

导读
魔搭社区发布了一个名为“InsTagger”的工具,用于分析LLM(大语言模型)中符合人类偏好的监督微调(SFT)数据。InsTagger 是基于 InsTag 方法训练的本地指令标签标注器,用于为符合人类偏好的监督微调数据集中的指令标注描述其意图和语义的标签,从而指导指令的分流或监督微调数据集的分析。
什么是InsTag
在大语言模型监督微调中,微调数据集中指令的多样性和复杂度被认为直接与 LLM 对齐之后的效果相关。近日 WizardLM 等方法也通过构造复杂指令成功提升了 LLM 对齐效果。然而,如何量化的分析微调数据集中指令的多样性和复杂度暂时仍未被充分研究。因此,InsTag 提出通过给指令标注细粒度标签的方式产出一种可解释的指令多样性和复杂度定义方法。
InsTag 收集了大量开源数据集,并利用 ChatGPT 强大的指令跟随能力进行开放式细粒度标签标注。为了解决开放式标注中产生的大量噪声,InsTag 设计了基于规则、语义、及共现性等多维度的降噪聚合方法,从近50万开源指令数据中标注了6K多个细粒度标签。人工评测显示,虽然使用开放式标注方式,经过降噪聚合的标签依旧具有满足下游分析和使用需求的精确度(precision)与一致性(consistency)。
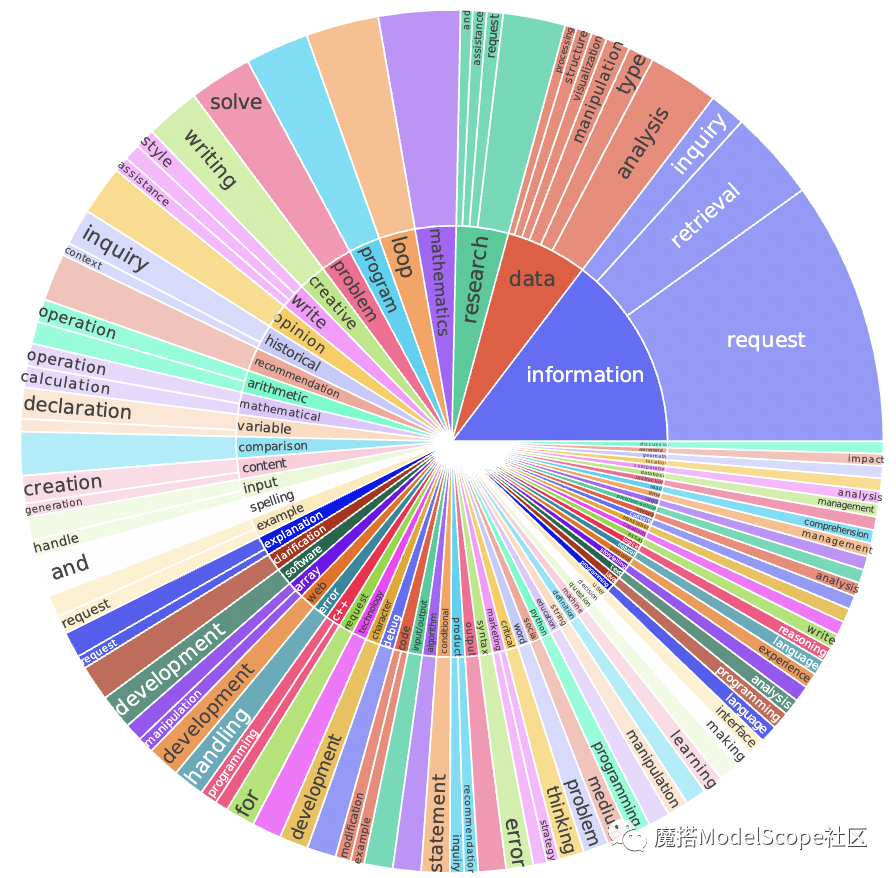
(部分高频标签展示)
InsTag的作用
数据分析
基于 InsTag 分析了流行的开源 SFT 数据集和相关模型,发现模型能力随着数据的多样化和复杂性而增长。同时我们也分析了开源数据集之间基于标签覆盖的相关性,发现 InsTag 产生的标签可以标注出子任务(例如数学与编程),同时也发现少数数据集可以覆盖绝大多数其他数据集。
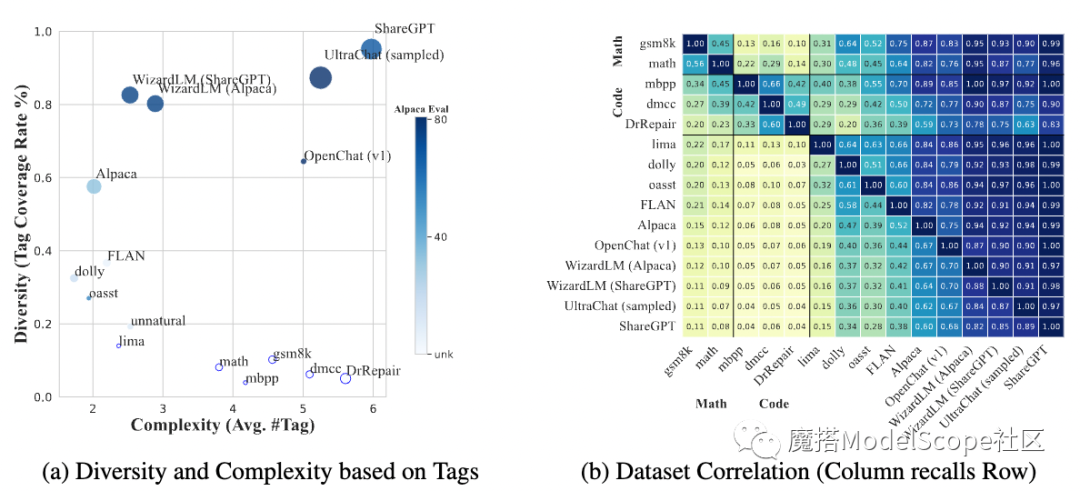
左图:开源数据集指令多样性与复杂度和其在AlpacaEval上的表现展示
右图:基于标签分析开源数据集之间的相关性
数据选择
基于 InsTag 生成标签对开源 SFT 数据进行复杂度优先的全覆盖采样,采样6K条数据用于微调 LLaMA 和 LLaMA-2,微调后的模型 TagLM 在 MT-Bench 上的表现优于许多依赖更多指令微调数据的开源 LLM。同时通过控制变量实验发现模型能力随着数据的多样化和复杂性的增加而增长。
InsTagger是什么
InsTag 是基于 ChatGPT 和后处理的方法。为了能在本地进行指令标签标注,InsTag 在标注及清洗后的约50万指令标签数据上微调了LLaMa-2模型,将指令标签标注的能力蒸馏到了微调后的LLaMa-2中,即InsTagger。
模型链接:
https://modelscope.cn/models/lukeminglkm/instagger_llama2/summary
模型体验链接:
https://www.modelscope.cn/studios/lukeminglkm/instagger_demo/summary
论文地址:
https://arxiv.org/pdf/2308.07074.pdf
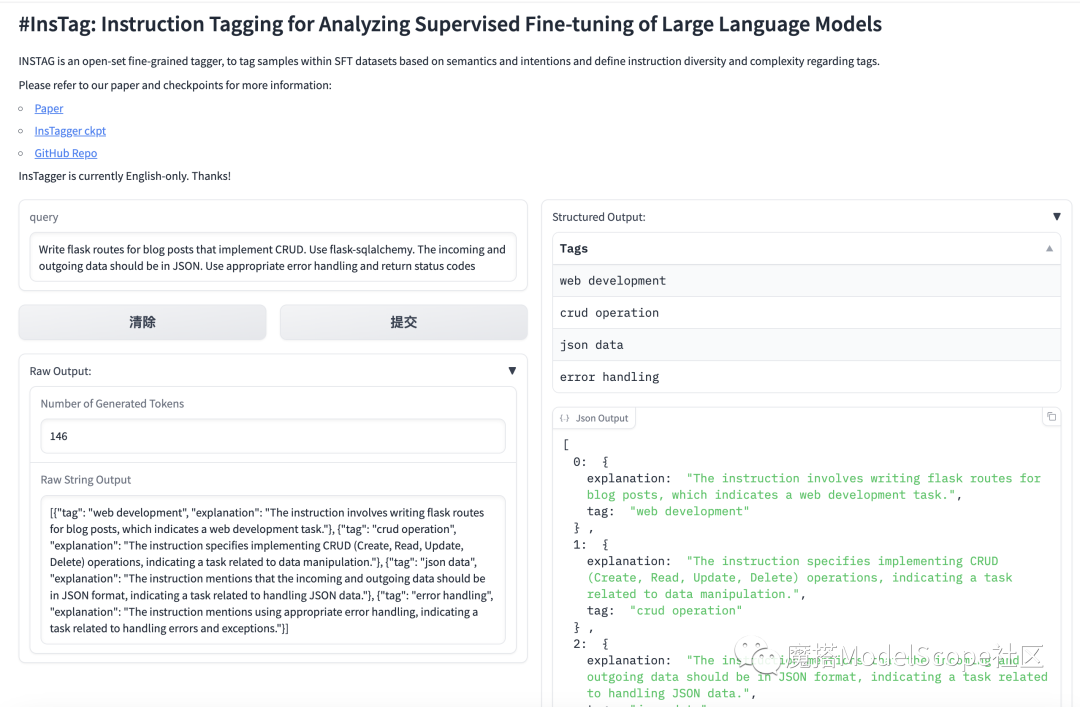
如何使用InsTagger:
InsTagger 是一个基于 LLaMa-2 的 SFT 模型,使用 FastChat 与vicuna模板进行训练。可以使用 FastChat 进行加载与推理,或通过如下手工构造模板的方式直接使用ModelScope 进行推理
