
阿里发布最强开源模型Qwen3,成本仅为DeepSeek-R1三分之一
4月29日凌晨,阿里巴巴开源新一代通义千问模型Qwen3,参数量仅为DeepSeek-R1的1/3,成本大幅下降,性能全面超越R1、OpenAI-o1等全球顶尖模型,登顶全球最强开源模型。Qwen3是国内首个“混合推理模型”,“快思考”与“慢思考”集成进同一个模型,对简单需求可低算力“秒回”答案,对复杂问题可多步骤“深度思考”,大大节省算力消耗。
4月29日凌晨,阿里巴巴开源新一代通义千问模型Qwen3,参数量仅为DeepSeek-R1的1/3,成本大幅下降,性能全面超越R1、OpenAI-o1等全球顶尖模型,登顶全球最强开源模型。Qwen3是国内首个“混合推理模型”,“快思考”与“慢思考”集成进同一个模型,对简单需求可低算力“秒回”答案,对复杂问题可多步骤“深度思考”,大大节省算力消耗。
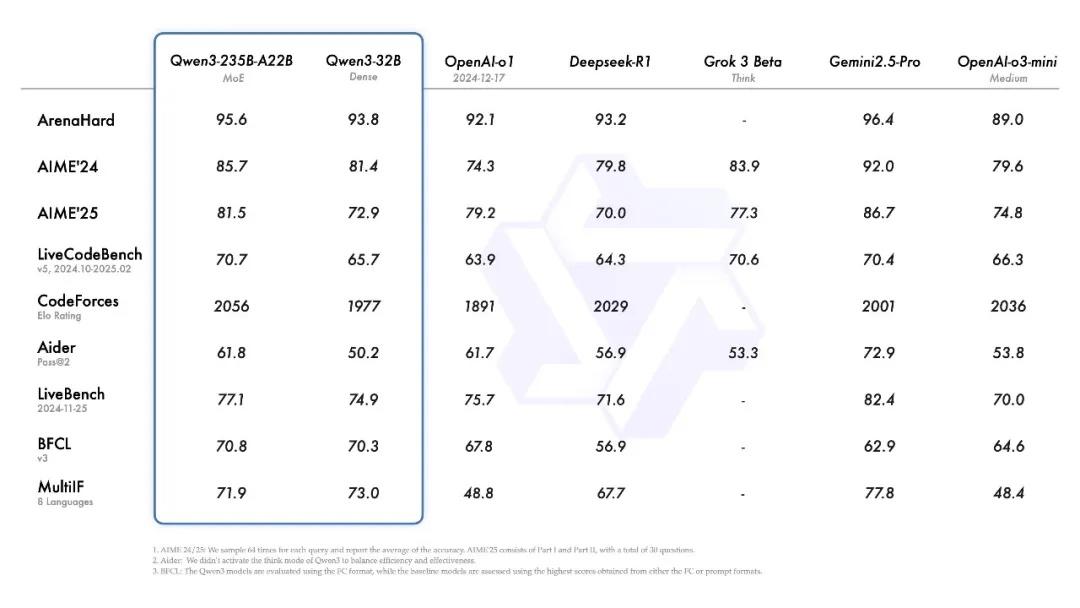
性能媲美DeepSeek R1、OpenAI o1,全部开源
Qwen3系列包括两个专家混合 (MoE) 模型和另外六个模型。阿里巴巴表示,最新发型的旗舰模型Qwen3-235B-A22B在代码、数学、通用能力等基准测试中,与DeepSeek-R1、o1、o3-mini、Grok-3和Gemini-2.5-Pro等顶级模型相比,表现出极具竞争力。
此外,被称为“专家混合”(MoE,Mixture-of-Experts)模型的Qwen3-30B-A3B的激活参数数量是QwQ-32B的10%,表现更胜一筹,甚至像Qwen3-4B这样的小模型也能匹敌Qwen2.5-72B-Instruct的性能。这类系统模拟人类解决问题的思维方式,将任务划分为更小的数据集,类似于让一组各有所长的专家分别负责不同部分,从而提升整体效率。
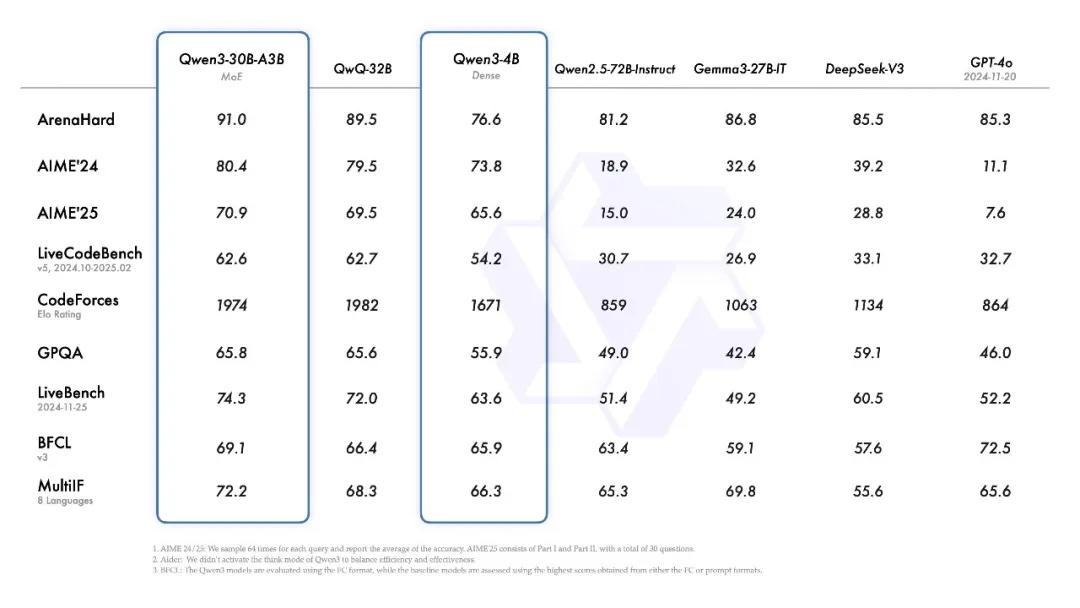
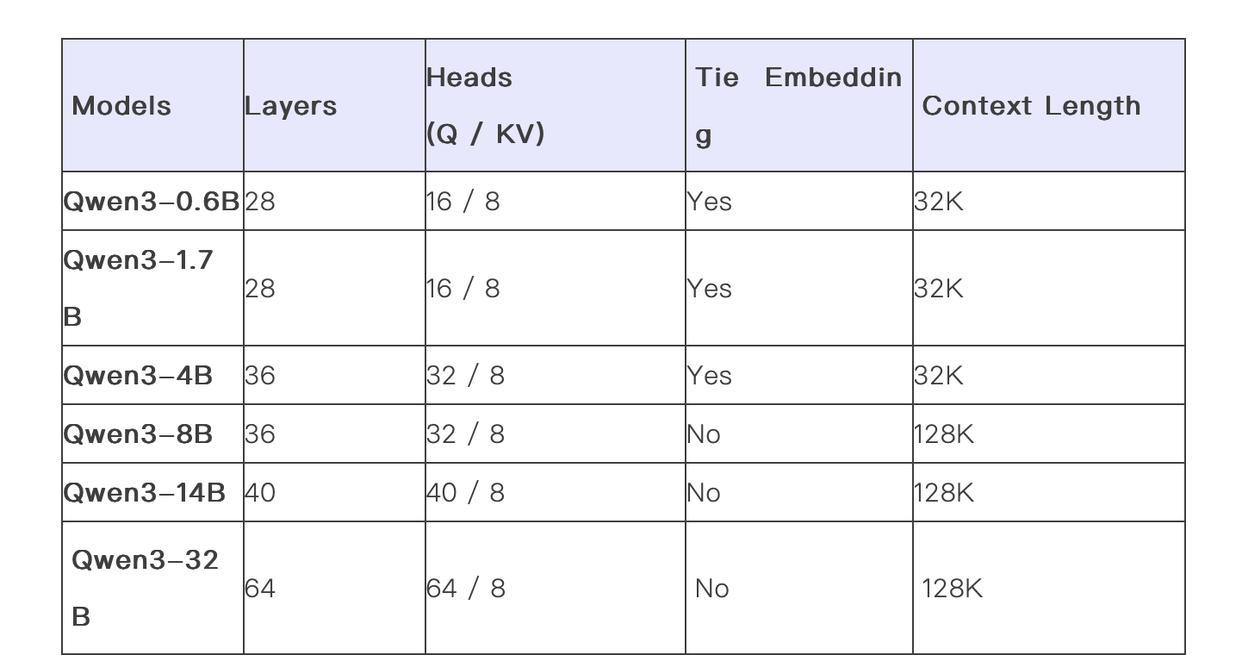
