现,共同推动R1类模型的进一步发展与应用。
点击链接阅读原文:R1蒸馏模型数学推理能力测试集

ModelScope旨在打造下一代开源的模型即服务共享平台,为泛AI开发者提供灵活、易用、低成本的一站式模型服务产品,让模型应用更简单!
更多推荐



 0
0 0
0- 0



 已为社区贡献634条内容
已为社区贡献634条内容

所有评论(0)