
from modelscope import AutoTokenizer, AutoModelForCausalLM
import torch
device = "cuda" # the device to load the model onto
model_path = "01ai/Yi-Coder-9B-Chat"
tokenizer = AutoTokenizer.from_pretrained(model_path)
model = AutoModelForCausalLM.from_pretrained(model_path, device_map="auto",torch_dtype=torch.bfloat16,).eval()
prompt = "Write a quick sort algorithm."
messages = [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
model_inputs = tokenizer([text], return_tensors="pt").to(device)
generated_ids = model.generate(
model_inputs.input_ids,
max_new_tokens=1024,
eos_token_id=tokenizer.eos_token_id
)
generated_ids = [
output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)
]
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
print(response)小而强大,零一万物编程小能手Yi-Coder系列模型开源!
9 月 5 日,零一万物开源了 Yi-Coder 系列模型,它作为 Yi 系列模型家族中的“编程小能手”,展现了卓越的代码生成能力。这是继今年 5 月 13 日开源 Yi-1.5 系列模型之后,零一万
·

在 AI 领域中,代码生成和编辑工具一直是开发者们关注的焦点。
9 月 5 日,零一万物开源了 Yi-Coder 系列模型,它作为 Yi 系列模型家族中的“编程小能手”,展现了卓越的代码生成能力。这是继今年 5 月 13 日开源 Yi-1.5 系列模型之后,零一万物在开源方向上的又一重要成果。
模型简介
