
AI+硬件最新资讯合集(2024-11-05第2期)
一起来看看AI+硬件领域的最新动态

01「AI+硬件现状与趋势」
大厂纷纷盯上的AI可穿戴大赛道
AGI 结合硬件趋势
-
市场渗透趋势:大模型在低线城市普及率低,未来可能通过 AI Phone、AI PC 等建立认知,再拓展到更多硬件产品,以服务更广泛人群。
-
信息增长与 AI 助手需求:技术发展使信息密度持续上升,AGI 时代信息爆炸更甚,人类需 AI 助手处理信息,端云模型协同发展,端侧模型有隐私性、体验感和个性化等优势。
-
AGI 对消费硬件影响:AGI 结合硬件需综合多方面能力,AGI 增强了消费硬件技术,还提升了用户和场景的数据飞轮及用户对订阅服务接受度。
AI 可穿戴赛道概况
-
先锋产品现状:以 AI Pin 为例,虽其预订单高,但因诸多问题,如发热、反馈慢、错误率高、交互复杂等,受到较多负面评价,不过也显示出人们对不依赖手机设备的需求。
-
大厂动态:三星发布 Samsung Ring;字节跳动有多条产品线开发相关可穿戴硬件,PICO 研发相关产品且字节收购耳机制造商 Oladance;美团探索 AI 与硬件结合,其 “俏鱼” 业务与 “小天才” 合作;阿里天猫精灵多位高管创业。
AI可穿戴设备有什么?
包括人身上已经穿戴的眼镜(近远视人群最刚需)、手表、耳机、戒指、人身上尚未穿戴的磁吸物/粘贴物/吊坠等都是AI可穿戴设备。
举例:
-眼镜:Meta Ray-Ban、华为/小米音频眼镜
-手表:Apple Watch、小米运动手表
-耳机:科大讯飞/漫步者/JBL耳机
-戒指:Nova ring/oura ring
AI Native形态
作为新兴的一种AI native的创新形态硬件,目前各种产品的功能和形态差异较大。这一波AGI对于实现的可穿戴设备最大的两个功能加成看法是:1.AI agent(个人助手):处理/记录几秒钟以内的碎片化信息/任务并做信息整理;2.多模态输入:大模型从手机APP/网页端走进现实世界,并通过传感器先理解物理世界的问题,再通过语音交互像人一样去做交互。首先是需要又小巧又好用,第二是离眼耳鼻喉等感官越近越好。
作为新兴品类,目前可穿戴硬件类玩家数量还不多,主要包括Limitless pendant,Tab.AI, AI pin等。
Limitless Pendant 是一款创新的人工智能可穿戴设备
能捕捉并安全存储现实世界对话,以会议记录为主,利用 AI 语音转文本技术在本地处理数据,保证隐私前提下实现多种功能,如创建待办事项、生成会议摘要、情感洞察、捕捉灵感等,有效解决健忘问题。

Tab AI,全球首款生活伴侣式 AI 项链
通过声控和录音功能,全天候监听声音,利用大模型技术转录分析,提供定制化洞见,集成语音助手、实时翻译和日程管理等多功能,可成为智能伴侣,满足多场景需求,有望实现从纯工具到智能生活伴侣的转变,靠情绪价值留住用户。

Humane Ai Pin
硬件配置:AI Pin 是一款没有屏幕的独立穿戴设备,搭载高通骁龙八核芯片
AI能力:
-
内置有大模型以及 Humane 打造的 AI 功能,支持的 50 种语言,使其能够充当一个随身 AI 助手
-
Ai Pin 支持语音、手势交互,轻轻敲击正面的触控面板,即可唤醒,而无需使用唤醒词

眼镜形态
AI 眼镜
配备人工智能技术,如 Meta-Rayban,核心功能包括视觉助手(拍照、录像、物体等识别与智能提示分析)、语音助手(语音交互与命令执行),显示功能尚在开发中(未来将提供实时信息叠加和导航等丰富图显)。

音频眼镜
内置音频播放和通信功能,如华为智能眼镜 2,通过骨传导或微型扬声器传递声音,具备音频播放(无需耳机播放音乐 / 音频)、通话(蓝牙连接手机)和语音助手(语音交互命令执行)功能。