同时,阿里巴巴还开源了两个MoE模型的权重:拥有2350多亿总参数和220多亿激活参数的Qwen3-235B-A22B,以及拥有约300亿总参数和30亿激活参数的小型MoE 模型Qwen3-30B-A3B。此外,六个Dense模型也已开源,包括Qwen3-32B、Qwen3-14B、Qwen3-8B、Qwen3-4B、Qwen3-1.7B和Qwen3-0.6B,均在Apache 2.0许可下开源。
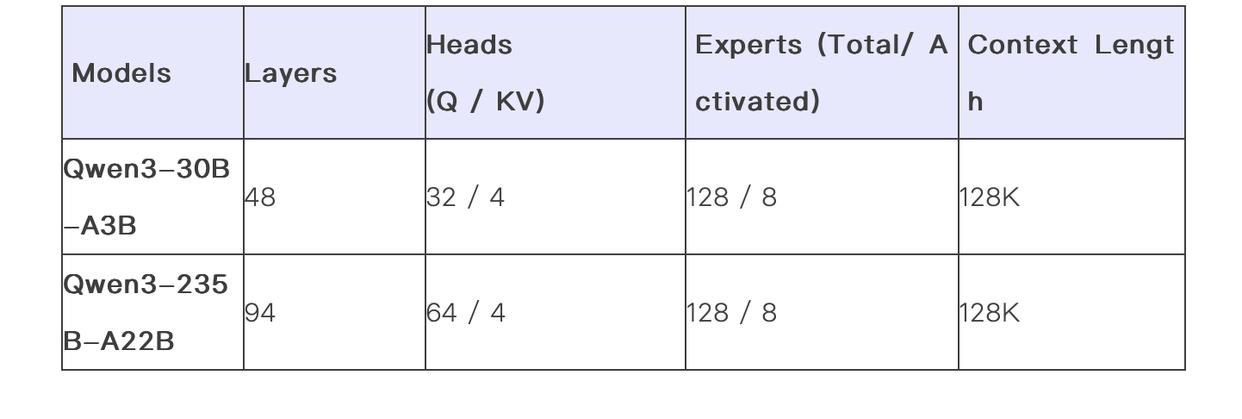
“混合型”模型,两种思考模式,部署成本大降
阿里巴巴表示,Qwen 3系列的一大创新在于其"混合型"模型设计,集成了两种思考模式。Qwen3既可以花时间"推理"解决复杂问题(思考模式),也可以快速回答简单请求(非思考模式)。“思考模式”中的推理能力使得模型能够有效地进行自我事实核查,类似于OpenAI的o3模型,但代价是推理过程中的延迟时间较高。
Qwen团队在博客文章中写道:
这种灵活性使用户能够根据具体任务控制模型进行“思考”的程度。例如**,复杂的问题可以通过扩展推理步骤来解决,而简单的问题则可以直接快速作答,无需延迟。**
至关重要的是,这两种模式的结合大大增强了模型实现稳定且高效的“思考预算”控制能力。如上文所述,Qwen3展现出可扩展且平滑的性能提升,这与分配的计算推理预算直接相关。
这样的设计让用户能够自行设置“思考成本”,更轻松地为不同任务配置特定的预算,在成本效益和推理质量之间实现更优的平衡。与性能相当的其他大模型相比,Qwen3.0显著降低了部署门槛,根据数据对比:
- 满血版671B DeepSeek-R1**需要8张H20(约100万元)**才能运行,推荐配置16张H20(约200万元)。
- 千问3旗舰模型**仅需3张H20(约36万元)**即可运行,推荐配置4张H20(约50万元)。
因此从部署成本角度看,Qwen3.0旗舰模型是满血版R1的25%~35%,部署成本大降75%~65%。
训练数据量是Qwen2.5的两倍,便于Agent调用