Yi-Coder 系列模型专为编码任务而生,提供 1.5B 和 9B 两种参数。其中,Yi-Coder-9B 的表现优于其他 10B 参数以下的模型,如 CodeQwen1.5 7B 和 CodeGeex4 9B,甚至能够与 DeepSeek-Coder 33B 相媲美。
模型特点
-小参数,强性能:尽管 Yi-Coder 的参数量相对较小,但它在各种任务,包括代码生成、代码理解、代码调试和代码补全中的表现十分出色。10B 以下的大小也让它易于使用,方便端侧部署。
-128K 长序列建模:Yi-Coder 能够处理长达 128K tokens 的上下文内容,有效捕捉长期依赖关系,适用于复杂项目级代码的理解和生成。
-强大的代码生成能力:支持 52 种主要编程语言,Yi-Coder 在代码生成和跨文件代码补全方面表现优异
模型成绩
-
Yi-Coder 在代码生成基准测试中名列前茅
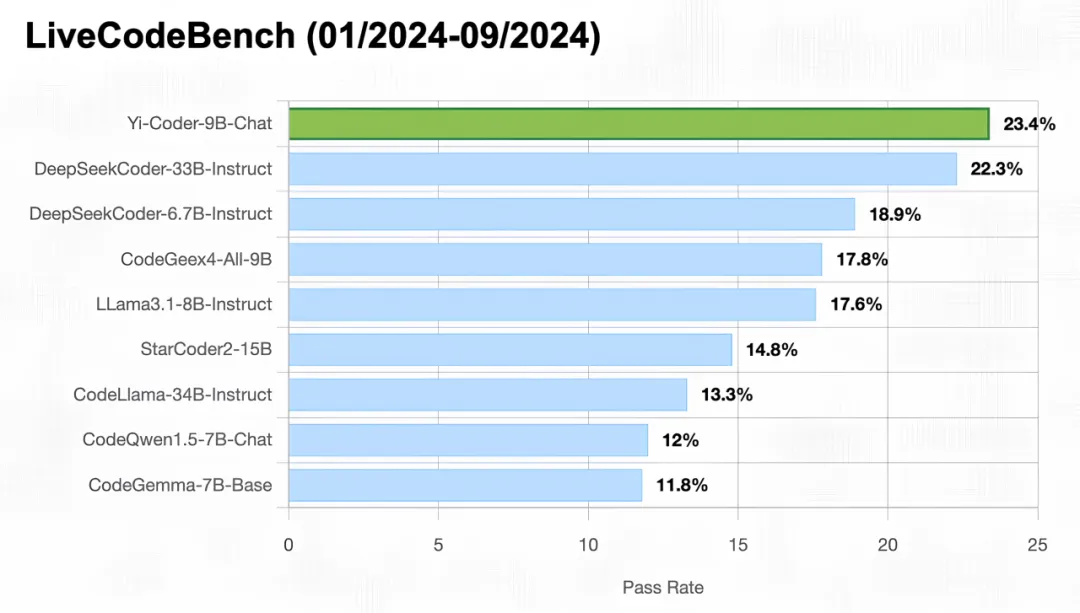
LiveCodeBench 是一个旨在为大语言模型提供全面公平的评测平台。它实时收集来自 LeetCode、AtCoder、CodeForces 等竞赛平台的新问题,构成了一个动态而全面的基准测试库。
