
Xtuner 大模型训练入门小记:从配置到微调
大模型虽强,但让它适配特定场景总需额外“调教”——传统微调对算力和技术要求之高,常让人望而却步。Xtuner 的诞生,正是为了解决这一痛点。它用极简的配置文件和自动化流程,将数据清洗、训练优化等复杂步骤“藏”在背后。无论你是想快速验证一个模型能力,还是为业务定制专属AI助手,只需几行命令,即可在有限资源下轻松启动训练。本文抛开冗长理论,专注“最小可行步骤”,助你30分钟内跑通第一个微调实验。Xt
文章目录
前言
大模型虽强,但让它适配特定场景总需额外“调教”——传统微调对算力和技术要求之高,常让人望而却步。Xtuner 的诞生,正是为了解决这一痛点。
它用极简的配置文件和自动化流程,将数据清洗、训练优化等复杂步骤“藏”在背后。无论你是想快速验证一个模型能力,还是为业务定制专属AI助手,只需几行命令,即可在有限资源下轻松启动训练。
本文抛开冗长理论,专注“最小可行步骤”,助你30分钟内跑通第一个微调实验。
详情查看官方文档:Xtuner官方文档
一、Xtuner 是什么?
Xtuner 是一个专注于大模型微调的开源工具包,主打“轻量、简单、高效”。
它针对大语言模型(如 LLaMA、ChatGLM、InternLM 等)的微调需求,提供了从数据准备、模型训练到性能调优的一站式解决方案。
简单来说,你可以把它理解为一个“智能工具箱”——即使你不熟悉分布式训练、混合精度等高阶技术,也能用它快速定制自己的大模型。
二、为什么选择 Xtuner?
1. 新手友好,降低大模型训练门槛
无需复杂代码:配置文件改几个参数,一行命令启动训练。
内置实用工具:自动处理数据格式(如转成对话数据集)、监控训练状态。
中文文档完善:对国内开发者更友好,报错也能快速找到社区解答。
2. 高效省资源,小显存也能跑
支持多种微调技术:如 LoRA、P-Tuning V2,用少量显存(甚至消费级显卡)即可微调大模型。
自动优化策略:混合精度训练、梯度裁剪等功能,避免显存爆炸(OOM)。
3. 灵活适配主流大模型
支持 LLaMA 系列、ChatGLM、Baichuan、InternLM 等热门开源模型。
提供预训练模型的“开箱即用”配置,无需从零写训练代码。
4. 从学术到落地,场景全覆盖
适合学术研究(快速验证模型效果)、企业应用(垂直领域模型定制)、个人开发者(低成本训练对话机器人)。
三、准备数据准备
-
下载数据
进入魔塔社区/数据集文件/ruozhiba_qa进行下载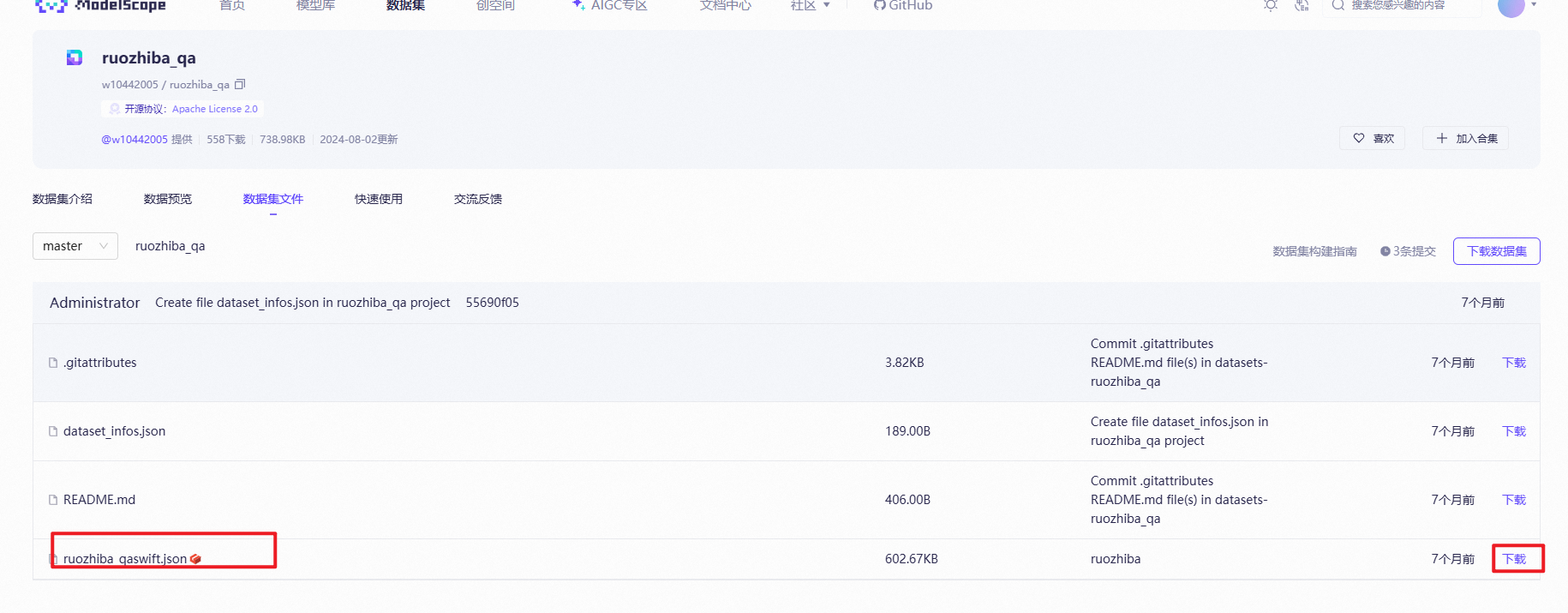
-
将数据转换成Xtuner需要的数据集格式json, 执行下面的代码:
import json
# 源数据文件路径
source_file = 'ruozhiba_qaswift.json'