XR眼镜
包括 VR、AR 和 MR 技术,注重显示能力,如 XREAL Air2 Pro,MR 和 AR 可实现透视(分别采用视频透视和光学透视),能在现实世界叠加数字信息,应用于多领域。

AGI + 眼镜形态阶段性看法
-
技术门槛:可复用 XR 眼镜技术,但显示、续航、重量平衡难,加显示功能成本和重量剧增,当前多为音频耳机,下一步目标是加 AI 功能和显示。
-
产品形态:空间足可加多种传感器,听觉和视觉强,但 AI Agent 能力不成熟,目前功能基础,突破后前景可观。
-
市场潜力:消费者可接受一定溢价,但不戴眼镜者有额外成本。智能眼镜年出货量大于手机,是重要形态,音频眼镜已逐步普及,AR 眼镜需攻克技术难题实现体验突破,多数用户对轻便且有音频和拍照功能的眼镜接受度高(Meta rayban 已证明)。
耳机形态
在普通耳机基础上,集成传感器(部分含摄像头)、麦克风和计算单元,除音频播放外,实现语音交互,具备语音助手(可完成多种任务)、降噪(利用人工智能分析环境噪声)、实时录音转写(含智能拨号识别等及云端 AI 功能)、实时翻译等核心功能。

附上报道原文:
02「AI+电脑」
微软开源OmniParser
微软开源的基于大模型的屏幕解析工具 OmniParser,其可将 UI 截图转换成结构化元素,解析和理解 UI 的能力达到当前最佳水平,甚至超越 GPT - 4V。
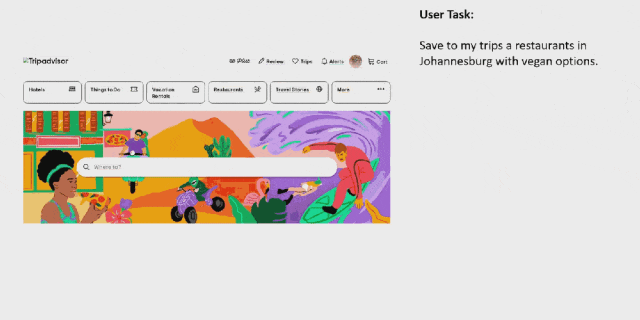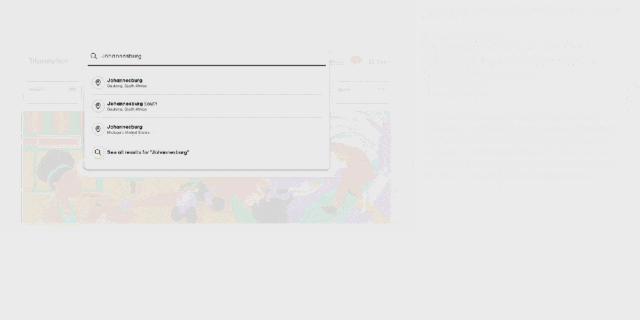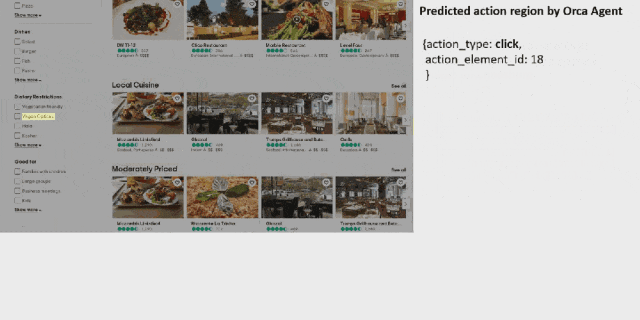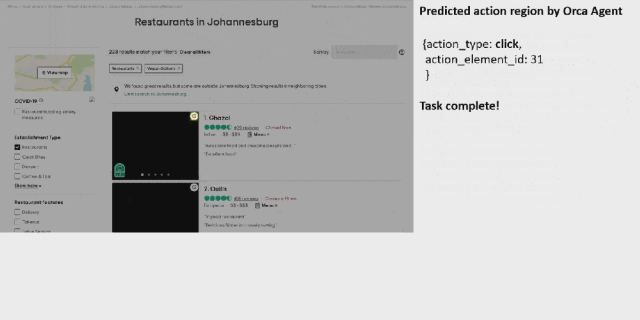
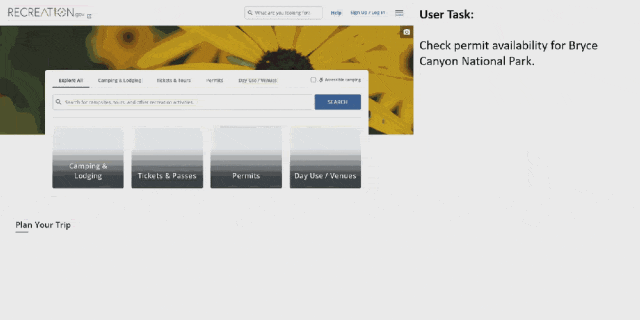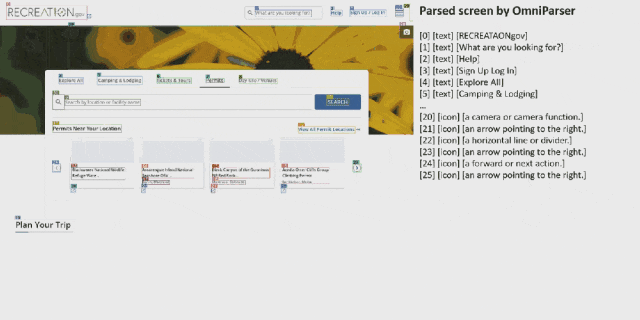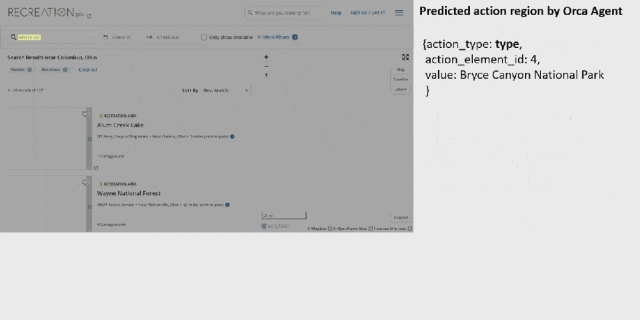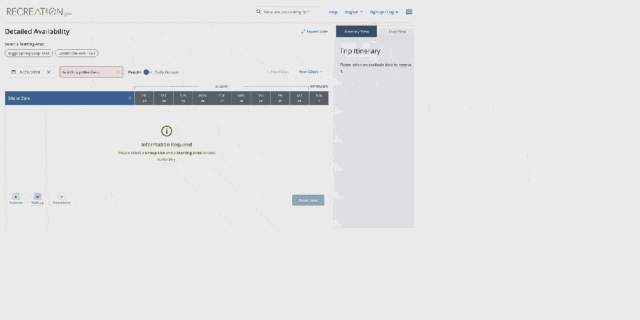