为确保没有数据污染,由于Yi-Coder的训练数据截止时间是 2023 年底,选取了 2024 年 1 月到 9 月的题目进行测试。在下图榜单中,Yi-Coder-9B-Chat 的通过率达到了 23.4%,在 10B 以下参数量的模型中是唯一一个通过率超过 20% 的模型。
-
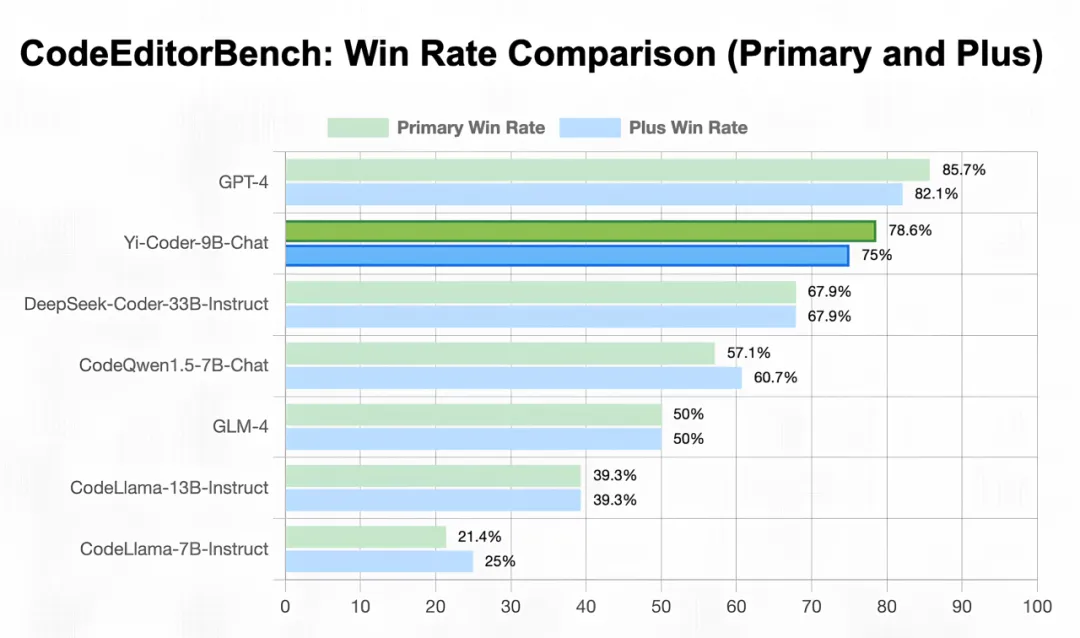
代码编辑和补全能力强劲
CodeEditorBench 涵盖了四个关键领域:代码调试、代码翻译、代码优化和代码需求转换。结果表明,在开源代码大语言模型中,Yi-Coder-9B-Chat 取得了优异的成绩,在 Primary 和 Plus 两个子集中始终优于 DeepSeek-Coder-33B-Instruct 和 CodeQwen1.5-7B-Chat。
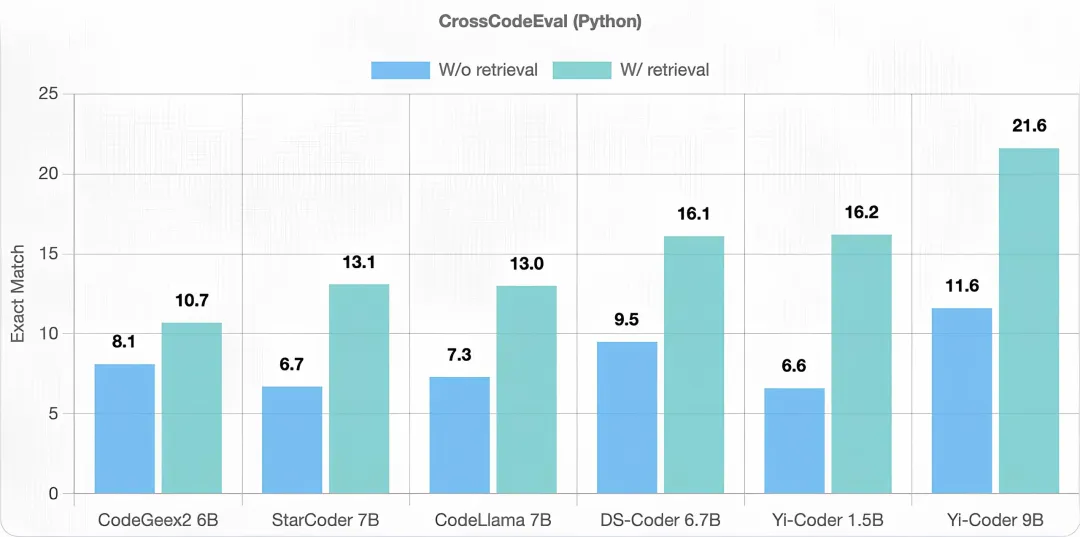
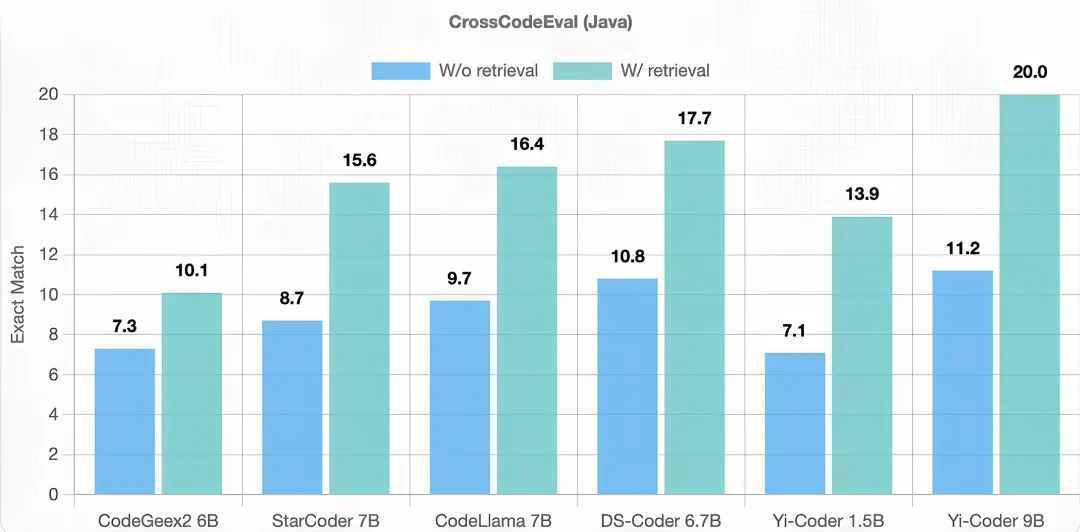
代码补全方面,Yi-Coder 也表现出色。与代码生成不同,跨文件代码补全要求模型访问并理解跨多个文件的资源库,这些文件之间存在大量的跨文件依赖关系。本次评估采用了 CrossCodeEval 基准,在两种不同的情况下进行:检索相关上下文和不检索相关上下文。
