

引言
Mistral宣布推出新一代旗舰机型 Mistral Large 2。与前代产品相比,Mistral Large 2 在代码生成、数学和推理方面的能力显著增强。它还提供了更强大的多语言支持和高级函数调用功能。
Mistral Large 2 具有 128k 上下文窗口,支持法语、德语、西班牙语、意大利语、葡萄牙语、阿拉伯语、印地语、俄语、中文、日语和韩语等数十种语言,以及 Python、Java、C、C++、JavaScript 和 Bash 等 80 多种编码语言。
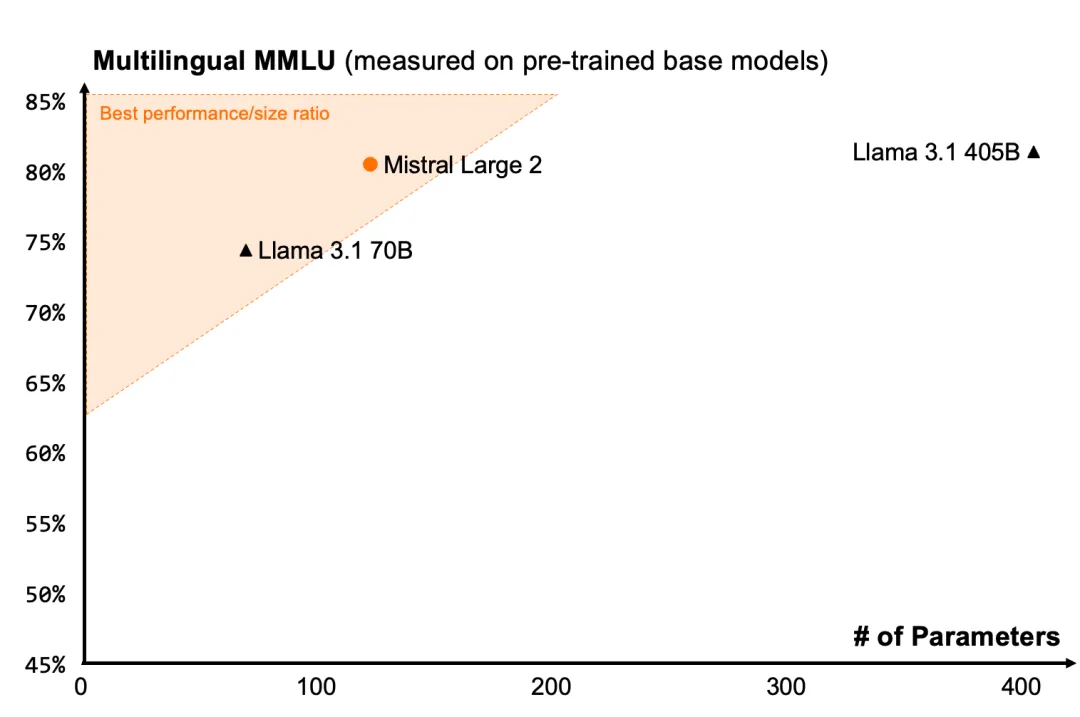
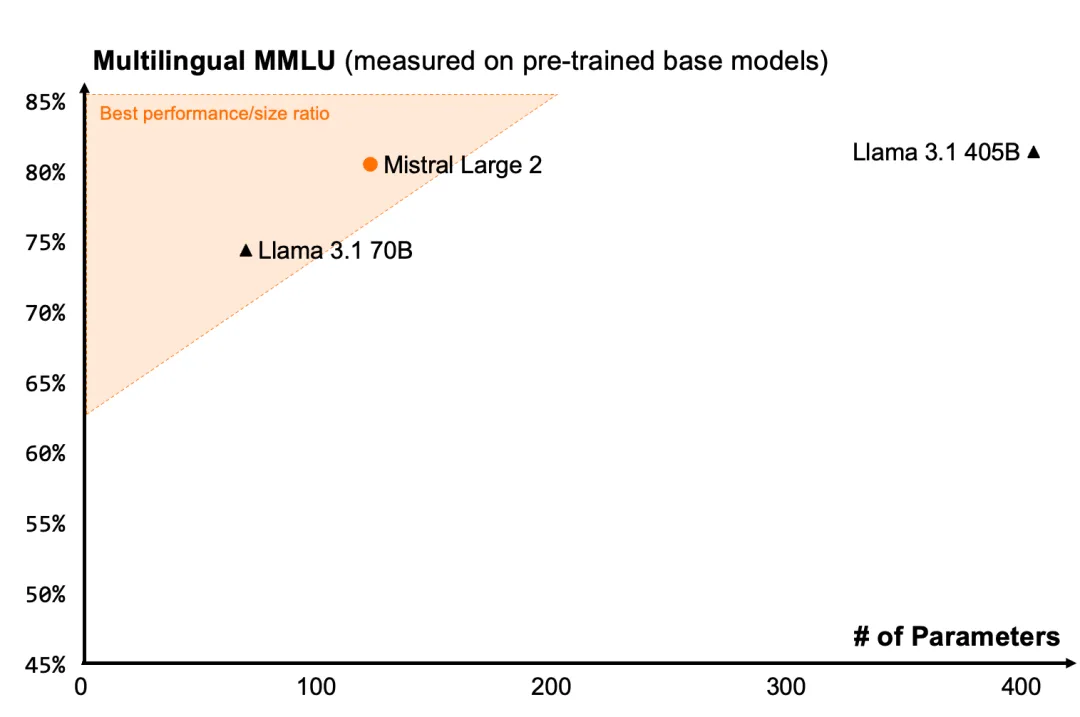
Mistral Large 2 在评估指标上在性能/服务成本方面树立了新标杆。特别是在 MMLU 上,预训练版本实现了 84.0% 的准确率,并在开放模型的性能/成本树立了新标杆。
模型链接和下载
模型链接:
