
Qwen3-0.6B这种迷你模型的意义和用途是什么?
由于模型架构的改进、训练数据的增加以及更有效的训练方法,Qwen3 Dense 基础模型的整体性能与参数更多的Qwen2.5基础模型相当。经过后训练的模型,例如 Qwen3-30B-A3B,以及它们的预训练基座模型(如 Qwen3-30B-A3B-Base),现已在 Hugging Face、ModelScope 和 Kaggle 等平台上开放使用。在第二阶段(S2),我们通过增加知识密集型数据(
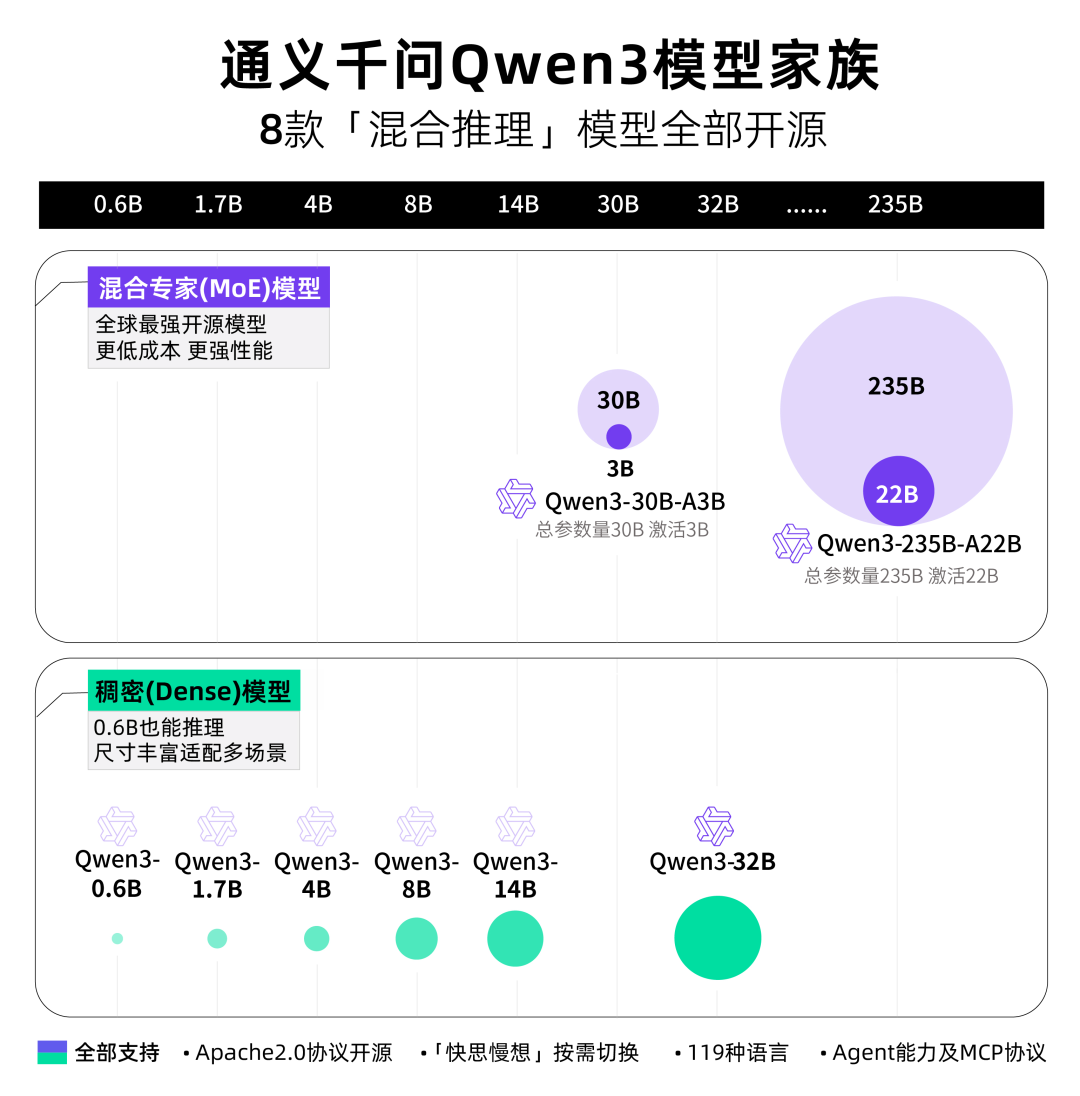
五一假期前,Qwen3正式发布并全部开源8款「混合推理模型」。
此次开源包括两款MoE模型:Qwen3-235B-A22B(2350多亿总参数、 220多亿激活参),以及Qwen3-30B-A3B(300亿总参数、30亿激活参数);以及六个Dense模型:Qwen3-32B、Qwen3-14B、Qwen3-8B、Qwen3-4B、Qwen3-1.7B和Qwen3-0.6B。
- 旗舰模型Qwen3-235B-A22B在代码、数学、通用能力等基准测试中,与一众顶级模型相比,表现出极具竞争力的结果。
学习AI大模型是一项系统工程,需要时间和持续的努力。但随着技术的发展和在线资源的丰富,零基础的小白也有很好的机会逐步学习和掌握。【点击蓝字获取】
【2025最新】AI大模型全套学习籽料(可白嫖):LLM面试题+AI大模型学习路线+大模型PDF书籍+640套AI大模型报告等等,从入门到进阶再到精通,超全面存下吧!