import torch
import json
from modelscope import AutoTokenizer, AutoModelForCausalLM
if torch.cuda.is_available():
use_cuda = True
else:
use_cuda = False
# Loading Instag Model
model_id = "lukeminglkm/instagger_llama2"
tokenizer = AutoTokenizer.from_pretrained(model_id, revision = 'v1.0.0')
model = AutoModelForCausalLM.from_pretrained(model_id, device_map='auto', torch_dtype=torch.float16, revision = 'v1.0.0')
model.requires_grad_(False)
model.eval()
# Build prompts for tagging
def make_prompt(query):
prompt = f"Please identify tags of user intentions in the following user query and provide an explanation for each tag. Please response in the JSON format {{\"tag\": str, \"explanation\": str}}.\n User query: {query}"
messages = [("USER", prompt), ("ASSISTANT", None)]
seps = [" ", "</s>"]
ret = "A chat between a curious user and an artificial intelligence assistant. The assistant gives helpful, detailed, and polite answers to the human's questions." + seps[0]
for i, (role, message) in enumerate(messages):
if message:
ret += role + ": " + message + seps[i % 2]
else:
ret += role + ":"
return ret
# Infer with a provided query
def inference(query):
input_str = make_prompt(query)
input_tokens = tokenizer(input_str, return_tensors="pt", padding=True)
if use_cuda:
for t in input_tokens:
if torch.is_tensor(input_tokens[t]):
input_tokens[t] = input_tokens[t].to("cuda")
output = model.generate(
input_tokens['input_ids'],
temperature=0,
do_sample=False,
max_new_tokens=2048,
num_return_sequences=1,