https://modelscope.cn/models/LLM-Research/Mistral-Large-Instruct-2407
模型下载:
from modelscope import snapshot_download
# 可仅下载model safetensor文件
model_dir = snapshot_download('LLM-Research/Mistral-Large-Instruct-2407', ignore_file_pattern=['^consolidated'])模型license: Mistral Research License, 仅允许用于在学术和非商用场景的使用
模型推理
升级transformers版本
pip install git+https://github.com/huggingface/transformers.git推理代码:
from transformers import pipeline
from modelscope import snapshot_download
model_dir=snapshot_download('LLM-Research/Mistral-Large-Instruct-2407', ignore_file_pattern=['^consolidated'])
messages = [
{"role": "system", "content": "You are a pirate chatbot who always responds in pirate speak!"},
{"role": "user", "content": "Who are you?"},
]
chatbot = pipeline("text-generation", model=model_dir)
chatbot(messages)模型效果
数学:最近很火的比大小
中文错了:


英文对了:


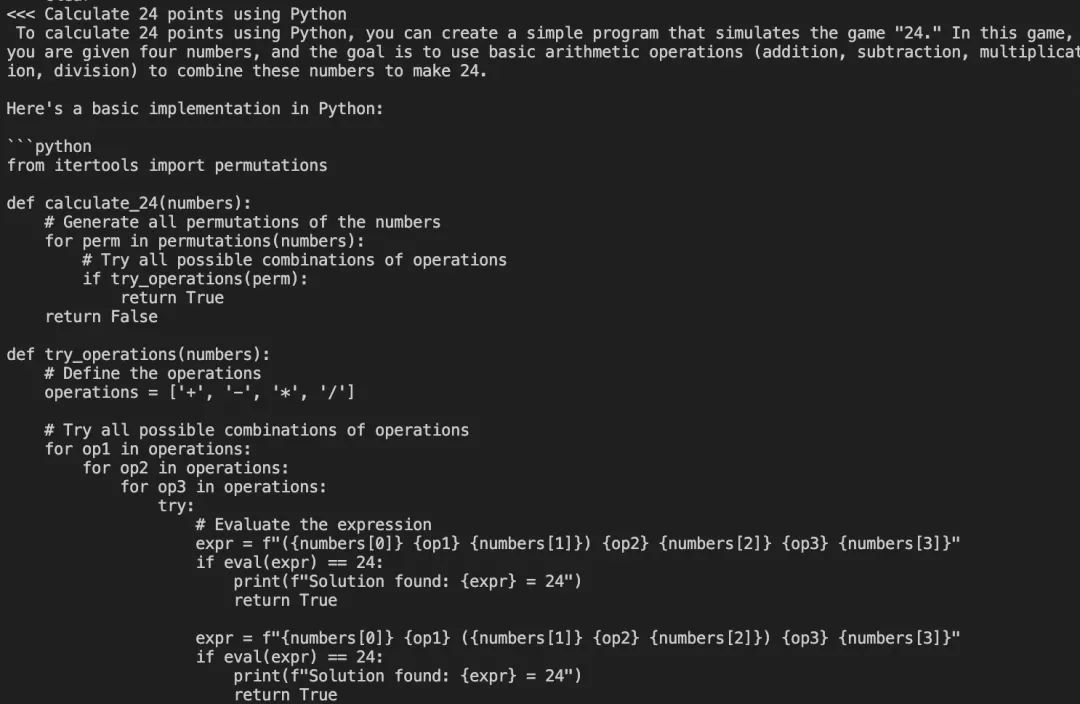
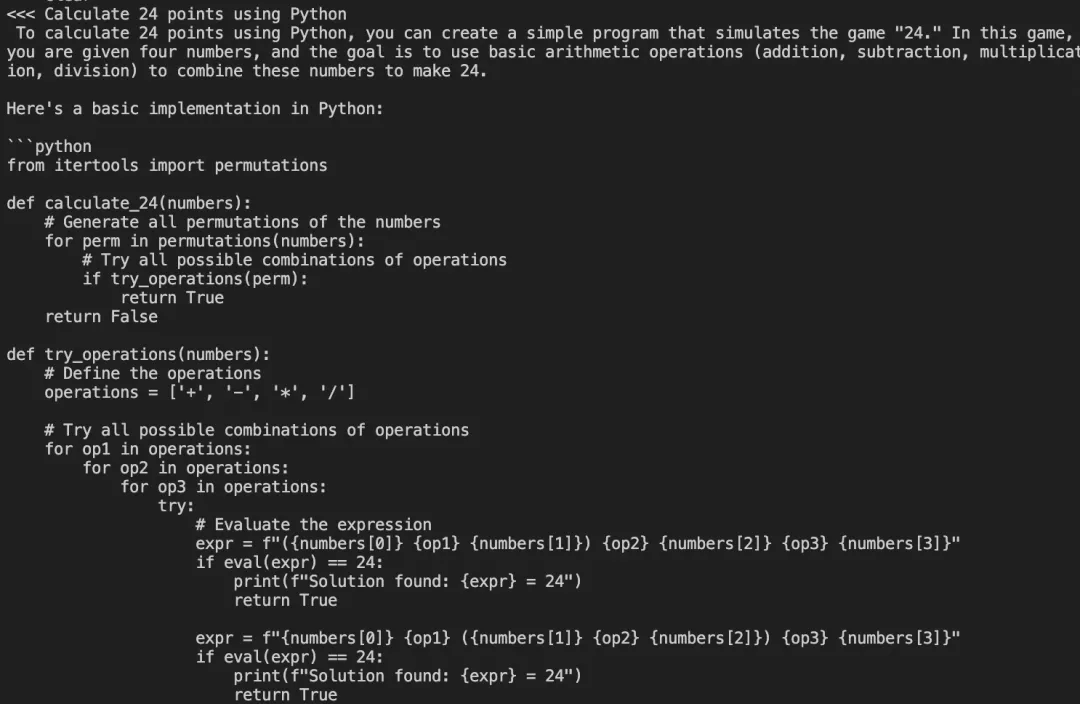