先来看看 OmniParser 的效果。对于一个用户任务:「将约翰内斯堡提供素食选择的餐厅保存到我的行程中」。
OmniParser 首先会解析 Tripadvisor 网页屏幕上的所有元素,然后它成功从中找到了「餐厅」选项。之后它点击(动作执行需要搭配其它模型)该选项,打开了一个搜索框。OmniParser 继续解析,这一次没有在屏幕上找到所需关键词,于是它在搜索框中输入了「约翰内斯堡」。再次解析后,它打开了相应的搜索项,展开了搜索结果。同样,继续解析,它成功定位到了素食选项,然后进行了勾选。最后,点击筛选出的第一个选项上的相应按钮将其收藏到行程中。至此,任务完成。
而如果你想看看能否进入布莱斯峡谷国家公园呢?OmniParser 也能助你轻松完成。
整体来看,OmniParser 的解析能力非常出色,过程也还算流畅。
附上报道原文:
控制电脑手机的智能体人人都能造,微软开源OmniParser
智谱自主智能体:把电脑交给大模型
像人类一样感知环境、规划任务、执行动作(如使用工具/软件),最终完成特定任务,是人工智能行业的下一个前沿发展方向,也是迈向通用人工智能(AGI)、超级智能(Super Intelligence)的必由之路。
基于在大语言模型(GLM 系列模型)、多模态模型和工具使用(Cog 系列模型)等方面的探索,在由自主智能体(Agent)驱动的人机交互新范式方面取得了一些阶段性成果:
CogAgent:Our Computer Use
CogAgent:一个替代终端用户理解、使用图形用户界面(GUI),完成信息获取和功能触发的智能体,更具泛化性和拟人性,目前支持在 Windows、macOS 软件上进行自然语言交互(包括打字输入和语音输入)、截图交互和划词交互;
基于CogAgent的应用:
①总结百科发微信、②淘宝购物、③预定会议、④虚拟屏幕

