
【DeepSeek微调】Windows下_全链路部署-安装-并微调DeepSeek大模型:看这一篇就够了~
多数企业的大模型初步应用场景为:知识库、智能客服等。该部分场景主要使用和技术。两者在使用中,又经常。笔者现将学习相关技术过程遇到的信息整理成文。相应的使用流程如下:底模选择 => Lora微调 => Rag增加 => 业务使用接下来,将通过Windows环境,实验整个流程。说明:该文章依据上述两个github开源工程实践,有能力者可直接按照github的教程操作。
前言
多数企业的大模型初步应用场景为:知识库、智能客服等。该部分场景主要使用模型增强和模型微调技术。两者在使用中,又经常结合使用。笔者现将学习相关技术过程遇到的信息整理成文。
| 技术 | 说明 | 工程化 | 地址 | 场景 |
|---|---|---|---|---|
| 模型增强 | RAG | RagFlow | https://github.com/infiniflow/ragflow | 知识库、智能客服 |
| 模型微调 | Lora | LLaMA-Factory | https://github.com/hiyouga/LLaMA-Factory/ | 垂直领域迁移 |
相应的使用流程如下:
底模选择 => Lora微调 => Rag增加 => 业务使用
接下来,将通过Windows环境,实验整个流程。
说明:该文章依据上述两个github开源工程实践,有能力者可直接按照github的教程操作。
一、步骤说明
- 环境准备
1.1 Conda环境准备
1.2 Torch、CUDA、LLaMA-Factory部署 - Lora微调与模型输出
2.1 模型、数据集下载 - Rag强化
- API调用
注:对电脑配置有一定要求,高于本机配置,理论可流畅执行下属步骤,低于本机配置,不保证正确运行。配置信息如下:
GPU:3060 12G
CPU:AMD R-7500F
内存:32G DDR5
硬盘:2T SSD(NVMe)
