
from diffsynth import ModelManager, save_video, VideoData, download_models, CogVideoPipeline
from diffsynth.extensions.RIFE import RIFEInterpolater
import torch, os
os.environ["TOKENIZERS_PARALLELISM"] = "True"
def text_to_video(model_manager, prompt, seed, output_path):
pipe = CogVideoPipeline.from_model_manager(model_manager)
torch.manual_seed(seed)
video = pipe(
prompt=prompt,
height=480, width=720,
cfg_scale=7.0, num_inference_steps=200
)
save_video(video, output_path, fps=8, quality=5)
download_models(["CogVideoX-5B", "RIFE"])
model_manager = ModelManager(torch_dtype=torch.bfloat16)
model_manager.load_models([
"models/CogVideo/CogVideoX-5b/text_encoder",
"models/CogVideo/CogVideoX-5b/transformer",
"models/CogVideo/CogVideoX-5b/vae/diffusion_pytorch_model.safetensors",
"models/RIFE/flownet.pkl",
])
# Example 1
text_to_video(model_manager, "an astronaut riding a horse on Mars.", 0, "1_video_1.mp4")可控高清视频生成: CogVideoX+DiffSynth-Studio = “配置拉满”
·
不久前,CogVideoX 开源了 5B 版本的文生视频模型。现在,开源项目 DiffSynth-Studio 为 CogVideoX 提供了更强大的功能支持。在本期文章中,我们一起来看一下,在DiffSynth-Studio 的加持下,“配置拉满”的 CogVideoX 有多强!
样例展示
首先我们生成一个骑马的宇航员,使用的提示词是“an astronaut riding a horse on Mars.”。
示例代码:

然后,我们使用视频生视频功能,把宇航员改成一个机器人,使用的提示词是“a white robot riding a horse on Mars.”。
def edit_video(model_manager, prompt, seed, input_path, output_path):
pipe = CogVideoPipeline.from_model_manager(model_manager)
input_video = VideoData(video_file=input_path)
torch.manual_seed(seed)
video = pipe(
prompt=prompt,
height=480, width=720,
cfg_scale=7.0, num_inference_steps=200,
input_video=input_video, denoising_strength=0.7
)
save_video(video, output_path, fps=8, quality=5)
edit_video(model_manager, "a white robot riding a horse on Mars.", 1, "1_video_1.mp4", "1_video_2.mp4")
视频的分辨率和帧率似乎不高,我们提高分辨率到 960x1440,再使用插帧技术,让视频变得丝滑流畅。
def self_upscale(model_manager, prompt, seed, input_path, output_path):
pipe = CogVideoPipeline.from_model_manager(model_manager)
input_video = VideoData(video_file=input_path, height=480*2, width=720*2).raw_data()
torch.manual_seed(seed)
video = pipe(
prompt=prompt,
height=480*2, width=720*2,
cfg_scale=7.0, num_inference_steps=30,
input_video=input_video, denoising_strength=0.4, tiled=True
)
save_video(video, output_path, fps=8, quality=7)
def interpolate_video(model_manager, input_path, output_path):
rife = RIFEInterpolater.from_model_manager(model_manager)
video = VideoData(video_file=input_path).raw_data()
video = rife.interpolate(video, num_iter=2)
save_video(video, output_path, fps=32, quality=5)
self_upscale(model_manager, "a white robot riding a horse on Mars.", 2, "1_video_2.mp4", "1_video_3.mp4")
interpolate_video(model_manager, "1_video_3.mp4", "1_video_4.mp4")
再来看另外一个例子。
首先我们生成一只小狗,使用的提示词是“a dog is running.”。

然后,我们使用视频生视频功能,把小狗的项圈改成蓝色,使用的提示词是“a dog with blue collar.”。

视频的分辨率和帧率似乎不高,我们提高分辨率到 960x1440,再使用插帧技术,让视频变得丝滑流畅。

原理解析
在基础的文生视频功能中,DiffSynth-Studio 沿用了 CogVideoX 原版的处理流程,但我们发现,迭代步数对于生成视频的质量影响非常大。在迭代步数比较少时,小狗的腿部动作会有些混乱,在上述样例中,我们把迭代步数加到了 200 步。 迭代 20 步

