
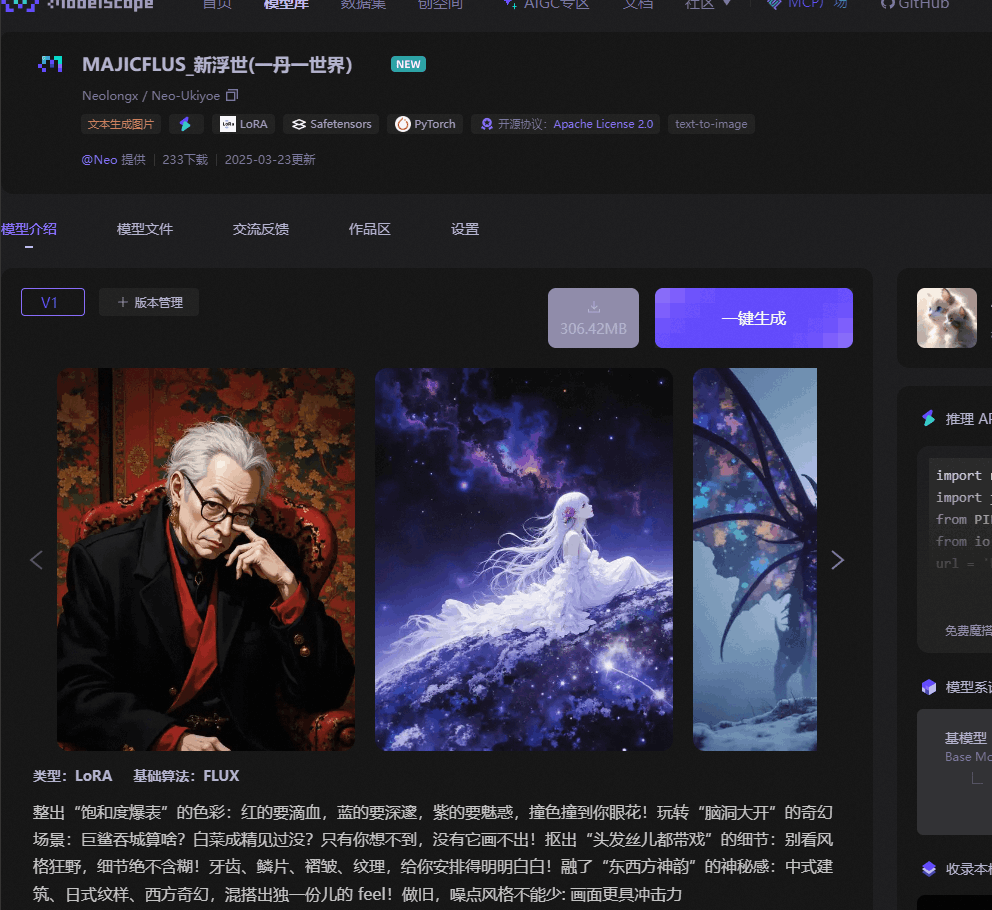
“一丹一世界”二等奖 | MAJICFLUS_新浮世 创作分享

我是Neo,一位热爱AICG的游戏美术。
自我介绍:
我本职工作是一名游戏行业从业者。接触AIGC至今已有三年,算是比较早一批Ai绘画玩家。在这个过程中,我从学习到实践,体会到了AIGC带给我的各种快乐,新技术更迭为工作带来了诸多加持。通过这几年AIGC的学习与沉淀,也有了不错的收获。
我喜欢的是ComfyUI各种有趣工作流的搭建,以及风格Lora的训练。
我平时的自媒体主要展示的是穿搭类的写实图片,各种画风的糅合,偶尔也出一些奇奇怪怪的风格。
从SD1.5到XL再到FLUX,我训练过许多Lora模型。对我而言,独特的Lora模型也是一种展现个人创作意图的方式。
首先,很荣幸这次我的模型“新浮世绘”获得了魔搭平台一丹一世界风格Lora大赛的二等奖。感谢平台邀请我来做这次的训练经验的分享。
前提声明:
以下内容仅为个人经验,仅供参考,下列分享只针对Flux的Lora模型。
Flux时代炼丹门槛的降低:
我是从1.5时代开始训练模型的,相比1.5和XL,Flux的训练几乎没有技术上面的难度,AI绘画自从进入Flux时代,炼丹的门槛实际上已经大幅降低。因为Flux的高泛化性,其对参数的敏感度相对较低,素材的重要性更为突出。
创作思路(以“新浮世绘”Lora为例):
以我这次比赛的Lora为例,我最初的想法是训练一个具有强烈笔触和丰富细节的模型。我在Midjourney上搜索了大量图片,但并没有找到我特别喜欢的风格。后来我参考了一些加藤彩老师的画作,进行反向推导和风格参考(sref)后才得到了初稿。然而,我对初稿的细节并不满意,因此在我的Flux模型下进行了重绘,增加了更多细节并修复了错误,最终得到了满意的训练素材。
我们训练一个画风Lora的目的是因为对这个画风的喜爱,并且它具有独特性,是对自己审美的一种体现。素材的来源可以是平时的积累、实体图片的扫描,Midjourney的素材也是非常不错的选择,特别是MJ V7的质感,这是Flux原生模型难以比拟的。通过个人后期处理和种子的巧妙组合,往往可以产生非常强烈且独特的风格。我建议大家多多尝试。收集素材时可以参考他人的作品,但务必尊重每一个作品,并融入自己的风格,避免一味地抄袭和临摹,那样就失去了训练的价值。
收集素材:
在我们收集训练素材时,需要注意以下几点:
素材的风格:
训练模型时,素材的风格必须统一,要具有肉眼可见的相似性。例如,如果训练水墨风格的模型,所有素材都应包含水墨风格的元素,不能混入素描等其他风格的图片。
素材的来源:
素材可以来源于平时的积累、实体图片的扫描,以及Midjourney等AI绘画工具的生成。
素材的范围:
素材的种类越多越好。这样模型在生成图像时,能在保证风格统一的前提下,衍生出更多样化的结果。我们可以简单地将素材分类为生物和场景。进一步细化,生物可以分为男人、女人、儿童、动物等;场景可以分为室内和室外。更深一步的细化可以考虑构图、镜头等元素,并依此类推。在这个前提下,如果你的模型主要用于生成角色,那么以角色为主体的素材应占多数;如果主要用于生成场景,则素材应以场景为主。

