
ToolBench指标提升8.25%!魔搭社区让Qwen2 成为你的智能体好帮手
随着千问2.0的发布,魔搭社区在第一时间上线了千问2全系列模型。我们注意到,千问2模型在通用能力上已经非常强悍,然而有时候用户需要使用模型在自己的私有场景上搭建起智能体调用流程,这时就有可能遇到对于特
导言
随着千问2.0的发布,魔搭社区在第一时间上线了千问2全系列模型。我们注意到,千问2模型在通用能力上已经非常强悍,然而有时候用户需要使用模型在自己的私有场景上搭建起智能体调用流程,这时就有可能遇到对于特定场景调用不良的情况,在这种情况下,用户对于千问2模型进行二次训练并提升智能体精度是非常有必要的。
在我们的实验中,我们使用我们特有的数据集MSAgent-Pro对千问2.0进行了sft,并且在ToolBench所有评测指标上平均提升8.25个百分点,证明在垂直场景中,针对LLM的特定调优是有较大提升的。
在本文章中,我们将利用魔搭社区的开源技术方案,给出Qwen2 Agent训练的数据集准备、训练、评测、部署等全链路能力,以及和ModelScope-Agent框架联合调用的过程。
智能体Agent的介绍
智能体(Agent)是利用模型的CoT(思维链)能力,对外部工具进行调用的场景。比如利用LLM调用天气接口实现天气预警,或者帮助用户进行旅程规划等。在工控场景中,智能体的应用更加广泛,比如OA系统协同、文档助手等。随着国产大模型的崛起,出于数据保护的需求,更推荐使用开源LLM实现Agent场景,如最新开源的Qwen2、GLM4、Llama3等,在这里就涉及到了对模型的重新训练, 以满足对用户特定场景API调用的需求。
在本文中,我们优先介绍了Agent智能体的训练过程,开发者也可以跳过训练过程尝试使用原模型进行Agent部署,或者和ModelScope-Agent框架进行联用。
数据集格式和准备
我们使用了和通义实验室共同开源的Agent训练集,该数据集地址在:
https://www.modelscope.cn/datasets/iic/MSAgent-Pro/summary?from=csdnzishequ_text?from=csdnzishequ_text
MSAgent-Pro数据集经过了数据遴选和采样,是魔搭社区提供的优质Agent训练数据集。开发者可以持续关注我们,后续我们也会开源更多的优质数据集。
在用户自定义场景中,我们推荐使用用户自己的数据集进行训练。目前我们支持两种格式的数据集,一种数据集是ToolBench格式,其中的API调用结果在新的一轮对话中返回:
{
'id': 'toolbench_ori_0',
'conversations': [{
'from': 'system',
'value': 'You can use many tools(functions) to do the following task.\nFirst I will give you the task description, and your task start.\nAt each step, you need to give your thought to analyze the status now and what to do next, with a function call to actually excute your step. Your output should follow this format:\nThought:\nAction\nAction Input:\n\nAfter the call, you will get the call result, and you are now in a new state.\nThen you will analyze your status now, then decide what to do next...\nAfter many (Thought-call) pairs, you finally perform the task, then you can give your finial answer.\nRemember: \n1.the state change is irreversible, you can\'t go back to one of the former state, if you want to restart the task, say "I give up and restart".\n2.All the thought is short, at most in 5 sentence.\n3.You can do more then one trys, so if your plan is to continusly try some conditions, you can do one of the conditions per try.\nLet\'s Begin!\nTask description: You should use functions to help handle the real time user querys. Remember:\n1.ALWAYS call "Finish" function at the end of the task. And the final answer should contain enough information to show to the user,If you can\'t handle the task, or you find that function calls always fail(the function is not valid now), use function Finish->give_up_and_restart.\n2.Do not use origin tool names, use only subfunctions\' names.\nSpecifically, you have access to the following APIs: [{"name": "url_for_newapi", "description": "This is the subfunction for tool \\"newapi\\", you can use this tool.The description of this function is: \\"url_for_newapi\\"", "parameters": {"type": "object", "properties": {"url": {"type": "string", "description": "", "example_value": "https://www.instagram.com/reels/CtB6vWMMHFD/"}}, "required": ["url"], "optional": ["url"]}}, {"name": "n_for_newapi", "description": "This is the subfunction for tool \\"newapi\\", you can use this tool.The