操作系统:Windows 11 专业版 24H2
二、环境准备
2.1 Conda环境准备
参考该文章:Windows安装Conda
2.2 Torch、CUDA、LLaMA-Factory环境准备
2.2.1 Conda创建llama_factory环境:
conda create -n llama_factory python=3.10
conda activate llama_factory
2.2.2 下载安装LLaMA-Factory
选择目录,并Git clone代码:
git clone https://github.com/hiyouga/LLaMA-Factory.git
git安装比较简单,不再赘述。git下载
cd LLaMA-Factory
pip install -e '.[torch,metrics]' # 安装依赖库、安装评估库、安装LLaMA-Factory
2.2.3 安装CUDA torch
一般情况下,此时会安装cpu版的cuda,这与我们的期望的gpu不符。
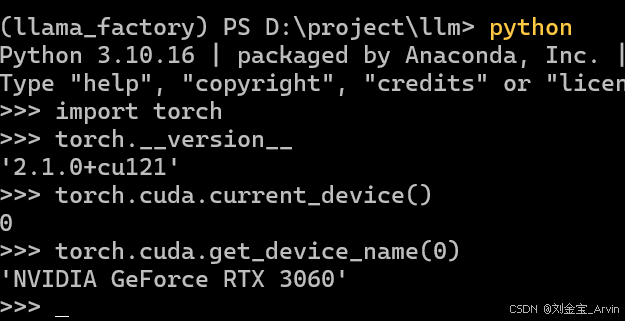
请通过以下脚本进行验证:
>>> import torch
>>> torch.__version__
'2.1.0+cu121'
>>> torch.cuda.current_device()
0
>>> torch.cuda.get_device_name(0)
'NVIDIA GeForce RTX 3060'
如果不满足,请先卸载torch。pip uninstall torch
并请参考文章,进行cuda的安装Windows安装CUDA
核心两个步骤:
- 进入该链接下载版本对应的gpu torch即可(torch whl下载)
- 进入下载地址,进入llama_factory环境,安装whl包
pip install torch-2.1.0+cu121-cp310-cp310-win_amd64.whl