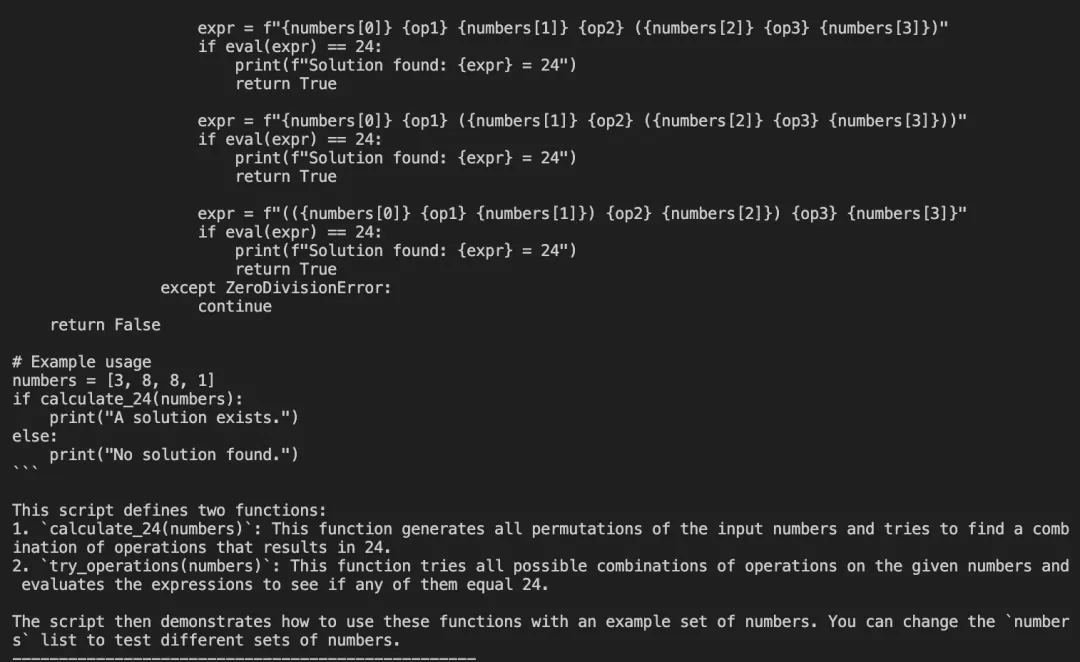
代码:写一个24点
中文错了:
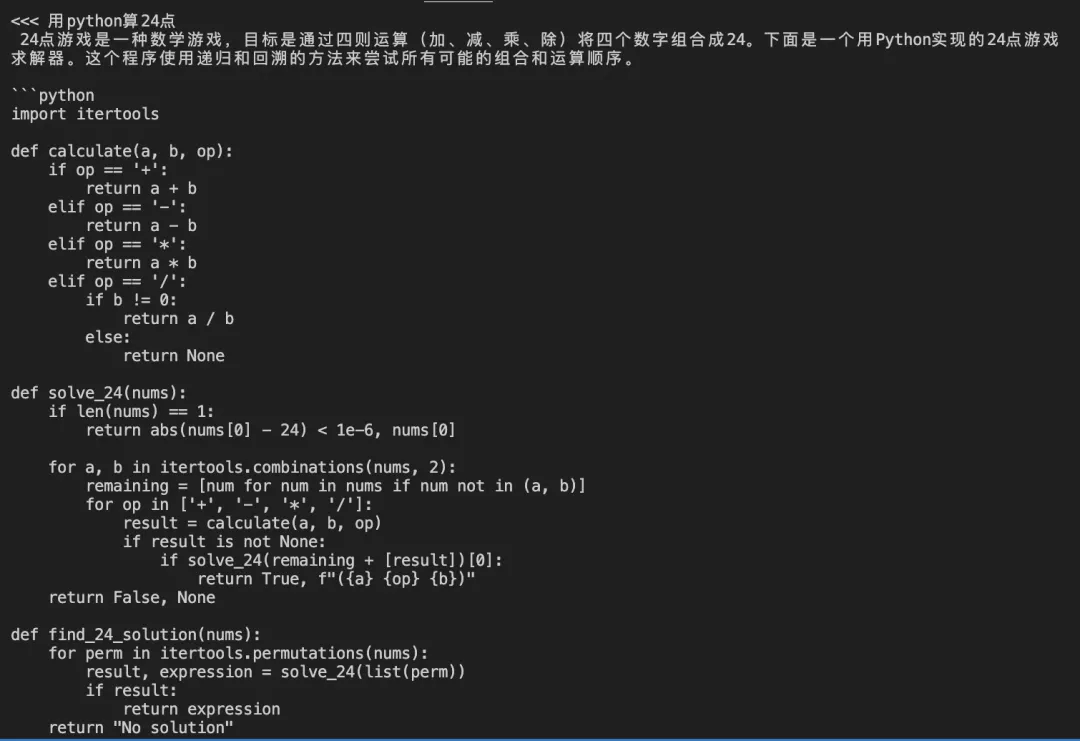
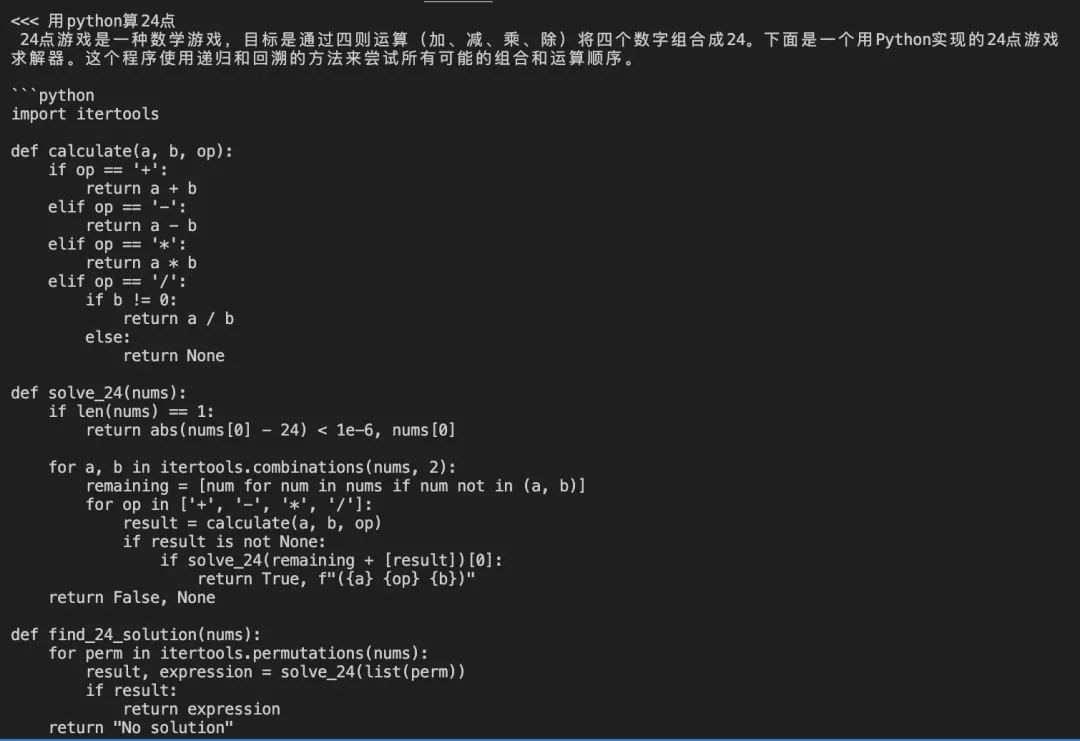


英文对了:
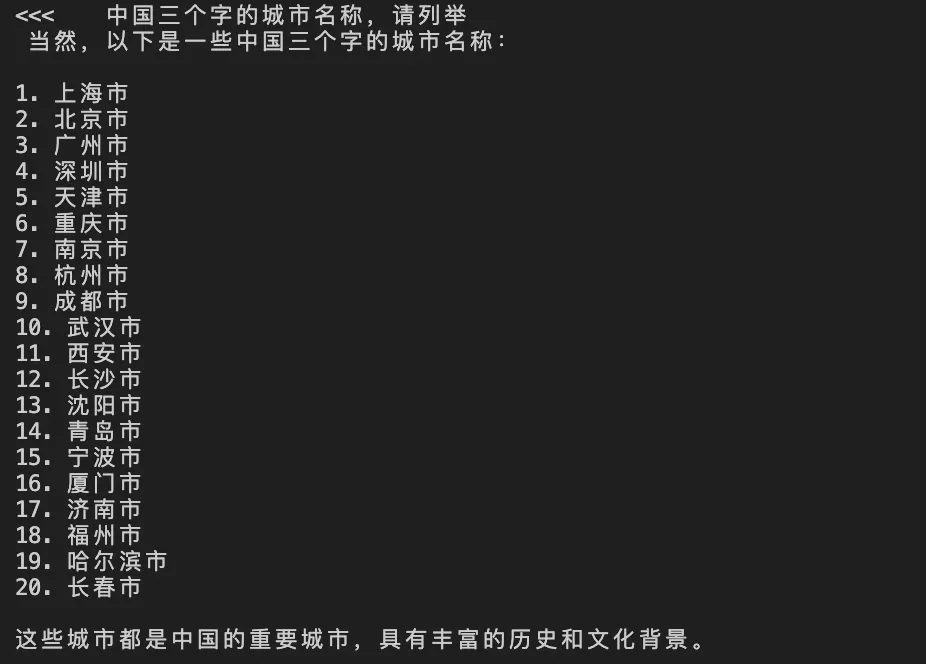
常识问答,城市名:
中文:

英文:


模型微调
我们介绍使用ms-swift对mistral-large-instruct-2407进行自我认知微调,并对微调前后的模型进行推理。swift是魔搭社区官方提供的LLM工具箱,支持300+大语言模型和50+多模态大模型的微调、推理、量化、评估和部署。
swift开源地址:
https://github.com/modelscope/swift
自我认知数据集:
https://modelscope.cn/datasets/swift/self-cognition