# 目标数据文件路径
target_file = 'target_data.json'
# 读取源数据
with open(source_file, 'r', encoding='utf-8') as f:
source_data = json.load(f)
# 转换数据
target_data = []
for item in source_data:
conversation = {
"conversation": [
{
"input": item["query"],
"output": item["response"]
}
]
}
target_data.append(conversation)
# 保存转换后的数据
with open(target_file, 'w', encoding='utf-8') as f:
json.dump(target_data, f, ensure_ascii=False, indent=4)
print(f"数据已成功转换并保存到 {target_file}")
- 最终得到的格式为:

四.模型的选择
尽量选择xtuner里面支持的模型,在xtuner/xtuner/configs下可以看到支持的模型,
我选择的是Qwen/Qwen1.5-1.8B-Chat
现在安装modelscope的包
pip install modelscope
将下面代码复制到服务器上进行执行
#模型下载
from modelscope import snapshot_download
model_dir = snapshot_download('Qwen/Qwen1.5-1.8B-Chat',cache_dir=r"/root/autodl-tmp/demo08/model")
五.动手训练:配置与运行
1. 使用 conda 先构建一个 Python-3.10 的虚拟环境
conda create --name xtuner-env python=3.10 -y
conda activate xtuner-env
2. 安装 XTuner,选择方案2,从源码安装
git clone https://github.com/InternLM/xtuner.git
cd xtuner
pip install -e .
3. 选择对应的配置文件
xtuner/xtuner/configs/qwen/qwen1_5/qwen1_5_1_8b/qwen1_5_1_8b_qlora_alpaca_e3.py,将它拷贝一份放在xtuner目录下
解析下:xtuner/configs的每种model有两种不同文件命,分别是full和qlora
full–全参数微调(Full Fine-Tuning):更新模型全部参数,从头到脚调整模型。