description of this function is: \\"n_for_newapiew var\\"", "parameters": {"type": "object", "properties": {"language": {"type": "string", "description": "", "example_value": "https://www.instagram.com/reels/Csb0AI3IYUN/"}}, "required": ["language"], "optional": []}}, {"name": "Finish", "description": "If you believe that you have obtained a result that can answer the task, please call this function to provide the final answer. Alternatively, if you recognize that you are unable to proceed with the task in the current state, call this function to restart. Remember: you must ALWAYS call this function at the end of your attempt, and the only part that will be shown to the user is the final answer, so it should contain sufficient information.", "parameters": {"type": "object", "properties": {"return_type": {"type": "string", "enum": ["give_answer", "give_up_and_restart"]}, "final_answer": {"type": "string", "description": "The final answer you want to give the user. You should have this field if \\"return_type\\"==\\"give_answer\\""}}, "required": ["return_type"]}}]',
'ignore_loss': True
},
{
'from': 'user',
'value': "\nI am planning a surprise birthday party for my friend and I want to create a personalized invitation. Could you fetch my friend's recent photos from social media platforms so that I can use them in the invitation? It would be helpful if you could also provide the photos' captions or descriptions.\nBegin!\n",
'ignore_loss': None
},
{
'from': 'assistant',
'value': 'Thought: I think the current API call, "url_for_newapi", is used to fetch the recent photos of the user\'s friend from the social media platform. The URL argument provided is "https://api.socialmedia.com/friend/photos". It seems like the assistant is trying to retrieve the photos to help the user create a personalized invitation for their friend\'s surprise birthday party. This API call will fetch the photos, which can be used in the invitation along with their captions or descriptions.\nAction: url_for_newapi\nAction Input: {\n "url": "https://api.socialmedia.com/friend/photos"\n}',
'ignore_loss': None
},
{
'from': 'tool',
'value': '{"error": "", "response": "{\'message\': \\"Endpoint \'/https:/api.socialmedia.com/friend/photos\' does not exist\\"}"}',
'ignore_loss': None
},
{
'from': 'assistant',
'value': 'Thought: Based on the previous actions, it seems that I have only one option, which is to give up and restart the task. However, before doing so, I can try using a different social media platform to fetch your friend\'s recent photos. Let\'s try using the Instagram API instead.\nAction: url_for_newapi\nAction Input: {\n "url": "https://api.instagram.com/friend/photos"\n}',
'ignore_loss': None
}, {
'from': 'tool',
'value': '{"error": "", "response": "{\'message\': \\"Endpoint \'/https:/api.instagram.com/friend/photos\' does not exist\\"}"}',
'ignore_loss': None
},
{
'from': 'assistant',
