
阿里Qwen3深夜开源,增强Agent能力,加强对MCP支持
经过后训练的模型,例如Qwen3-30B-A3B,以及它们的预训练基座模型(如Qwen3-30B-A3B-Base),现已在HuggingFace、ModelScope和Kaggle等平台上开放使用。对于部署,我们推荐使用SGLang和vLLM等框架;而对于本地使用,像Ollama、LMStudio、MLX、llama.cpp和KTransformers这样的工具也非常值得推荐。
前言
2025年4月29日,阿里通义千问推出了其最新一代开源大型语言模型Qwen3系列。

经过后训练的模型,例如Qwen3-30B-A3B,以及它们的预训练基座模型(如Qwen3-30B-A3B-Base),现已在HuggingFace、ModelScope和Kaggle等平台上开放使用。对于部署,我们推荐使用SGLang和vLLM等框架;而对于本地使用,像Ollama、LMStudio、MLX、llama.cpp和KTransformers这样的工具也非常值得推荐。
**github代码仓库:**https://github.com/QwenLM/Qwen3
QwenChat网页版(https://chat.qwen.ai/)和手机APP中试用Qwen3!
Qwen3模型开源
开源了两个MoE模型的权重:Qwen3-235B-A22B,一个拥有2350多亿总参数和220多亿激活参数的大模型,以及Qwen3-30B-A3B,一个拥有约300亿总参数和30亿激活参数的小型MoE模型。
开源了六个Dense模型,包括Qwen3-32B、Qwen3-14B、Qwen3-8B、Qwen3-4B、Qwen3-1.7B和Qwen3-0.6B,均在Apache2.0许可下开源。
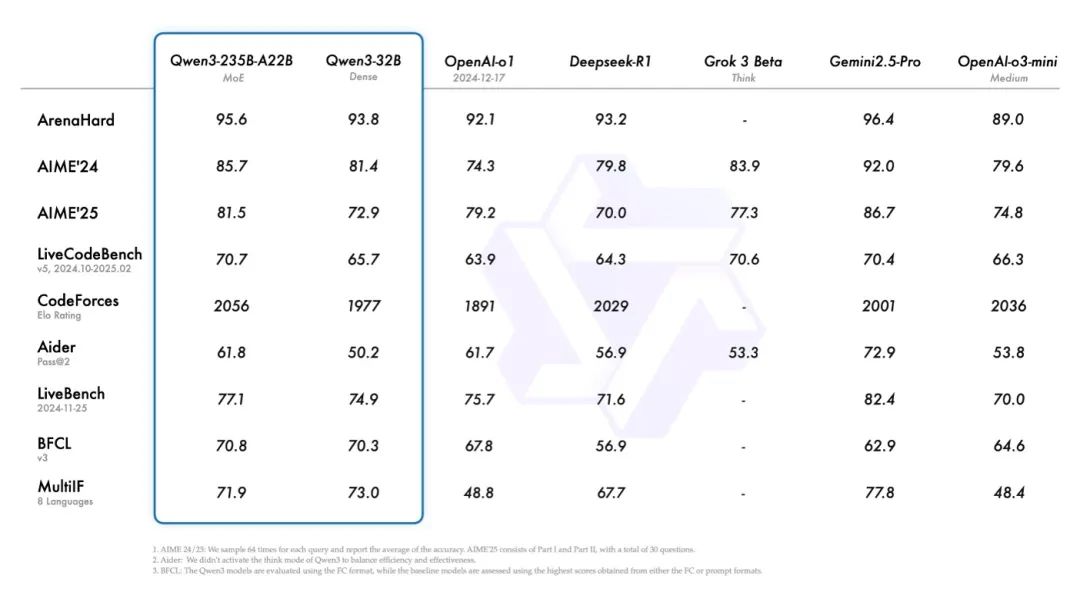
Qwen3模型在行业基准测试中取得顶级成果
Qwen3核心亮点
- **引入混合思考模式:**用户可切换“思考模式、“非思考模式”,自己控制思考程度;
- **推理能力提升:**在代码、数学、通用能力等基准测试中,与DeepSeek-R1、o1、o3-mini、Grok-3和Gemini-2.5-Pro等顶级模型相比,表现出极具竞争力的结果;
- **增强的Agent能力:**优化了Qwen3模型的Agent和代码能力;
- **支持MCP(模型上下文协议):**加强了对MCP的支持;
- **支持119种语言和方言:**具备多语言理解、推理、指令跟随和生成能力。
快速开始Qwen3
以下是如何在不同框架中使用Qwen3的简单指南。下面提供了一个在HuggingFacetransformers中使用Qwen3-30B-A3B的标准示例:
frommodelscopeimportAutoModelForCausalLM,AutoTokenizer
model_name="Qwen/Qwen3-30B-A3B"
#loadthetokenizerandthemodel
tokenizer=AutoTokenizer.from_pretrained(model_name)
model=AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype="auto",
device_map="auto"
)
#preparethemodelinput
prompt="Givemeashortintroductiontolargelanguagemodel."
messages=[
{"role":"user","content":prompt}
]
text=tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True,
enable_thinking=True#Switchbetweenthinkingandnon-thinkingmodes.DefaultisTrue.
)
model_inputs=tokenizer([text],return_tensors="pt").to(model.device)