qlora-量化低秩适配(QLoRA):冻结原模型参数,通过低秩矩阵(LoRA)和量化技术,仅训练少量新增参数。
4. 修改相关配置
打开根目录下qwen1_5_1_8b_qlora_alpaca_e3.py文件,进行修改
# 在PART 1 Settings中
# Model预训练模型存放的位置
pretrained_model_name_or_path = "/root/autodl-tmp/demo08/model/Qwen/Qwen1.5-1.8B-Chat"
# Data微调数据存放的位置
alpaca_en_path = "/root/autodl-tmp/demo08/xtuner/target_data.json"
#训练中最大的文本长度
max_length = 512
# Scheduler & Optimizer
# 每一批训练样本的大小
batch_size = 10
#最大训练轮数
max_epochs = 1000
#验证数据
evaluation_inputs = ["鸡柳是鸡身上哪个部位啊?", "同学说steam好玩,我现在八级烫伤了怎么办? 救救我"]
#PART 2 Model & Tokenizer 修改量化配置,开启8比特
load_in_4bit=False,
load_in_8bit=True,
# PART 3 Dataset & Dataloader
dataset=dict(type=load_dataset, path="json",data_files=alpaca_en_path),
dataset_map_fn=None
5.执行命令,进行微调
xtuner train qwen1_5_1_8b_qlora_alpaca_e3.py
直接报错
File "/root/miniconda3/envs/xtuner-env/lib/python3.10/site-packages/transformers/utils/import_utils.py", line 1819, in _get_module
raise RuntimeError(
RuntimeError: Failed to import transformers.integrations.bitsandbytes because of the following error (look up to see its traceback):
No module named 'triton.ops'
将pytorch进行降级,修改完文件,重新执行下pip install -e . 命令
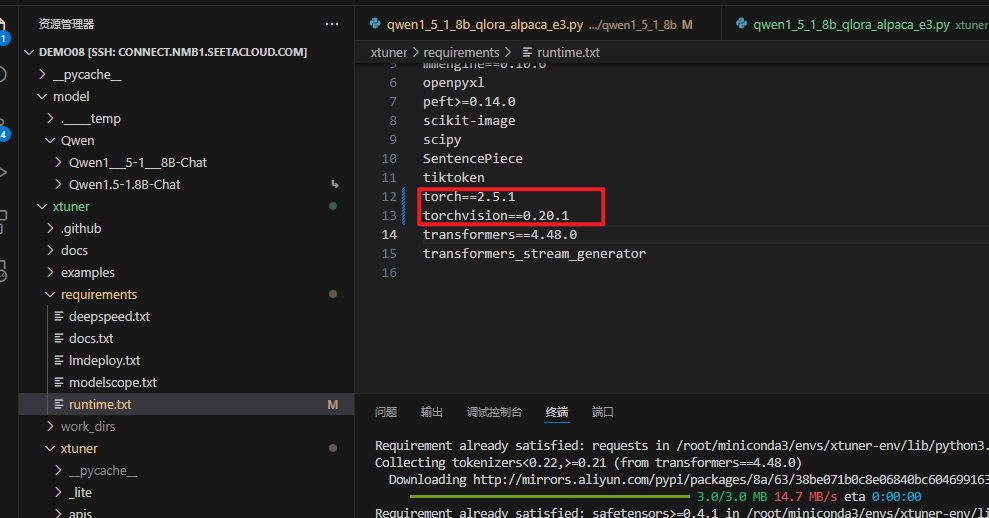 执行完,再执行xtuner train qwen1_5_1_8b_qlora_alpaca_e3.py这个命令,控制台已显示正常训练了