- 小型MoE模型Qwen3-30B-A3B的激活参数数量是QwQ-32B10%,表现更胜一筹, Qwen3-4B 这样的小模型也能匹敌 Qwen2.5-72B-Instruct 的性能。

经过后训练的模型,例如 Qwen3-30B-A3B,以及它们的预训练基座模型(如 Qwen3-30B-A3B-Base),现已在 Hugging Face、ModelScope 和 Kaggle 等平台上开放使用。对于部署,我们推荐使用 SGLang 和 vLLM 等框架;而对于本地使用,像 Ollama、LMStudio、MLX、llama.cpp 和 KTransformers 这样的工具也非常值得推荐。这些选项确保用户可以轻松将 Qwen3 集成到他们的工作流程中,无论是用于研究、开发还是生产环境。
我们相信,Qwen3 的发布和开源将极大地推动大型基础模型的研究与开发。我们的目标是为全球的研究人员、开发者和组织赋能,帮助他们利用这些前沿模型构建创新解决方案。
目前,全球开发者、研究机构和企业均可免费在魔搭社区、HuggingFace等平台下载模型并商用,也可以通过阿里云百炼调用Qwen3的API服务。个人用户可立即通过通义APP直接体验Qwen3,夸克也即将全线接入Qwen3。
-
GitHub:
https://github.com/QwenLM/Qwen3
-
Hugging Face:
https://huggingface.co/collections/Qwen/qwen3-67dd247413f0e2e4f653967f
-
魔搭社区:
https://modelscope.cn/collections/Qwen3-9743180bdc6b48
#核心亮点
*// 多种思考模式*
Qwen3 模型支持两种思考模式:
\1. 思考模式:在这种模式下,模型会逐步推理,经过深思熟虑后给出最终答案。这种方法非常适合需要深入思考的复杂问题。
\2. 非思考模式:在此模式中,模型提供快速、近乎即时的响应,适用于那些对速度要求高于深度的简单问题。
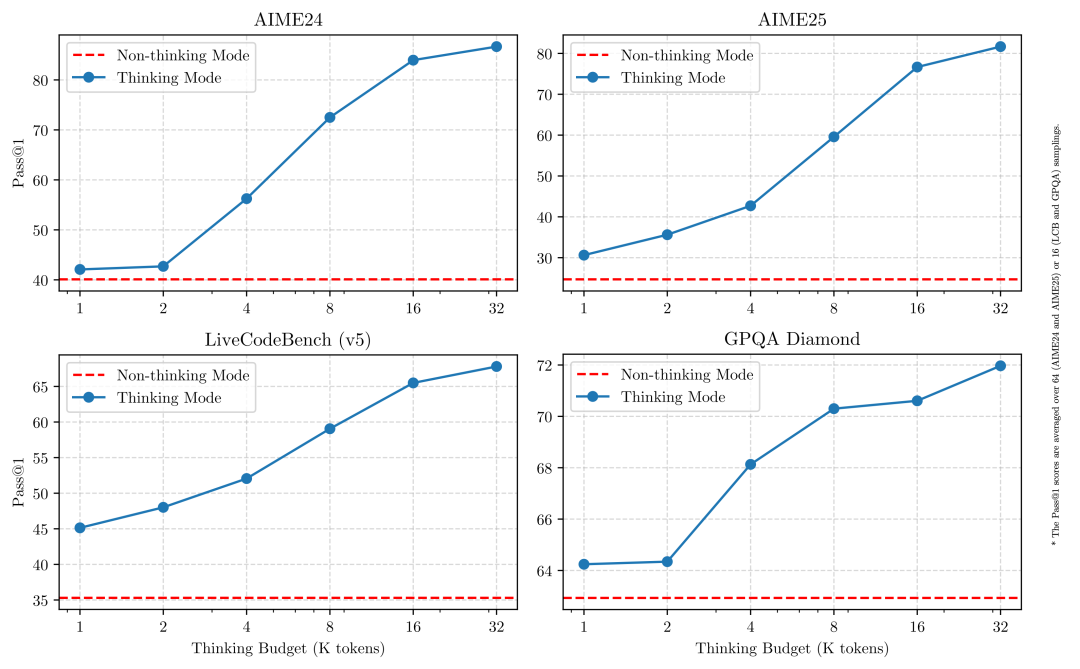
