
AAAI 2025| S5VH: 基于选择性状态空间的高效自监督视频哈希
论文标题: Efficient Self-Supervised Video Hashing with Selective State Spaces (S5VH) 作者: Jinpeng Wang, Niu Lian, Jun Li, Yuting Wang, Yan Feng, Bin Chen, Yongbing Zhang, Shu-Tao Xia 机构: 清华大学、哈尔滨工业大学࿰

论文标题:
Efficient Self-Supervised Video Hashing with Selective State Spaces (S5VH)
作者:
Jinpeng Wang, Niu Lian, Jun Li, Yuting Wang, Yan Feng, Bin Chen, Yongbing Zhang, Shu-Tao Xia
机构:
清华大学、哈尔滨工业大学(深圳)、美团、鹏城实验室
代码链接:
https://github.com/gimpong/AAAI25-S5VH
https://modelscope.cn/models/JUN2005/AAAI2025-S5VH
论文链接:
https://arxiv.org/abs/2412.14518
会议:
AAAI 2025 (Association for the Advancement of Artificial Intelligence)
01.研究背景
随着短视频、流媒体平台的爆发式增长,如何高效地索引和检索视频数据成为计算机视觉和多媒体领域的重要研究问题。视频哈希(Video Hashing) 是一种通过学习紧凑的二进制编码来高效索引和检索视频的技术,其核心目标是使哈希码的汉明距离(Hamming Distance)能够准确地反映视频之间的语义相似性。
近年来,自监督视频哈希(SSVH, Self-Supervised Video Hashing)受到广泛关注,因为:
- 无需人工标注,可以利用海量无标签视频数据进行训练,利用视频内在的时序和语义信息进行学习,具有较高的实用价值。
- 计算效率高,相比深度特征匹配方法,哈希方法的查询速度更快,存储成本更低。
现有主流 SSVH 方法大多采用 Transformer 进行时序建模,然而:
- Transformer 计算复杂度随帧数呈二次增长,难以扩展到长视频。
- 训练和推理过程占用大量显存,限制了大规模部署的可行性。
大多数方法通常遵循内部样本学习(self/intra-sample)与样本间学习(inter-sample)相结合的范式。其中,内部信号(self)主要指通过各种数据增强下的重建任务来实现视频理解;而样本间信号则依赖于视频之间的对比学习,以获得具有辨识性的哈希码。但由于样本间信号受到单个样本局部(local)信息的影响,缺乏全局语义指导,容易受到负样本采样等问题影响,训练效率和稳定性较低。
02.研究目标
为了解决上述问题,我们受到Mamba(一种先进的状态空间模型(SSM))的启发,结合创新的自监督学习策略,提出了一种全新的 SSVH 方法——S5VH,能够在高效计算与检索效果之间取得更优的平衡。
03.论文贡献
我们的研究主要做出了以下三大贡献:
- 创新的视频哈希网络:
- 首次 将 Mamba 引入 SSVH,提出 双向 Mamba 层 进行高效时序建模。
- Mamba 采用数据选择性扫描机制,计算复杂度为线性 O(N),相比 Transformer 大幅降低计算量。
- 全新的自监督学习策略:
提出了Self-Local-Global(SLG)学习范式,结合 哈希中心生成 与 中心对齐损失(),大幅提高训练效率。
- 传统 SSVH 主要依赖对比学习,我们引入全局语义监督,使得哈希码学习更加高效且稳定。
- 高效的哈希学习机制:
- 设计了一种哈希中心生成算法,将特征空间的全局语义结构映射到哈希空间,提升哈希码的语义一致性。
- 通过中心对齐损失,显著加速训练收敛速度。
04.方法介绍
Pipeline 介绍