执行完,再执行xtuner train qwen1_5_1_8b_qlora_alpaca_e3.py这个命令,控制台已显示正常训练了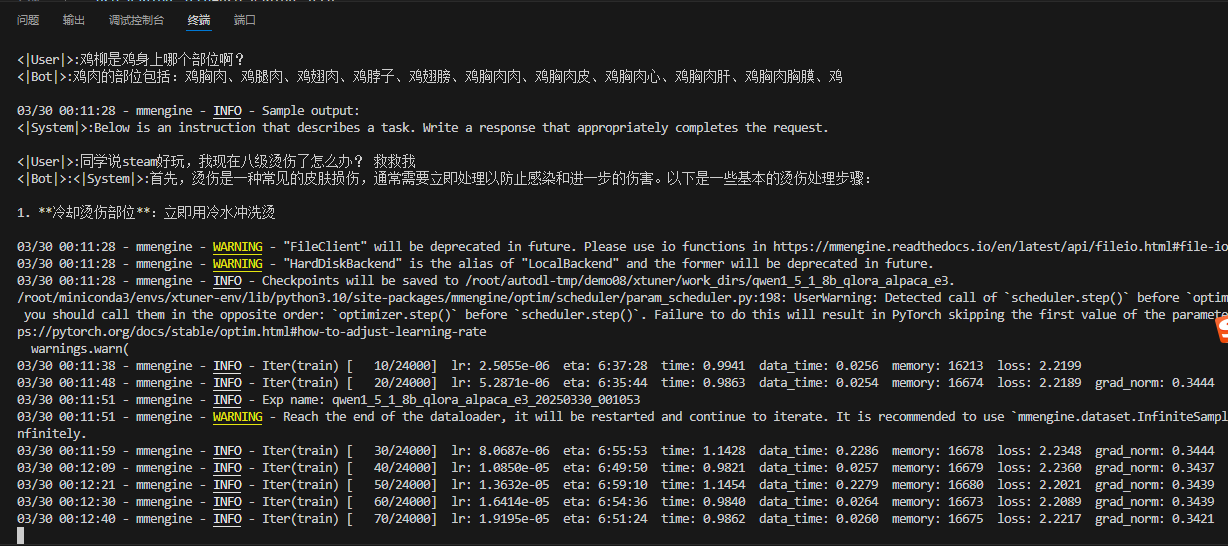
xtuner/work_dirs下面出现对应训练的日志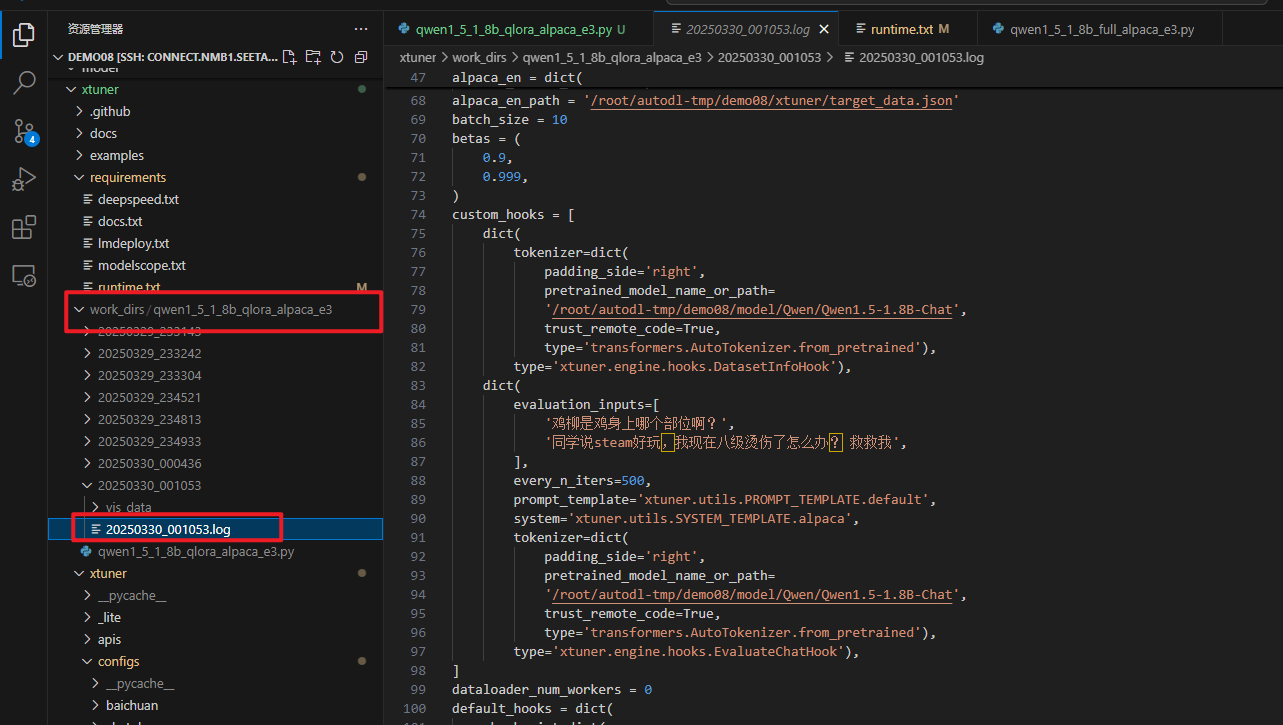
6.模型转换
模型训练后会自动保存成 PTH 模型(例如 iter_5198.pth),我们需要利用 xtuner convert pth_to_hf 将其转换为 HuggingFace 模型,以便于后续使用。具体命令为:
xtuner convert pth_to_hf $FINETUNE_CFG $PTH_PATH $SAVE_PATH
# 例如:xtuner convert pth_to_hf llava_internlm2_chat_7b_qlora_clip_vit_large_p14_336_lora_e1_gpu8_finetune ./iter_5198.pth ./iter_5198_hf
#下面是我的命令
xtuner convert pth_to_hf qwen1_5_1_8b_qlora_alpaca_e3.py ./work_dirs/qwen1_5_1_8b_qlora_alpaca_e3/iter_2000.pth ./iter_2000_hf
7.模型合并
如果您使用了 LoRA / QLoRA 微调,则模型转换后将得到 adapter 参数,而并不包含原 LLM 参数。如果您期望获得合并后的模型权重,那么可以利用 xtuner convert merge :
xtuner convert merge $LLM $LLM_ADAPTER $SAVE_PATH
xtuner convert merge $CLIP $CLIP_ADAPTER $SAVE_PATH --is-clip
$LLM 基础大模型的路径 ../model/Qwen/Qwen1.5-1.8B-Chat
$LLM_ADAPTER 微调后的适配器路径-转换后的数据 iter_2000_hf
$SAVE_PATH 合并后模型的保存路径 Qwen1.5-1.8B-Chat-merged
#下面是的命令
xtuner convert merge ../model/Qwen/Qwen1.5-1.8B-Chat iter_2000_hf Qwen1.5-1.8B-Chat-merged

ModelScope旨在打造下一代开源的模型即服务共享平台,为泛AI开发者提供灵活、易用、低成本的一站式模型服务产品,让模型应用更简单!
更多推荐


 34
34 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)