
-
Github:https://github.com/THUDM/CogVLM
-
论文:https://arxiv.org/abs/2312.08914
视觉Agent来了!智谱AI开源CogAgent,支持GUI图形界面问答(附魔搭推理微调最佳实践)
·
序言
近日,智谱AI开源了VLM领域的最新工作 CogAgent。
CogAgent 是基于CogVLM改进的模型,是一个擅长于GUI理解和导航的180亿参数规模的视觉语言模型,CogAgent-18B 拥有110亿视觉参数和70亿语言参数。
CogAgent-18B 在9个跨模态基准测试上取得了 SOTA 的通用性能,包括VQAv2、OK-VQA、TextVQA、ST-VQA、ChartQA、infoVQA、DocVQA、MM-Vet、和 POPE。在AITW、Mind2Web等GUI操作数据集上取得了SOTA的性能。
除了CogVLM已有的全部功能(视觉多轮对话、视觉定位)外,CogAgent还:
- 支持更高分辨率的视觉输入和对话问答。支持1120*1120超高分辨率的图像输入;
- 具备视觉Agent的能力,针对任意GUI截图,对于用户给定的任务,CogAgent均能返回计划、下一个动作、含坐标的具体操作;
- 提升了GUI相关的问答能力,可以针对任意GUI截图进行问答,例如网页、PPT、手机软件,甚至能够解说原神界面。
- 通过预训练与微调,在OCR相关任务上的能力大幅提升。
模型体验
CogAgent本次特别的支持了GUI问答,后续在RPA等场景,也可以发挥很大的作用。本次体验中,我们通过上传一张桌面截图,考考CogAgent的能力。
GUI(屏幕截图)的Agent任务:
使用Agent模板如下:
en_template_task = [
"Can you advise me on how to <TASK>?",
"I'm looking for guidance on how to <TASK>.",
"What steps do I need to take to <TASK>?",
"Could you provide instructions for <TASK>?",
"I'm wondering what the process is for <TASK>.",
"How can I go about <TASK>?",
"I need assistance with planning to <TASK>.",
"Do you have any recommendations for <TASK>?",
"Please share some tips for <TASK>.",
"I'd like to know the best way to <TASK>.",
"What's the most effective way to <TASK>?",
"I'm seeking advice on accomplishing <TASK>.",
"Could you guide me through the steps to <TASK>?",
"I'm unsure how to start with <TASK>.",
"Is there a strategy for successfully <TASK>?",
"What's the proper procedure for <TASK>?",
"How should I prepare for <TASK>?",
"I'm not sure where to begin with <TASK>.",
"I need some insights on <TASK>.",
"Can you explain how to tackle <TASK>?",
"I'm interested in the process of <TASK>.",
"Could you enlighten me on <TASK>?",
"What are the recommended steps for <TASK>?",
"Is there a preferred method for <TASK>?",
"I'd appreciate your advice on <TASK>.",
"Can you shed light on <TASK>?",
"What would be the best approach to <TASK>?",
"How do I get started with <TASK>?",
"I'm inquiring about the procedure for <TASK>.",
"Could you share your expertise on <TASK>?",
"I'd like some guidance on <TASK>.",
"What's your recommendation for <TASK>?",
"I'm seeking your input on how to <TASK>.",
"Can you provide some insights into <TASK>?",
"How can I successfully accomplish <TASK>?",
"What steps are involved in <TASK>?",
"I'm curious about the best way to <TASK>.",
"Could you show me the ropes for <TASK>?",
"I need to know how to go about <TASK>.",
"What are the essential steps for <TASK>?",
"Is there a specific method for <TASK>?",
"I'd like to get some advice on <TASK>.",
"Can you explain the process of <TASK>?",
"I'm looking for guidance on how to approach <TASK>.",
"What's the proper way to handle <TASK>?",
"How should I proceed with <TASK>?",
"I'm interested in your expertise on <TASK>.",
"Could you walk me through the steps for <TASK>?",
"I'm not sure where to begin when it comes to <TASK>.",
"What should I prioritize when doing <TASK>?",