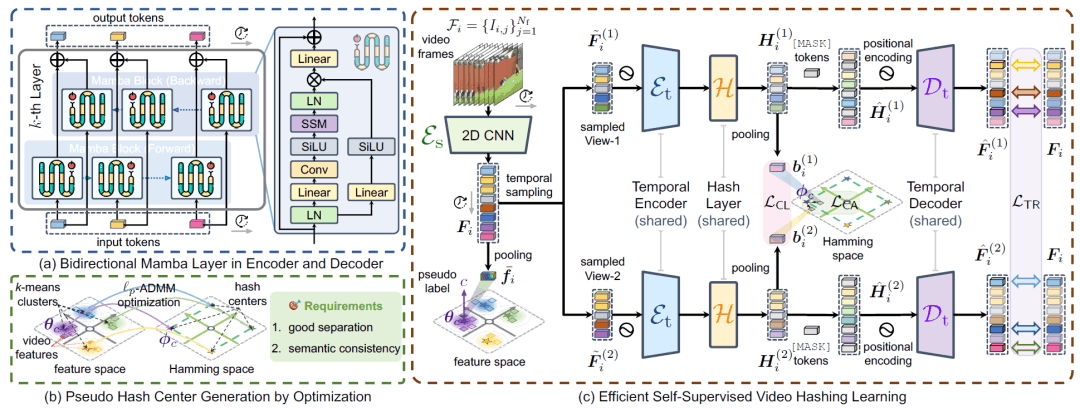
(a) 我们设计了一种基于 双向 Mamba 层 的编码器和解码器,以实现高效且精准的时序建模。
(b) 我们提出了一种优化算法,将特征空间中的全局语义结构转换为分离性良好且语义一致的哈希中心,以增强哈希学习的全局监督。
(c) 在哈希学习过程中,我们首先对视频帧进行编码,并基于最近的特征聚类生成伪标签。随后,对视频的两个视图进行采样,并采用共享的编码器和哈希层进行特征处理,从而获得帧级软哈希向量。接着,我们对帧级哈希向量进行聚合,以生成视频级哈希向量,进一步用于对比学习与中心对齐。此外,我们引入了一种辅助解码器(推理阶段移除),利用每个视图的帧哈希向量重建屏蔽帧,以强化局部信息建模。
✨ Mamba 赋能高效时序建模
❓ 为什么选择 Mamba?
传统的 SSVH 方法主要依赖 Transformer 进行时序建模,但其计算复杂度随帧数增长呈 O(N²),对于长视频的处理十分昂贵。而 Mamba 基于状态空间模型(SSM),其核心优势在于:
- 计算复杂度仅为 O(N),适用于长视频处理。
- 数据选择性扫描机制 能够自适应地筛选重要信息,减少冗余计算。
- 结构紧凑,占用显存少,能够支持更大批量的视频输入。
S5VH 采用的 Mamba 结构
在 S5VH 中,我们设计了一种 双向 Mamba 结构:
- 前向 Mamba 模块:从视频起始向末尾扫描,捕捉前向依赖关系。
- 反向 Mamba 模块:从视频末尾向起始扫描,弥补单向建模的不足,增强全局上下文信息。
- 融合策略:通过对前向与反向的输出进行融合,获得更为丰富的时序特征表
这种结构相比 Transformer,计算量更低,时序建模能力更强,在实验中展现出了更优的性能。
全新 Self-Local-Global(SLG)学习范式
挑战:如何高效利用全局语义信息?
现有的自监督视频哈希(SSVH)方法通常依赖两类信号:
- 自我恢复任务(Self):例如 帧重构、遮挡帧预测、时序顺序预测等,利用视频内在的时序和局部信息进行训练。
- 单个视频对比学习(Local):通过比较同一视频的不同增强视图(或不同视频间的样本)来获得区分性特征。
存在如下问题:
- Self重构任务往往只能捕捉到视频内的局部细节,难以提取出数据集整体的全局语义信息。
- Local对比学习中,负样本采样等策略容易受到噪声和样本不平衡的影响(例如只将同一个视频的视图视为正例,不同视频全部视为负例,但实际上同一类视频的视图应为正例),导致训练过程不稳定且效率有限。
- 缺乏显示全局监督,哈希码学习不稳定
✅ 我们的解决方案
我们提出了一种基于哈希中心的全局监督策略:
- 全局语义提取:在特征空间进行 k-means 聚类,获得 Nc 个全局聚类中心,聚类中心被看作是语义信息的压缩表示,用于指导后续哈希码学习。
- 哈希中心生成:论文提出优化算法,将特征空间中的全局语义中心转换为哈希空间中的“哈希中心”,要求这些哈希中心之间具有良好的分离性和语义一致性。
- 中心对齐损失(LCA):通过设计中心对齐损失,直接将视频的哈希码与对应的哈希中心进行对齐。该损失作为全局学习信号补充传统的局部重构或对比损失,使模型训练更快、更稳定,同时提升了最终哈希码的语义一致性。
我们在原有的 self-local 信号基础上引入了我们提出的全局监督信号,构建了全新的 Self-Local-Global (SLG) 学习范式。通过整合这三类互补的学习信号,SLG 既能够有效捕捉 self-local 级别的特征信息,又能确保生成的哈希码在哈希空间中保持良好的全局语义一致性与区分性。此外,该范式显著提升了模型的收敛速度与泛化能力,使其在大规模视频数据处理中表现更优。
05.实验结果
通用数据集检索
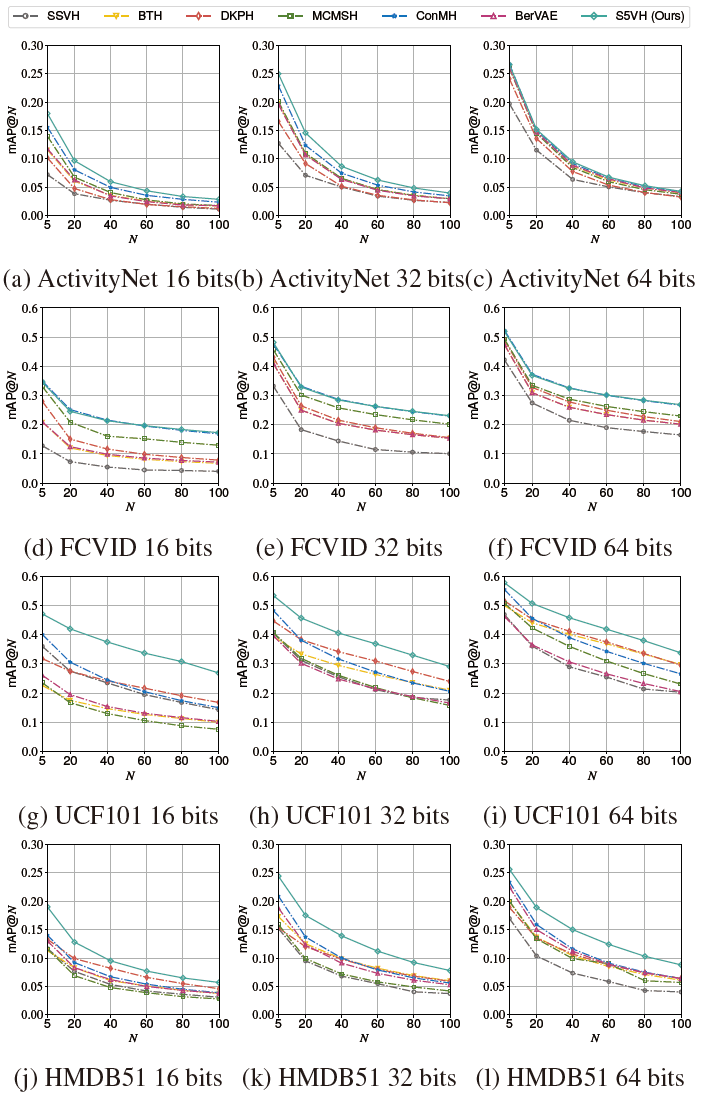
我们选取了6个有代表性的基线进行比较,在数据集和代码长度上,S5VH通常优于其他方法,证明了优越的功效。特别是对于16位这样的low-bit设置,这种改进更加明显,突出了S5VH卓越的检索性能。
t-SNE比较

