
阿里 Qwen-2.5 Coder 32B 测评:成绩亮眼,实战为何让人失望?
Qwen-2.5 Coder系列是阿里巴巴推出的最新代码生成模型,具体信息来自于阿里巴巴发布的Qwen2.5-Coder Technical Report。根据该技术报告,Qwen-2.5 Coder在前一代CodeQwen1.5的基础上进行了大幅升级,推出了从0.5B到32B不同参数量的六个模型。作为一个代码专用模型,Qwen-2.5 Coder基于Qwen2.5架构构建,预训练数据规模超过5.
阿里 Qwen-2.5 Coder 32B 测评:成绩亮眼,实战为何让人失望?
原创 surfirst 非架构 2024年11月13日 23:25 北京
阿里巴巴最近(2024.11)发布的Qwen-2.5 Coder 32B在代码生成领域引起了广泛关注。这款模型作为专为代码生成设计的系列产品之一,不仅在多个基准测试上表现优异,还通过开放许可为开发者提供了更多实际应用的可能。然而,尽管在标准化测试中成绩亮眼,Qwen-2.5 Coder在真实的开发场景中的实战表现却不尽如人意。以下是对Qwen-2.5 Coder的详细评测。
1. Qwen-2.5 Coder 32B简介
Qwen-2.5 Coder系列是阿里巴巴推出的最新代码生成模型,具体信息来自于阿里巴巴发布的Qwen2.5-Coder Technical Report。根据该技术报告,Qwen-2.5 Coder在前一代CodeQwen1.5的基础上进行了大幅升级,推出了从0.5B到32B不同参数量的六个模型。作为一个代码专用模型,Qwen-2.5 Coder基于Qwen2.5架构构建,预训练数据规模超过5.5万亿标记,采用了严格的数据清洗、大规模的合成数据生成和数据平衡策略。这使得模型在代码生成、补全、推理和修复等任务中达到了SOTA(state-of-the-art)水平,甚至超过了其他同规模的大模型。
阿里巴巴团队认为,Qwen-2.5 Coder的发布将为代码智能领域带来新的研究契机,并通过其开放许可支持开发者在实际应用中广泛采用。
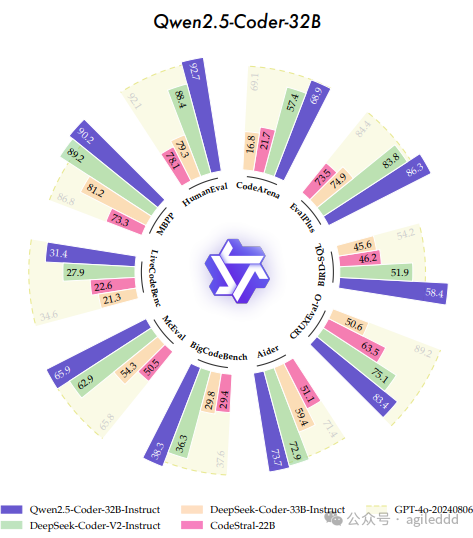
阿里团队的报告里的测评结果
2. Aider LLM Leaderboards表现
Aider测试方法
在Aider代码编辑榜单中,模型被要求在133个小型Python代码任务上完成代码编辑操作,这些任务来自Exercism。这些任务设计用来评估模型在代码修改、集成以及生成新代码片段时的准确性和效率。每个模型不仅需要在Python源文件中插入正确的代码,还要符合特定的编辑格式要求,并在无人工干预的情况下成功执行所有修改。这一测试标准能较好地衡量模型的编程能力、代码集成适配性及代码生成的自动化水平。
Qwen-2.5 Coder的表现评价
在这一评测中,Qwen-2.5 Coder-32B的表现相对优秀,完成了73.7%的任务,且编辑格式均符合要求。尽管如此,该模型的整体排名仍落后于Claude 3.5系列等顶尖模型,显示出在准确性和整合能力上的差距。Qwen-2.5 Coder虽具备一定的代码生成实力,但与其他领先模型相比,其在自动化代码修改和编辑精确度上仍有提升空间。尽管如此,这一成绩表明Qwen-2.5 Coder在Aider编辑榜单上的竞争力,尤其是其代码规范和格式的高匹配率值得肯定。
各模型的Aider评测结果
| 模型名称 | 完成率 (%) | 编辑格式符合率 (%) | Aider 命令 | 编辑方式 |
|---|---|---|---|---|
| Claude-3.5-Sonnet-20241022 | 84.2 | 99.2 | aider --model anthropic/claude-3-5-sonnet-20241022 |
diff |
| o1-preview | 79.7 | 93.2 | aider --model o1-preview |
diff |
| Claude-3.5-Sonnet-20240620 | 77.4 | 99.2 | aider --model claude-3.5-sonnet-20240620 |
diff |
| Claude-3.5-Haiku-20241022 | 75.2 | 95.5 | aider --model anthropic/claude-3-5-haiku-20241022 |
diff |
| Qwen2.5-Coder-32B-Instruct (whole) | 73.7 | 100.0 | aider --model openai/Qwen2.5-Coder-32B-Instruct |
whole |
