
社区供稿 | 引入隐式模型融合技术,中山大学团队推出 FuseChat-3.0
在大语言模型(LLM)领域,结合多个模型的优势以提升单个模型的能力已成为一大趋势。然而,以往的模型融合方法例如 FuseLLM[1], FuseChat-1.0/2.0[2] 等存在词表对齐困难、效率
01.前言
在大语言模型(LLM)领域,结合多个模型的优势以提升单个模型的能力已成为一大趋势。然而,以往的模型融合方法例如 FuseLLM[1], FuseChat-1.0/2.0[2] 等存在词表对齐困难、效率低下等问题。近日,中山大学的研究团队提出了 FuseChat-3.0,一种利用偏好优化进行隐式模型融合的新方法。
不同于显式模型融合需要对齐不同模型的概率分布,FuseChat-3.0 通过构建偏好数据集并应用监督微调(SFT)和直接偏好优化(DPO)两个阶段,将多个源模型的能力隐式地迁移到目标模型中,实现了在不增加推理开销的前提下,显著提升目标模型的性能。

项目主页:
https://slit-ai.github.io/FuseChat-3.0
模型地址:
https://www.modelscope.cn/organization/FuseAI
论文链接:
https://arxiv.org/abs/2412.03187
02.方法介绍
FuseChat-3.0的核心在于利用偏好优化进行隐式模型融合(IMF),从多个强大的源模型中学习偏好,将其能力迁移到更小的目标模型中。作为对WRPO[3]核心思想的实践性延伸和优化,我们对原始方案进行了精简和改进,以提升开源社区的可复现性和降低计算资源消耗。整体方法由以下三个主要步骤构成:
-
数据集构建:选择四个主流开源大语言模型(Gemma-2-27B-It、Mistral-Large-Instruct-2407、Qwen-2.5-72B-Instruct、Llama-3.1-70B-Instruct)作为源模型,构建监督微调(SFT)和直接偏好优化(DPO)数据集。相比于原方案中多达十个源模型的选择,这种精简的源模型选择确保了实验的代表性和可获取性。
-
监督微调(SFT)阶段:与原方案一致,在目标模型上使用得分最高的源模型回复进行微调,以缩小目标模型与源模型之间的分布差异。
-
偏好优化阶段:采用更为高效的直接偏好优化(DPO)技术,利用源模型生成的最佳和最差回复对作为偏好对,对目标模型进行优化。相较于原方案基于目标模型的回复构造偏好对并引入源模型回复作为额外正样本,我们发现在数学和代码领域,仅由目标模型自身回复构造的偏好对较为有限,而从多个源模型采样可以获得更丰富的偏好对数据。
这些优化调整在保留隐式模型融合核心优势的同时,使得实现更加轻量化和实用化,更适合开源社区的实际应用场景。
03.实验设置
源模型
|
Gemma-2-27B-It |
Mistral-Large-Instruct-2407 |
Qwen-2.5-72B-Instruct |
Llama-3.1-70B-Instruct |
目标模型
|
Llama-3.1-8B |
Llama-3.2-3B |
Llama-3.2-1B |
Qwen-2.5-7B |
Gemma-2-9B |
数据集
数据集构建的目的在于增强模型的指令遵循、通用对话、数学、代码和中文能力。研究团队从开源社区数据集中选择数据,进行了有针对性的过滤和预处理。主要的数据集和过滤标准包括:
-
