

元象推出 70 亿参数通用大模型 XVERSE-7B 底座与对话版,保持高性能、全开源、免费可商用,让海量中小企业和 AI 开发者能以低成本用上高性能大模型,并在魔搭社区开源,共同推动中国大模型生态建设。
与 8 月开源的 XVERSE-13B 相比,7B 版本主打“小而美”:它支持在单张消费级显卡部署运行,推理量化后最低只需 6GB 显存,大幅降低开发门槛和推理成本;继续保持高性能,在多个权威基准测评中表现出色,部分能力还“跳级”赶超了13B、16B等更大尺寸模型。
使用 5 shot 方法测试
在多项权威测试中表现出色
● XVERSE-7B 是在 2.6 万亿 tokens 高质量多语言数据上从头训练的底座模型,具有强大的认知、规划、推理和记忆能力。其上下文窗口长度为 8192 ,支持中、英、俄、法等40多种语言。
● XVERSE-7B-Chat 是底座模型经 SFT 指令精调后的中英文对话模型,大幅提升了理解和生成内容的准确度,也更符合人类的认知偏好。
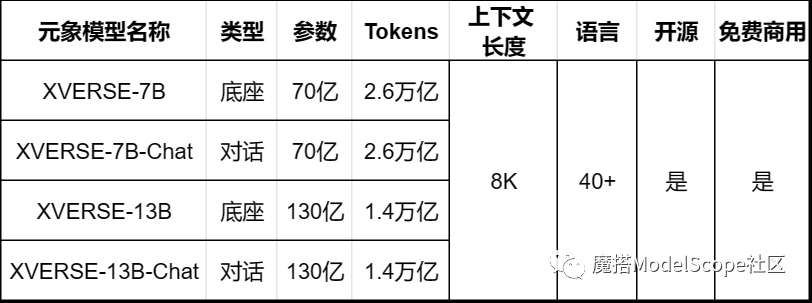
元象通用大模型 XVERSE 系列
-
python 3.8及以上版本
-
pytorch 1.12及以上版本,推荐2.0及以上版本
-
建议使用CUDA 11.4及以上(GPU用户需考虑此选项)
使用步骤
本文在ModelScope的免费GPU环境配置下运行 (可单卡运行)
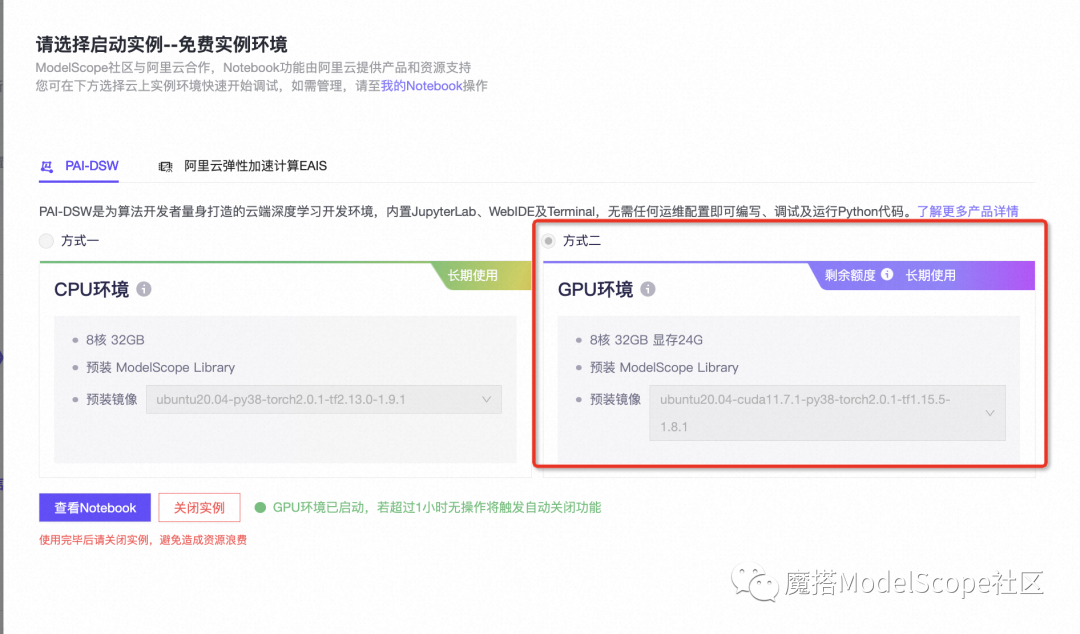
元象XVERSE系列模型现已在ModelScope社区开源,包括:
XVERSE-7B:
https://modelscope.cn/models/xverse/XVERSE-7B
XVERSE-7B-Chat:
https://modelscope.cn/models/xverse/XVERSE-7B-Chat
XVERSE-13B:
https://modelscope.cn/models/xverse/XVERSE-13B
XVERSE-13B-Chat:
https://modelscope.cn/models/xverse/XVERSE-13B-Chat
社区支持直接下载模型的repo:
from modelscope.hub.snapshot_download import snapshot_download
