


魔搭社区每周速递(6.21-6.27)
·
魔搭ModelScope本周带来:
9个模型:包括:chatglm2-6b、CAM++说话人日志-对话场景角色区分-通用、Sunsimiao-01M-Chat-lora等;
6个数据集:文生图风格定制数据集、视频-文本预训练、CoT_zh智能对话、alpaca_data_cleaned等;
1个创新应用:ChatGLM2-6B对话机器人 unofficial;
1篇文章:魔搭公布AI编程大赛赛题;
chatglm2-6b
ChatGLM2-6B 是开源中英双语对话模型 ChatGLM-6B 的第二代版本,在保留了初代模型对话流畅、部署门槛较低等众多优秀特性的基础之上,ChatGLM2-6B 引入了如下新特性:
更强大的性能:基于 ChatGLM 初代模型的开发经验,我们全面升级了 ChatGLM2-6B 的基座模型。ChatGLM2-6B 使用了 GLM 的混合目标函数,经过了 1.4T 中英标识符的预训练与人类偏好对齐训练,评测结果显示,相比于初代模型,ChatGLM2-6B 在 MMLU(+23%)、CEval(+33%)、GSM8K(+571%) 、BBH(+60%)等数据集上的性能取得了大幅度的提升,在同尺寸开源模型中具有较强的竞争力。
更长的上下文:基于 FlashAttention 技术,我们将基座模型的上下文长度(Context Length)由 ChatGLM-6B 的 2K 扩展到了 32K,并在对话阶段使用 8K 的上下文长度训练,允许更多轮次的对话。但当前版本的 ChatGLM2-6B 对单轮超长文档的理解能力有限,我们会在后续迭代升级中着重进行优化。
更高效的推理:基于 Multi-Query Attention 技术,ChatGLM2-6B 有更高效的推理速度和更低的显存占用:在官方的模型实现下,推理速度相比初代提升了 42%,INT4 量化下,6G 显存支持的对话长度由 1K 提升到了 8K。
示例代码
from modelscope.utils.constant import Tasks
from modelscope.pipelines import pipeline
pipe = pipeline(task=Tasks.chat, model='ZhipuAI/chatglm2-6b', model_revision='v1.0.2',device_map='auto')
inputs = {'text':'你好', 'history': []}
result = pipe(inputs)
inputs = {'text':'介绍下清华大学', 'history': result['history']}
result = pipe(inputs)
print(result)
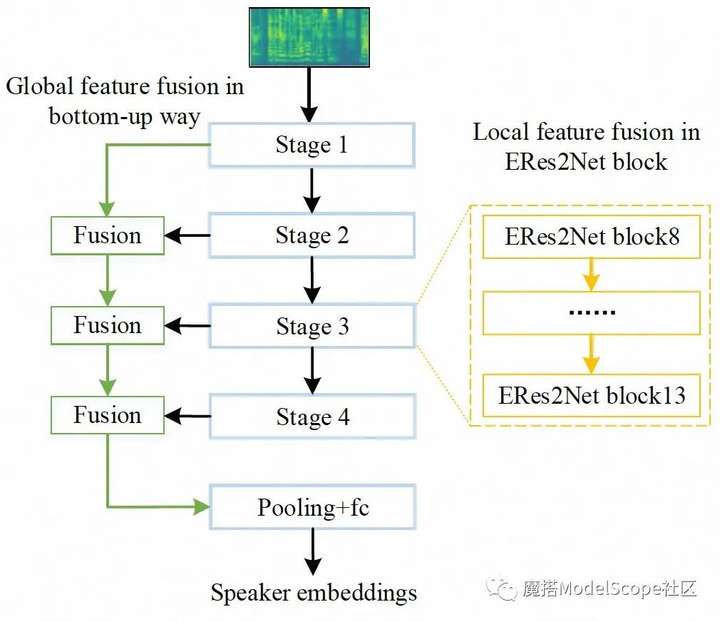
ERes2Net说话人确认-中文-通用-200k-Spkrs
ERes2Net模型是在Res2Net的基础上,对全局和局部特征进一步融合,从而提高说话人识别性能。局部特征融合将一个单一残差块内的特征融合提取局部信号;全局特征融合使用不同层级输出的不同尺度声学特征聚合全局信号;为了实现有效的特征融合,ERes2Net架构中采用了注意力特征融合模块。
CAM++说话人日志-对话场景角色区分-通用
输入一段多人对话的音频,本模型可以自动的识别音频中的对话人数,并且对其进行区分,适合用于客服对话、会议讨论、采访等场景,该系统配合语音识别可进一步搭建多人对话的语音识别系统。
本模型是基于分段-聚类(segmentation-clustering)模块化的框架,整个流程可分为4个部分,首先使用语音活动端点检测(Voice activity Detection,VAD)模块去除输入音频中的非人声部分,然后将音频按照固定的窗移和窗长进行切段,随后利用说话人模型提取这些音频段中的说话人特征,最后对这些特征进行聚类,识别出每个人的音频段,输出相应的时间信息。在确定说话人转换点的位置如果配套使用说话人转换点识别模型,识别会更准确。
chatglm2-6b
https://modelscope.cn/studios/AI-ModelScope/ChatGLM6B-unofficial/summary
精选数据集推荐
文生图风格定制数据集
文生图风格定制数据集用于定制不同风格的文生图模型.
本数据集包括6类风格: watercolor(水墨画风格)、3D(3D风格)、anime(日漫风格)、flatillustration(平面插图风格)、oilpainting(油画风格)、sketch(素描风格).
训练集:上述6类风格,每类风格30张图片+对应的prompt.
测试集:上述6类风格,每类风格10条prompt.
数据集加载方式
from modelscope.msdatasets import MsDataset
ms_train_dataset = MsDataset.load('style_custom_dataset', namespace='damo', split='train')
print(next(iter(ms_train_dataset)))
ms_test_dataset = MsDataset.load('style_custom_dataset', namespace='damo', split='test')
print(next(iter(ms_test_dataset)))
CoT_zh
CoT数据集是通过对FLAN发布的9个CoT数据集进行格式化组合得到的。它包含9个CoT任务,涉及74771个样本。CoT_zh数据集是通过使用谷歌翻译将CoT数据集转成中文得到的。
数据集加载方式
from modelscope.msdatasets import MsDataset
from modelscope.utils.constant import DownloadMode
# Load the CoT chinese dataset
ds_train = MsDataset.load('YorickHe/CoT_zh', split='train', download_mode=DownloadMode.FORCE_REDOWNLOAD)
print(next(iter(ds_train)))

ModelScope旨在打造下一代开源的模型即服务共享平台,为泛AI开发者提供灵活、易用、低成本的一站式模型服务产品,让模型应用更简单!
更多推荐



 0
0 0
0- 0



 已为社区贡献629条内容
已为社区贡献629条内容

所有评论(0)