"How can I ensure success with <TASK>?",
"I'd appreciate some tips on <TASK>.",
"Can you provide a roadmap for <TASK>?",
"What's the recommended course of action for <TASK>?",
"I'm seeking your guidance on <TASK>.",
"Could you offer some suggestions for <TASK>?",
"I'd like to know the steps to take for <TASK>.",
"What's the most effective way to achieve <TASK>?",
"How can I make the most of <TASK>?",
"I'm wondering about the best approach to <TASK>.",
"Can you share your insights on <TASK>?",
"What steps should I follow to complete <TASK>?",
"I'm looking for advice on <TASK>.",
"What's the strategy for successfully completing <TASK>?",
"How should I prepare myself for <TASK>?",
"I'm not sure where to start with <TASK>.",
"What's the procedure for <TASK>?",
"Could you provide some guidance on <TASK>?",
"I'd like to get some tips on how to <TASK>.",
"Can you explain how to tackle <TASK> step by step?",
"I'm interested in understanding the process of <TASK>.",
"What are the key steps to <TASK>?",
"Is there a specific method that works for <TASK>?",
"I'd appreciate your advice on successfully completing <TASK>.",
"Can you shed light on the best way to <TASK>?",
"What would you recommend as the first step to <TASK>?",
"How do I initiate <TASK>?",
"I'm inquiring about the recommended steps for <TASK>.",
"Could you share some insights into <TASK>?",
"I'm seeking your expertise on <TASK>.",
"What's your recommended approach for <TASK>?",
"I'd like some guidance on where to start with <TASK>.",
"Can you provide recommendations for <TASK>?",
"What's your advice for someone looking to <TASK>?",
"I'm seeking your input on the process of <TASK>.",
"How can I achieve success with <TASK>?",
"What's the best way to navigate <TASK>?",
"I'm curious about the steps required for <TASK>.",
"Could you show me the proper way to <TASK>?",
"I need to know the necessary steps for <TASK>.",
"What's the most efficient method for <TASK>?",
"I'd appreciate your guidance on <TASK>.",
"Can you explain the steps involved in <TASK>?",
"I'm looking for recommendations on how to approach <TASK>.",
"What's the right way to handle <TASK>?",
"How should I manage <TASK>?",
"I'm interested in your insights on <TASK>.",
"Could you provide a step-by-step guide for <TASK>?",
"I'm not sure how to start when it comes to <TASK>.",
"What are the key factors to consider for <TASK>?",
"How can I ensure a successful outcome with <TASK>?",
"I'd like some tips and tricks for <TASK>.",
"Can you offer a roadmap for accomplishing <TASK>?",
"What's the preferred course of action for <TASK>?",
"I'm seeking your expert advice on <TASK>.",
"Could you suggest some best practices for <TASK>?",
"I'd like to understand the necessary steps to complete <TASK>.",
"What's the most effective strategy for <TASK>?",
]
将其中的<TASK>替换为用双引号包围的任务指令。该方法可以获得模型推测的Plan和Next Action。若在句末加上(with grounding),则模型会进一步返回含坐标的形式化表示。
首先我们上传一张电脑的截屏:

然后问他:I'm looking for a software to "edit my photo with grounding"
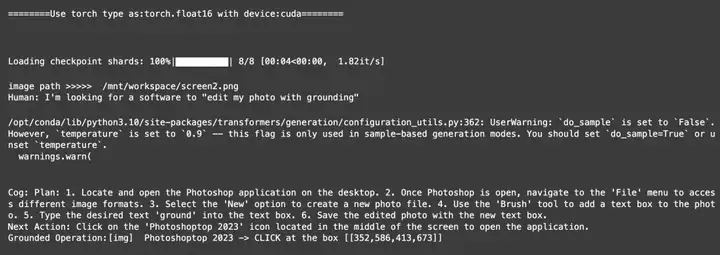
我们可以看到,CogAgent给我们返回了edit photo的步骤,以及下一步action是点击屏幕的PhotoShop,以及正确的指出了PhotoShop的坐标信息。
然后我们试一下多轮对话的能力,我们再问他:I want to "calculate the average score of students with grounding"

我们可以看到,Cogagent给我们建议使用excel的步骤,以及下一步action是点击屏幕的excel软件,以及正确的指出了excel的坐标信息。
同时CogAgent的官方文档中,也给出了更多更加好玩的PC端和移动端的玩法,大家都可以来试一下!
模型下载和推理
现在CogAgent系列已经上线魔搭社区,开发者们可以下载使用。
模型链接:
cogagent-chat:
https://modelscope.cn/models/ZhipuAI/cogagent-chat/summary
cogagent-vqa:
https://www.modelscope.cn/models/ZhipuAI/cogagent-vqa/summary
使用魔搭社区pipeline函数推理 cogagent-chat:
from modelscope import pipeline
pipe = pipeline(task='chat', model='ZhipuAI/cogagent-chat', llm_first=True, device_map='cuda')
messages_en = {
'messages': [{
'role': 'user',
'content': [{'image': 'einstein.png'}, {'text': 'Who is him?'}]
}]
}
gen_kwargs = {"max_length": 2048,
"temperature": 0.9,
"do_sample": False}
print(pipe(messages_en, **gen_kwargs))
使用AutoModel推理代码:
import torch
from PIL import Image
from modelscope import AutoModelForCausalLM, AutoTokenizer
import argparse
parser = argparse.ArgumentParser()
parser.add_argument("--quant", choices=[4], type=int, default=None, help='quantization bits')
parser.add_argument("--from_pretrained", type=str, default="ZhipuAI/cogagent-chat", help='pretrained ckpt')
parser.add_argument("--local_tokenizer", type=str, default="AI-ModelScope/vicuna-7b-v1.5", help='tokenizer path')
parser.add_argument("--fp16", action="store_true")
parser.add_argument("--bf16", action="store_true")
args, unknown = parser.parse_known_args()
MODEL_PATH = args.from_pretrained
TOKENIZER_PATH = args.local_tokenizer
DEVICE = 'cuda' if torch.cuda.is_available() else 'cpu'
tokenizer = AutoTokenizer.from_pretrained(TOKENIZER_PATH)
if args.bf16:
torch_type = torch.bfloat16
else:
torch_type = torch.float16
print("========Use torch type as:{} with device:{}========\n\n".format(torch_type, DEVICE))
if args.quant:
model = AutoModelForCausalLM.from_pretrained(
MODEL_PATH,
torch_dtype=torch_type,
low_cpu_mem_usage=True,
load_in_4bit=True,
trust_remote_code=True
).eval()
else:
model = AutoModelForCausalLM.from_pretrained(
MODEL_PATH,
torch_dtype=torch_type,
low_cpu_mem_usage=True,
load_in_4bit=args.quant is not None,
trust_remote_code=True
).to(DEVICE).eval()
while True:
image_path = input("image path >>>>> ")
if image_path == "stop":
break
image = Image.open(image_path).convert('RGB')
history = []
while True:
query = input("Human:")
if query == "clear":
break
input_by_model = model.build_conversation_input_ids(tokenizer, query=query, history=history, images=[image])
inputs = {