注:该包为本人所用torch包,请根据上文替换为你自己的包
再次执行上文的脚本,验证CUDA torch正确安装。
验证llamafactory是否正确安装:
llamafactory-cli train -h
三、Lora微调与模型输出
3.1 模型下载
国内推荐魔塔社区(能访问外网的话可以huggingface),类似于模型界的gitee:魔塔社区
pip install modelscope # 安装
# 下载DeepSeek-R1基于千问的7B参数的蒸馏模型,并指定目录
modelscope download --model deepseek-ai/DeepSeek-R1-Distill-Qwen-7B --local_dir 'D:\project\llm\DeepSeek-R1-Distill-Qwen-7B'
注:这里也可以下载其他模型,在魔塔社区搜索即可。
3.2 下载训练和测试数据集:
数据集
并将数据集,解压到期望的目录,如我这里放到了LLaMA-Factory下:
3.3 Lora微调
此处训练一个新闻分类的模型。
3.3.1 webui,启动
如果你玩过Stable Diffusion,一定对Lora不陌生,也一定对秋叶大佬的webui不陌生,这里LLaMa-Factory也有一个webui。
在conda的llama_factory虚拟机环境中,并进入LLaMa-Factory目录。执行以下命令,会自动弹出webui,如下图
llamafactory-cli webui --USE_MODELSCOPE_HUB=1 # 设置魔塔社区,不过似乎不生效,问题不大,已经下载过模型了
界面类似下图: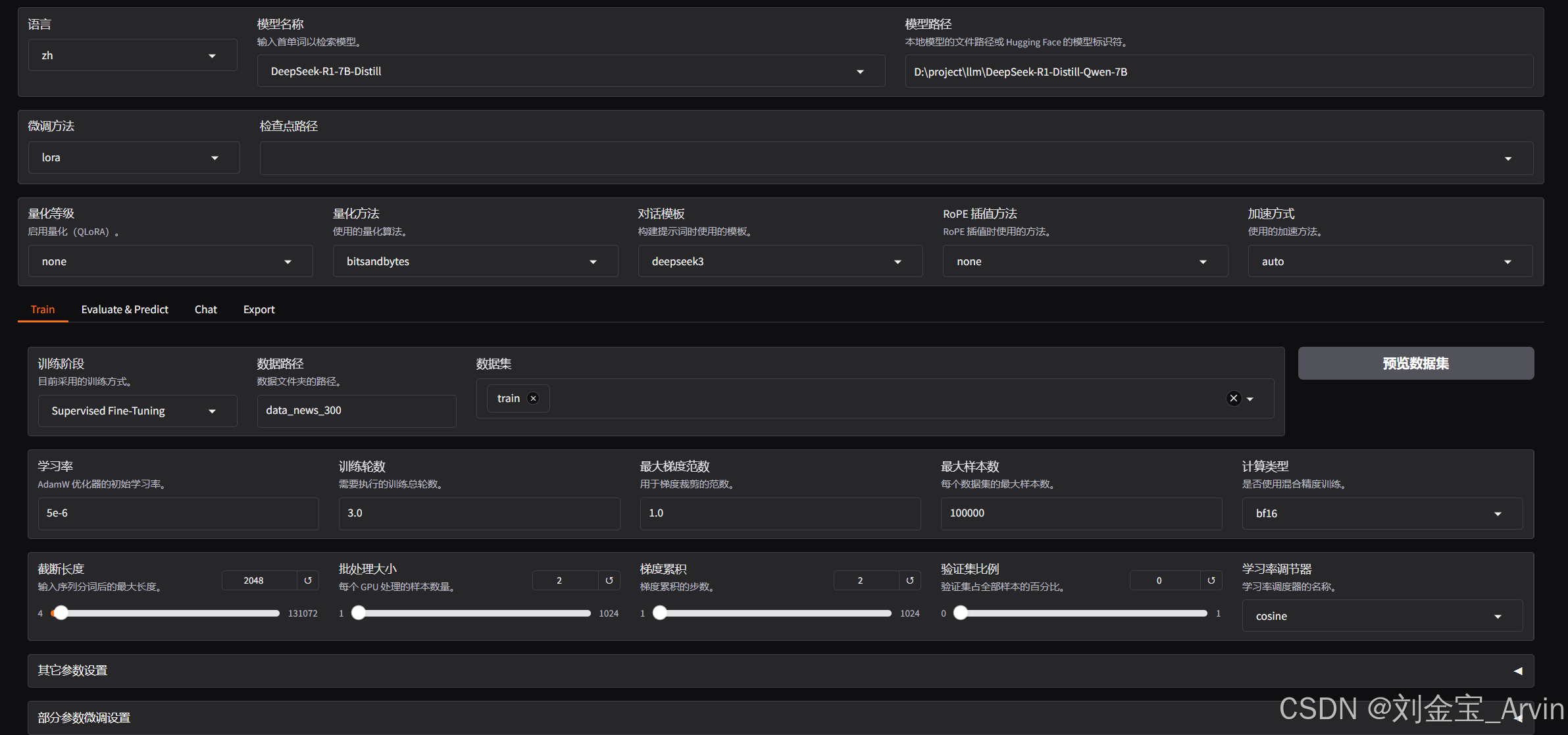
3.3.2 模型与数据集加载
如下图:
注:如果没有找到数据路径,大概率是没有进入LLaMa-Factory目录,建议进入目录重新启动。