指令遵循与通用对话:来自 UltraFeedback、Magpie-Pro-DPO-100K-v0.1 和 HelpSteer2。
-
数学:选自 OpenMathInstruct-2,包含近 60,000 个样本。
-
代码:整理自 leetcode 和 self-oss-instruct-sc2-exec-filter-50k,保留了包含测试用例的样本。
-
中文:整合了 alpaca_gpt4_zh 和 Magpie-Qwen2-Pro-200K-Chinese,过滤掉代码和数学问题,保留了大约 10,000 个高质量样本。
针对每个数据集的问题,研究团队主要从四个不同系列的源模型合成回复,包括 Gemma-2-27b-It、Mistral-Large-Instruct-2407、Qwen-2.5-72B-Instruct 和Llama-3.1-70B-Instruct。
-
指令遵循与通用对话:从所有源模型中对每个问题进行了五次采样。
-
数学:保留了原始数据集(OpenMathInstruct-2)中由 Llama-3.1-405B-Instruct 生成的回复,并额外使用 Qwen-2.5-Math-72B-Instruct 进行了采样。
-
代码:对每个问题从所有源模型进行了八次采样。
-
中文:仅包含了从 Qwen-2.5-72B-Instruct 中采样的单个回复。
由于不同领域数据存在各自特点,研究团队设计如下方案为每个领域构建 SFT 和 DPO 数据集。
-
指令遵循:为了给每个源模型生成的五个回复分配奖励分数,使用了 ArmoRM 进行标注。然后以 4:6 的比例将标注的数据划分为 SFT 和 DPO 数据集。在 SFT 阶段,选择具有最高奖励分数的回复。在 DPO 阶段,将来自同一源模型的回复进行配对,将具有最高奖励分数的指定为正样本,具有最低奖励分数的指定为负样本。确保每对正负样本之间的奖励分数差在 0.01 到 0.1 之间。
-
数学:首先通过与标准标签比较,标注了所有源模型的回复以评估其答案正确性,并使用 ArmoRM 标注奖励分数。然后,将数据集分为 SFT 阶段和 DPO 阶段。在 SFT 阶段,使用正确且具有最高奖励分数的回复。此选择确保了微调过程基于高质量且答案正确的回复。在 DPO 阶段,从同一源模型构建配对样本。正样本由正确且具有最高奖励分数的答案组成,负样本是错误且具有最低奖励分数的答案。为了在优化过程中确保有意义的比较,保持了正负样本对之间的奖励分数差在 0.01 到 0.1 之间。
-
代码:采用了由正确性分数和奖励分数组成的双评分系统进行代码评估。正确性分数评估代码是否通过了静态分析和测试用例,确保功能的准确性,奖励分数用于偏好评估,衡量回复的质量。在 SFT 阶段,使用通过所有测试用例且具有最高奖励分数的回复,确保模型在满足正确性和偏好标准的示例代码上进行微调。在 DPO 阶段,使用通过测试的高分回复作为正样本,使用未通过测试的低分回复作为负样本。目的是优化模型在训练过程中学习代码领域正确偏好的能力。且排除了所有模型回复都未能满足测试标准的实例。
-
中文:在 SFT 阶段,只使用从 Qwen-2.5-72B-Instruct 采样的回复,因为该模型在中文上经过优化,相较于其他模型具备明显优势。
最终数据集包含 158,784 条样本,其中 94,539 条用于 SFT 阶段,64,245 个偏好对用于DPO 阶段。数据集的整体构成如下所示。