**阿里巴巴表示,Qwen3系列支持119种语言,并基于近36万亿个token(标记)进行训练,使用的数据量是Qwen2.5的两倍。**Token是模型处理的基本数据单元,约100万个token相当于75万英文单词。阿里巴巴称,Qwen3的训练数据包括教材、问答对、代码片段等多种内容。
据介绍,Qwen3预训练过程分为三个阶段。在第一阶段(S1),模型在超过30万亿个token上进行了预训练,上下文长度为4K token。这一阶段为模型提供了基本的语言技能和通用知识。
在第二阶段(S2),训练则通过增加知识密集型数据(如 STEM、编程和推理任务)的比例来改进数据集,随后模型又在额外的5万亿个token上进行了预训练。在最后阶段则使用高质量的长上下文数据将上下文长度扩展到32K token,确保模型能够有效地处理更长的输入。
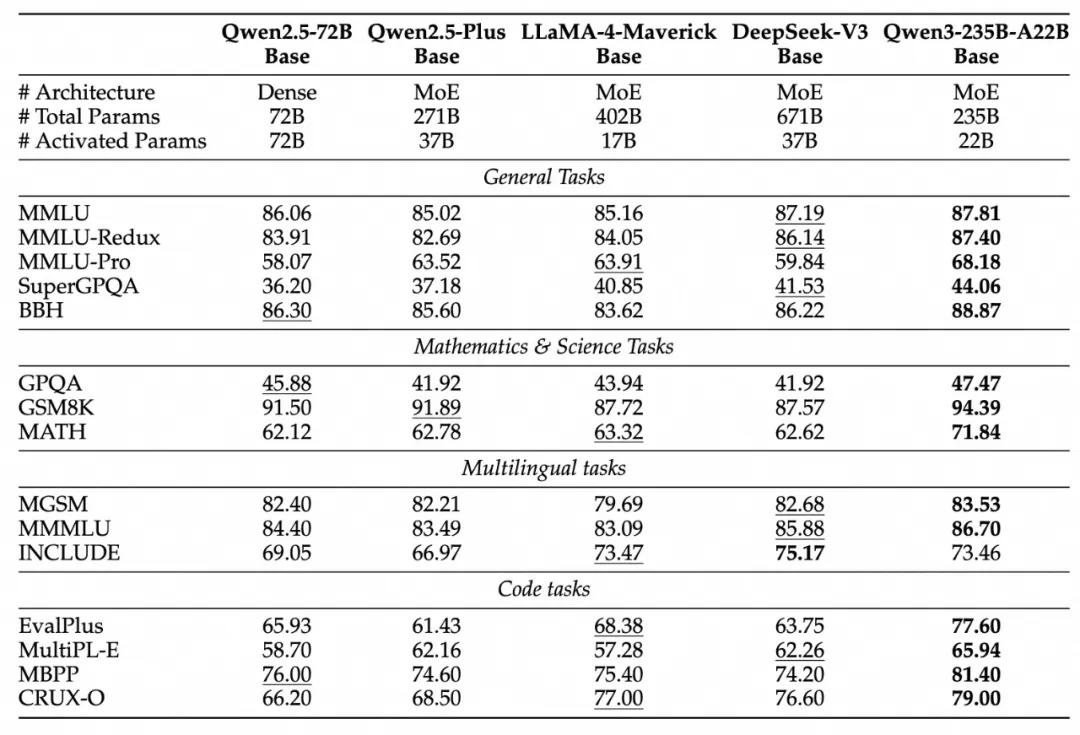
阿里巴巴表示,由于模型架构的改进、训练数据的增加以及更有效的训练方法,Qwen3 Dense基础模型的整体性能与参数更多的Qwen2.5基础模型相当。例如,Qwen3-1.7B/4B/8B/14B/32B-Base分别与Qwen2.5-3B/7B/14B/32B/72B-Base 表现相当。特别是在 STEM、编码和推理等领域,Qwen3 Dense基础模型的表现甚至超过了更大规模的Qwen2.5 模型。对于Qwen3 MoE基础模型,它们在仅使用10%激活参数的情况下达到了与Qwen2.5 Dense基础模型相似的性能,显著节省了训练和推理成本。
而在后训练阶段,阿里使用多样的的长思维链数据对模型进行了微调,涵盖了数学、代码、逻辑推理和 STEM 问题等多种任务和领域,为模型配备基本的推理能力。然后通过大规模强化学习,利用基于规则的奖励来增强模型的探索和钻研能力。
阿里巴巴表示,Qwen3在调用工具(tool-calling)、执行指令以及复制特定数据格式等能力方面表现出色,推荐用户使用Qwen-Agent来充分发挥Qwen3的Agent能力。Qwen-Agent内部封装了工具调用模板和工具调用解析器,大大降低了代码复杂性。