'value': 'Thought: The API call "url_for_newapi" was used to fetch the recent photos of the user\'s friend from the social media platform, but it seems that the endpoint \'/https:/api.socialmedia.com/friend/photos\' does not exist. This caused the previous attempt to fail. Since the assistant couldn\'t retrieve the photos, they apologized for the inconvenience and asked if there was anything else they could assist with. In this state, it seems that all previous attempts have failed, so I need to generate a new action that is different from the previous ones. Based on the current situation, I can suggest directly asking the user to provide the photos and their captions or descriptions for the personalized invitation. This would be a different approach to solve the problem.\nAction: Finish\nAction Input: {\n "return_type": "give_up_and_restart"\n}',
'ignore_loss': None
}
]
}另一种是ReAct格式:
{
'system': 'Answer the following questions as best you can. You have access to the following APIs:\\n1. modelscope_text-translation-zh2en: Call this tool to interact with the modelscopetext-translation-zh2en API. What is the modelscopetext-translation-zh2en API useful for? 将输入的中文文本翻译成英文. Parameters: [{"name": "text", "description": "用户输入的中文文本", "required": "True"}]\\n\\n2. modelscope_text-translation-zh2en: Call this tool to interact with the modelscopetext-translation-zh2en API. What is the modelscopetext-translation-zh2en API useful for? 将输入的中文文本翻译成英文. Parameters: [{"name": "text", "description": "用户输入的中文文本", "required": "True"}]\\n\\n3. modelscope_text-translation-zh2en: Call this tool to interact with the modelscopetext-translation-zh2en API. What is the modelscopetext-translation-zh2en API useful for? 将输入的中文文本翻译成英文. Parameters: [{"name": "text", "description": "用户输入的中文文本", "required": "True"}]\\n\\nUse the following format:\\n\\nThought: you should always think about what to do\\nAction: the action to take, should be one of the above tools[modelscope_text-translation-zh2en, modelscope_text-translation-zh2en, modelscope_text-translation-zh2en]\\nAction Input: the input to the action\\nObservation: the result of the action\\n... (this Thought/Action/Action Input/Observation can be repeated zero or more times)\\nThought: I now know the final answer\\nFinal Answer: the final answer to the original input question\\nBegin!',
'query': '用英文翻译下,数年前,深圳还只是一个小渔村,如今,它已成为中国最富有和发达的城市之一。',
'response': "Thought: 好的,我将调用ModelScope的中英翻译模型翻译成英文\\nAction: modelscope_text-translation-zh2en\\nAction Input: {'text': '数年前,深圳还只是一个小渔村,如今,它已成为中国最富有和发达的城市之一。'}\\nObservation: {'text': 'A few years ago, Shenzhen was just a small fishing village, but now it has become one of the richest and most developed cities in China.'}\\nThought: I now know the final answer\\nFinal Answer: 翻译结果:A few years ago, Shenzhen was just a small fishing village, but now it has become one of the richest and most developed cities in China. 我使用的模型是ModelScope的'damo/modelscope_text-translation-zh2en',该模型是基于连续语义增强的神经机器翻译模型CSANMT,相关论文获得了ACL 2022的Outstanding Paper Award。"
}
{
