
git clone https://www.modelscope.cn/studios/MeissonFlow/meissonic.git
cd meissonic
pip install -r requirements.txtMeissonic:高效高分辨率文生图重大革新
Meissonic的新模型,仅1b参数可实现高质量图像生成,能在普通电脑上运行,未来有望支持无线端文本到图像的生成。
·
01前言

由阿里巴巴集团、Skywork AI和香港科技大学及其广州校区、浙江大学、加州大学伯克利分校联合的研究团队提出了一种名为Meissonic的新模型,仅1b参数可实现高质量图像生成,能在普通电脑上运行,未来有望支持无线端文本到图像的生成。
Meissonic旨在通过融合先进的技术和方法来提升非自回归图像生成器(MIM)在文本到图像(T2I)合成任务中的性能和效率。Meissonic主要通过引入改进的Transformer架构、高级位置编码策略以及动态采样条件,实现了对MIM技术的重大革新。
此外,该模型还利用高质量训练数据、微调条件和特征压缩层进一步提升了图像生成的质量和分辨率。实验结果表明,Meissonic不仅在高分辨率图像生成方面与当前最先进的扩散模型相媲美,而且其参数量远小于这些大型模型,能够在不牺牲性能的前提下运行在消费级GPU上,无需额外优化。总体而言,Meissonic代表了向高效、高质量文本到图像合成迈出了重要一步,同时为未来的相关研究提供了新的方向和技术参考。
近期,Collov-Labs开发的Monetico 是 Meissonic 的高效复制版。在 8 个 H100 GPU 上训练约一周后,Monetico 可以生成高质量的 512x512 图像,与 Meissonic 和 SDXL 生成的图像相当。今天也登录Huggingface趋势榜榜首。
模型链接:
https://modelscope.cn/models/AI-ModelScope/Monetico
在线Demo链接:
https://modelscope.cn/studios/AI-ModelScope/Monetico
关键要点
-
下一代高效文生图模型:Meissonic是一种基于masked discrete image token modeling的下一代文生图模型,非常高效。
-
改进的Transformer架构:通过结合多模态和单模态Transformers层,可以显著提高MIM训练效率和性能。
-
高级位置编码:使用RoPE进行编码位置信息,并使用动态采样条件来实现更好的图像细节和质量。
-
高质量训练数据:高质量的训练数据、微调条件和特征压缩层有助于提高生成能力。
-
高效生成,支持消费级显卡:Meissonic能够在消费者级GPU上运行,且不需要任何额外的优化。
02模型架构