除了提供下载版本外,Qwen3还可以通过Fireworks AI、Hyperbolic等云服务提供商使用。
目标仍对准AGI
OpenAI、谷歌和Anthropic近期也陆续推出了多款新模型。OpenAI近日表示,也计划在未来几个月发布一款更加“开放”的模型,模仿人类推理方式,这标志着其策略出现转变,此前DeepSeek和阿里巴巴已经率先推出了开源AI系统。
目前,阿里巴巴正以Qwen为核心,构建其AI版图。今年2月,首席执行官吴泳铭表示,公司目前的“首要目标”是实现通用人工智能(AGI)——即打造具备人类智力水平的AI系统。
阿里表示,Qwen3代表了该公司在通往通用人工智能(AGI)和超级人工智能(ASI)旅程中的一个重要里程碑。展望未来,阿里计划从多个维度提升模型,包括优化模型架构和训练方法,以实现几个关键目标:扩展数据规模、增加模型大小、延长上下文长度、拓宽模态范围,并利用环境反馈推进强化学习以进行长周期推理。
开源社区振奋
阿里Qwen3的发布让AI社区感到激动,有网友献上经典Meme:
有网友说,
在我的测试中,235B在高维张量运算方面的表现相当于Sonnet。
这是一个非常出色的模型,
感谢你们。
有网友对Qwen3赞不绝口:
如果不是亲眼看到屏幕上实时生成的tokens,我根本不会相信那些基准测试结果。??? 简直像魔法一样???
而开源AI的支持者则更加兴奋。有网友说:
“有了一个开源32B大模型,性能跟Gemini 2.5 Pro不相上下。”
“我们彻底杀回来了!”
网友感谢阿里积极推动开源:
i 2.5 Pro不相上下。”
“我们彻底杀回来了!”
[外链图片转存中…(img-IYgx16ky-1745898373227)]
网友感谢阿里积极推动开源:

大模型风口已至:月薪30K+的AI岗正在批量诞生
2025年大模型应用呈现爆发式增长,根据工信部最新数据:
国内大模型相关岗位缺口达47万
初级工程师平均薪资28K(数据来源:BOSS直聘报告)
70%企业存在"能用模型不会调优"的痛点
真实案例:某二本机械专业学员,通过4个月系统学习,成功拿到某AI医疗公司大模型优化岗offer,薪资直接翻3倍!