'system': 'Answer the following questions as best you can. You have access to the following APIs:\\n1. modelscope_text-translation-zh2en: Call this tool to interact with the modelscopetext-translation-zh2en API. What is the modelscopetext-translation-zh2en API useful for? 将输入的中文文本翻译成英文. Parameters: [{"name": "text", "description": "用户输入的中文文本", "required": "True"}]\\n\\n2. modelscope_text-translation-zh2en: Call this tool to interact with the modelscopetext-translation-zh2en API. What is the modelscopetext-translation-zh2en API useful for? 将输入的中文文本翻译成英文. Parameters: [{"name": "text", "description": "用户输入的中文文本", "required": "True"}]\\n\\n3. modelscope_text-translation-zh2en: Call this tool to interact with the modelscopetext-translation-zh2en API. What is the modelscopetext-translation-zh2en API useful for? 将输入的中文文本翻译成英文. Parameters: [{"name": "text", "description": "用户输入的中文文本", "required": "True"}]\\n\\nUse the following format:\\n\\nThought: you should always think about what to do\\nAction: the action to take, should be one of the above tools[modelscope_text-translation-zh2en, modelscope_text-translation-zh2en, modelscope_text-translation-zh2en]\\nAction Input: the input to the action\\nObservation: the result of the action\\n... (this Thought/Action/Action Input/Observation can be repeated zero or more times)\\nThought: I now know the final answer\\nFinal Answer: the final answer to the original input question\\nBegin!',
'query': '用英文翻译下,数年前,深圳还只是一个小渔村,如今,它已成为中国最富有和发达的城市之一。',
'response': "Thought: 好的,我将调用ModelScope的中英翻译模型翻译成英文\\nAction: modelscope_text-translation-zh2en\\nAction Input: {'text': '数年前,深圳还只是一个小渔村,如今,它已成为中国最富有和发达的城市之一。'}\\nObservation: {'text': 'A few years ago, Shenzhen was just a small fishing village, but now it has become one of the richest and most developed cities in China.'}\\nThought: I now know the final answer\\nFinal Answer: 翻译结果:A few years ago, Shenzhen was just a small fishing village, but now it has become one of the richest and most developed cities in China. 我使用的模型是ModelScope的'damo/modelscope_text-translation-zh2en',该模型是基于连续语义增强的神经机器翻译模型CSANMT,相关论文获得了ACL 2022的Outstanding Paper Award。"
}用户可以选择这两种的任意一种格式进行训练,训练后的部署是都支持的。
训练
基于Qwen2-7B-Insturct模型,我们基于msagent-pro数据集,结合loss_scale技术(下文中介绍),对模型进行微调,超参如下
| Parameter | Value |
| learning_rate | 2e-6 |
| batch_size | 32 |
| num_train_epochs | 1 |
| lora_rank | 8 |
| lora_alpha | 32 |
| lora_dropout_p | 0.05 |
| use_loss_scale | true |
| loss_scale_config_path | agent-flan |
评测结果对比
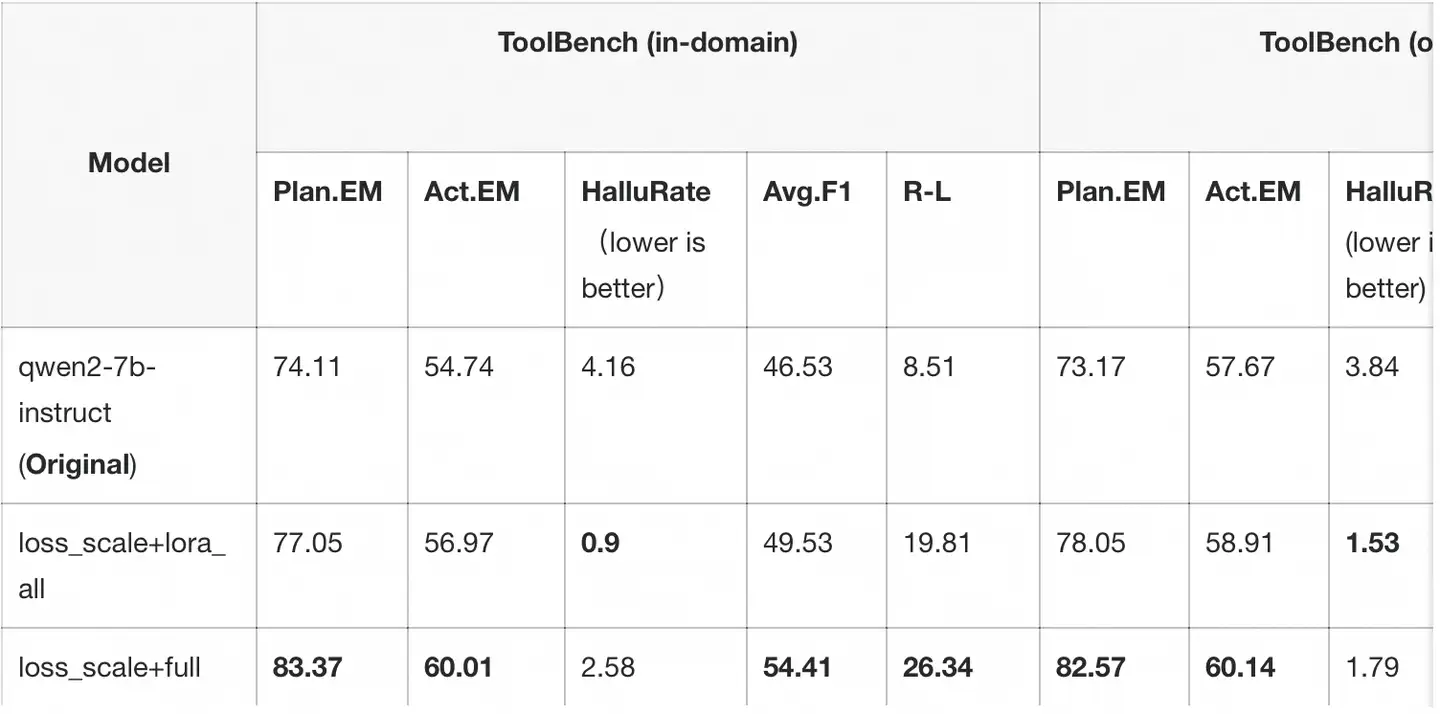
注
- 评测工具:使用eval-scope toolbench_static评测,参考:https://github.com/modelscope/eval-scope/tree/main/llmuses/third_party/toolbench_static
- 指标解释:参考上述文档
- lora_all 表示对模型的全部线性层进行lora训练
- full 表示全参微调
我们使用了loss scale技术对效果进行了进一步提升,该技术可以将重要的输出(如Action/Action Input)的loss权重进行提高,保证更好的训练效果。
loss_scale是针对重要字符将loss权重进行提升的训练技术。
我们应用了Agent-Flan中对ReAct数据的处理,将单轮数据处理为多轮对话形式。并且对ReAct格式中的不同部分设置不同的loss scale
{
"response":{
"Name:": [1.0, 3.0],
"Action:": [1.0, 3.0],
"ACTION:": [1.0,3.0],
"Tool:": [1.0, 3.0],
"Command": [1.0, 3.0],
"Arguments:": [1.0, 3.0],
"action input": [1.0, 3.0],
"ACTION_INPUT:":[1.0, 3.0],
"Action Input:": [1.0, 3.0],
"Thought:": [1.0, 1.0],
"Final Answer:": [1.0, 1.0],
"Observation:": [2.0, 0.0]
},
"query":{
"What is the tool you want to use": [3.0],
"What are the required parameter names": [3.0],