'input_ids': input_by_model['input_ids'].unsqueeze(0).to(DEVICE),
'token_type_ids': input_by_model['token_type_ids'].unsqueeze(0).to(DEVICE),
'attention_mask': input_by_model['attention_mask'].unsqueeze(0).to(DEVICE),
'images': [[input_by_model['images'][0].to(DEVICE).to(torch_type)]],
}
if 'cross_images' in input_by_model and input_by_model['cross_images']:
inputs['cross_images'] = [[input_by_model['cross_images'][0].to(DEVICE).to(torch_type)]]
# add any transformers params here.
gen_kwargs = {"max_length": 2048,
"temperature": 0.9,
"do_sample": False}
with torch.no_grad():
outputs = model.generate(**inputs, **gen_kwargs)
outputs = outputs[:, inputs['input_ids'].shape[1]:]
response = tokenizer.decode(outputs[0])
response = response.split("</s>")[0]
print("\nCog:", response)
history.append((query, response))
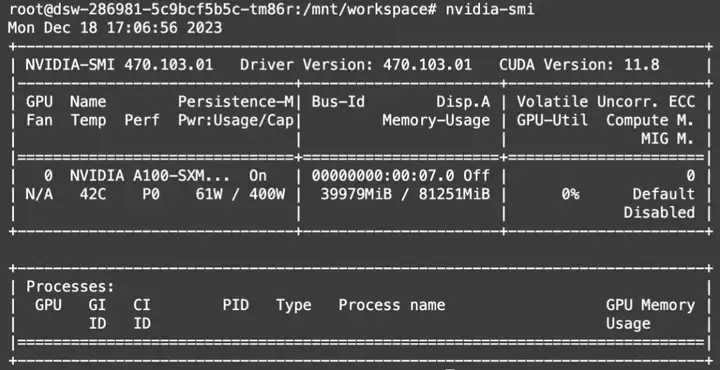
显存占用:
模型训练
CogAgent-Chat 和 CogAgent-VQA 模型已经在 SWIFT(https://github.com/modelscope/swift)中支持训练。官方提供的训练示例中使用了原版github训练中使用的数据集captcha-images。该数据集的输入图片为包含字母和数字的图片,标签为识别出来的内容。开发者可以使用如下脚本进行训练:
# Experimental environment: 2 * A100
# 2 * 45GB
PYTHONPATH=../../.. \
CUDA_VISIBLE_DEVICES=0,1 \
python llm_sft.py \
--model_type cogagent-chat \
--sft_type lora \
--tuner_backend swift \
--dtype fp16 \
--output_dir output \
--dataset capcha-images \
--train_dataset_sample -1 \
--num_train_epochs 2 \
--max_length 1024 \
--check_dataset_strategy warning \
--lora_rank 8 \
--lora_alpha 32 \
--lora_dropout_p 0.05 \
--gradient_checkpointing false \
--batch_size 1 \
--weight_decay 0.01 \
--learning_rate 1e-4 \
--gradient_accumulation_steps 16 \
--max_grad_norm 0.5 \
--warmup_ratio 0.03 \
--eval_steps 100 \
--save_steps 100 \
--save_total_limit 2 \
--logging_steps 10
--push_to_hub false \
--hub_model_id cogagent-chat-lora \
--hub_private_repo true \
--hub_token 'your-sdk-token' \
训练过程需要注意:
- 该模型cross-image的Vit联合FusedLayerNorm使用会造成训练跑飞,避免该错误请`pip uninstall apex`
- 该模型联合device_map使用时可能会有不同算子处于不同CUDA设备上的问题,请酌情调节device_map配置
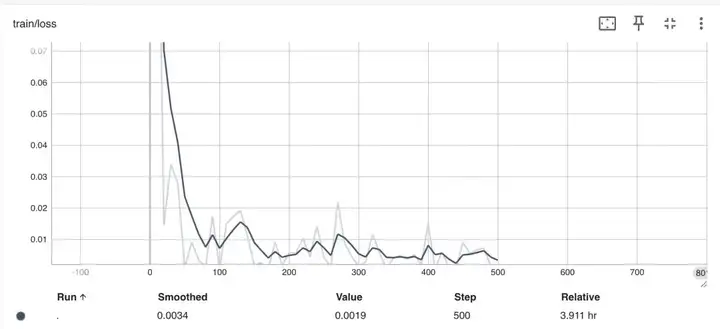
训练loss如下:
训练的显存使用情况:
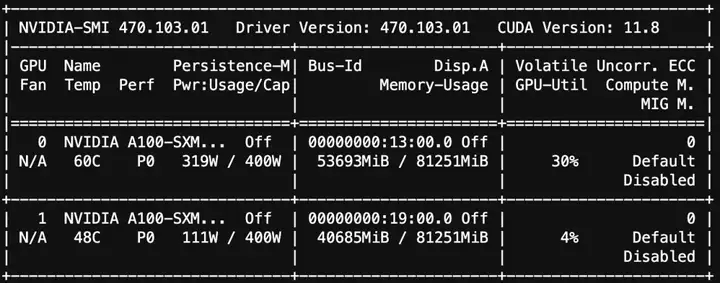
训练后推理可以使用如下脚本:
# Experimental environment: A100
PYTHONPATH=../../.. \
CUDA_VISIBLE_DEVICES=0 \
python llm_infer.py \
--ckpt_dir "/xxx/xxx/cogagent-chat/vx-xxx/checkpoint-xx" \
--load_args_from_ckpt_dir true \
--eval_human true \
--max_length 4096 \
--use_flash_attn true \
--max_new_tokens 2048 \
--temperature 0.3 \
--top_p 0.7 \
--repetition_penalty 1.05 \
--do_sample true \
--merge_lora_and_save false \
原始图片:

识别输出:

推理显存使用情况:
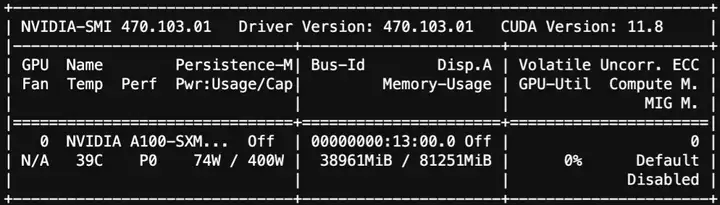
这两个脚本都可以在SWIFT examples中找到。
点击查看模型详情~

ModelScope旨在打造下一代开源的模型即服务共享平台,为泛AI开发者提供灵活、易用、低成本的一站式模型服务产品,让模型应用更简单!
更多推荐



 0
0 0
0- 0



 已为社区贡献629条内容
已为社区贡献629条内容

所有评论(0)