Meissonic模型架构旨在通过集成框架促进高效高性能的文本到图像合成,该集成框架包括CLIP文本编码器,vector-quanlized(VQ)图像编码器和解码器,以及多模态Transformer backbone。下图显示了模型的整体结构。
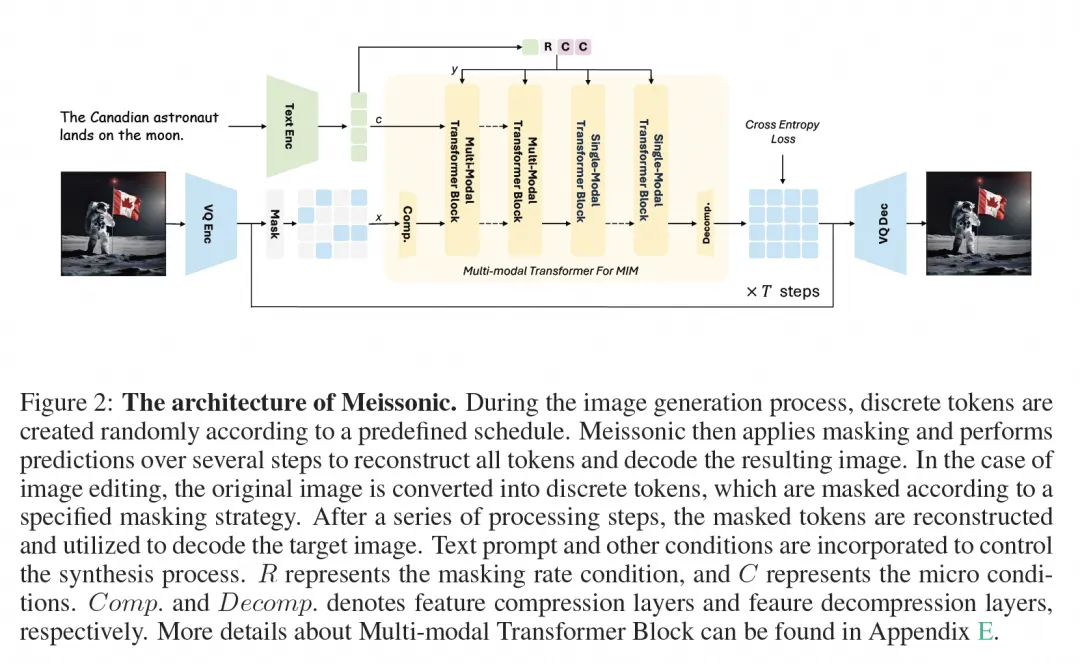
vector-quanlized图像编码器和解码器。
研究团队使用一个VQ-VAE模型将原始图像像素转换为离散的语义令牌。该模型包括一个编码器、一个解码器以及一个映射输入图像到由学习代码书生成的序列的离散令牌的量化层。对于大小为H×W的图像,编码的令牌尺寸是Hf×Wf,其中f表示下采样比。实现中,利用了f = 16的下采样比和8192个代码书大小,允许1024×1024图像被编码成64×64个离散令牌的序列。
灵活高效的文本编码器。
与之前广泛使用的大型语言模型编码器(例如T5-XXL1)不同,使用的是CLIP模型的最先进的单个文本编码器,其潜在维度为1024,然后对其进行微调以获得最佳的T2I性能。虽然这一决策可能会限制模型对较长文本提示的理解能力,但我们的观察表明,排除像T5这样的大规模文本编码器并不会降低视觉质量。此外,这种方法显著降低了GPU内存需求和计算成本。值得注意的是,在线提取T5特征需要大约11倍的处理时间和6倍的存储空间,这凸显了设计的高效性。
多模态Transformer backbone用于Masked Image Modeling。
Transformer架构建立在多模态Transformer框架之上,该框架包括采样参数r以编码采样参数和旋转位置嵌入(RoPE),用于空间信息编码。引入特征压缩层来高效处理高分辨率生成的大量离散令牌。这些层将嵌入特征从64×64压缩到32×32,然后通过变压器进行处理,并由后继的特征解压缩层恢复为64×64,从而减轻计算负担。为了增强训练稳定性并缓解NaN损失问题,在分布式训练期间遵循LLaMa的训练策略,在训练过程中实施梯度裁剪和检查点重新加载,并集成QK-Norm层进入架构。
多样化的微环境条件。
为了增强生成性能,引入了额外的条件,例如原始图像分辨率、裁剪坐标和人类偏好分数。这些条件被转换为正弦嵌入,并与最终文本编码器池化隐藏状态的附加通道进行拼接。
Masking策略。采用一个随余弦调度变化的可变掩蔽比率。具体来说,从以下密度函数所描述的截断反正切分布中随机采样一个掩蔽比率r∈ [0, 1],密度函数如下:
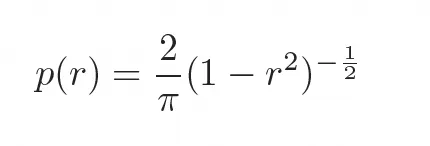
相比自回归模型为固定的标记顺序学习条件分布 ,本文的方法通过随机masking和可变比率来让模型学习 ,适用于任意标记子集 。这种灵活性对并行采样策略至关重要,并促进了各种零样本图像编辑能力。
03模型效果体验