下图结果表明,Yi-Coder 在有检索和无检索的情况下都优于其他同等规模的模型。这一成功验证了在具有较长上下文长度的软件仓库级代码语料库上进行训练能够使 Yi-Coder 有效捕捉长期依赖关系,从而提高其性能。
-
长序列建模表现优秀
我们效仿文本领域流行的长序列评测,合成了一个 128K 长序列的“Needle in the code” 评估任务,长度双倍于 CodeQwen1.5 所构建的 64K 长序列评测。它通过在长代码库中随机插入一个简单的自定义函数,测试模型能否在代码库最后重复这个函数。该测试旨在检测模型LLM是否能从长文本中提取出这些关键信息,从而反映 LLM 其对长文本的理解基础能力。
下图全绿结果表示,Yi-Coder-9B 在 128K 长度范围内完美完成了这一任务。

-
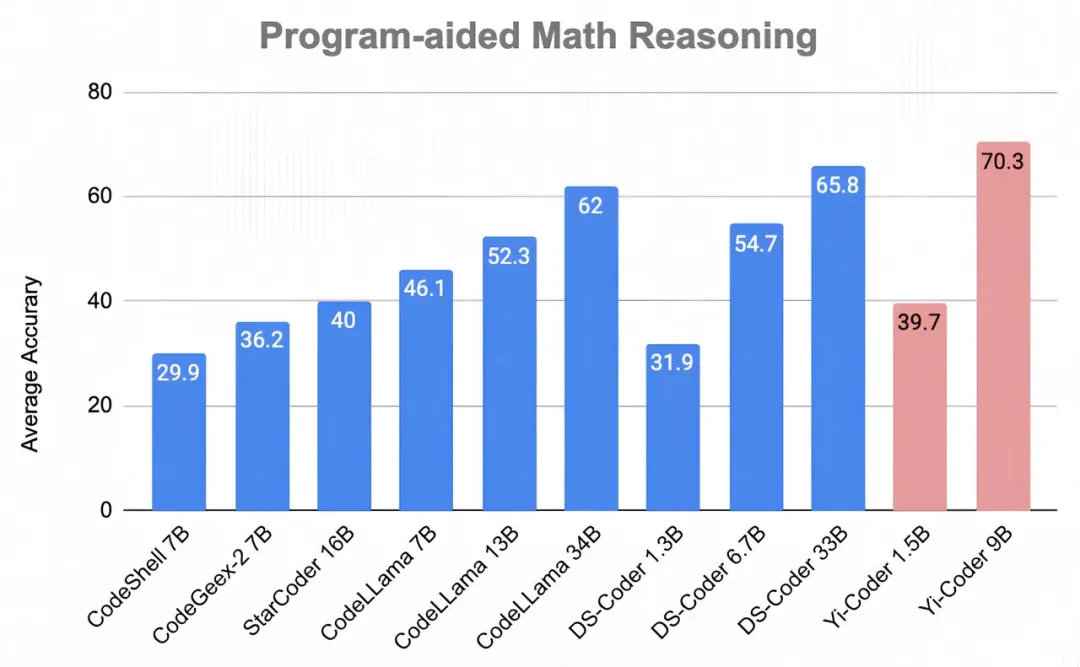
数学推理能力毫不逊色
DeepSeek Coder 先前的研究表明,模型强大的编码能力可以增强其数学推理能力。Yi-Coder 在七个数学题数据集上评估了代码辅助(PAL: Program-aided Language Models)解题能力,在每个数据集中,模型都要通过生成Python代码然后执行代码得出最后的答案。这七个任务的平均准确率得分如下图所示,Yi-Coder 9B的准确率达到 70.3%,超过了 DeepSeek-Coder 33B 的 65.8%。