model_dir = snapshot_download('xverse/XVERSE-7B-Chat', 'v1.0.0')
依赖项:
XVERSE-7B-Chat依赖项:
pip install "modelscope==1.8.1"推理代码:
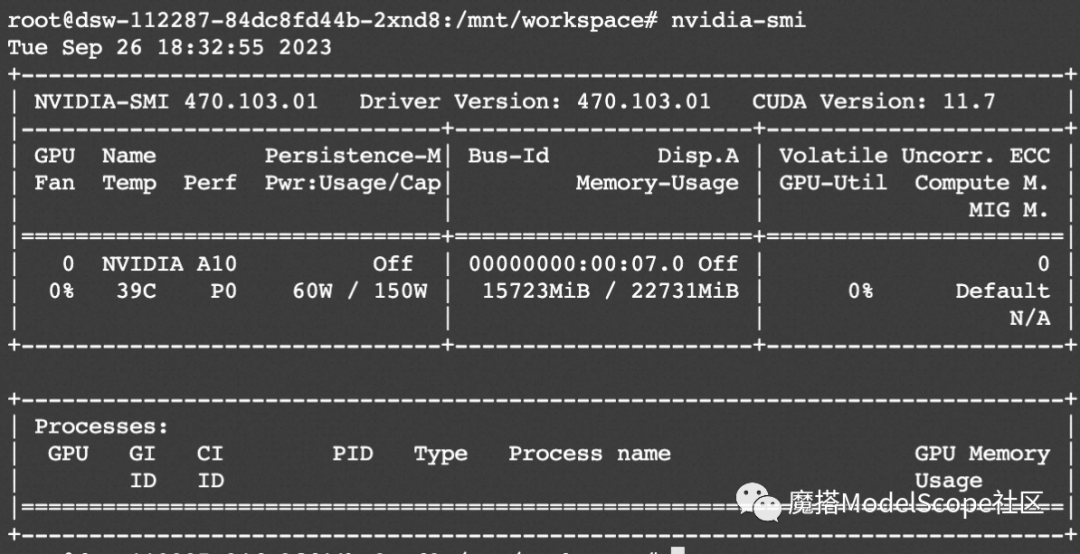
XVERSE-7B-Chat可在魔搭社区免费GPU算力(单卡A10)运行:
import torch
from modelscope import AutoTokenizer, AutoModelForCausalLM,snapshot_download
from modelscope import GenerationConfig
model_dir = snapshot_download('xverse/XVERSE-7B-Chat',revision = 'v1.0.0')
tokenizer = AutoTokenizer.from_pretrained(model_dir)
model = AutoModelForCausalLM.from_pretrained(model_dir, trust_remote_code=True, torch_dtype=torch.bfloat16, device_map='auto')
model.generation_config = GenerationConfig.from_pretrained(model_dir)
model = model.eval()
history = [{"role": "user", "content": "1955年谁是美国总统?他是什么党派?"}]
response = model.chat(tokenizer, history)
print(response)
history.append({"role": "assistant", "content": response})
history.append({"role": "user", "content": "他任职了多少年"})
response = model.chat(tokenizer, history)
print(response)
资源消耗:
微调代码开源地址:
clone swift仓库并安装swift
git clone https://github.com/modelscope/swift.git
cd swift
pip install .