#conducttextcompletion
generated_ids=model.generate(
**model_inputs,
max_new_tokens=32768
)
output_ids=generated_ids[0][len(model_inputs.input_ids[0]):].tolist()
#parsingthinkingcontent
try:
#rindexfinding151668(</think>)
index=len(output_ids)-output_ids[::-1].index(151668)
exceptValueError:
index=0
thinking_content=tokenizer.decode(output_ids[:index],skip_special_tokens=True).strip("\n")
content=tokenizer.decode(output_ids[index:],skip_special_tokens=True).strip("\n")
print("thinkingcontent:",thinking_content)
print("content:",content)
要禁用思考模式,只需对参数enable_thinking进行如下修改:
text=tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True,
enable_thinking=False#Trueisthedefaultvalueforenable_thinking.
)
**vLLM部署,**使用vllm>=0.8.4来创建一个与OpenAIAPI兼容的APIendpoint:
vllmserveQwen/Qwen3-30B-A3B--enable-reasoning--reasoning-parserdeepseek_r1
如果用于本地开发,通过运行简单的命令ollamarunqwen3:30b-a3b来使用ollama与模型进行交互。
最后的最后
感谢你们的阅读和喜欢,作为一位在一线互联网行业奋斗多年的老兵,我深知在这个瞬息万变的技术领域中,持续学习和进步的重要性。
为了帮助更多热爱技术、渴望成长的朋友,我特别整理了一份涵盖大模型领域的宝贵资料集。
这些资料不仅是我多年积累的心血结晶,也是我在行业一线实战经验的总结。
这些学习资料不仅深入浅出,而且非常实用,让大家系统而高效地掌握AI大模型的各个知识点。如果你愿意花时间沉下心来学习,相信它们一定能为你提供实质性的帮助。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

大模型知识脑图
为了成为更好的 AI大模型 开发者,这里为大家提供了总的路线图。它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。
经典书籍阅读
阅读AI大模型经典书籍可以帮助读者提高技术水平,开拓视野,掌握核心技术,提高解决问题的能力,同时也可以借鉴他人的经验。对于想要深入学习AI大模型开发的读者来说,阅读经典书籍是非常有必要的。

实战案例
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

面试资料
我们学习AI大模型必然是想找到高薪的工作,下面这些面试题都是总结当前最新、最热、最高频的面试题,并且每道题都有详细的答案,面试前刷完这套面试题资料,小小offer,不在话下

640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

ModelScope旨在打造下一代开源的模型即服务共享平台,为泛AI开发者提供灵活、易用、低成本的一站式模型服务产品,让模型应用更简单!
更多推荐



 23
23 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)