这种灵活性使用户能够根据具体任务控制模型进行“思考”的程度。例如,复杂的问题可以通过扩展推理步骤来解决,而简单的问题则可以直接快速作答,无需延迟。至关重要的是,这两种模式的结合大大增强了模型实现稳定且高效的“思考预算”控制能力。如上文所述,Qwen3 展现出可扩展且平滑的性能提升,这与分配的计算推理预算直接相关。这样的设计让用户能够更轻松地为不同任务配置特定的预算,在成本效益和推理质量之间实现更优的平衡。
*// 多语言*
Qwen3 模型支持 119 种语言和方言。这一广泛的多语言能力为国际应用开辟了新的可能性,让全球用户都能受益于这些模型的强大功能。

// 增强的 Agent 能力
我们优化了 Qwen3 模型的 Agent 和 代码能力,同时也加强了对 MCP 的支持。
*#预训练*
***
在预训练方面,Qwen3 的数据集相比 Qwen2.5 有了显著扩展。Qwen2.5是在 18 万亿个 token 上进行预训练的,而 Qwen3 使用的数据量几乎是其两倍,达到了约 36 万亿个 token,涵盖了 119 种语言和方言。为了构建这个庞大的数据集,我们不仅从网络上收集数据,还从 PDF 文档中提取信息。我们使用 Qwen2.5-VL 从这些文档中提取文本,并用 Qwen2.5 改进提取内容的质量。为了增加数学和代码数据的数量,我们利用 Qwen2.5-Math 和 Qwen2.5-Coder 这两个数学和代码领域的专家模型合成数据,合成了包括教科书、问答对以及代码片段等多种形式的数据。
预训练过程分为三个阶段。在第一阶段(S1),模型在超过 30 万亿个 token 上进行了预训练,上下文长度为 4K token。这一阶段为模型提供了基本的语言技能和通用知识。在第二阶段(S2),我们通过增加知识密集型数据(如 STEM、编程和推理任务)的比例来改进数据集,随后模型又在额外的 5 万亿个 token 上进行了预训练。在最后阶段,我们使用高质量的长上下文数据将上下文长度扩展到 32K token,确保模型能够有效地处理更长的输入。
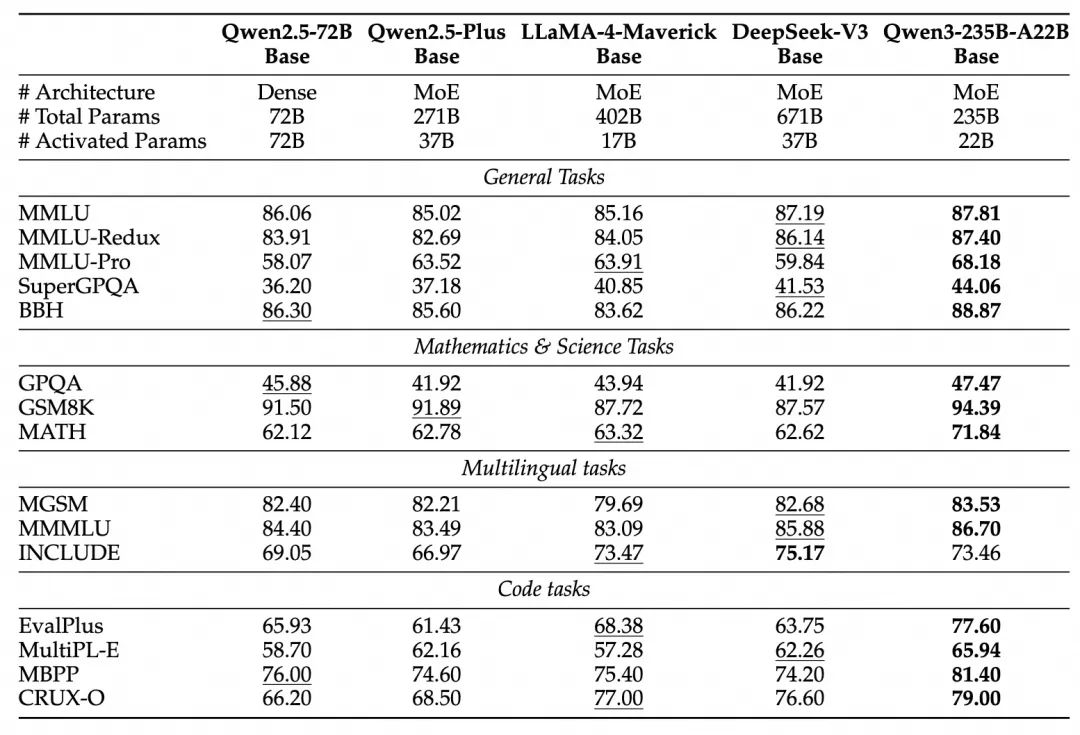