迭代 50 步

迭代 200 步

基于文生图模型的图生图技术已经很成熟了,根据类似的思路,DiffSynth-Studio 实现了基于文生视频模型的视频生视频技术。具体来说,就是对视频加噪到中间步骤,然后重新运行迭代过程的后半段,模型就会根据提示词对画面中的内容进行编辑。
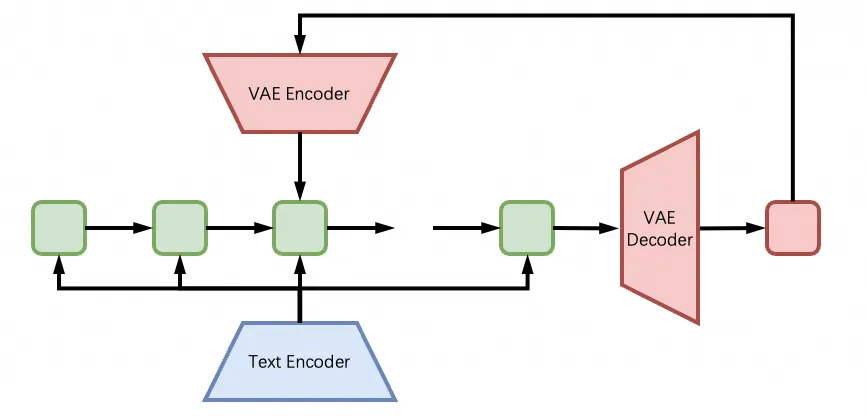
此外,DiffSynth-Studio 还借鉴了 SD-WebUI 中的高分辨率修复技术,将其应用到了 CogVideoX 上,原理和图生图类似,用模型自身重新润色高分辨率的视频。值得注意的是,由于模型本身位置编码的固定性,高分辨率视频无法直接输入给模型,所以 DiffSynth-Studio 采用了 tile 处理方式,每次只会把画面中的一部分输入给模型进行处理。
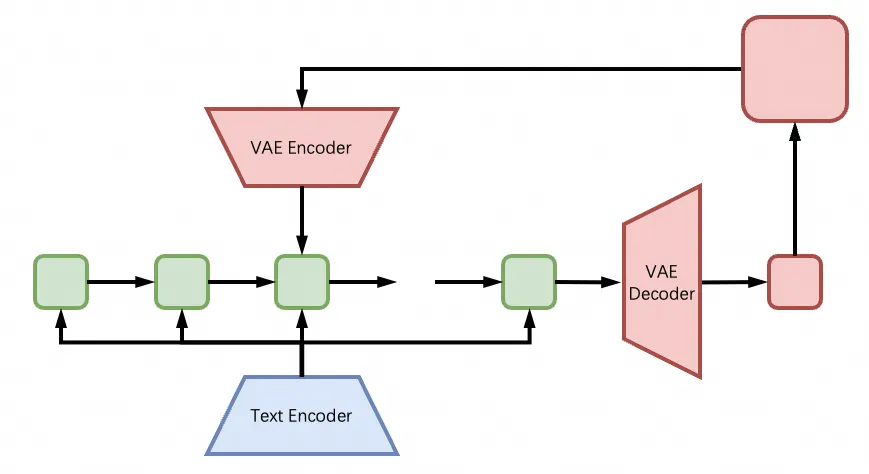
最后,CogVideoX 目前只能生成 49 帧,经过测试发现它还无法像“扩图”一样“扩视频”,但我们可以用插帧模型进一步处理它生成的视频,提高视频的帧率。上述样例中使用的插帧模型是 RIFE(Real-Time Intermediate Flow Estimation),插帧两次都得到 193 帧。
最佳实践
下载并安装 DiffSynth-Studio:
git clone https://github.com/modelscope/DiffSynth-Studio.git
cd DiffSynth-Studio
pip install -e .运行样例脚本(模型会自动下载):
python examples/video_synthesis/cogvideo_text_to_video.py由于这个脚本中开启了高分辨率修复,所以目前只有 80G 显存的显卡可以运行全部流程。

ModelScope旨在打造下一代开源的模型即服务共享平台,为泛AI开发者提供灵活、易用、低成本的一站式模型服务产品,让模型应用更简单!
更多推荐



 1
1 1
1- 0



 已为社区贡献634条内容
已为社区贡献634条内容

所有评论(0)