| DeepSeek Coder V2 0724 (deprecated) | 72.9 | 97.7 | aider --model deepseek/deepseek-coder |
diff |
| GPT-4o-2024-05-13 | 72.9 | 96.2 | aider |
diff |
| ChatGPT-4o-latest | 72.2 | 97.0 | aider --model openai/chatgpt-4o-latest |
diff |
| DeepSeek V2.5 | 72.2 | 96.2 | aider --deepseek |
diff |
| Qwen2.5-Coder-32B-Instruct (diff) | 71.4 | 94.7 | aider --model openai/Qwen2.5-Coder-32B-Instruct |
diff |
| GPT-4o-2024-08-06 | 71.4 | 98.5 | aider --model openai/gpt-4o-2024-08-06 |
diff |
| o1-mini (whole) | 70.7 | 90.0 | aider --model o1-mini |
whole |
| DeepSeek Chat V2 0628 (deprecated) | 69.9 | 97.7 | aider --model deepseek/deepseek-chat |
diff |
以上结果显示Qwen-2.5 Coder在特定任务中具有一定竞争力,但尚未达到领先模型的顶尖水平,其准确率和集成表现还有提升空间。
3. 实际测试表现与不足
以下是国外最大视频网站的博主AICodeking测评后的评价。
3.1 Cline集成测试——初步测试与失望
Cline是一个VSCode插件,能够让用户直接在编辑器中调用大模型进行代码生成和修改,方便在开发流程中灵活应用LLM模型。博主首先通过Cline插件对Qwen-2.5 Coder进行了评估,以观察其在Next.js等复杂项目中的代码生成能力。初步测试显示,该模型在基本HTML项目上能够有效生成代码,但在Next.js项目的复杂任务中,模型的表现却显得不稳定。特别是在需要调用外部工具时,Qwen-2.5 Coder表现出工具调用不可靠、生成内容不够完整的缺陷。对比GPT-4、Claude 3.5 Sonnet和Deepseek等模型,Qwen在复杂项目的代码生成和上下文处理方面稍显不足。因此,Cline测试结果表明,该模型在多模块项目中的表现仍有待改进,难以满足高效代码生成的需求。
cline是一款AI辅助编码代理可以对接各种大模型
3.2 Aider集成测试——进一步测试与挫败
Aider是一个专为代码编辑设计的AI开发辅助工具,通过指令引导LLM在代码中进行精确的添加、编辑和调试。博主在Aider环境中对Qwen-2.5 Coder的代码编辑能力进行了深入测试,重点考察其在上下文理解和跨文件逻辑处理上的表现。测试中,通过Aider在Next.js项目内进行多次任务生成,结果显示该模型在较复杂的代码上下文中缺乏精确性。尤其是在跨文件的逻辑一致性和上下文理解方面,模型频繁出现错误,往往需要手动干预。这种局限性与博主对高效自动化代码生成的期望相去甚远。尽管Qwen-2.5 Coder在一些简单模块上实现了基本成功,但整体输出仍然偏向于简单代码,难以完成复杂项目的集成需求。
qwen 2.5 32B在aider里的集成过程
总体来看,这两项集成测试的结果表明,尽管Qwen-2.5 Coder在基准测试中表现不错,但在真实的开发场景中,其在稳定性、工具调用和代码集成方面仍有较大改进空间。
结论
综合来看,尽管Qwen-2.5 Coder在基准测试上取得了亮眼成绩,但其在实际开发环境中的表现不尽人意。我更倾向于选择Deepseek、Mistral Large和Cestal等模型,这些模型在日常开发中的表现更为可靠。Qwen的开发方向或许应该更多关注模型在真实应用中的适用性,而不仅仅是基准测试的表现分数。综上所述,Qwen-2.5 Coder的发布虽具有潜力,但当前版本尚不具备足够的实用性,不会是我个人的首选。
希望这篇评测文章对各位开发者了解Qwen-2.5 Coder的实际能力有所帮助,也期待该模型在未来的更新中进一步改进和优化。
参考链接
-
https://arxiv.org/pdf/2409.12186
-
https://aider.chat/docs/leaderboards/
推荐阅读

ModelScope旨在打造下一代开源的模型即服务共享平台,为泛AI开发者提供灵活、易用、低成本的一站式模型服务产品,让模型应用更简单!
更多推荐



 27
27 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)