数据集可以预览,如下图。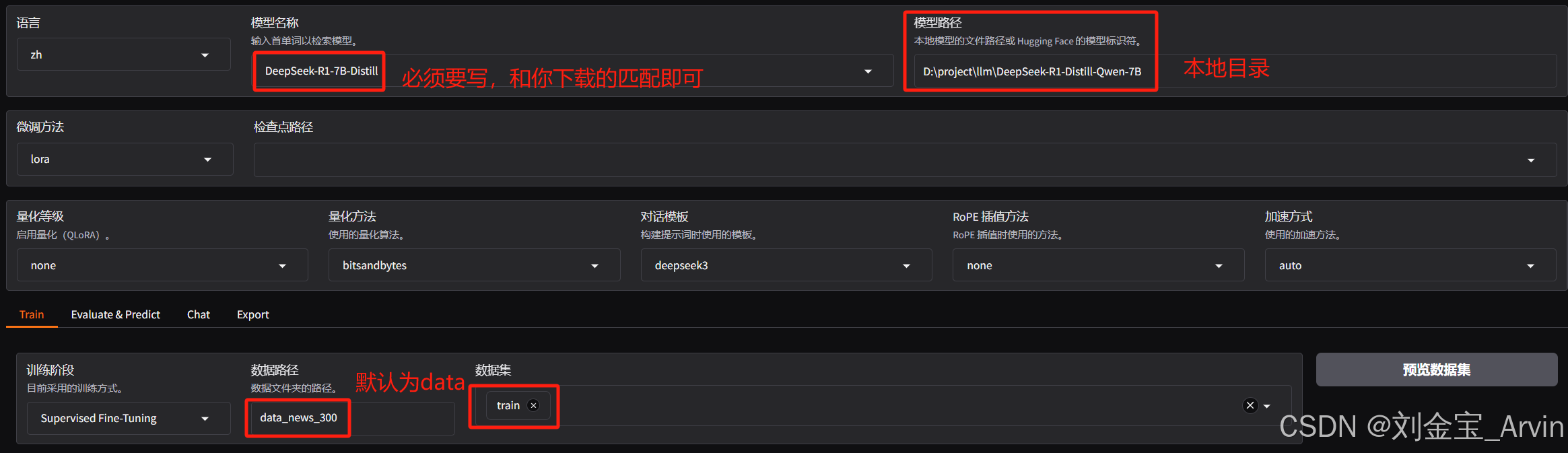
3.3.3 训练参数设置
如下图: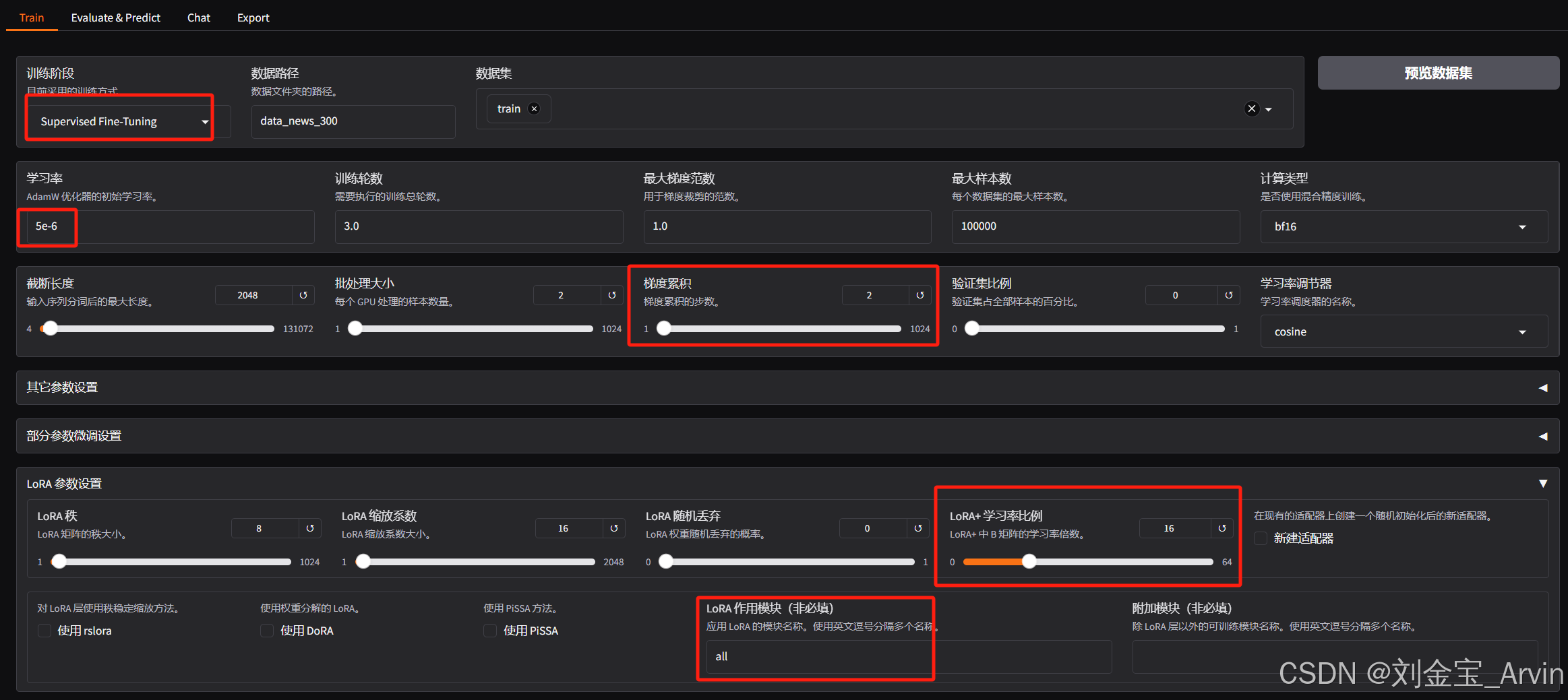
3.3.4 预览与训练
点击预览页面,可以看到真正提交的命令,确认无误后,开始执行即可。
可以看到训练的损失趋势图:
同步的,也可以在后台终端看到进度: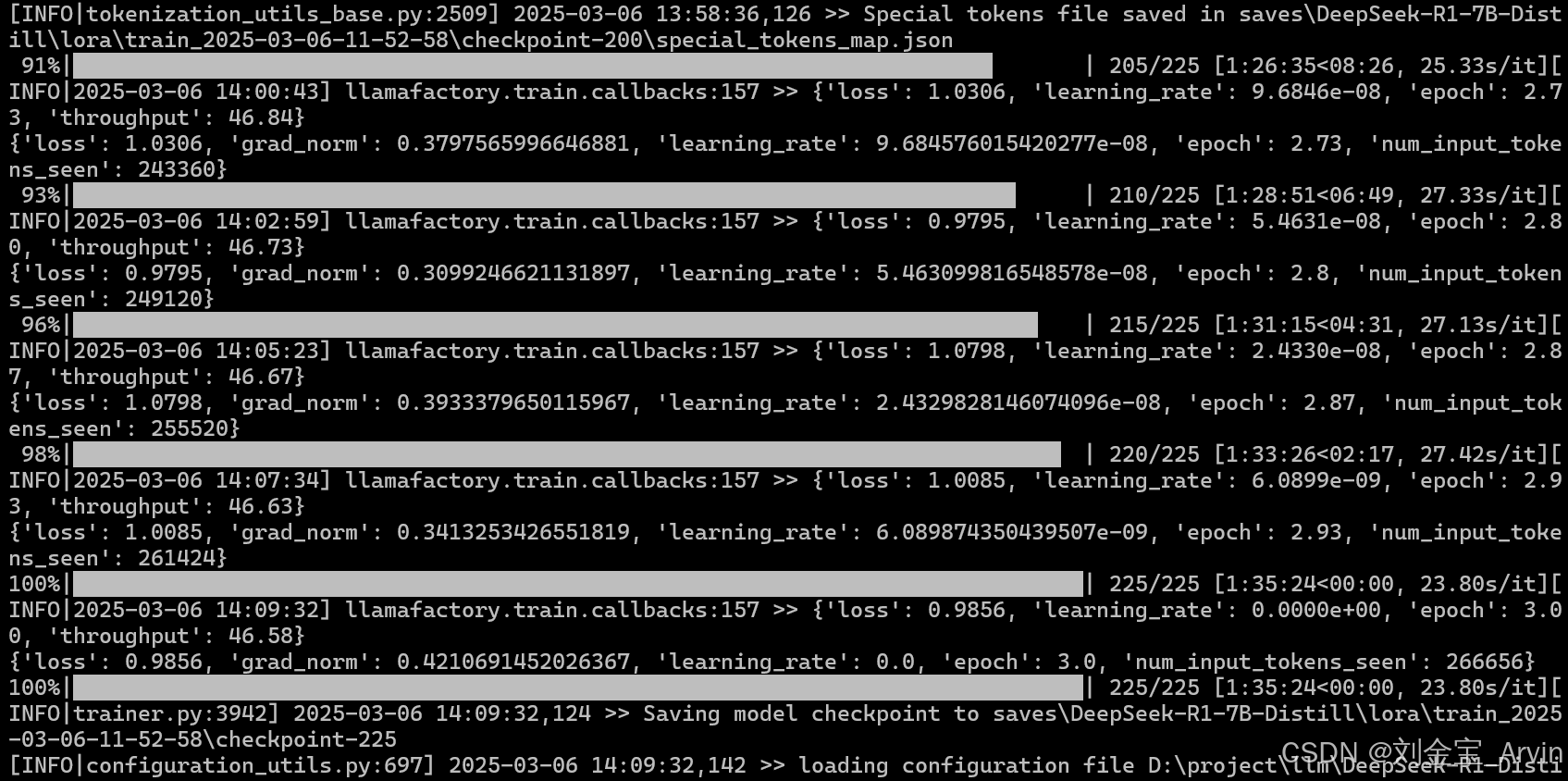
3.3.5 评估
与训练类似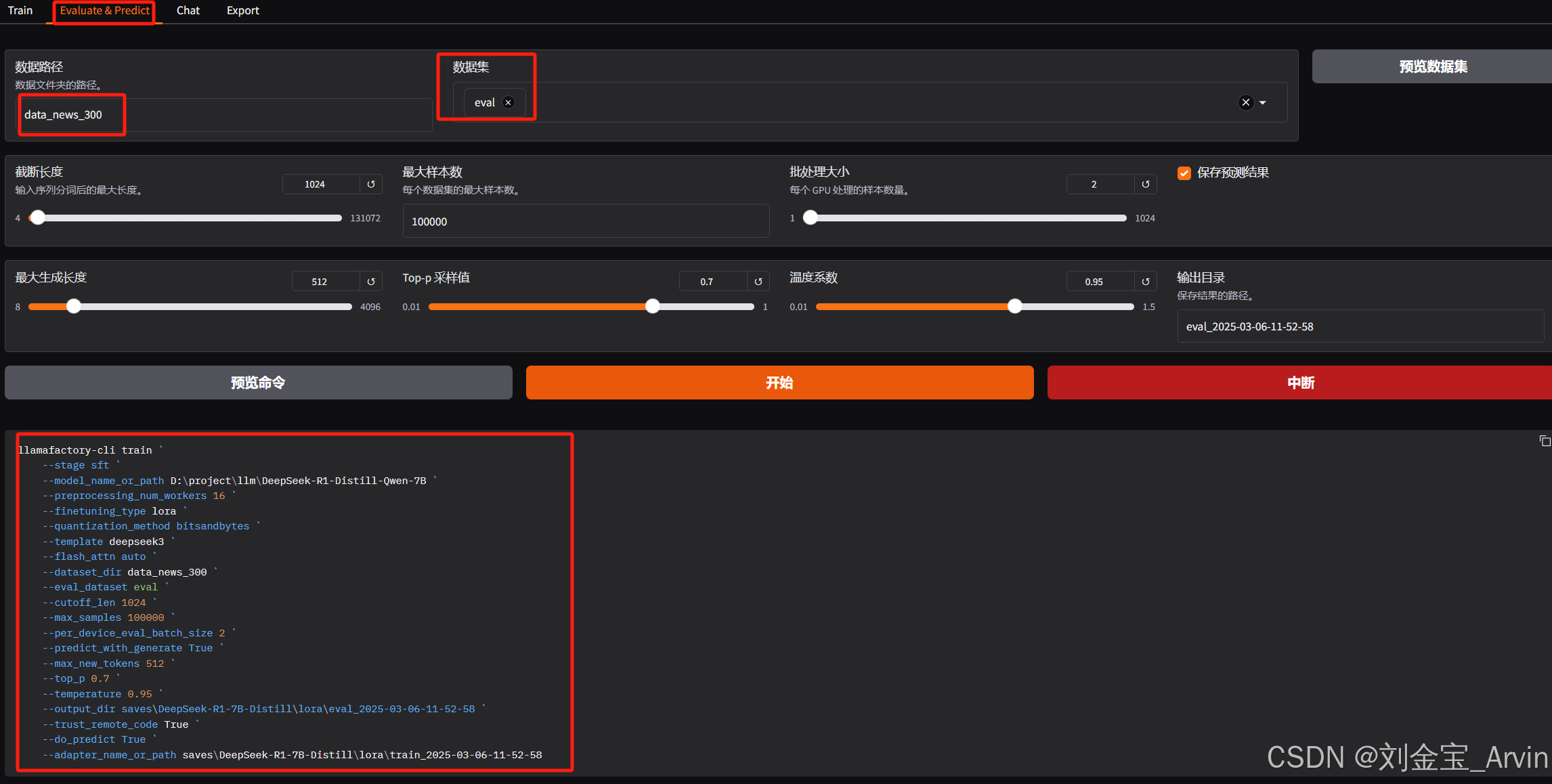
3.3.6 Chat
加载检查点,并提出问题:可以正常分类。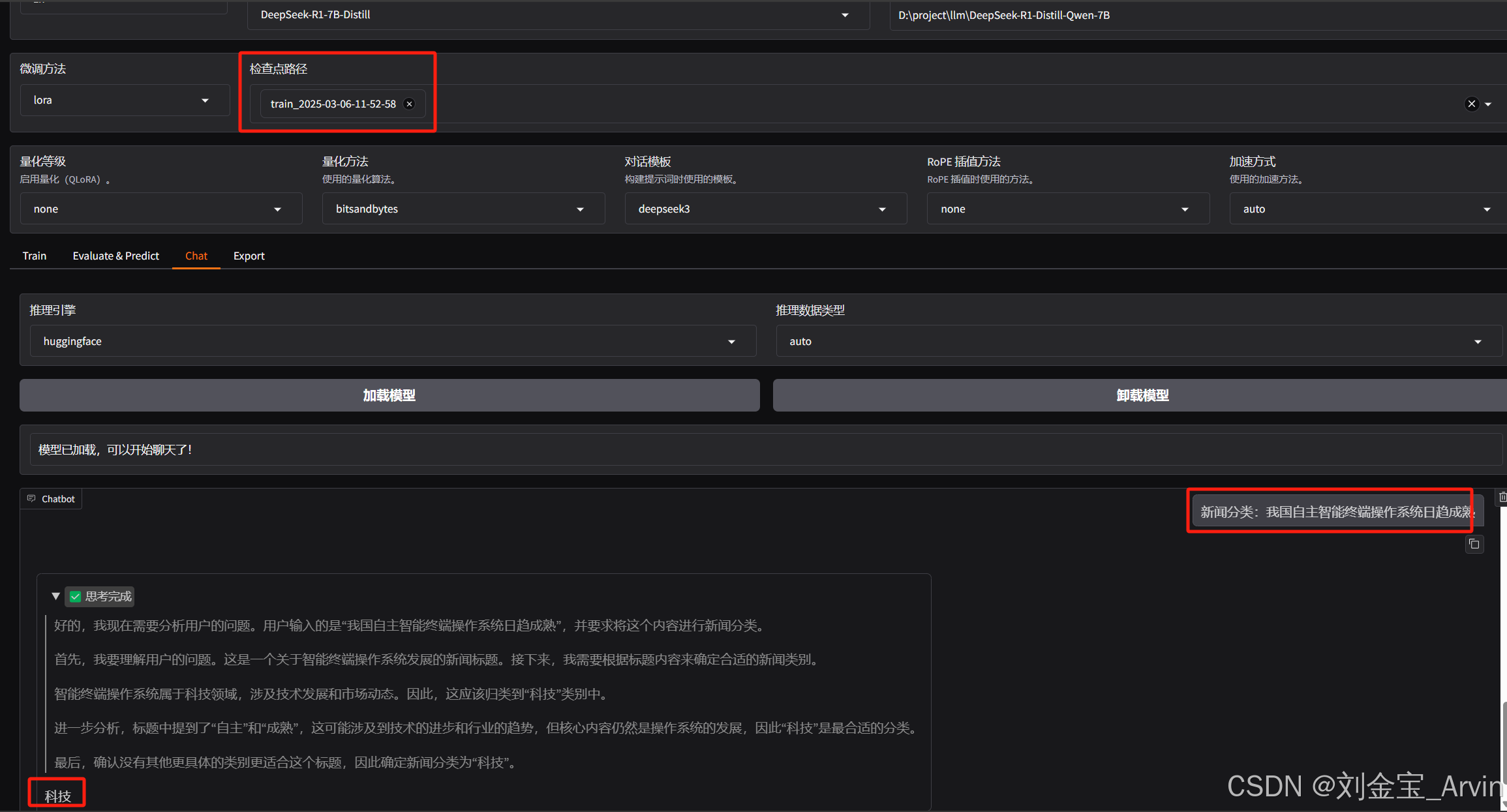
如果不加“新闻分类”,则仍然按照原有逻辑正常生成,未过拟合: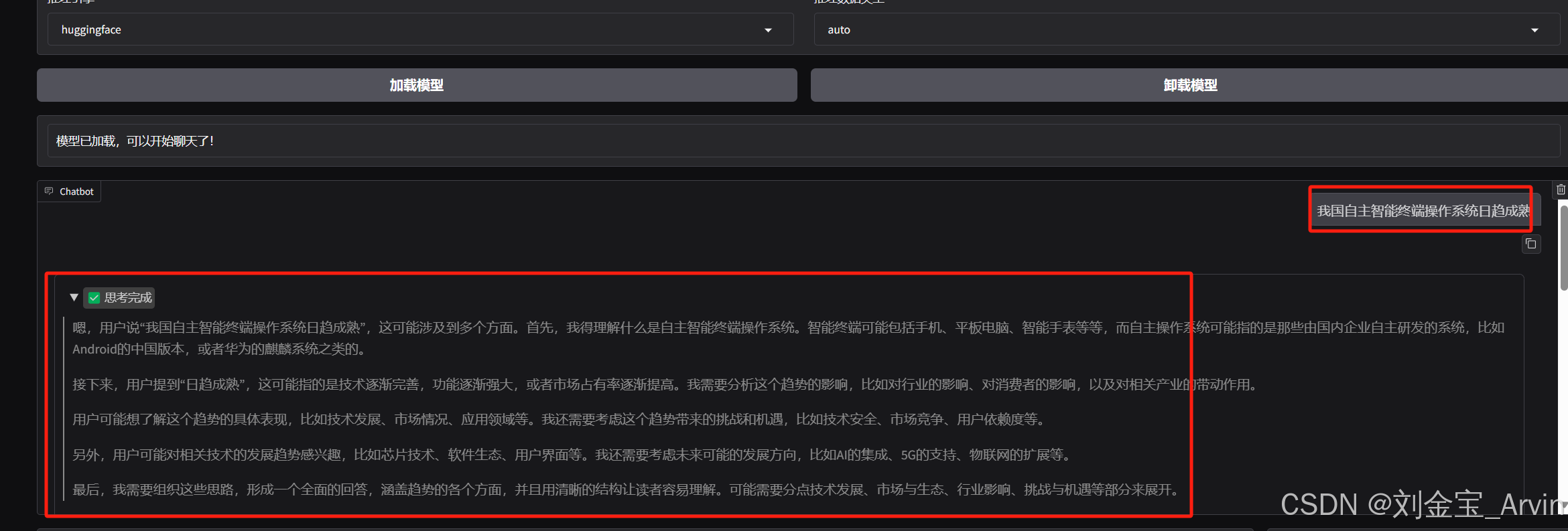
3.3.7 Lora合并
将自己训练的Lora与底模合并,生成一个新的大模型文件。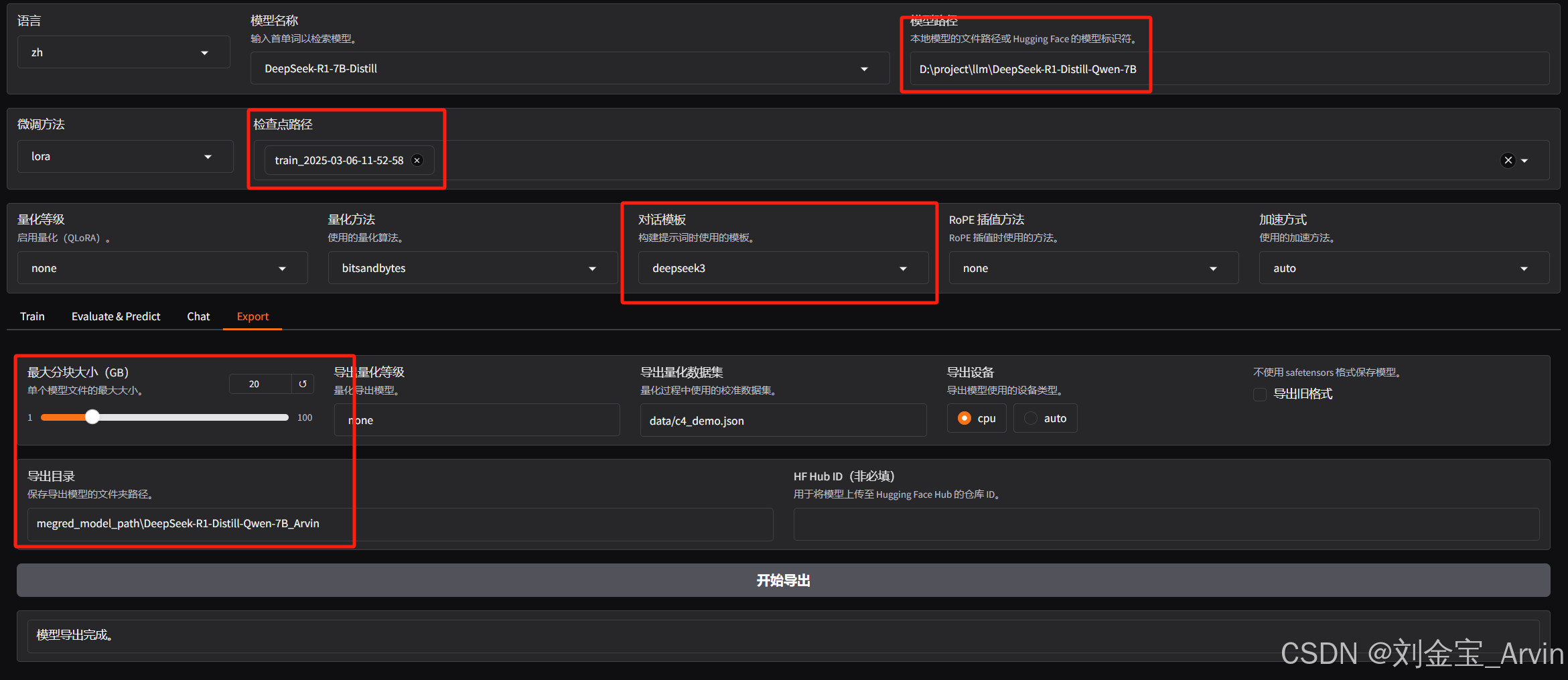
3.3.8 加载合并的模型
再次验证效果,满足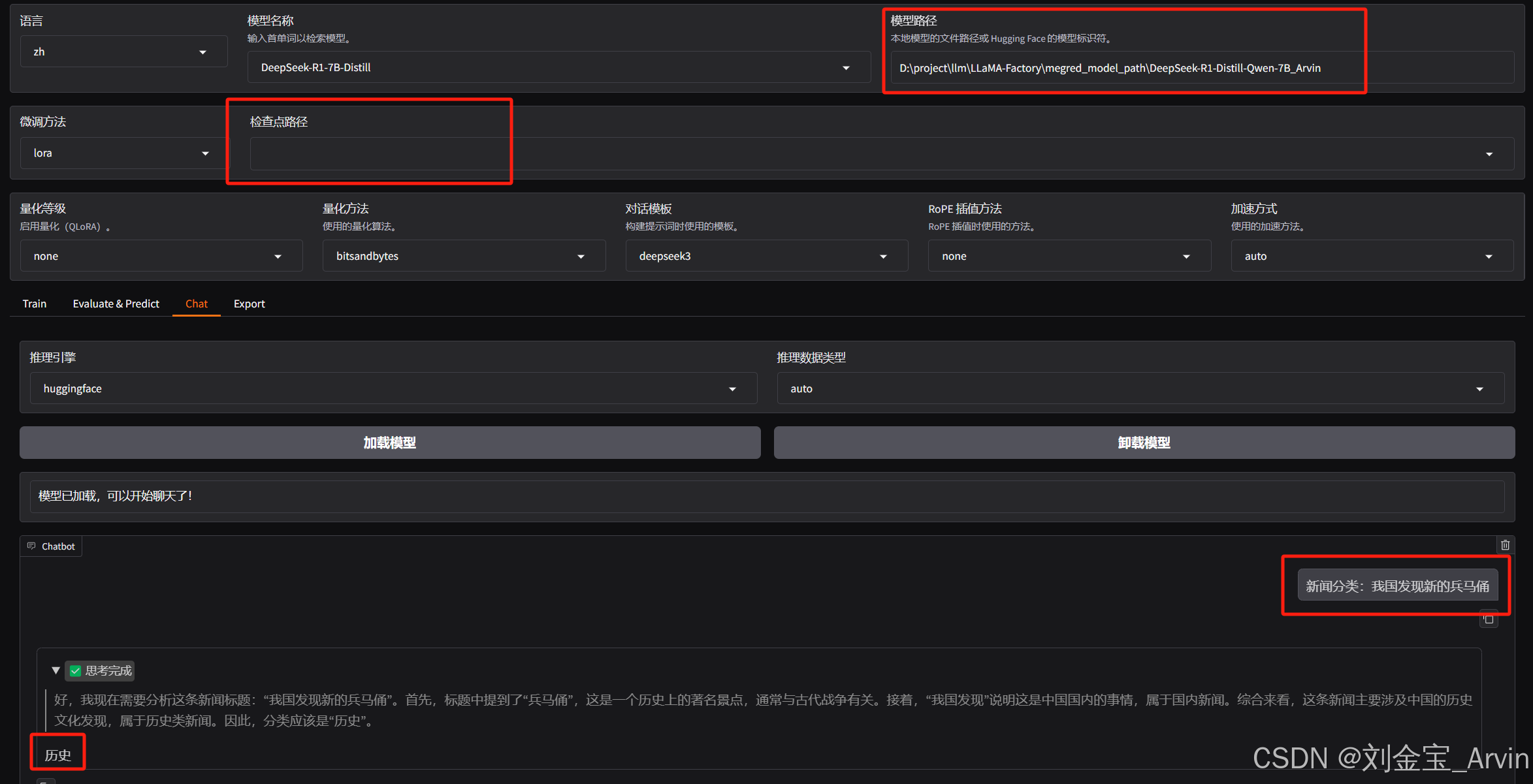
四、RAG部署
包含以下三个步骤:
- Ollama安装部署
- Docker部署RAGFlow
- RAG构建个人知识库
4.1 Ollama安装部署
下载安装即可:
ollama官网
环境变量配置:
OLLAMA_HOST 0.0.0.0:11434
OLLAMA_MODELS D:\OllamaModels
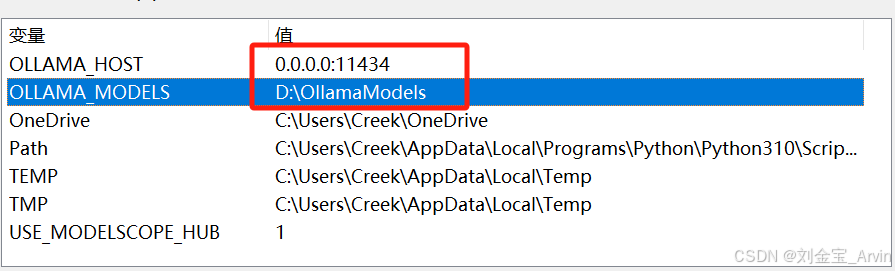
配置完成重启电脑。
终端输入ollama -v查看版本,并访问http://localhost:11434/:
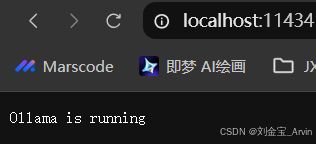