AutoGLM-Web:帮你网上冲浪
AutoGLM-Web:一个能模拟用户访问网页、点击网页的浏览器助手,可以根据用户指令在私域网站上完成高级检索并总结信息、模拟用户看网页的过程进行批量、快速的浏览并总结多个网页,结合历史邮件信息回复邮件。
基于AutoGLM-Web的应用:
①网页点餐、②旅游攻略、③总结论文
附上报道原文:
Mobile-Agent,实现了高级的RPA(Robotic Process Automation)功能
通义NLP实验室联合魔搭社区在今年2月份推出了Mobile-Agent框架(开源地址:https://github.com/X-PLUG/MobileAgent),在手机端和PC端实现了高级的RPA(Robotic Process Automation)功能。
PC端自主化操作
①通过浏览器访问网页并下载保存文件
②在Microsoft Word中创建新文档、编辑文本及保存文件
③通过浏览器访问网页并复制文字发送消息给阿里
附上报道原文: “今日热点:AI像人类一样使用手机和电脑”,魔搭社区的开源项目已先行一步
03「AI+手机」
情感语音+手机智能体AutoGLM
智谱清言推出的新功能——情感语音和手机智能体AutoGLM
-
不需要人工干预,在微信上批量总结公众号文章的内容
以下视频来源于
卡尔的AI沃茨

情感语音:
-
模拟不同的情感和语调,喜怒哀乐。
-
对话过程中动态调整语速快慢。
-
随时打断。打断 GPT 一般需要五到六个字,而智谱通常在第2个字就反应过来了。延长到一次完整对话里面,可以少重复2-3句话。
以下视频来源于
卡尔的AI沃茨
https://www.modelscope.cn/learn/750
以下视频来源于
卡尔的AI沃茨
手机智能体AutoGLM:
AutoGLM 仅仅是一款软件,就可以通过读取当前屏幕,做出任务规划,执行手机上的常用操作:
1. 在淘X上购买之前买过的产品