模型使用
Transformers推理:
模型部署
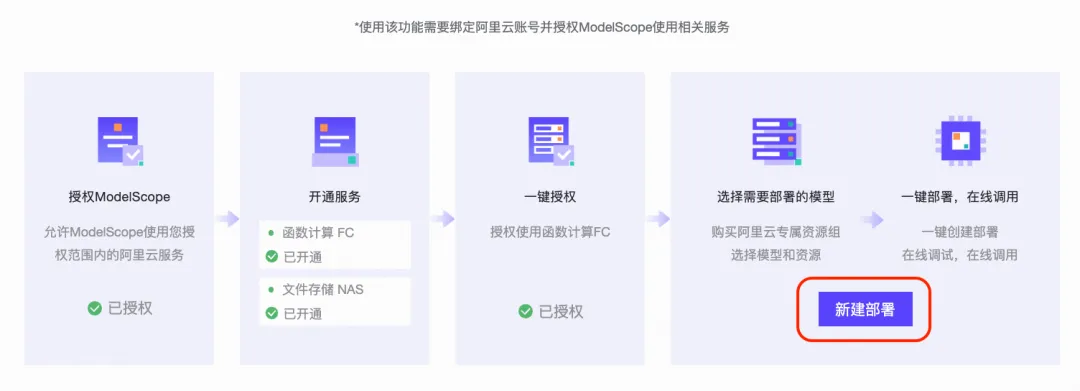
魔搭的SwingDeploy也在第一时间支持了Yi-Coder-9B模型的部署,一键将模型部署为OpenAI API兼容的专属服务。可从魔搭首页进入“模型服务->部署服务”,或直接访问
https://www.modelscope.cn/my/modelService/deploy
资源选择“函数计算(FC)”进行Serverless服务部署,如果第一次使用,按照页面提示账号绑定和授权即可:
点击“新建部署”后,可调出部署页面:
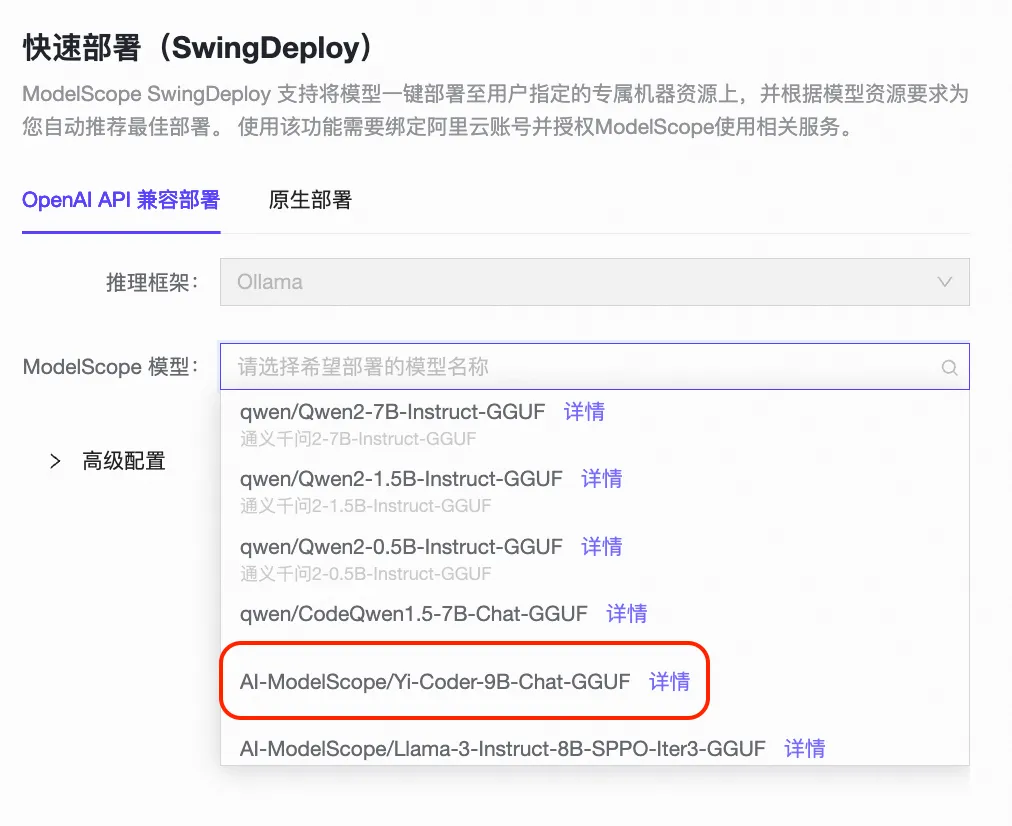
选择GGUF格式的Yi模型 “Yi-Coder-9B-Chat-GGUF”部署即可。Yi-Coder-9B模型量化后可在CPU上直接部署,也可以选择GPU资源部署(响应速度会更快)。

等待部署成功后,点击“立即使用”,就可以看到成功部署后使用OpenAI API以及SDK调用Yi-Coder模型的方法。