如何学习AI大模型 ?
“最先掌握AI的人,将会比较晚掌握AI的人有竞争优势”。
这句话,放在计算机、互联网、移动互联网的开局时期,都是一样的道理。
相信大家在刚刚开始学习的过程中总会有写摸不着方向,故此将并将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程等免费分享出来。
如果你是零基础小白,想快速入门大模型是可以考虑的。
一方面是学习时间相对较短,学习内容更全面更集中。
二方面是可以根据这些资料规划好学习计划和方向。
😝有需要的小伙伴,可以微信扫码领取!

👉1.大模型入门学习思维导图👈
要学习一门新的技术,作为新手一定要先有一个明确的学习路线,方向不对,努力白费。
对于从来没有接触过AI大模型的同学,我们帮你准备了详细的学习路线图。可以说是最科学最系统的学习路线,大家跟着这个大的方向学习准没问题。(完整路线在公众号内领取)

大模型学习路线
👉2.大模型配套视频👈
很多朋友都不喜欢晦涩的文字,我也为大家准备了视频教程,每个章节都是当前板块的精华浓缩。(篇幅有限,仅展示部分)

大模型教程
👉3.大模型经典学习电子书👈
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。(篇幅有限,仅展示部分,公众号内领取)

电子书
👉4.大模型面试题&答案👈
截至目前大模型已经超过200个,在大模型纵横的时代,不仅大模型技术越来越卷,就连大模型相关的岗位和面试也开始越来越卷了。为了让大家更容易上车大模型算法赛道,我总结了大模型常考的面试题。(篇幅有限,仅展示部分,公众号内领取)

大模型面试
**因篇幅有限,仅展示部分资料,需要的扫描下方二维码领取 **


ModelScope旨在打造下一代开源的模型即服务共享平台,为泛AI开发者提供灵活、易用、低成本的一站式模型服务产品,让模型应用更简单!
更多推荐


 12
12 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)