2. 在携X上订个高铁

3. 在X团里面买个螺蛳粉

4.涉及交易等重要操作,AutoGLM 会主动询问是否执行
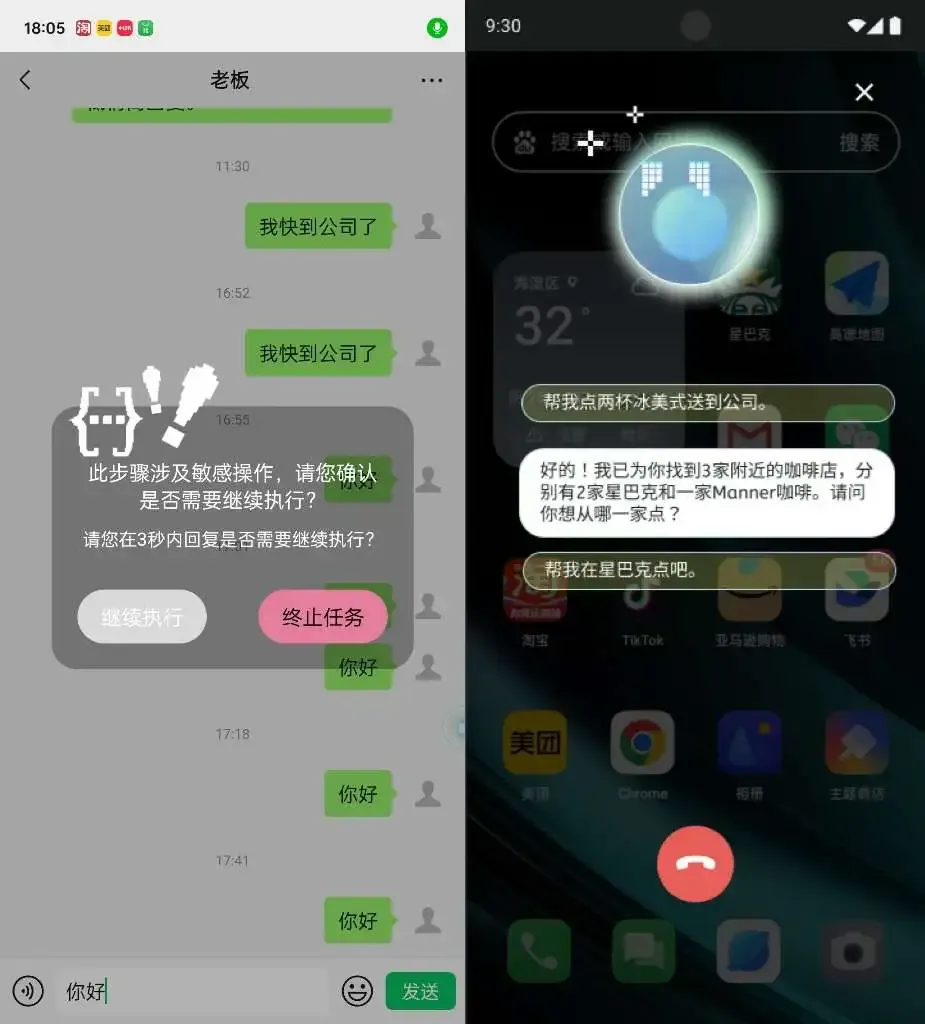
附上报道原文:
情感语音+手机智能体,智谱你是要取代我的Apple Intelligence了
Mobile-Agent,一句指令自动操作手机的高效移动设备操作助手
Mobile-Agent通过纯视觉方案,利用视觉感知工具和操作工具,实现了智能体在手机上的自动化操作,无需依赖系统级别的UI文件,展现了即插即用的能力。Mobile-Agent的推出,迅速在AI领域和手机制造商中引起了广泛关注。
一句指令操作手机
-
帮你点奶茶
-
帮你打微信视频电话
-
帮你搜索旅游攻略并发给自己微信好友
附上报道原文:
“今日热点:AI像人类一样使用手机和电脑”,魔搭社区的开源项目已先行一步
Datawhale—Task1:跑通Mobile-Agent Demo
Mobile-Agent(移动智能体)正逐步成为连接现实世界与数字世界的桥梁,Mobile-Agent:强大的移动设备操作助手家族是一个可以支持移动设备及其他终端设备与人工智能深度融合的多Agent框架。
先看几段 Mobile-Agent 演示案例:
-大模型智能体背景
-多模态手机智能体Mobile-Agent
-多模态手机智能体Mobile-Agent-V1
-多模态手机智能体Mobile-Agent-V2
可让你在200分钟,跑通 Mobile-Agent Demo!
200分Mobile-Agent Demo钟体验指南:
https://datawhaler.feishu.cn/wiki/BbEuwzZMXiWwxbkfFuHcflwrneg
04「AI+机器人」
智元机器人开源灵犀X1人形机器人全套图纸+代码]
稚晖君于 1024 程序员节开源智元人形机器人灵犀 X1 的全套资料,包括设计图纸和代码。

而这次的开源,相当于是把稚晖君快速造机器人的秘笈分享了出来,也是兑现了当时“人形机器人人人造”的诺言。虽然造的快,但当时在现场也是演示了灵犀X1不论如何被稚晖君“霸凌”都不会倒的平衡力:

灵犀 X1 相关特点:
由自研 PowerFlow 关节(PF86 和 PF52)搭建成,具备中空走线、输出端绝对值编码、支持 PF - Link 智能接口等功能,融入模块化设计理念,双手为自适应通用夹爪,执行器还可为六维力传感器,可开启 “机机模式”(用手机当脑子)。
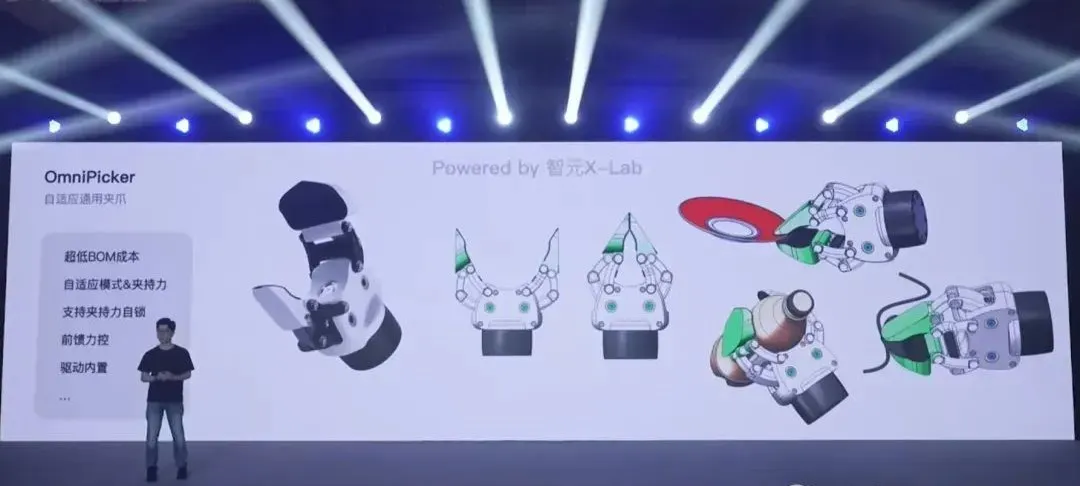
抓啥都行,甚至是桌面上平躺着的一根针,也能稳稳夹起来。


有点意思的是,灵犀X1可以开启“机机模式”。
简单来说,就是打开灵犀X1的脑子(里面本来是空的),把手机装进去,用性价比更高、功能更丰富、算力更强、普及率更广的手机,来当它的脑子。
然后大家就能看到以下这个又好笑又有点诡异的对话画面:

附上报道原文:
同济子豪兄麒麟臂-智能抓药机械臂
它可以通过语音对话了解用户病症并思考合适的药品,通过视觉理解模型识别不同药品,然后驱动机械臂抓取药物到指定的盘子。
附上报道原文:
“今日热点:AI像人类一样使用手机和电脑”,魔搭社区的开源项目已先行一步
具身智能的最新全面综述
具身智能基本概念:
是将机器学习算法适配至物理实体,与物理世界交互的人工智能范式,与 “软件智能体” 不同,强调智能体与物理环境交互,人形机器人是其代表产品。
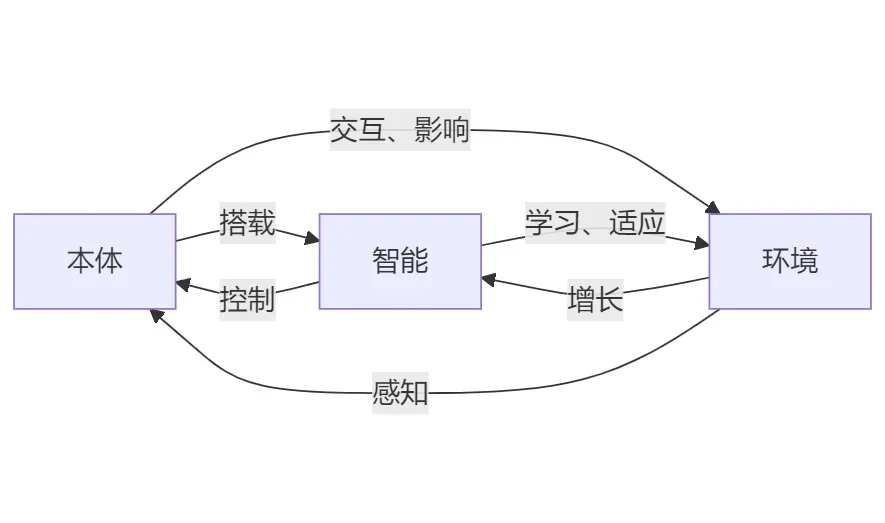
具身智能的三要素
-
本体:即硬件载体,不同环境适用不同形态硬件,如室内平地适用轮式机器人,崎岖地面适用四足机器人。
-
智能:包括大模型、语音、图像等算法。
-
环境:本体交互的物理世界,本体、智能、环境高度耦合是高级智能基础,智能算法可通过本体传感器感知环境、决策并操控本体执行动作影响环境,还可通过交互学习和拟人化思维适应环境实现智能增长。
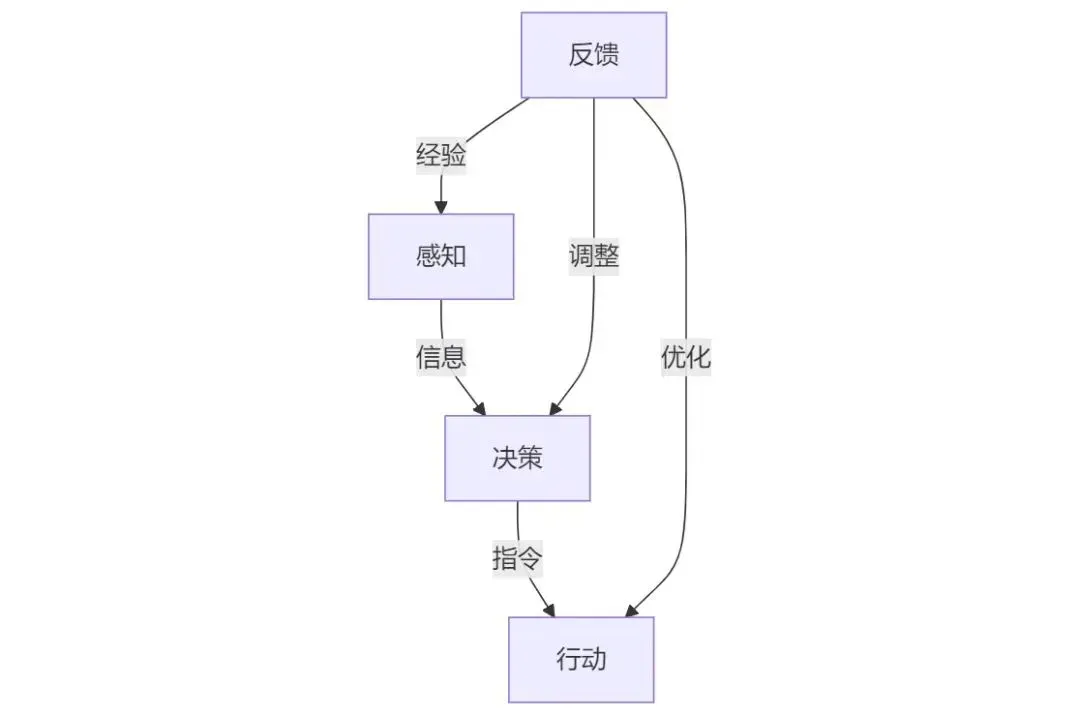
具身智能的四个模块
-
感知模块:通过多种传感器收集和处理信息感知环境,常见传感器有可见光相机、红外相机、深度相机、激光雷达、超声波传感器、压力传感器、麦克风等,不同传感器有不同功能,还可根据场景使用特定传感器,环境理解方面,稳定可控环境用特定场景模型,多变陌生环境需多模态大模型融合多种信息判断。
-
1. 可见光相机:负责收集彩色图像。
-
2. 红外相机:负责收集热成像、温度测量、夜视和透视。红外相机能够检测物体发出的热辐射,即使在完全黑暗的环境中也能生成图像。这种能力使得红外相机适用于夜视和热成像。红外相机可以测量物体表面的温度,广泛应用于设备过热检测、能源审计和医学成像等领域。某些红外相机能够穿透烟雾、雾气和其他遮挡物,适用于应急救援和安全监控。