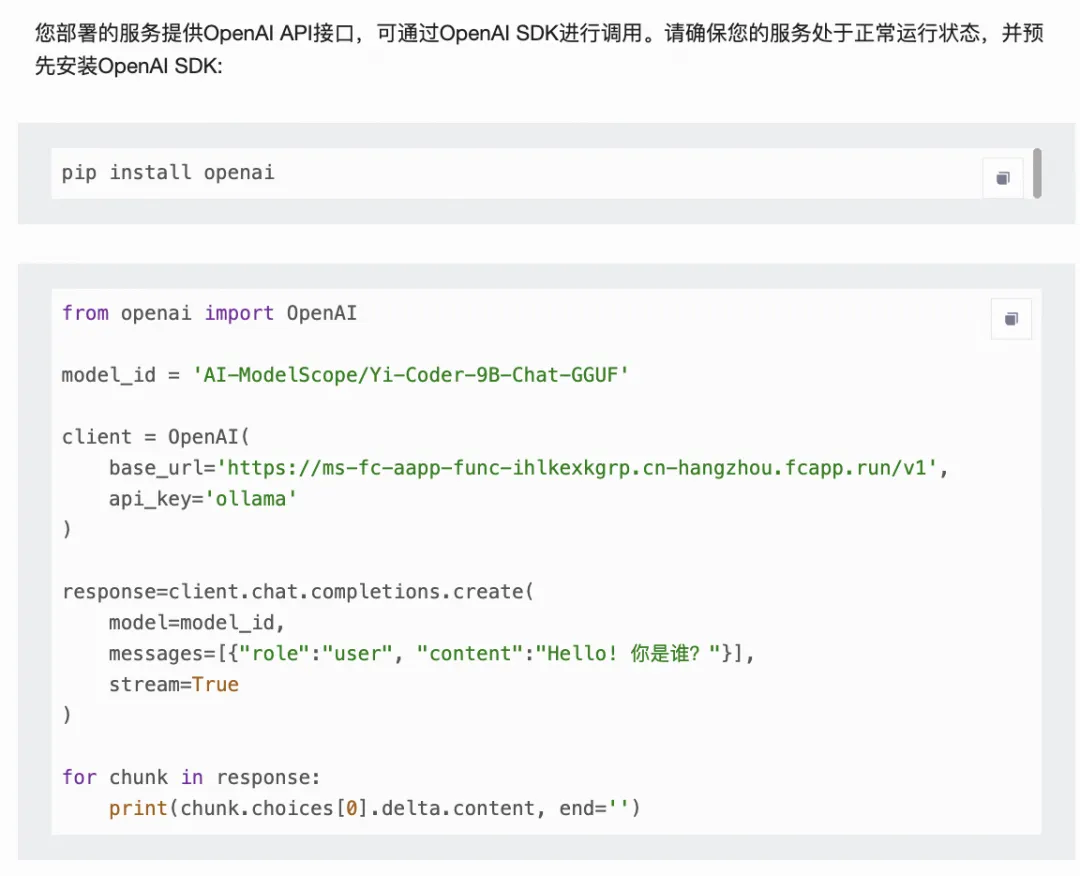
拷贝代码即可使用。
Note:因为是serverless部署,不使用的时候不计费,第一次调用首包可能要稍作等待
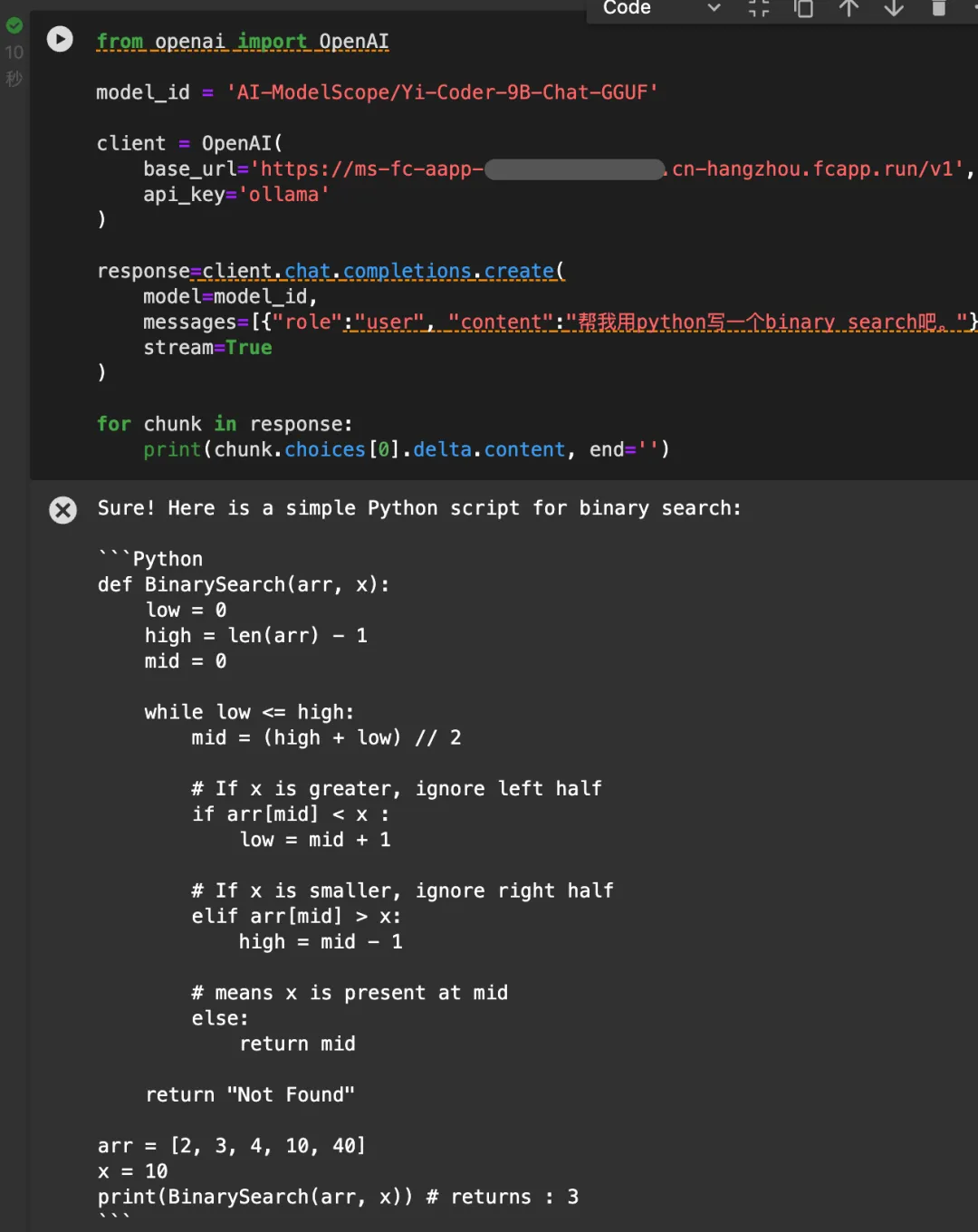
现在就可以将Yi-Coder-9B代码模型,通过OpenAI API兼容的方式,迅速接入你的各种应用开发,让它真正成为你的编程小助手啦!
Yi 开源系列模型家族现已包含 Yi、Yi-1.5、Yi-VL、Yi-Coder 等多款模型,我们鼓励大家探索大语言模型的更多可能,将 Yi 系列模型集成到他们的项目中,亲身体验其强大的性能。
🙌共勉!
点击链接,即可跳转模型详情~
https://modelscope.cn/models/01ai/Yi-Coder-9B-Chat?from=csdnzishequ_text?from=csdnzishequ_text

ModelScope旨在打造下一代开源的模型即服务共享平台,为泛AI开发者提供灵活、易用、低成本的一站式模型服务产品,让模型应用更简单!
更多推荐



 0
0 0
0- 0



 已为社区贡献634条内容
已为社区贡献634条内容

所有评论(0)