return_dict_in_generate=True,
)
num_input_tokens = input_tokens["input_ids"].shape[1]
output_tokens = output.sequences
generated_tokens = output_tokens[:, num_input_tokens:]
num_generated_tokens = (generated_tokens != tokenizer.pad_token_id).sum(dim=-1).tolist()[0]
generated_text = tokenizer.batch_decode(generated_tokens, skip_special_tokens=True)
string_output = [i.strip() for i in generated_text][0]
return string_output
# Example
query = "Write flask routes for blog posts that implement CRUD. Use flask-sqlalchemy. The incoming and outgoing data should be in JSON. Use appropriate error handling and return status codes"
print(inference(query))
### JSON Output
[{"tag": "web development", "explanation": "The instruction involves writing flask routes for blog posts, which indicates a web development task."}, {"tag": "crud operation", "explanation": "The instruction specifies implementing CRUD (Create, Read, Update, Delete) operations, indicating a task related to data manipulation."}, {"tag": "json data", "explanation": "The instruction mentions that the incoming and outgoing data should be in JSON format, indicating a task related to handling JSON data."}, {"tag": "error handling", "explanation": "The instruction mentions using appropriate error handling, indicating a task related to handling errors and exceptions."}]
创空间体验:
所有模型均基于 LLaMA 或 LLaMA-2,并且应相应地在其许可下使用。
https://www.modelscope.cn/studios/lukeminglkm/instagger_demo/summary








 已为社区贡献633条内容
已为社区贡献633条内容

所有评论(0)