【可选】本地部署一个deepseek模型。下载deepseek模型,如下载1.5B的蒸馏模型(后续会基于上文Lora微调的模型进行演示)
ollama run deepseek-r1:1.5b
4.2 Docker部署RAGFlow
4.2.1 Docker安装
国内docker可用镜像(通过deepseek问出来的)
"registry-mirrors": [
"https://docker.m.daocloud.io",
"https://docker-0.unsee.tech",
"https://docker.1ms.run",
"https://func.ink"
]
参考该文章:Windows安装Docker
Docker用于ragflow运行过程中所依赖的组件:es、redis、minio、mysql等
4.2.2 安装ragflow
在自己规划的目录中,clone ragflow工程,比如我放在了llama-factory的同级目录下
git clone https://github.com/infiniflow/ragflow.git

修改ragflow配置,使其下载完整版本embedding模型:
修改.ragflow\docker\.env,将84行注释,并取消87行的注释,保存。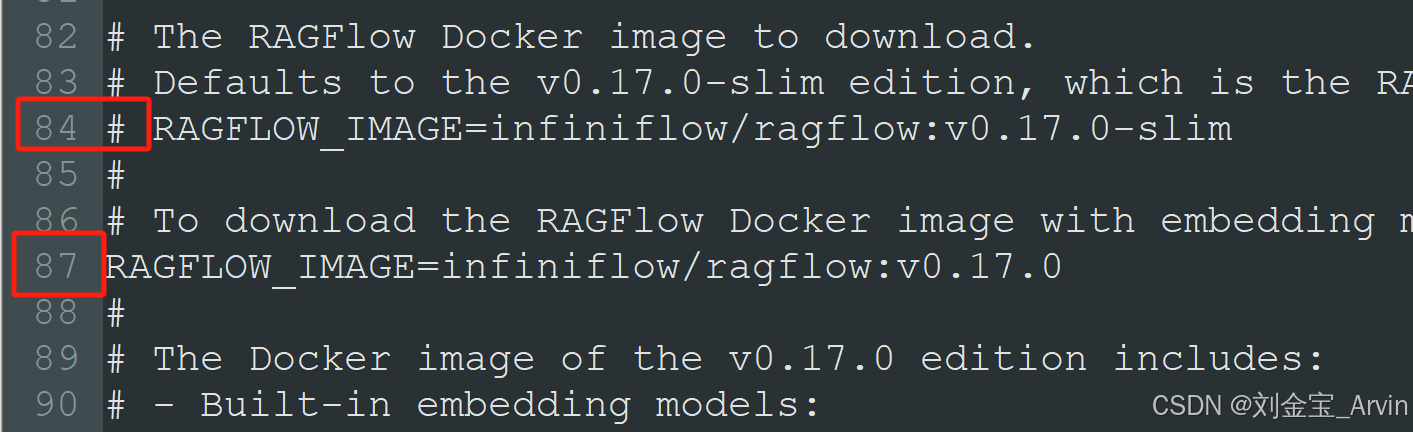
在该目录下,执行docker compose -f docker-compose.yml up -d,等待拉取镜像并启动完成即可(如果遇到端口冲突,多半重启下电脑就好了)。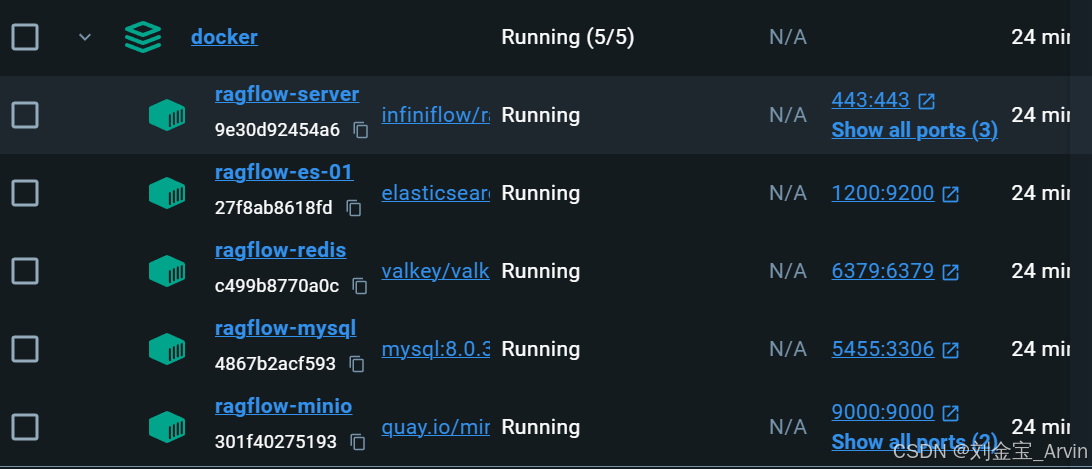
访问localhost:80,注册一个账户即可,页面如下: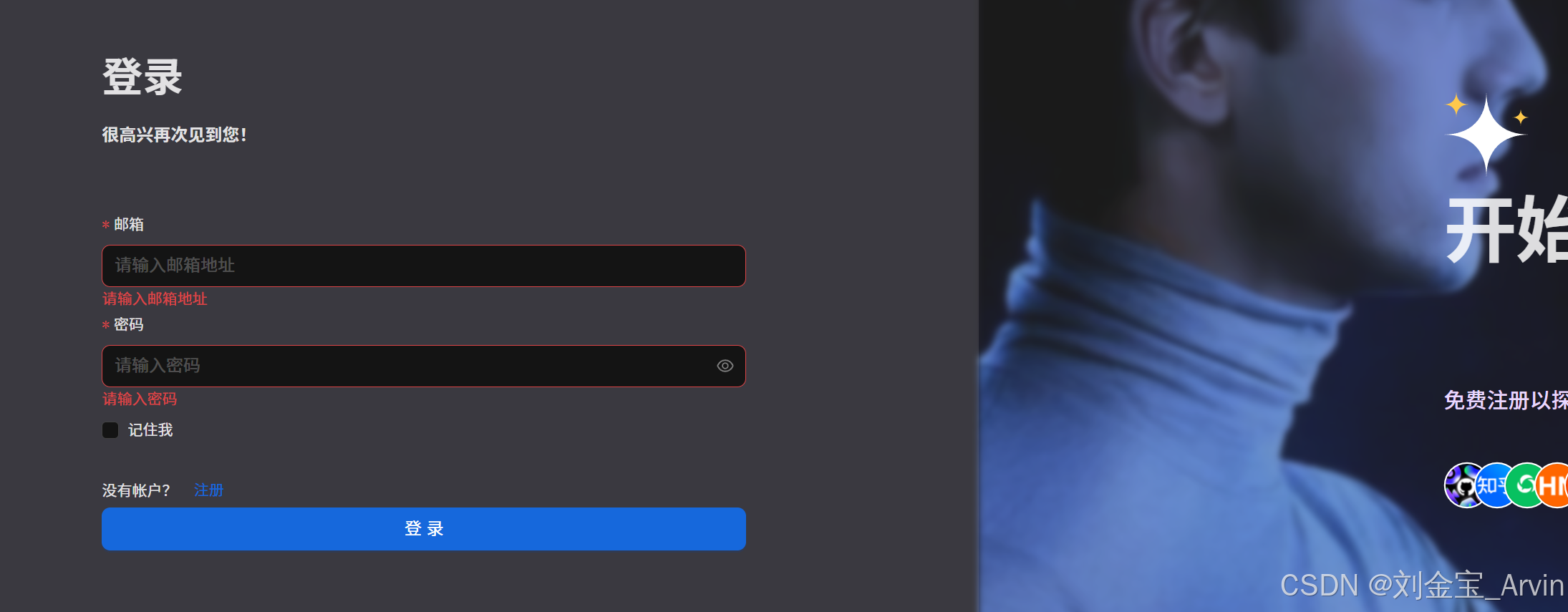
至此,部署成功。
4.3 构建个人知识库
4.3.1 将个人模型集成到ollama
微调后的模型为safetensor文件,新版本的ollama是可以集成的,但需要简单修改下:
4.3.1.1 创建启动文件
在指定目录创建一个文件DS_7B_Arvin(名字按照个人习惯写即可),并写入以下内容:
注意:
- from后面为自己的模型的相对路径
- 第二行及以后需要加上,不然模型虽然可以正确加载,但是会胡言乱语(具体原因未知)
FROM .\LLaMA-Factory\megred_model_path\DeepSeek-R1-Distill-Qwen-7B_Arvin
TEMPLATE """{{- if .System }}{{ .System }}{{ end }}
{{- range $i, $_ := .Messages }}
{{- $last := eq (len (slice $.Messages $i)) 1}}
{{- if eq .Role "user" }}<|User|>{{ .Content }}
{{- else if eq .Role "assistant" }}<|Assistant|>{{ .Content }}{{- if not $last }}<|end▁of▁sentence|>{{- end }}
{{- end }}
{{- if and $last (ne .Role "assistant") }}<|Assistant|>{{- end }}
{{- end }}"""
PARAMETER stop "<|begin▁of▁sentence|>"
PARAMETER stop "<|end▁of▁sentence|>"
PARAMETER stop "<|User|>"
PARAMETER stop "<|Assistant|>"
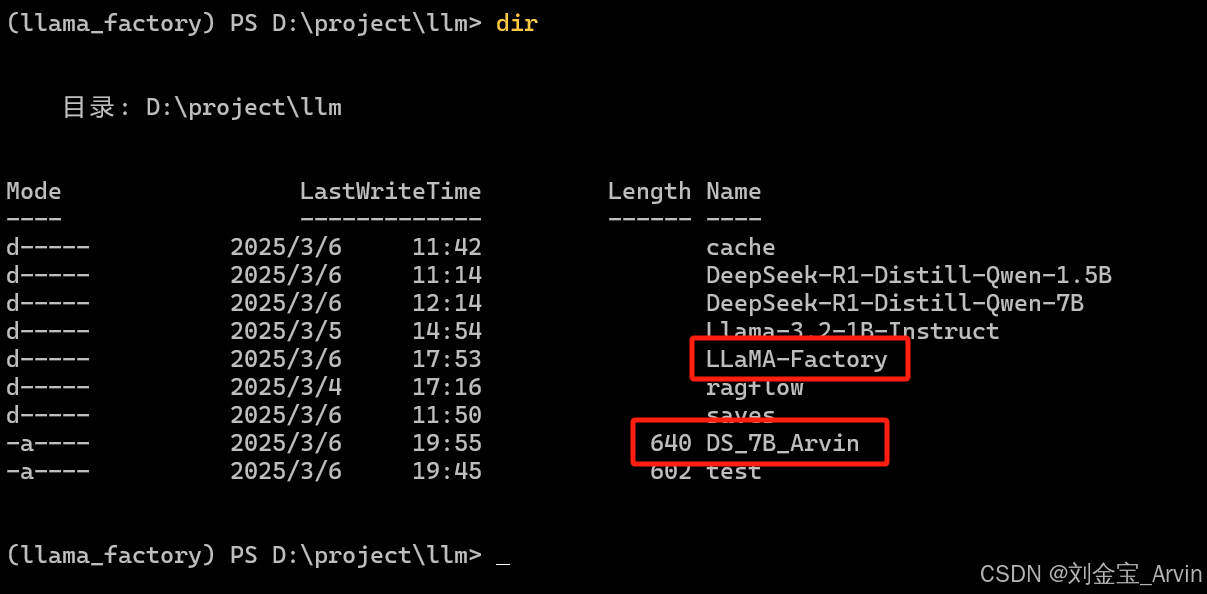
4.3.1.2 启动运行模型
加载模型,在指定目录加载启动文件,并等待:
ollama create mymodel -f .\DS_7B_Arvin
ollama list