"What is the value of": [3.0],
"What are the required parameter names for this tool": [3.0]
}
}对工具选择/参数选择/参数值设置的部分设置了3.0的scale weight,能够让模型更好地学习对应的能力。
loss_scale搭配全参微调的效果最好,如果训练资源受限,使用LoRA训练的结果也仍然不错
在agent训练上,我们也基于Llama3-8b-instruct模型做了一些对比实验,训练超参数如下
| Parameter | Value |
| learning_rate | 2e-5 |
| batch_size | 32 |
| num_train_epochs | 2 |
| lora_rank | 8 |
| lora_alpha | 32 |
| lora_dropout_p | 0.05 |
LoRA实验
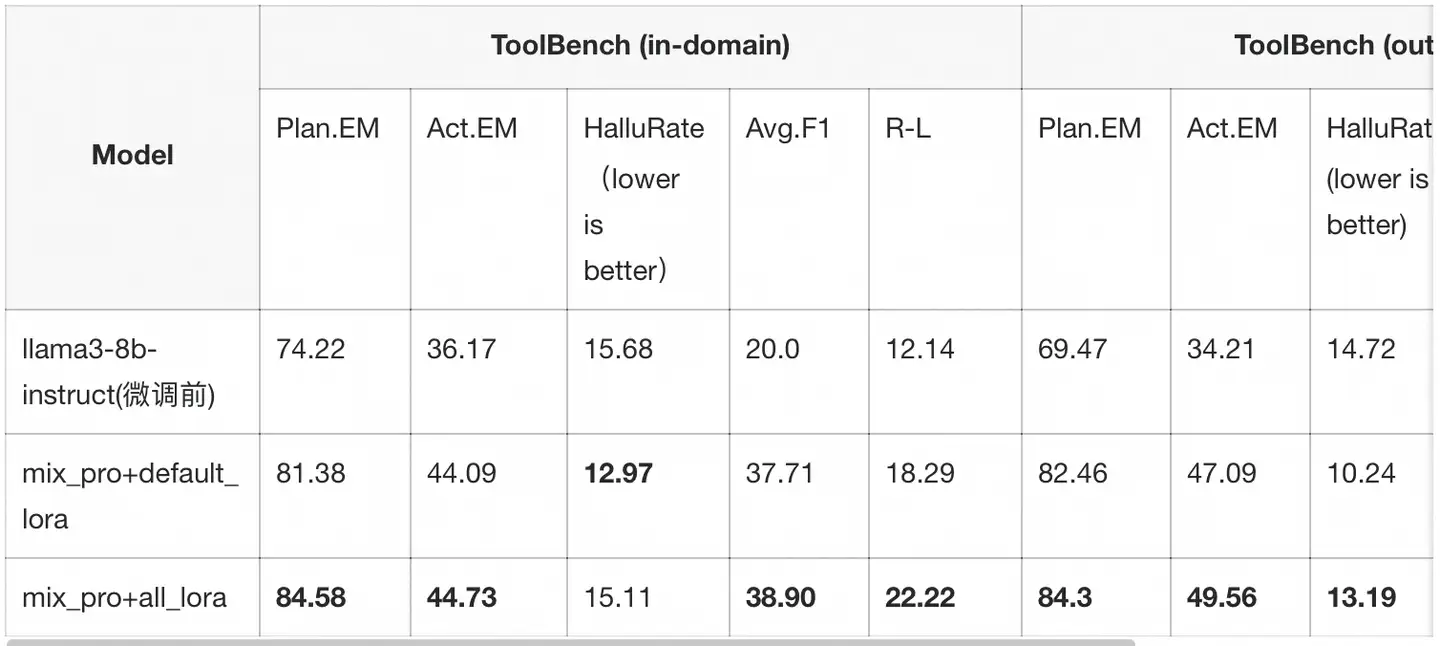
注:
- mix_pro 表示使用msagent-pro数据集混合sharegpt数据集进行训练
- default_lora 表示对模型的QKV矩阵采用LoRA训练
- all_lora 表示对模型的全部线性层采用LoRA训练
可以看到训练模型的全部线性层的综合性能表现最为出色,同时保留了LoRA节省计算资源的优势。在后续的LoRA训练实验中,我们将默认使用all_lora配置进行训练。
数据集实验
在使用all_lora配置的基础上,我们对不同数据集进行了一系列实验,以此比较各数据集在训练中的表现效果。
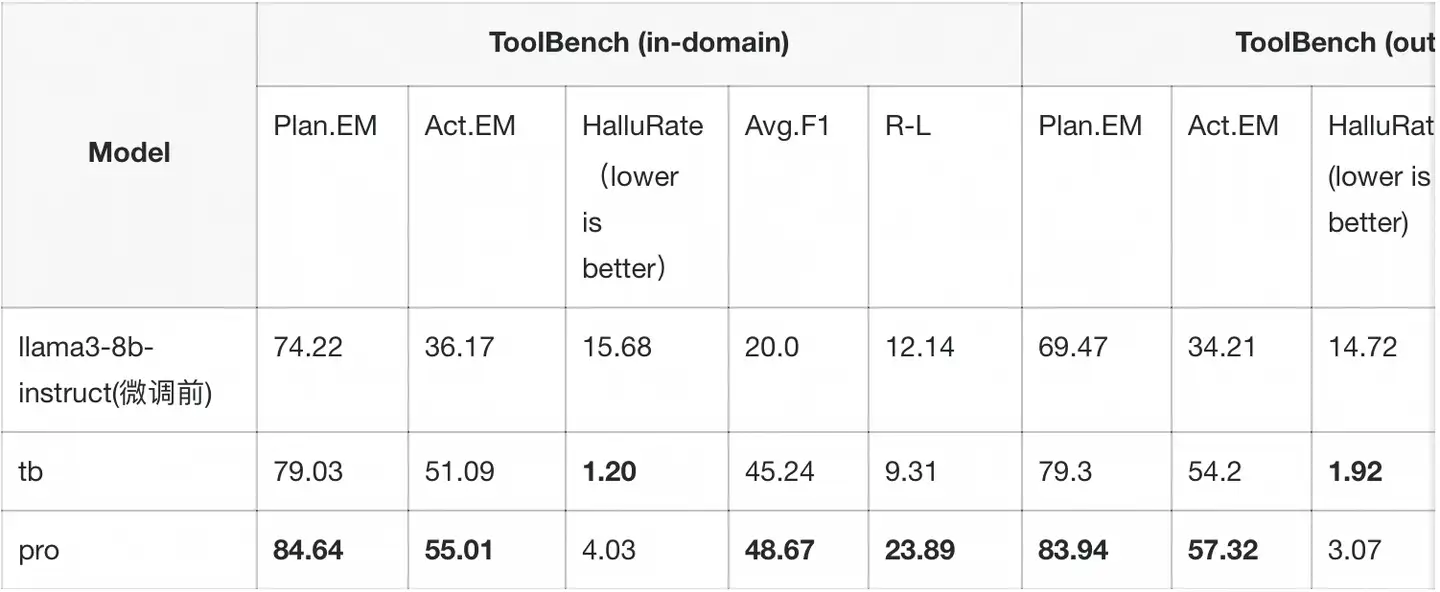
- pro表示仅训练msagent-pro数据集
- tb表示仅训练ToolBench训练集
仅训练msagent-pro数据集下,模型在ToolBench评测上的综合能力最强,但如果想要更好地保留模型的通用能力,我们建议混合一定的通用数据集。
我们根据loss_scale做了消融实验,以下为实验结果
实验结果如下:
评测过程参见下方的评测章节
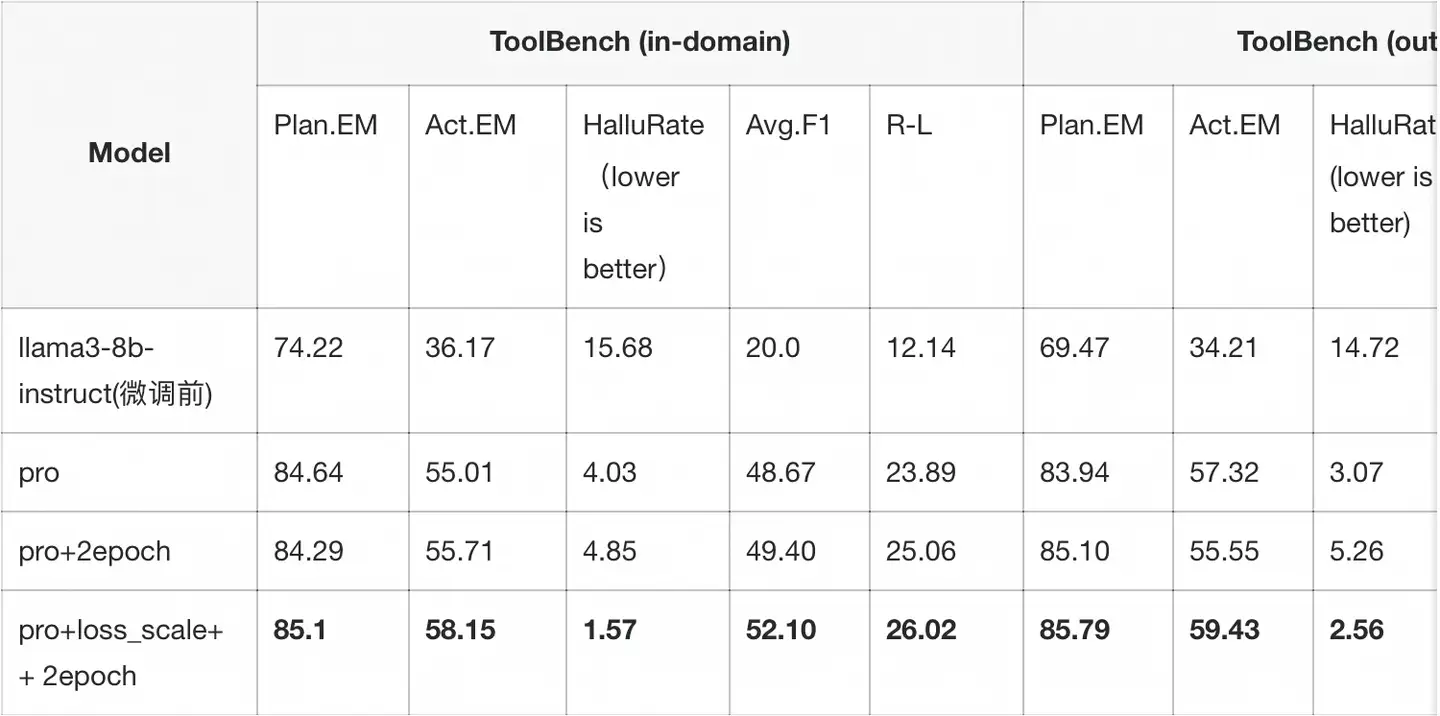
实验结果表明,引入loss_scale之后,所有评估指标得到了显著的提高。
以上实验均可通过swift进行复现,对于loss_scale,我们也提供了相应的配置文件。以qwen2-7b-instruct的实验为例,我们可以通过下面的命令进行训练
# 单卡 显存占用20G
# loss_scale+lora
swift sft \
--model_type qwen2-7b-instruct \
--learning_rate 2e-6 \
--sft_type lora \
--dataset msagent-pro \
--gradient_checkpointing true \
--gradient_accumulation_steps 32 \
--use_loss_scale true \
--loss_scale_config_path agent-flan \
--save_strategy epoch \
--batch_size 1 \
--num_train_epochs 2 \
--max_length 8192 \
--preprocess_num_proc 4 \
--use_loss_scale true \
# DDP
# loss_scale+full
NPROC_PER_NODE=8 \
CUDA_VISIBLE_DEVICES=0,1,2,3,4,5,6,7 \
MASTER_PORT=29500 \
swift sft \
--model_type qwen2-7b-instruct \
--learning_rate 2e-6 \
--sft_type full \
--dataset msagent-pro \
--gradient_checkpointing true \
--gradient_accumulation_steps 4 \
--deepspeed default-zero3 \
--use_loss_scale true \
--save_strategy epoch \
--batch_size 1 \
--num_train_epochs 2 \
--max_length 8192 \
--preprocess_num_proc 4 \
--use_loss_scale true \
--loss_scale_config_path agent-flan \
--ddp_backend nccl \你也可以使用`--dataset toolbench`来选择使用toolbench作为训练集
更多微调的超参数含义可以参考命令行参数文档:https://github.com/modelscope/swift/blob/main/docs/source/LLM/%E5%91%BD%E4%BB%A4%E8%A1%8C%E5%8F%82%E6%95%B0.md
我们已经将评测效果最佳的模型上传至modelscope:
https://modelscope.cn/models/swift/qwen2-7b-agent-instruct/summary
https://modelscope.cn/models/swift/llama3-8b-agent-instruct-v2/summary
和huggingface:
https://huggingface.co/modelscope/qwen2-7b-agent-instruct
https://huggingface.co/modelscope/llama3-8b-agent-instruct-v2
你可以在swift设置以下参数直接使用
# qwen2-7b-agent
--model_id_or_path swift/qwen2-7b-agent-instruct \
--model_type qwen2-7b-instruct
# llama3-8b-agent-instruct-v2
--model_id_or_path swift/llama3-8b-agent-instruct-v2 \
--model_type llama3-8b-instruct全链路能力
下面的章节我们介绍如何基于训练结果进行评测,用户也可以利用该能力评测自己的模型;以及如何利用原始模型或训练后的模型进行部署或应用。
评测
我们使用魔搭社区的EvalScope框架对ToolBench (static) benchmark进行评测,参考文档:
https://github.com/modelscope/eval-scope/tree/main/llmuses/third_party/toolbench_static
具体使用方式:
1.安装eval-scope评测工具和swift微调工具
pip install llmuses -U
pip install ms-swift -U2.准备数据
使用wget命令获取远端数据压缩包并解压
wget https://modelscope.oss-cn-beijing.aliyuncs.com/open_data/toolbench-static/data.zip