04模型效果对比

05魔搭最佳实践
在魔搭社区免费算力运行webui
第一步:
打开免费算力(单卡A10)
第二步:
clone代码并安装依赖
第三步:
运行app.py
# 魔搭社区运行gradio,需要指定域名处dsw路径
export GRADIO_ROOT_PATH=/dsw-xxx/proxy/7860/
python app.py体验页面:
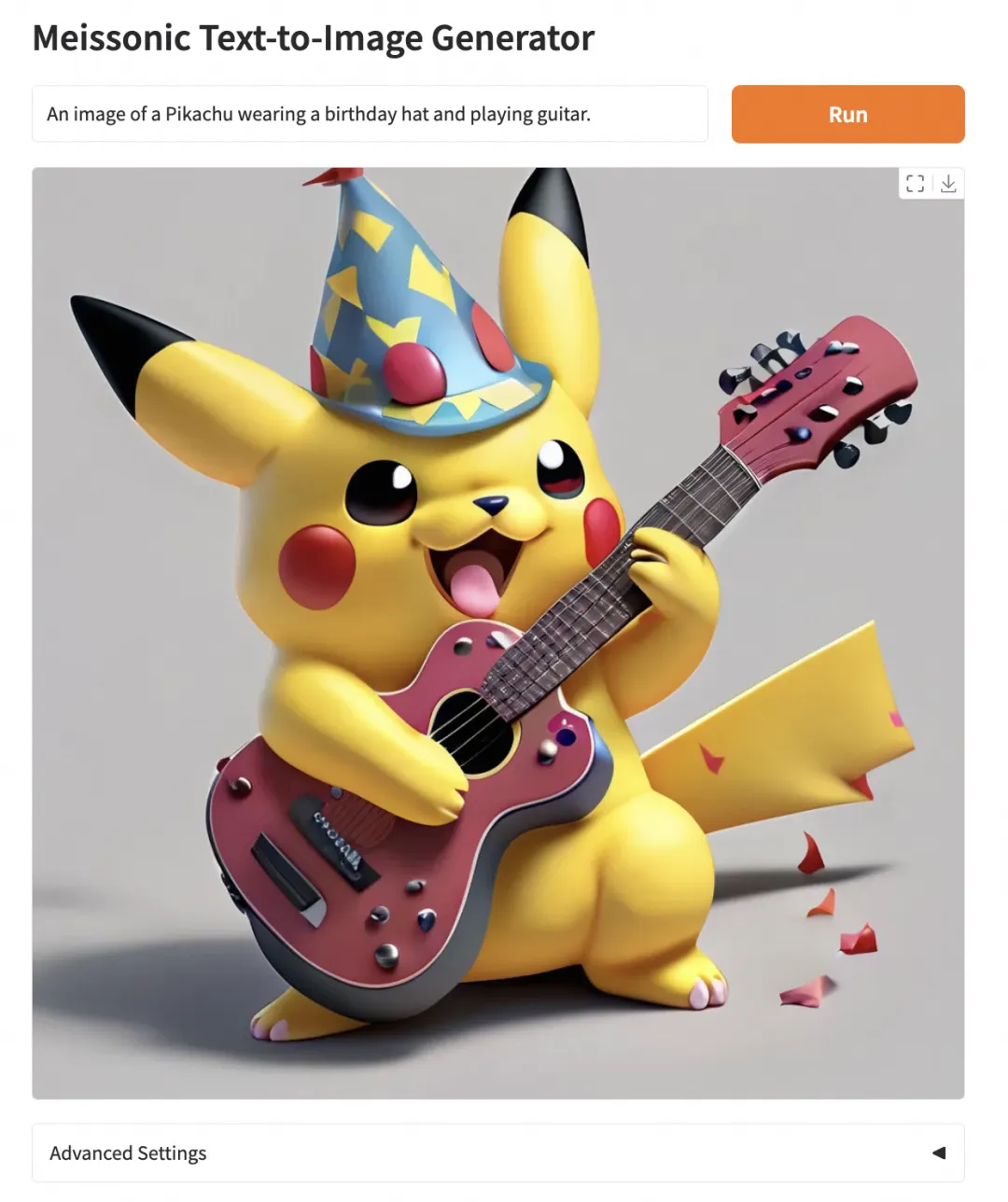
显存占用:
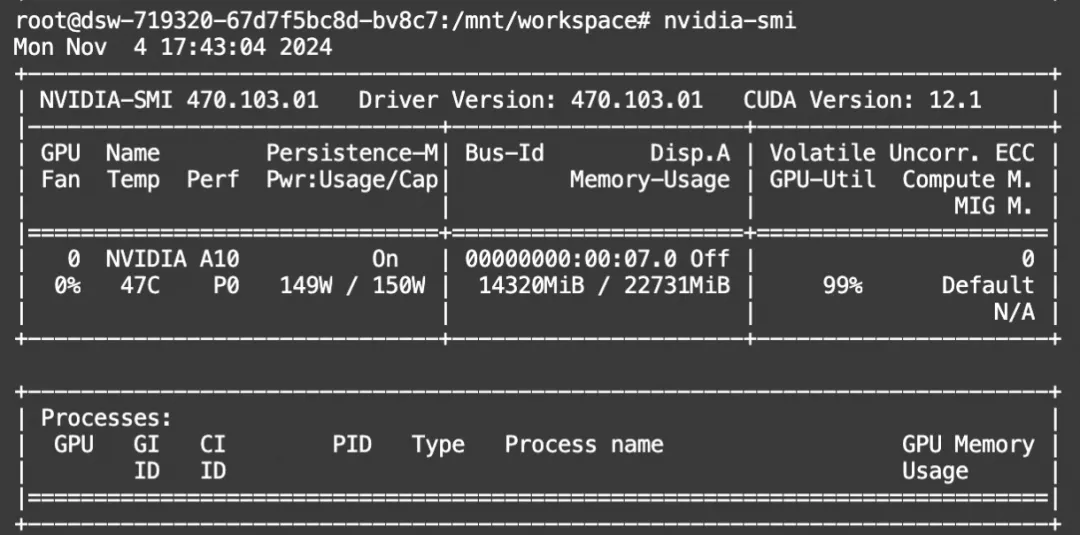
06未来展望
和作者沟通,Meissonic int4已经优化完毕,大概4GB显存就够了,狠狠的期待住了。
随着端侧设备的日益强大,离线文生图模型应用程序已经在移动端上线,例如 Google Pixel 9 的 Pixel Studio 和 Apple iPhone 16 的 Image Playground,我们期待Meissonic早日登上移动端设备,提供了高效高分辨率文生图能力的同时,离线运行能够更好的保护用户隐私。
文章链接:
https://arxiv.org/pdf/2410.08261
模型链接:
https://modelscope.cn/models/MeissonFlow/Meissonic
在线Demo链接:
https://modelscope.cn/studios/MeissonFlow/meissonic/

ModelScope旨在打造下一代开源的模型即服务共享平台,为泛AI开发者提供灵活、易用、低成本的一站式模型服务产品,让模型应用更简单!
更多推荐



 0
0 0
0- 0



 已为社区贡献629条内容
已为社区贡献629条内容

所有评论(0)