与ConMH生成的哈希码相比,S5VH生成的哈希码在同一类别内表现出更清晰的紧凑性,不同类别之间的分离度增加。这一发现表明,S5VH产生更具鉴别性的二进制代码,这显著提高了检索性能。
推理效率
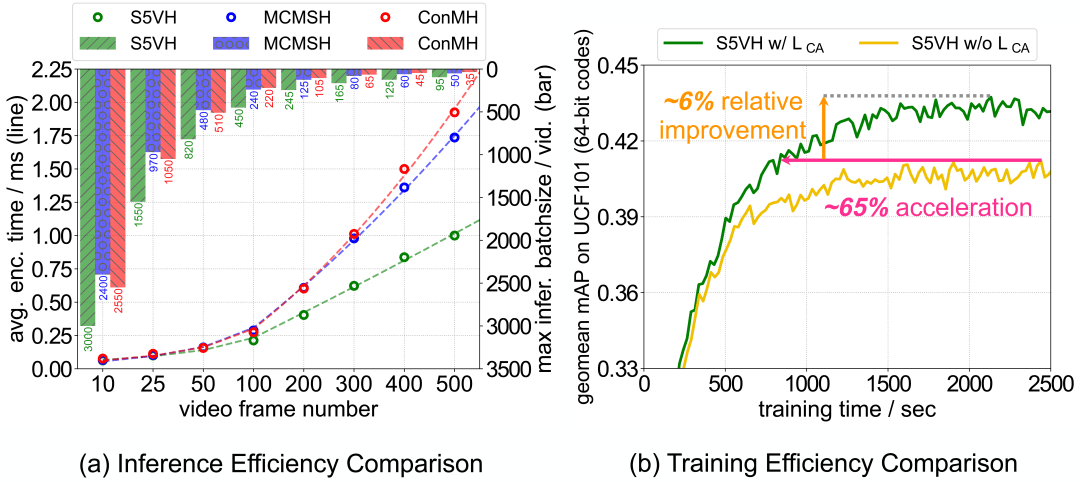
我们可以看到基于Mamba的S5VH在内存和计算上表现出较低的推理开销,其效率优势是可扩展的,并且在更大的帧数下更加显著。同时在哈希空间引入的全局学习信号表现出更快和更好的收敛。
06.论文总结
在本文中,团队介绍了S5VH,它是第一个基于Mamba的SSVH模型,具有增强的学习范式。S5VH开发双向Mamba层来捕获全面的时间关系,用于哈希学习。为了提高训练效率,我们提出了语义哈希中心生成算法和中心对齐损失来提取和利用全局学习信号。实验表明,S5VH在各种设置下都有一致的改进,迁移能力强,推理效率更高。我们的研究表明了状态空间模型在视频哈希中的强大潜力,我们希望这能激发进一步的研究。
欢迎大家在 GitHub 上 Star 我们的代码:https://github.com/gimpong/AAAI25-S5VH

ModelScope旨在打造下一代开源的模型即服务共享平台,为泛AI开发者提供灵活、易用、低成本的一站式模型服务产品,让模型应用更简单!
更多推荐



 0
0 0
0- 0



 已为社区贡献633条内容
已为社区贡献633条内容

所有评论(0)