unzip data.zip注意文件夹结构为: data/toolbench_static/in_domain.json, data/toolbench_static/out_of_domain.json,
3.配置任务
为toolbench static任务准备配置参数,eval-scope支持两种配置方式,分别为dict和yaml配置文件:
task config with dict
task_config = {
'infer_args': {
'model_name_or_path': '/path/to/model_dir', # absolute path is recommended
'model_type': 'qwen2-7b-instruct',
'data_path': '/path/to/data/toolbench_static', # absolute path is recommended
'deploy_type': 'swift',
'max_new_tokens': 2048,
'num_infer_samples': None,
'output_dir': 'output_res'
},
'eval_args': {
'input_path': 'output_res',
'output_path': 'output_res'
}
}task config with yaml
infer_args:
model_name_or_path: /path/to/model_dir
model_type: qwen2-7b-instruct
data_path: /path/to/data/toolbench_static # absolute path is recommended
deploy_type: swift
max_new_tokens: 2048
num_infer_samples: null
output_dir: output_res
eval_args:
input_path: output_res
output_path: output_res- Arguments:
model_name_or_path: The path to the model local directory.model_type: The model type, refer to : https://github.com/modelscope/swift/blob/main/docs/source/LLM/%E6%94%AF%E6%8C%81%E7%9A%84%E6%A8%A1%E5%9E%8B%E5%92%8C%E6%95%B0%E6%8D%AE%E9%9B%86.mddata_path: The path to the dataset directory containsin_domain.jsonandout_of_domain.jsonfiles.output_dir: The path to the output directory. Default tooutput_res.deploy_type: The deploy type, default toswift.max_new_tokens: The maximum number of tokens to generate.num_infer_samples: The number of samples to infer. Default toNone, which means infer all samples.input_path: The path to the input directory for evaluation, should be the same asoutput_dirofinfer_args.output_path: The path to the output directory for evaluation.
4.运行任务
eval-scope toolbench任务支持两种方式提交任务,可以指定task_config为dict或yaml文件路径:
from llmuses.third_party.toolbench_static import run_task
# Run with config-dict
run_task(task_config=task_config)
# Run with config-yaml
run_task(task_config='/path/to/your_task_config_file')5.结果
我们使用以下指标来衡量智能体的效果:
- Metrics:
Plan.EM: The agent’s planning decisions at each step for using tools invocation, generating answer, or giving up. Exact match score.Act.EM: Action exact match score, including the tool name and arguments.HalluRate(lower is better): The hallucination rate of the agent's answers at each step.Avg.F1: The average F1 score of the agent's tools calling at each step.R-L: The Rouge-L score of the agent's answers at each step.
其中,我们会重点关注以下3个指标:Act.EM, HalluRate and Avg.F1 。实际的评测结果请参考上方的表格。
部署和应用
训练过后,最重要的就是能够在生产场景中进行部署和应用,在这里我们推荐两种方式进行使用,一种是提供工具列表,基于该列表使用OpenAI的标准接口进行调用,第二种是和ModelScope-Agent框架联用,由框架进行调用。
部署
这里我们使用swift deploy 命令,用vLLM模型部署训练好的Qwen2模型,选用toolbench形式的prompt,将模型部署为符合OpenAI接口规范的独立服务。
如果直接使用训练前的模型进行部署,将下面的ckpt_dir参数改为model_id_or_path参数
swift deploy \
--ckpt_dir /path/to/qwen2-7b-instruct/vx-xxxx/checkpoint-xxx \
--model_type qwen2-7b-instruct \
--infer_backend vllm \
--tools_prompt toolbench我们可以使用OpenAI SDK进行测试
from openai import OpenAI
client = OpenAI(
api_key='EMPTY',
base_url='http://localhost:8000/v1',
)
query = "What's the weather like in Boston today?"