这里我们只展示可直接运行的demo,如果需要使用其他数据集进行微调,只需要修改 --dataset即可。自定义dataset支持传入本地路径、modelscope和huggingface中的dataset_id。
文档可以查看:https://github.com/modelscope/swift/blob/main/docs/source/LLM/%E8%87%AA%E5%AE%9A%E4%B9%89%E4%B8%8E%E6%8B%93%E5%B1%95.md#%E8%87%AA%E5%AE%9A%E4%B9%89%E6%95%B0%E6%8D%AE%E9%9B%86
在开始微调之前,请确保您的环境已正确安装
# 安装ms-swift
git clone https://github.com/modelscope/swift.git
cd swift
pip install -e .[llm]
pip install transformers>=4.43
# 如果要使用推理加速
pip install vllm>=0.5.3.post1微调脚本:(如果出现显存不足,请增加GPU数量)
# 实验环境: 4 * A100
# 训练时间: 40小时
# 4 * 80GB GPU memory
NPROC_PER_NODE=4 \
CUDA_VISIBLE_DEVICES=0,1,2,3 swift sft \
--model_type mistral-large-instruct-2407 \
--dataset alpaca-zh#500 alpaca-en#500 self-cognition#500 \
--logging_steps 5 \
--max_length 2048 \
--learning_rate 1e-4 \
--output_dir output \
--lora_target_modules ALL \
--model_name 小黄 'Xiao Huang' \
--model_author 魔搭 ModelScope \
--deepspeed default-zero3微调显存消耗:
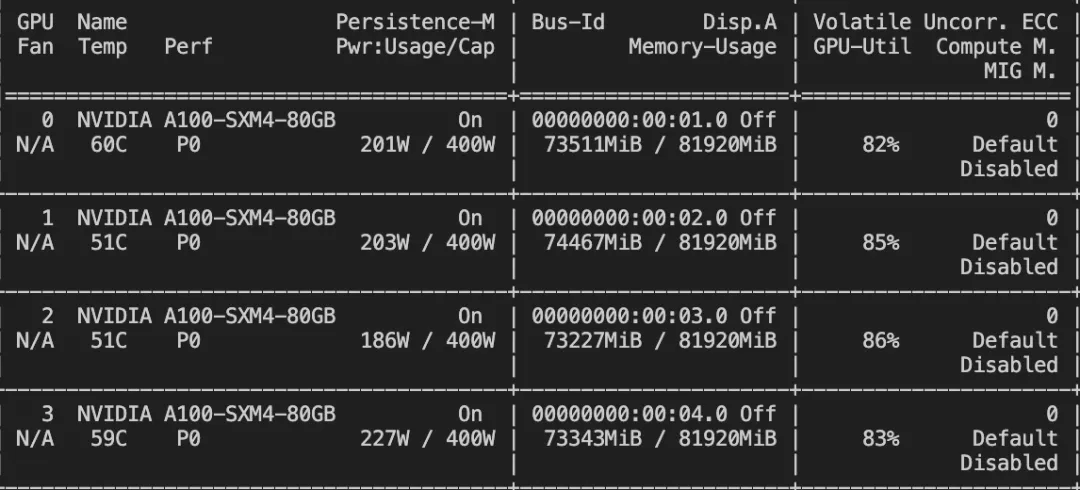