-
3. 深度相机:负责测量图像中每个点与相机之间的距离,获取场景的三维坐标信息。

-
4. 激光雷达(LiDAR):负责测量目标物体的距离和速度。通过发射激光脉冲并接收反射回来的光来计算与物体的距离,生成高精度的三维点云数据,广泛应用于自动驾驶和机器人导航。

-
5. 超声波传感器:负责避障。通过发射超声波脉冲并接收这些脉冲的反射来确定机器人与障碍物之间的距离,判断障碍物是否存在。

-
6. 压力传感器:负责测量机器人手或脚部的压力,用于行走和抓取力的控制以及避障。

-
7. 麦克风:负责收音。

-
决策模块(大模型):是系统核心,早期依赖人工编程规则判断和专用算法,后强化学习方法有一定改进但仍有局限,大模型出现增强了具身智能体智能程度,具身智能体大模型是 AIGA,其发展方向是 VLA 和 VLN,未来多模态大模型与世界模型结合可实现感知预测,最终可能发展出端到端大模型融合多种功能实现低延时和强泛化。
-
行动模块:是 “执行单元”,任务包括移动和物体操作,实现精细动作控制是挑战,其响应决策指令生成动作有三种方式,从上到下技术不断进步,逐渐融合决策、行动和感知,提高行动模块能力和灵活性。
-
反馈模块:通过多层交互接收环境反馈经验调整优化,分别反馈感知、决策、行动模块,增强感知模块敏感度,帮助决策模块自我优化,使行动模块能适应环境变化。
附上报道原文:
05「其他+硬件」
智能戒指RingConn,出海爆卖超十万枚
RingConn 设计并量产了仅2克重、2毫米厚度、可续航12天的智能戒指。RingConn 通过实时监测心率、血氧水平等重要生命体征,提供连续、精准的健康数据。第二代产品在上线后的8小时内就销售了100万美元,受到海外科技媒体的广泛关注和报道。
联合创始人兼CEO 吴昊表示:我们选择智能戒指是因为它特别适合健康监测,有三个优点:首先,戒指小巧,佩戴感好;其次,适合夜间佩戴,可以24小时监测;最后,手指皮肤薄,信号质量比手腕好,能监测更多医疗级指标。


智能戒指是一个新兴增长的品类,预计未来几年内年出货量将超过千万部。
附上报道原文:
Z Potentials|吴昊,90后港大AI博士,出海爆卖超十万枚智能戒指RingConn
全球第一台柔性可穿戴录音AI硬件 Plaud NotePin
Notepin是Plaud公司卡片录音机后推出的第二款产品,选择了柔性可穿戴。第一款卡片机也成为了现象级产品,已交付~20万台,按每台售价$159计算,总销售额已破亿元人民币。 本次推出的第二款产品本质上在使用方式和交互上没有太大的区别,均基于录音功能,进行转写和内容总结。第二款柔性可穿戴更能捕捉使用者碎片化的信息记录需求,衍变出灵感,待办,会议记录等多类记录需求。

演示视频:https://x.com/i/status/1828779941028040792



附上报道原文:
产品 | 全球第一台柔性可穿戴录音AI硬件 Plaud NotePin
更多信息,请点击链接查看魔搭品牌馆~
https://modelscope.cn/brand/view/Mobile-Agent?branch=0&tree=?from=csdnzishequ_text?from=csdnzishequ_text

ModelScope旨在打造下一代开源的模型即服务共享平台,为泛AI开发者提供灵活、易用、低成本的一站式模型服务产品,让模型应用更简单!
更多推荐



 0
0 0
0- 0



 已为社区贡献633条内容
已为社区贡献633条内容

所有评论(0)