messages = [{
'role': 'user',
'content': query
}]
tools = [
{
"name": "url_for_newapi",
"description": "This is the subfunction for tool \"newapi\", you can use this tool.The description of this function is: \"url_for_newapi\"",
"parameters": {
"type": "object",
"properties": {
"url": {
"type": "string",
"description": "",
"example_value": "https://www.instagram.com/reels/CtB6vWMMHFD/"
}
},
"required": [
"url"
],
"optional": [
"url"
]
}
},
]
resp = client.chat.completions.create(
model='qwen2-7b-instruct',
tools = tools,
messages=messages,
seed=42)
tool_calls = resp.choices[0].message.tool_calls
print(f'query: {query}')
print(f'tool_calls: {tool_calls}')
# 流式
stream_resp = client.chat.completions.create(
model='qwen2-7b-instruct',
messages=messages,
tools=tools,
stream=True,
seed=42)
print(f'query: {query}')
print('response: ', end='')
for chunk in stream_resp:
print(chunk.choices[0].delta.content, end='', flush=True)
print()
"""
query: What's the weather like in Boston today?
tool_calls: {'id': 'toolcall-e4c637435e754cf9b2034c3e6861a4ad', 'function': {'arguments': ' {"url": "https://api.weatherapi.com/v1/current.json?key=YOUR_API_KEY&q=Boston"}', 'name': 'url_for_newapi'}, 'type': 'function'}
query: What's the weather like in Boston today?
response: Thought: I need to find the weather information for Boston today. I can use the 'newapi' tool to get the weather forecast.
Action: url_for_newapi
Action Input: {"url": "https://api.weatherapi.com/v1/current.json?key=YOUR_API_KEY&q=Boston"}