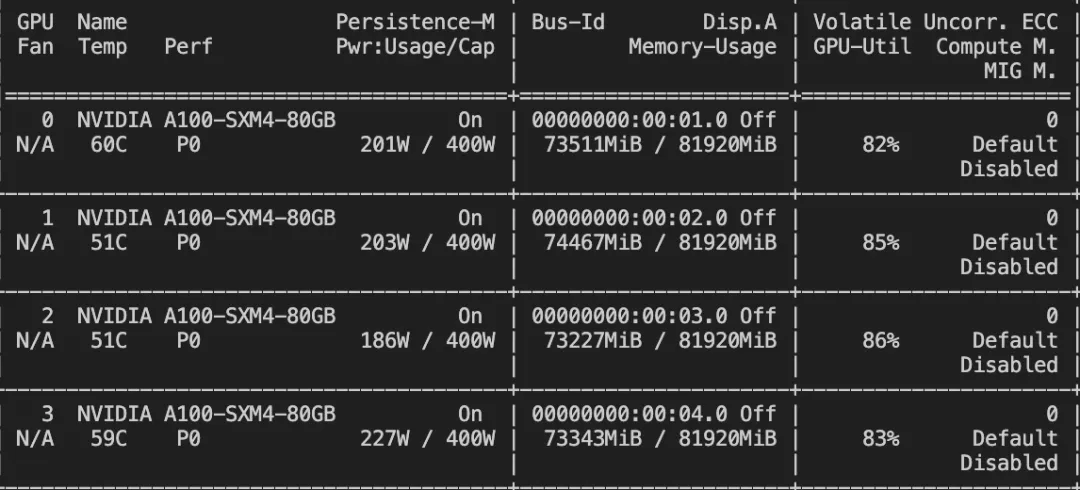
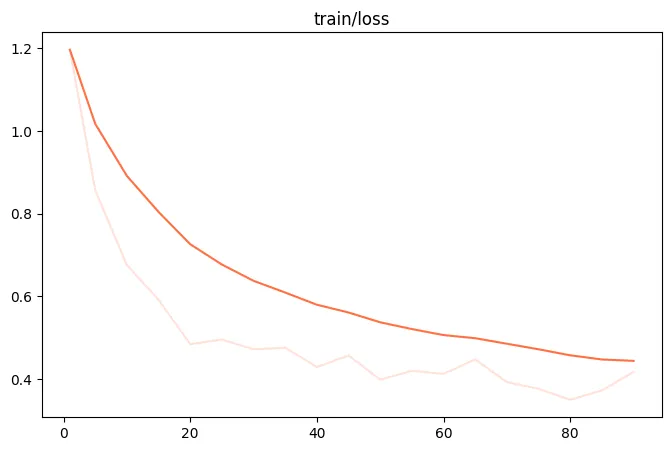
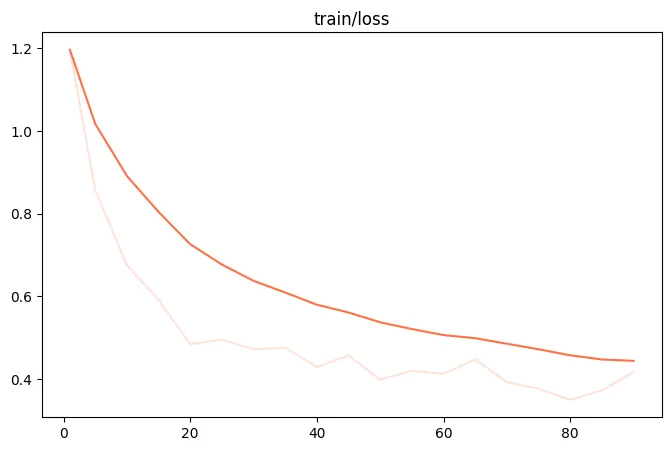
微调过程的loss可视化:
微调后推理脚本如下,这里的ckpt_dir需要修改为训练生成的last checkpoint文件夹。我们可以使用vLLM对merge后的checkpoint进行推理加速。
# 实验环境: 4 * A100
# 4 * 80GB GPU memory
# merge-lora
CUDA_VISIBLE_DEVICES=0 swift export \
--ckpt_dir output/mistral-large-instruct-2407/vx-xxx/checkpoint-xxx \
--merge_lora true --merge_device_map cpu