04.结果评估
针对指令微调模型的评估主要集中在模型在指令遵循、自然语言理解、通用问答、推理、数学、代码等方面的性能。对于 FuseChat-3.0 的评估,包含了 14 个基准测试,划分为以下四类:
-
指令遵循任务:AlpacaEval-2、Arena-Hard、MTbench、AlignBench v1.1(中文)。
-
通用任务:LiveBench-0831、MMLU-Pro、MMLU-redux、GPQA-Diamond。
-
数学任务:GSM8K、MATH、AMC 23。
-
代码任务:HumanEval、MBPP、LiveCodeBench 2408-2411。
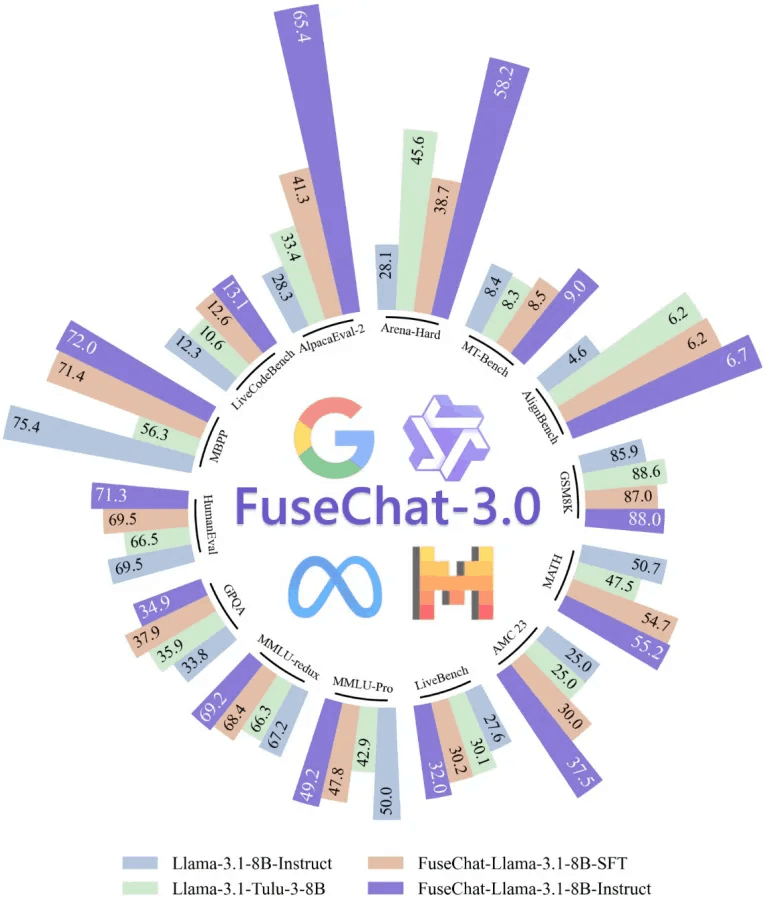
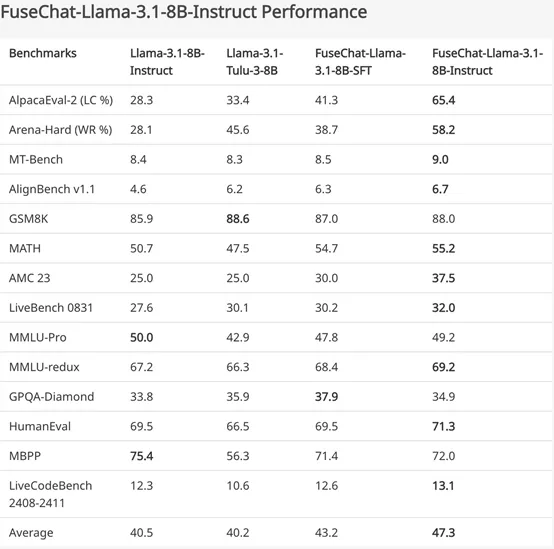
研究团队选择了多个目标模型进行实验,包括 Llama-3.1-8B-Instruct、Gemma-2-9B-It、Qwen-2.5-7B-Instruct,以及更小的Llama-3.2-3B-Instruct 和 Llama-3.2-1B-Instruct。在包括指令遵循、通用问答、数学推理、代码生成等 14 个基准测试上,FuseChat-3.0 显示出了显著的性能提升。
以 Llama-3.1-8B-Instruct 作为目标模型的实验为例,FuseChat-3.0在所有基准测试上的平均性能提升了 6.8 分。其中,在指令遵循测试集 AlpacaEval-2 和 Arena-Hard 上,性能分别提升了 37.1 分和 30.1 分,表现出色。
此外,和 AllenAI 最近发布的 Llama-3.1-Tulu-3-8B 模型对比,FuseChat-3.0 在除 GSM8K 和 GPQA-Diamond 外的所有基准测试中都展现出显著性能优势。关于更多目标模型上的实验结果,请参考原文(https://slit-ai.github.io/FuseChat-3.0)。
05.参考论文
[1] Wan F, Huang X, Cai D, et al. Knowledge Fusion of Large Language Models[C]//The Twelfth International Conference on Learning Representations.
[2] Wan F, Zhong L, Yang Z, et al. Fusechat: Knowledge fusion of chat models[J]. arXiv preprint arXiv:2408.07990, 2024.
[3]Yang Z, Wan F, Zhong L, et al. Weighted-Reward Preference Optimization for Implicit Model Fusion[J]. arXiv preprint arXiv:2412.03187, 2024.
点击 链接即可阅读全文:https://www.modelscope.cn/organization/FuseAI

ModelScope旨在打造下一代开源的模型即服务共享平台,为泛AI开发者提供灵活、易用、低成本的一站式模型服务产品,让模型应用更简单!
更多推荐



 0
0 0
0- 0



 已为社区贡献634条内容
已为社区贡献634条内容

所有评论(0)