cd examples/pytorch/llm
微调案例
模型微调脚本 (qlora)
# Experimental environment: 3090
# 12GB GPU memory
CUDA_VISIBLE_DEVICES=0 \
python src/llm_sft.py \
--model_type xverse-13b \
--sft_type lora \
--template_type default-generation \
--dtype bf16 \
--output_dir output \
--dataset advertise-gen \
--train_dataset_sample -1 \
--num_train_epochs 1 \
--max_length 2048 \
--quantization_bit 4 \
--bnb_4bit_comp_dtype bf16 \
--lora_rank 8 \
--lora_alpha 32 \
--lora_dropout_p 0. \
--lora_target_modules ALL \
--gradient_checkpointing true \
--batch_size 1 \
--weight_decay 0. \
--learning_rate 1e-4 \
--gradient_accumulation_steps 16 \
--max_grad_norm 0.5 \
--warmup_ratio 0.03 \
--eval_steps 100 \
--save_steps 100 \
--save_total_limit 2 \
--logging_steps 10 \
--push_to_hub false \
--hub_model_id xverse-13b-qlora \
--hub_private_repo true \
--hub_token 'your-sdk-token' \
模型微调后的推理脚本
# If you want to merge LoRA weight and save it, you need to set `--merge_lora_and_save true`.
CUDA_VISIBLE_DEVICES=0 \
python src/llm_infer.py \
--model_type xverse-13b \
--sft_type lora \
--template_type default-generation \
--dtype bf16 \
--ckpt_dir "output/xverse-13b/vx_xxx/checkpoint-xxx" \
--eval_human false \
--dataset advertise-gen \
--max_length 2048 \
--quantization_bit 4 \
--bnb_4bit_comp_dtype bf16 \
--max_new_tokens 1024 \
--temperature 0.9 \
--top_k 20 \
--top_p 0.9 \
--do_sample true \
--merge_lora_and_save false \
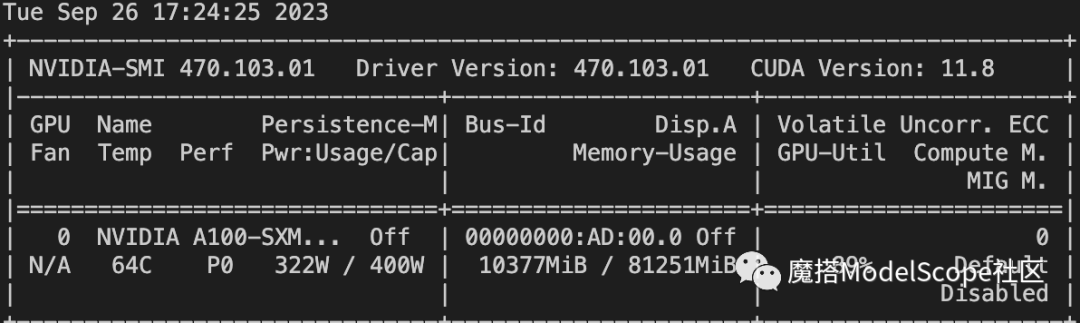
资源消耗
使用 QLoRA 的方式训练的显存占用如下,大约在11G.
点击直达魔搭社区模型详情








 已为社区贡献606条内容
已为社区贡献606条内容

所有评论(0)