# 使用vLLM进行推理加速
CUDA_VISIBLE_DEVICES=0,1,2,3 swift infer \
--ckpt_dir output/mistral-large-instruct-2407/vx-xxx/checkpoint-xxx-merged \
--tensor_parallel_size 4 --gpu_memory_utilization 0.9 \
--infer_backend vllm推理结果:


模型部署
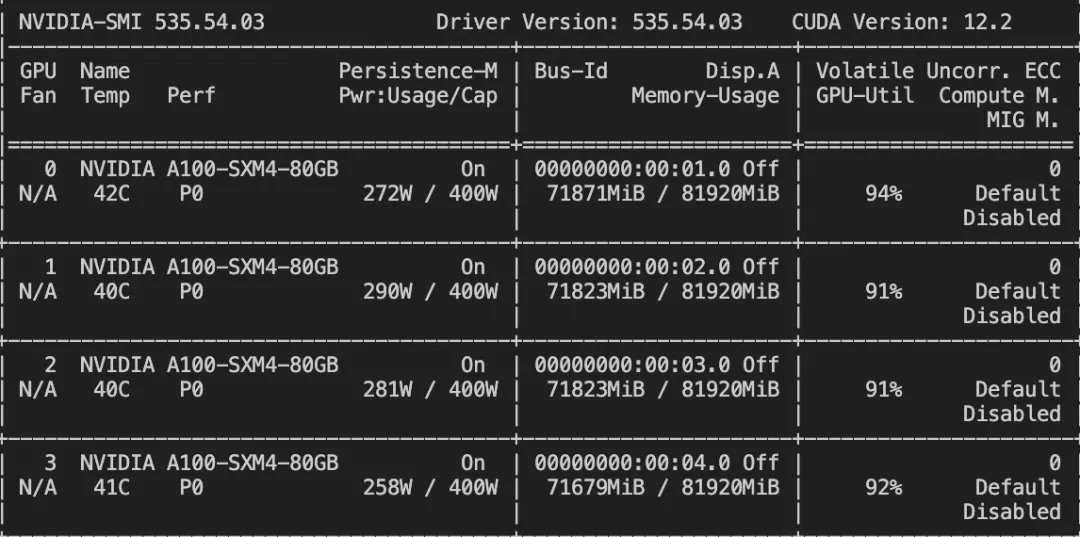
使用4卡机器,部署mistral-large-instruct-2407模型
CUDA_VISIBLE_DEVICES=0,1,2,3 vllm serve <loca_path> --served_model_name mistral-large-instruct-2407 --tensor_parallel_size 4显存利用率如下:








 已为社区贡献634条内容
已为社区贡献634条内容

所有评论(0)