素材的打标:
对于Flux风格Lora的素材打标,我采用自然语言标签,可以遵循以下规律:触发词 + 画面风格 + 主体(包括服装姿势等)+ 背景 + 主要氛围(这里的描述不宜过多,简单概括即可,例如光线、特效等)。标签不宜过于复杂,单张图片的标签尽量不要超过225个token。过多的标签在生成图像时可能会带来不便,而过少的标签可能无法提供足够的信息。我推荐大家使用Gemini 2或GPT-4o等API,将上述规则告知它们,它们可以自动完成标签的生成,效果相当不错,这样可以大大减少手动修改的工作量。

素材的数量:
针对风格Lora,一般来说,Flux Lora微调模型学习一个全新的概念,30张素材已经足够。但考虑到素材的多样性以提高泛化能力,我建议总素材数量在50-70张左右比较合适,不宜过多,尤其要避免包含过多重复元素的素材!
素材的迭代:
训练出来的效果可能不是让你特别满意的时候,甚至我们可以用训练出来的模型补充一些素材,或者用训练出来的模型重绘一下先有的素材,加强风格,这样迭代的出来模型,会更加优秀。
参数的设置(以魔搭训练器为例):
一般来说,Flux对参数的敏感度不如XL。以下是我个人在Flux上训练画风类Lora的一些关键参数经验(以魔搭训练器为例):
|
步数 (Repeat) |
建议设置为8-12步 |
|
训练轮数 (Epochs) |
建议设置为10-15次 |
|
图像分辨率 |
建议设置为768-1024,并开启分桶功能(开启分桶后可以自适应素材的尺寸)。 |
|
学习率 (Learning Rate) |
学习率就像模型在学习时“迈出的步子”的大小。如果步子太大(学习率过高),模型可能会在最优解附近跳来跳去,难以收敛,导致训练不稳定或者效果不佳。如果步子太小(学习率过低),模型学习的速度会非常慢,可能需要很长时间才能达到理想的效果,甚至可能陷入局部最优解。在Flux风格Lora训练中的应用: 对于画风类的Lora,我们通常希望模型学习到风格的细腻特征,因此学习率一般会设置得相对较低(例如你提到的 0.0002-0.00035)。对于全新的概念或者需要更大幅度调整的场景(例如人物或特定产品),则需要更高的学习率(例如 0.0005 以上)以便模型更快地捕捉到主要特征。 |
|
Dim值 (Dimension) |
Dim 值可以看作是 Lora 模型用来存储“知识”的容量大小。更高的 Dim 值就像一个更大的笔记本,可以记录更多关于要学习的风格或对象的细节和复杂性。如果你的目标风格非常细腻、包含很多复杂的纹理或笔触,可以尝试更高的 Dim 值(例如 32 或 64)。对于一些相对简单的风格或者只需要学习主体的大致特征,较低的 Dim 值可能就足够了(例如 8 或 16)。你需要根据实际效果和模型大小进行权衡。 |
|
Alpha值: |
Alpha 值就像是控制 Lora 模型对原始模型影响程度的“开关”。它可以调整 Lora 模型学习到的风格特征在最终生成图像时所占的比重。当 Alpha 值等于 Dim 值时 (Alpha/Rank = 1),Lora 模型学习到的特征会以其原始的强度与原始模型结合。当 Alpha 值小于 Dim 值时 (Alpha/Rank < 1),Lora 模型的影响会相对减弱,可能需要更高的学习率来补偿。较高的 Alpha 值通常能带来更强的风格迁移效果,但也可能更容易出现与原始风格不一致的情况。你需要根据你希望 Lora 模型对生成结果产生多大的影响来调整 Alpha 值。通常建议 Alpha 值设置为 Dim 值的一半或等于 Dim 值,作为起始的尝试。 |
|
优化器 (Optimizer): |
简单理解: 优化器是模型“如何迈出学习步伐”的具体方法。它负责根据损失函数计算出的梯度来更新模型的权重。不同的优化器有不同的更新策略,就像不同的运动员有不同的跑步方式。通常我们在魔搭使用的AdamW,。他对初始学习率的选择不那么敏感,并且其集成的权重衰减有助于防止过拟合,这对于训练风格Lora也是有益的。 |
|
关于 Loss 值 |
请不要过分依赖Loss值。由于不同概念的复杂程度各异,在Flux模型中,Loss值所体现的参考价值相对有限。最终的评判标准仍然是生成图像的实际效果。 |
总结:
实践是最好的老师,你可以尝试不同的参数组合和策略,观察它们对训练结果的影响,从而积累更丰富的经验。这个模型我在魔搭通过不同参数的调试,至少训练了3次,才达到想要的效果。
再次感谢魔搭团队和麦橘社群的认可。以上是我个人的经验分享,如有不足之处,敬请指

ModelScope旨在打造下一代开源的模型即服务共享平台,为泛AI开发者提供灵活、易用、低成本的一站式模型服务产品,让模型应用更简单!
更多推荐



 0
0 0
0- 0



 已为社区贡献653条内容
已为社区贡献653条内容

所有评论(0)