"""和ModelScope-Agent联用
安装ModelScope-Agent环境
git clone https://github.com/modelscope/modelscope-agent.git
cd modelscope-agent && pip install -r requirements.txt && pip install -r apps/agentfabric/requirements.txt在modelscope-agent/apps/agentfabric/config/model_config.json中,新增本地模型配置
"local-qwen2": {
"type": "openai",
"model": "qwen2-7b-instruct",
"api_base": "http://localhost:8000/v1",
"is_chat": true,
"is_function_call": false,
"support_stream": false
}部署模型
同上一步使用swift deploy命令,这里省略。
使用AgentFabric
在以下实践中,会调万象生图https://help.aliyun.com/zh/dashscope/opening-service?spm=a2c4g.11186623.0.0.50724937O7n40B 和高德天气https://lbs.amap.com/api/webservice/guide/create-project/get-key 需要手动设置API KEY, 设置后启动AgentFabric
export PYTHONPATH=$PYTHONPATH:/path/to/your/modelscope-agent
export DASHSCOPE_API_KEY=your_api_key
export AMAP_TOKEN=your_api_key
cd modelscope-agent/apps/agentfabric
python app.py进入AgentFabric后,在配置(Configure)的模型中选择本地模型`local-qwen2`
内置能力选择agent可以调用的API, 选择`Wanx Image Generation`和`高德天气`
点击更新配置,等待配置完成后在右侧的输入栏中与Agent交互
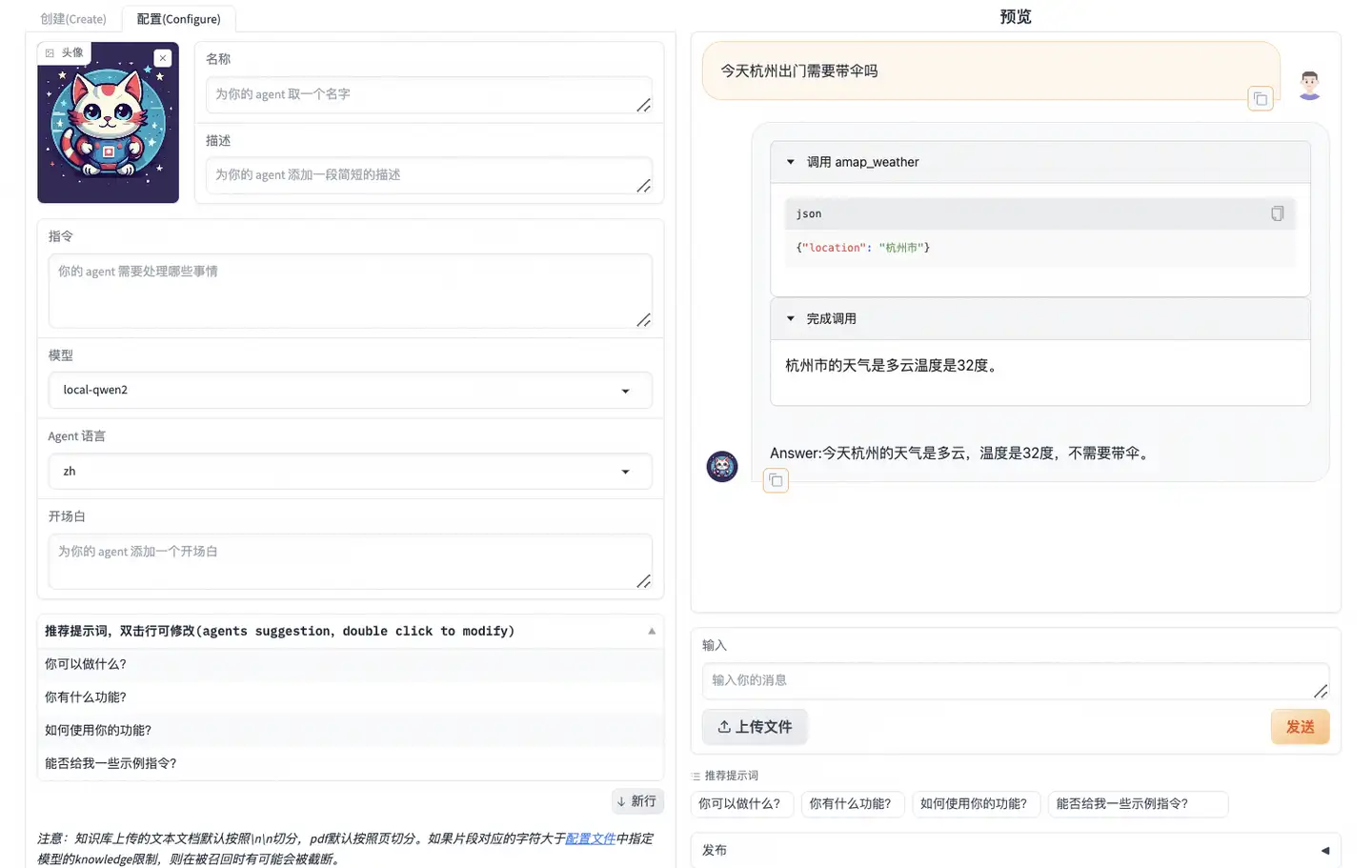
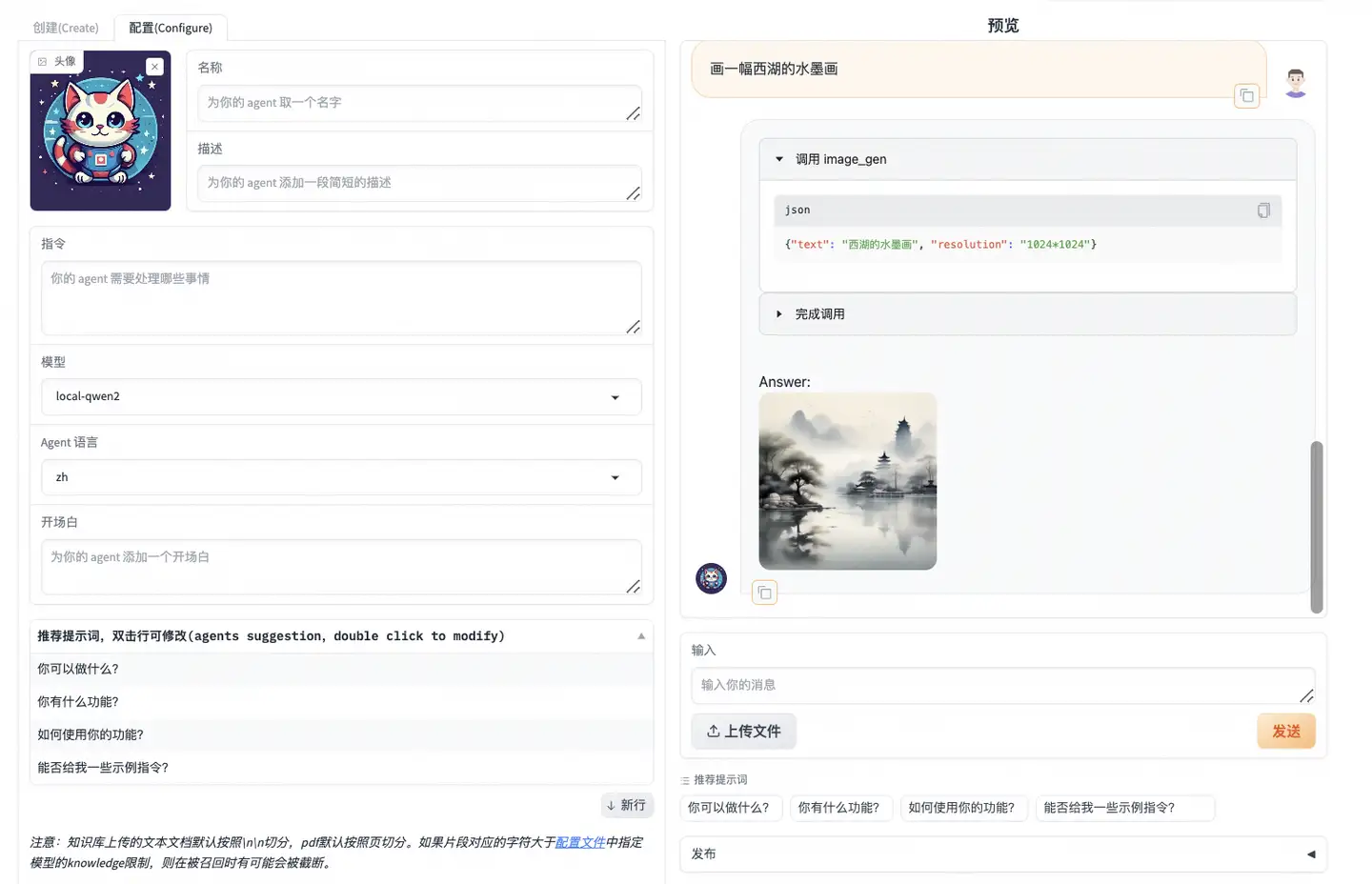
结论
在本文中,我们对Llama3-8b和Qwen2-7b模型进行了调优和训练,并基于魔搭社区的技术生态对调优后的模型进行了评测和实际部署,可以看到,在调优后模型的智能体能力更强,并且在使用用户自定义数据时可以良好适配特定业务场景,且由于是全开源方案,没有数据隐私问题。依赖于魔搭的Agent框架,我们可以方便地将模型应用在具体的场景中,并且支持OpenAI格式的部署调用能力,用户可以在自己的生产环境中使用一行命令直接调用起来。

ModelScope旨在打造下一代开源的模型即服务共享平台,为泛AI开发者提供灵活、易用、低成本的一站式模型服务产品,让模型应用更简单!
更多推荐



 1
1 0
0- 0



 已为社区贡献633条内容
已为社区贡献633条内容

所有评论(0)