ollama run mymodel
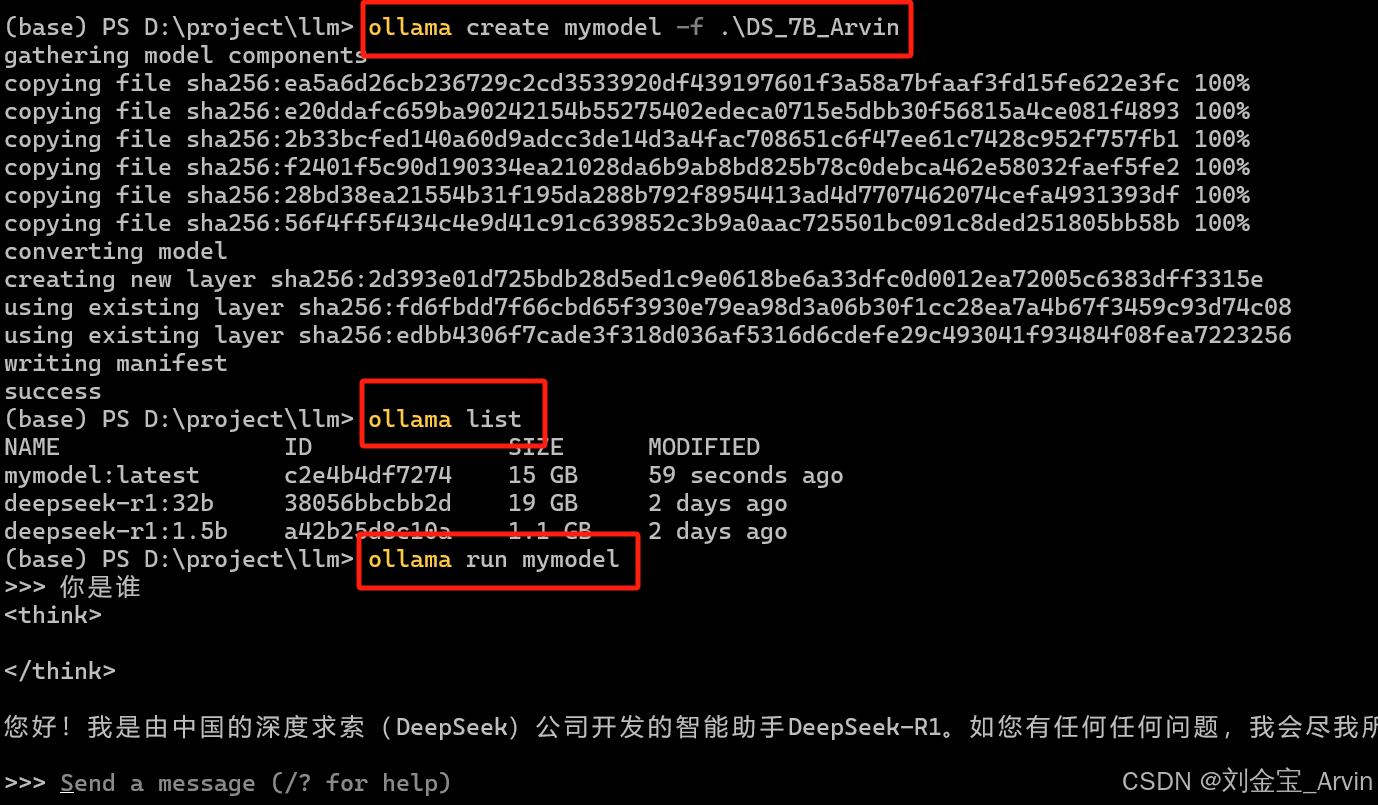
4.3.2 RAGFlow集成
4.3.2.1 模型添加
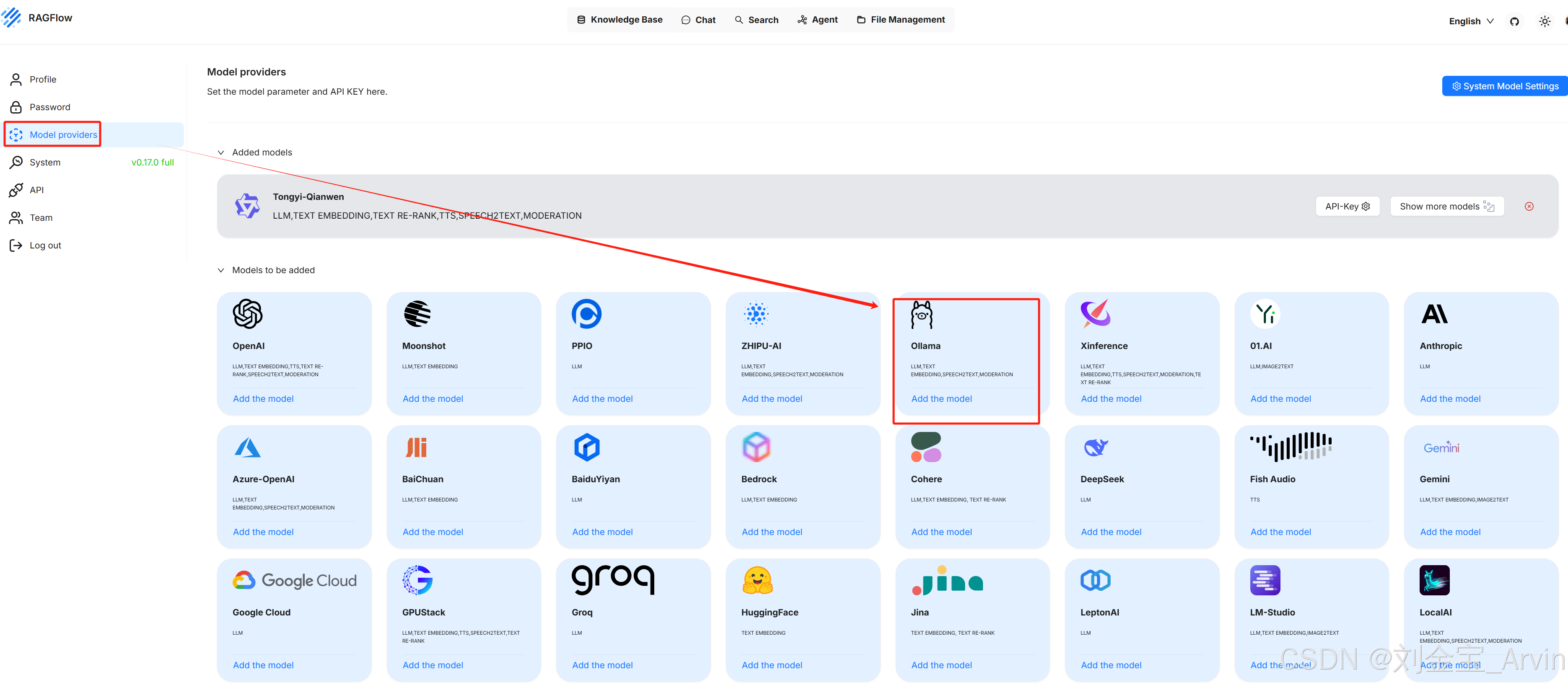
配置信息
- 模型名称为
ollama list输出的名字 - 基础url写死为:
http://host.docker.internal:11434 - chat模型
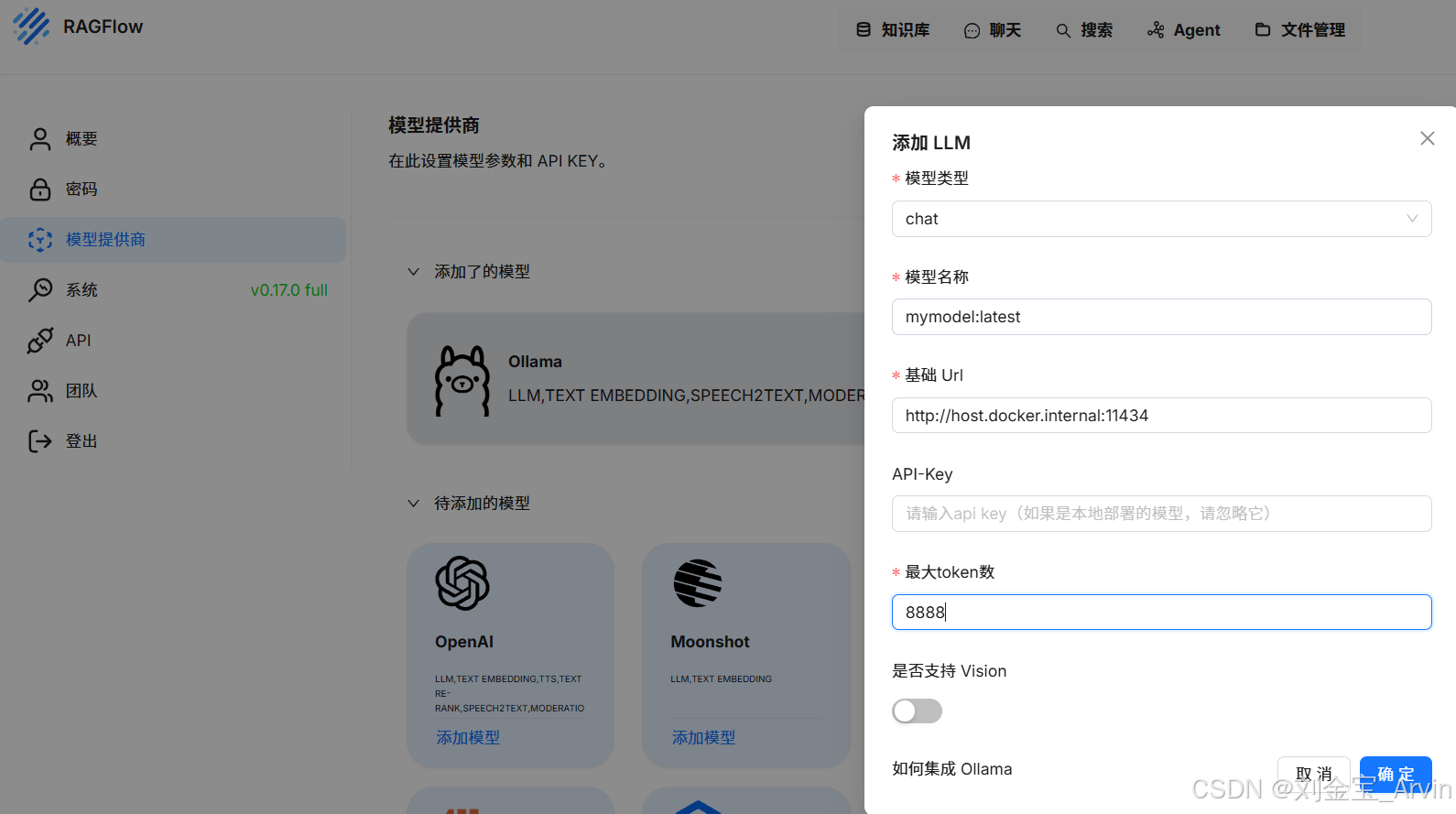
设置系统模型:
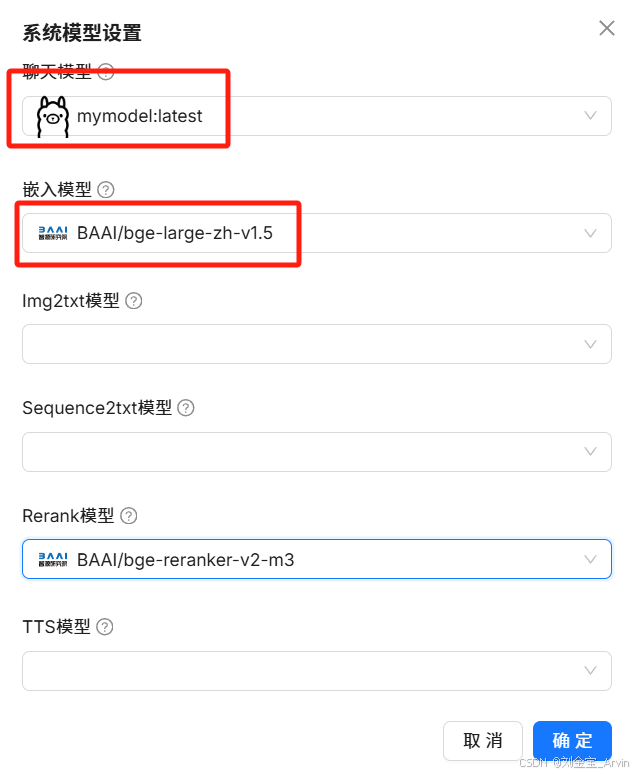
4.3.2.2 创建知识库
新建知识库: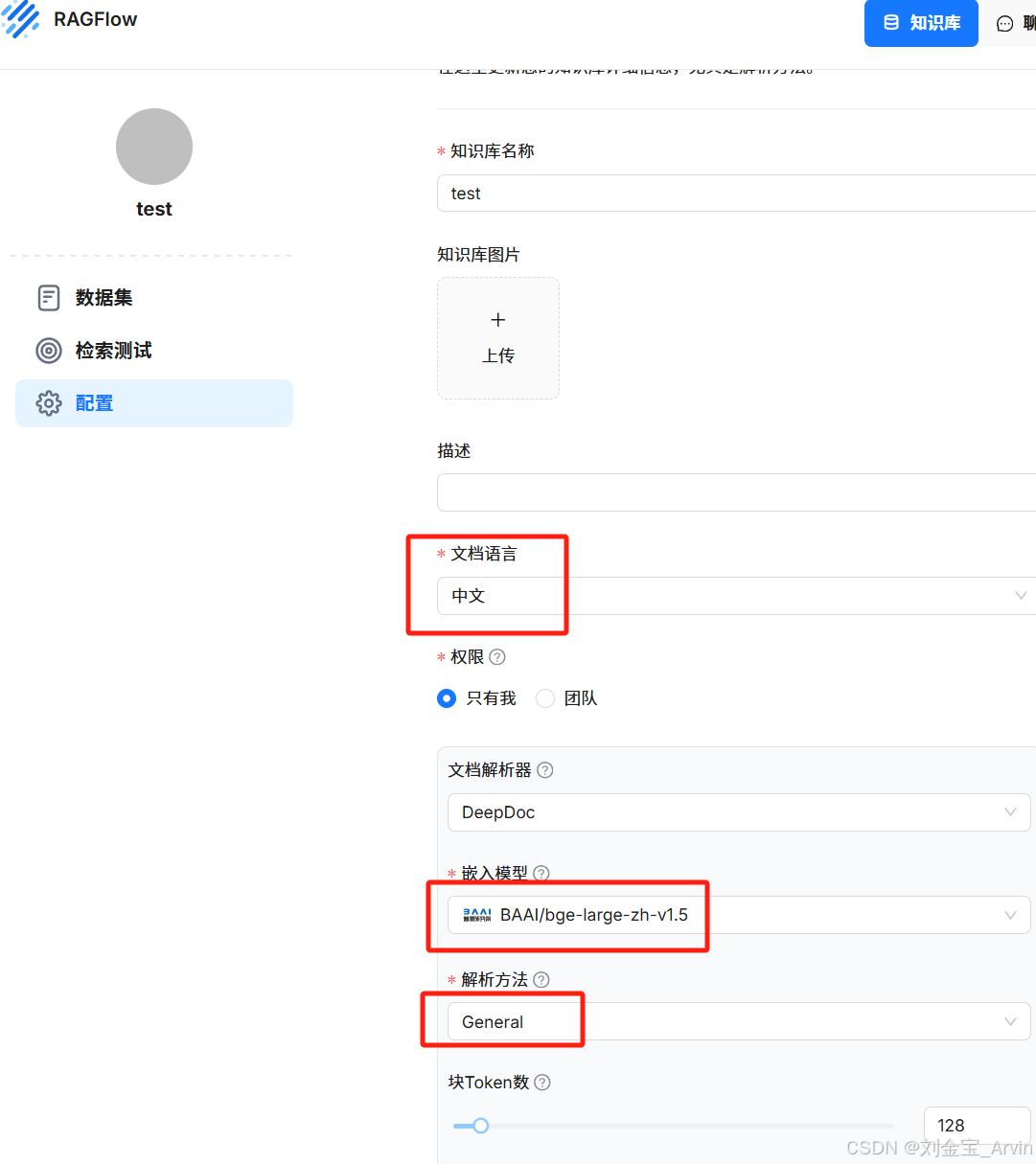
上传只是并解析: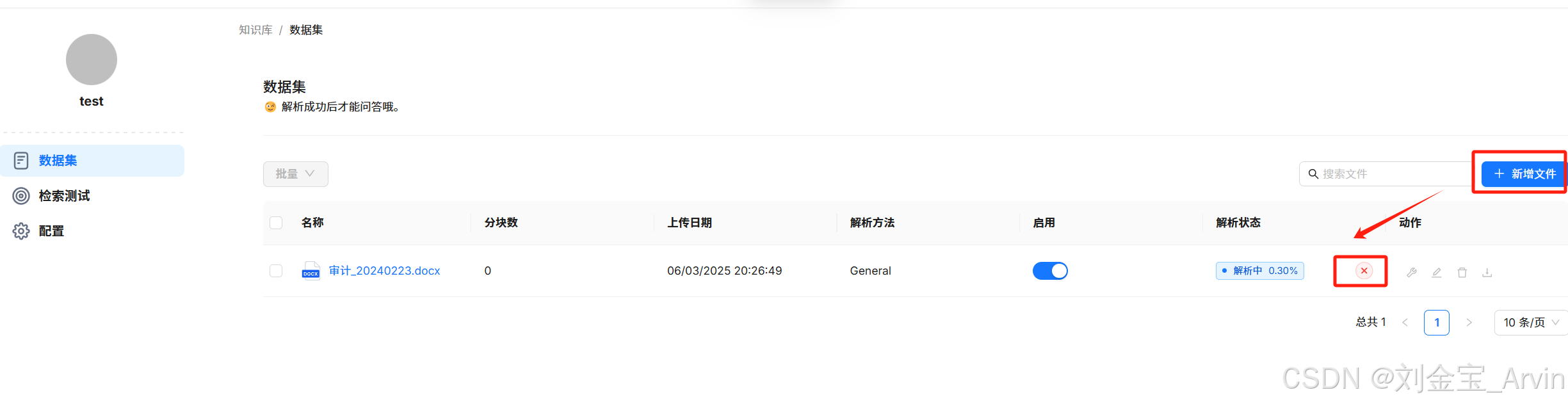
创建助理: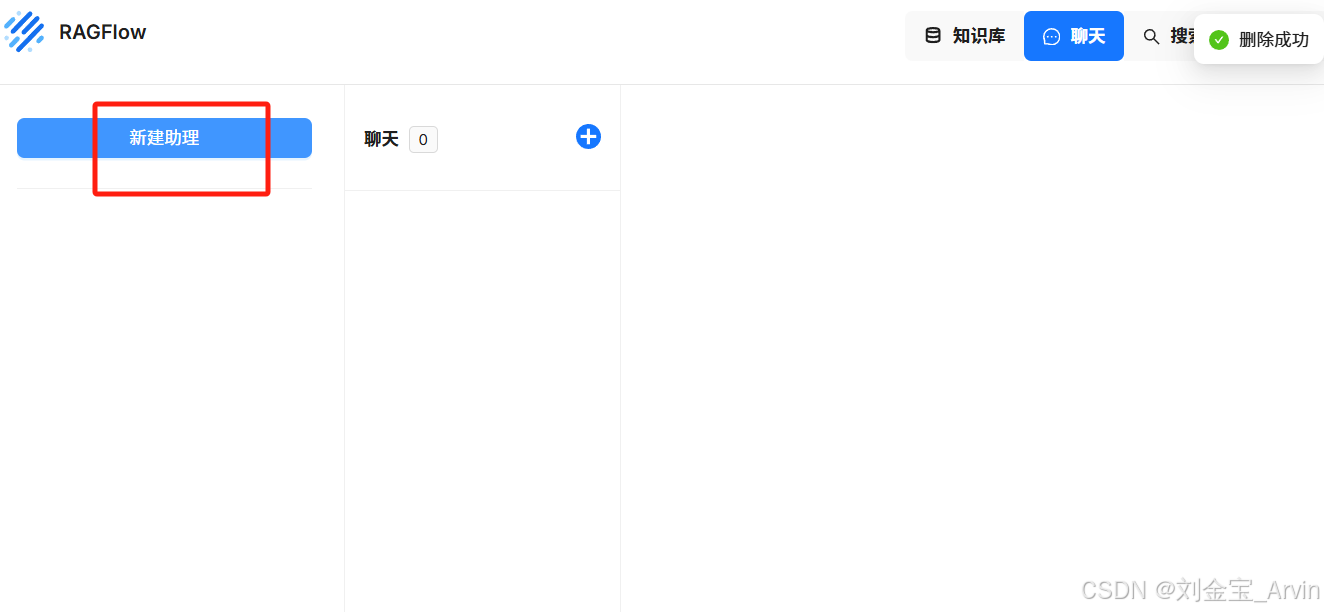
选择知识库: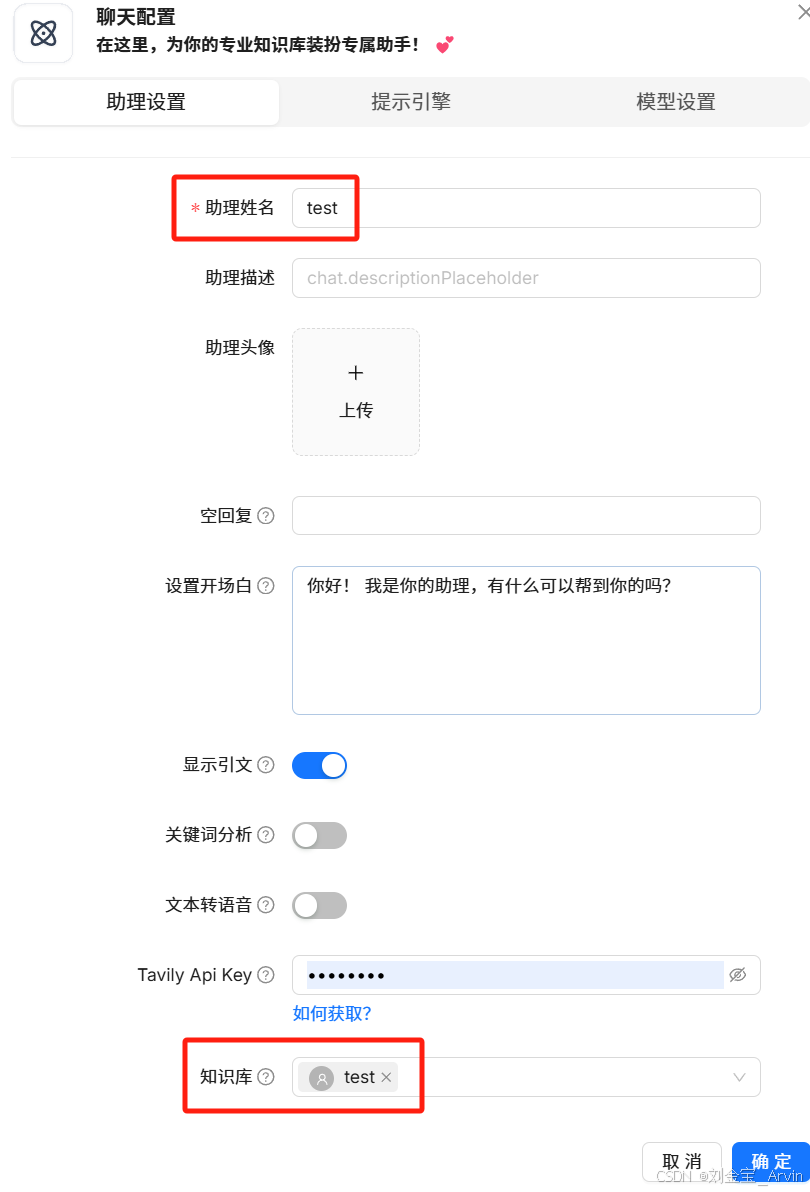
创建聊天,看下效果,同时满足知识库&Lora的训练效果。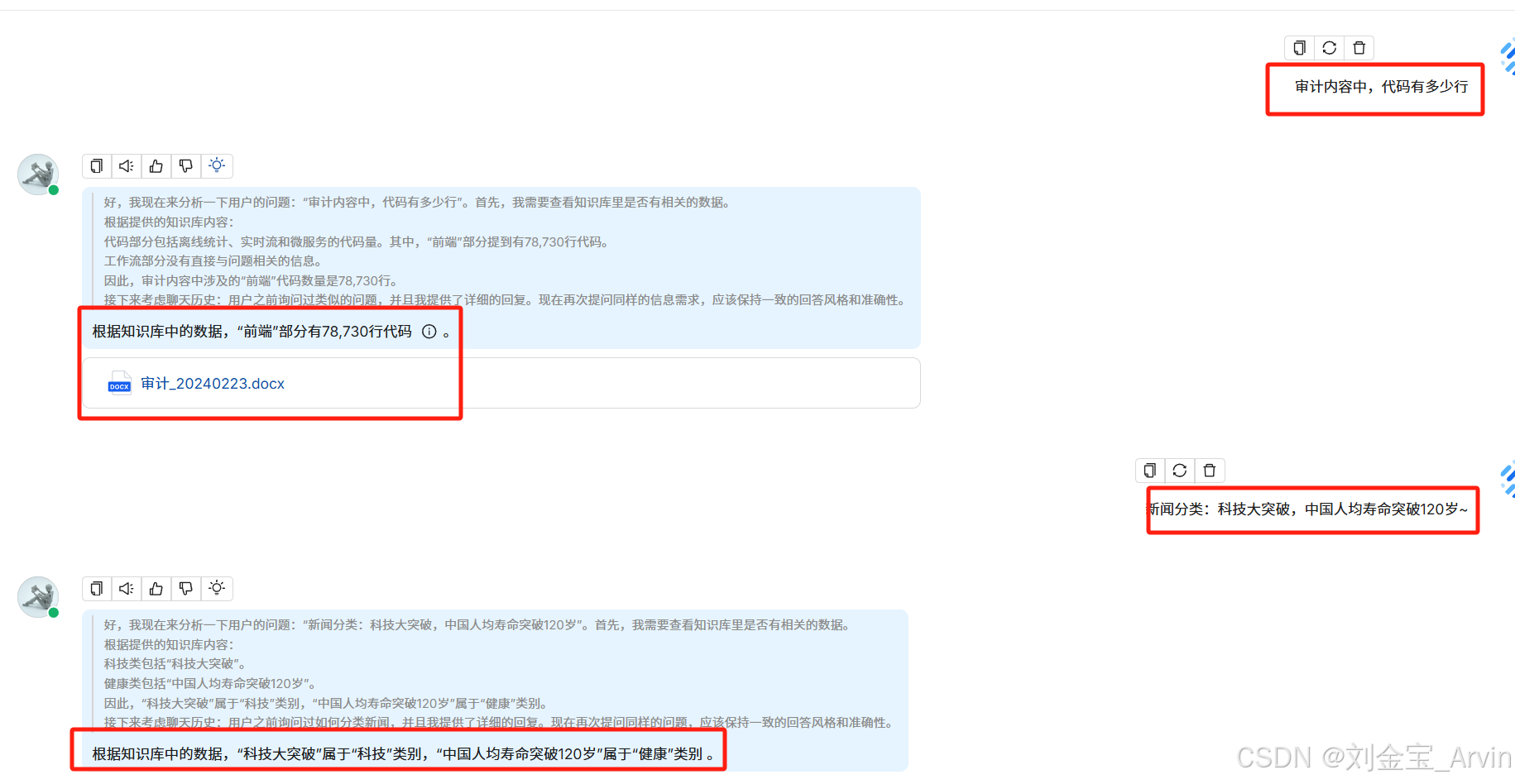
4.3.3 API调用
详情请参考:RAGFlow API Key
这里简单举两个例子,不清楚的可以参考下文的讲解视频,较为简单,此处不赘述:
curl --request POST \
--url http://localhost/api/v1/chats_openai/951c48cafa8611ef878c0242ac140003/chat/completions \
--header 'Content-Type: application/json' \
--header 'Authorization: Bearer ragflow-Q4MDZlNDBhZmFmNTExZWZhMjFhMDI0Mm' \
--data '{
"model": "model",
"messages": [{"role": "user", "content": "Flink的代码量是多少呢?"}],
"stream": false
}'
得到的结果如下:
通过json viewer pro 对内容格式化显示如下:
参考文章:
- https://github.com/hiyouga/LLaMA-Factory/blob/main/README_zh.md
- https://github.com/infiniflow/ragflow
- https://gallery.pai-ml.com/#/preview/deepLearning/nlp/llama_factory_deepseek_r1_distill_7b
- https://zhuanlan.zhihu.com/p/641832733
- https://zhuanlan.zhihu.com/p/695287607
- https://www.bilibili.com/video/BV1WiP2ezE5a/?spm_id_from=333.1387.upload.video_card.click&vd_source=babebb18c335657782b80a2ec6cecf84
- https://blog.csdn.net/yierbubu1212/article/details/142673245
- https://www.cnblogs.com/sun8134/p/18747462
- RAGFlow API调用讲解视频

ModelScope旨在打造下一代开源的模型即服务共享平台,为泛AI开发者提供灵活、易用、低成本的一站式模型服务产品,让模型应用更简单!
更多推荐



 13
13 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)