由于模型架构的改进、训练数据的增加以及更有效的训练方法,Qwen3 Dense 基础模型的整体性能与参数更多的Qwen2.5基础模型相当。例如,Qwen3-1.7B/4B/8B/14B/32B-Base分别与Qwen2.5-3B/7B/14B/32B/72B-Base 表现相当。特别是在 STEM、编码和推理等领域,Qwen3 Dense 基础模型的表现甚至超过了更大规模的 Qwen2.5 模型。对于 Qwen3 MoE 基础模型,它们在仅使用 10% 激活参数的情况下达到了与 Qwen2.5 Dense 基础模型相似的性能。这带来了训练和推理成本的显著节省。
*#后训练*
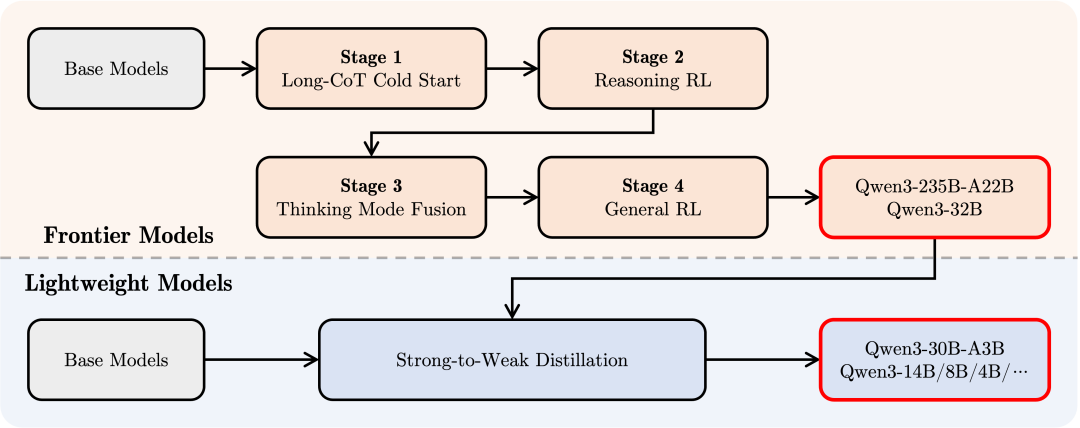
为了开发能够同时具备思考推理和快速响应能力的混合模型,我们实施了一个四阶段的训练流程。该流程包括:(1)长思维链冷启动,(2)长思维链强化学习,(3)思维模式融合,以及(4)通用强化学习。
在第一阶段,我们使用多样的的长思维链数据对模型进行了微调,涵盖了数学、代码、逻辑推理和 STEM 问题等多种任务和领域。这一过程旨在为模型配备基本的推理能力。第二阶段的重点是大规模强化学习,利用基于规则的奖励来增强模型的探索和钻研能力。
在第三阶段,我们在一份包括长思维链数据和常用的指令微调数据的组合数据上对模型进行微调,将非思考模式整合到思考模型中。确保了推理和快速响应能力的无缝结合。最后,在第四阶段,我们在包括指令遵循、格式遵循和 Agent 能力等在内的 20 多个通用领域的任务上应用了强化学习,以进一步增强模型的通用能力并纠正不良行为。
学习AI大模型是一项系统工程,需要时间和持续的努力。但随着技术的发展和在线资源的丰富,零基础的小白也有很好的机会逐步学习和掌握。【点击蓝字获取】
【2025最新】AI大模型全套学习籽料(可白嫖):LLM面试题+AI大模型学习路线+大模型PDF书籍+640套AI大模型报告等等,从入门到进阶再到精通,超全面存下吧!

ModelScope旨在打造下一代开源的模型即服务共享平台,为泛AI开发者提供灵活、易用、低成本的一站式模型服务产品,让模型应用更简单!
更多推荐



 27
27 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)