
基于Qwen3的Embedding和Rerank模型系列,开源!
近年来,随着大规模预训练语言模型(LLM)的飞速发展,文本嵌入(Embedding)和重排序(Reranking)技术在搜索引擎、问答系统、推荐系统等多个领域的重要性愈发凸显。
01.前言
近年来,随着大规模预训练语言模型(LLM)的飞速发展,文本嵌入(Embedding)和重排序(Reranking)技术在搜索引擎、问答系统、推荐系统等多个领域的重要性愈发凸显。嵌入技术通过将文本映射到向量空间,实现语义层面的相似度计算;重排序技术则在候选文本检索的基础上,进一步确保最相关的结果被精准呈现。然而,如何在多语言、多任务环境下,训练出兼具效率与效果的嵌入/重排序模型,一直是学术界和工业界面临的挑战。
在以往的研究中,文本嵌入模型多以 BERT、RoBERTa 等编码器为基础,通过对大规模无监督语料进行预训练,再以有监督数据微调,从而获得能够捕捉语义相似度的向量表示。然而,这类模型存在以下局限:
1、多语言支持不足
传统嵌入模型往往针对英语或单一语种进行优化,而对于低资源语言或多语种混合场景的适应性有限。
2、训练数据收集成本高
以往弱监督数据主要依赖公开社区(如 Q&A 论坛、学术论文)进行收集,数据质量和多样性难以兼顾。
3、模型泛化与鲁棒性挑战
单一检查点训练容易导致模型对特定任务/数据分布的过拟合,缺乏跨领域、跨任务的稳健性。
4、重排序任务需求日益增长
在检索系统中,嵌入阶段负责召回,重排序阶段负责精排。随着 RAG(Retrieval-Augmented Generation)与 Agent 系统的兴起,重排序对上下文理解和跨语言能力的要求提高,亟需高质量的 LLM 支撑。
阿里巴巴通义实验室正式发布Qwen3-Embedding和Qwen3-Reranker系列模型, 成为Qwen模型家族的新成员。该系列模型专为文本表征、检索与排序任务设计,基于Qwen3基础模型进行训练,充分继承了Qwen3在多语言文本理解能力方面的优势。
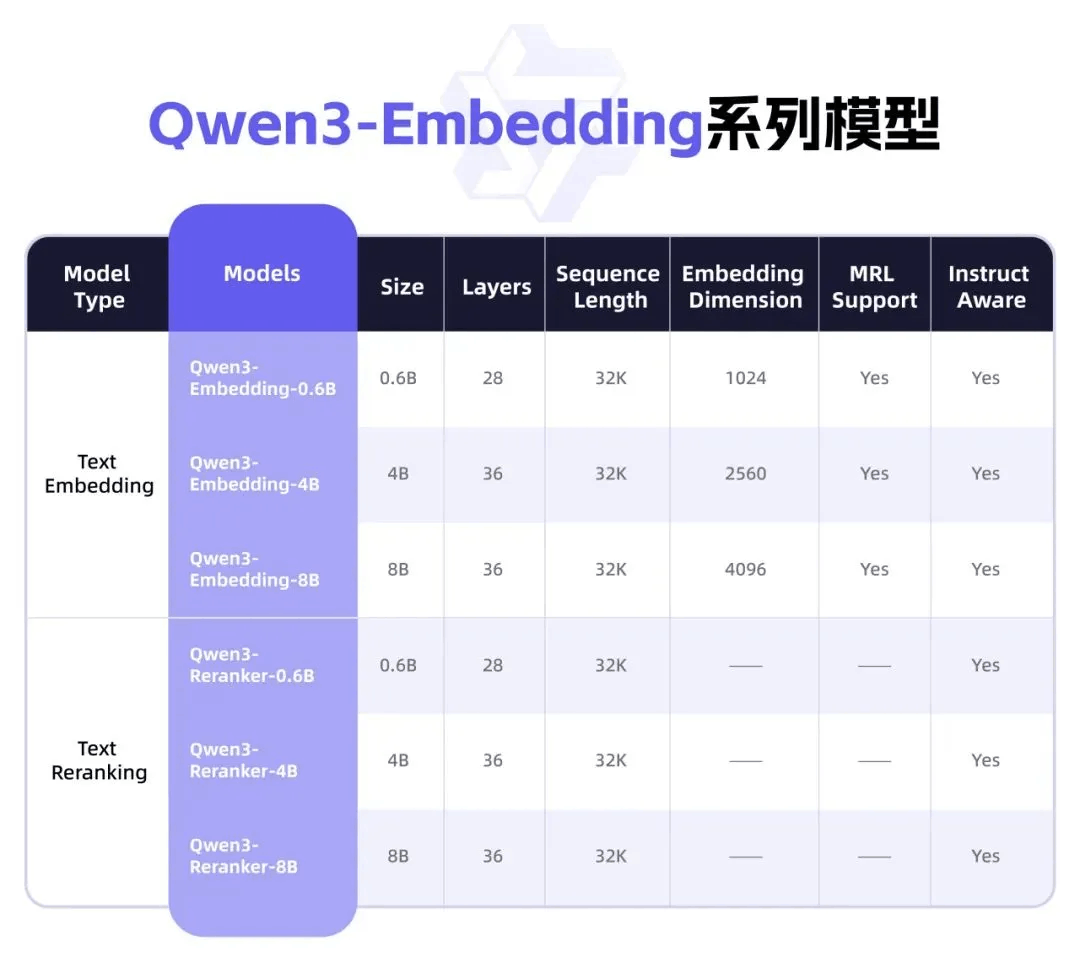
注:「MRL Support」表示Embedding模型是否支持最终向量的自定义维度。「Instruction Aware」表示Embedding或Reranker模型是否支持根据不同任务定制输入指令。
在多项基准测试中,Qwen3-Embedding系列在文本表征和排序任务中展现了卓越的性能。

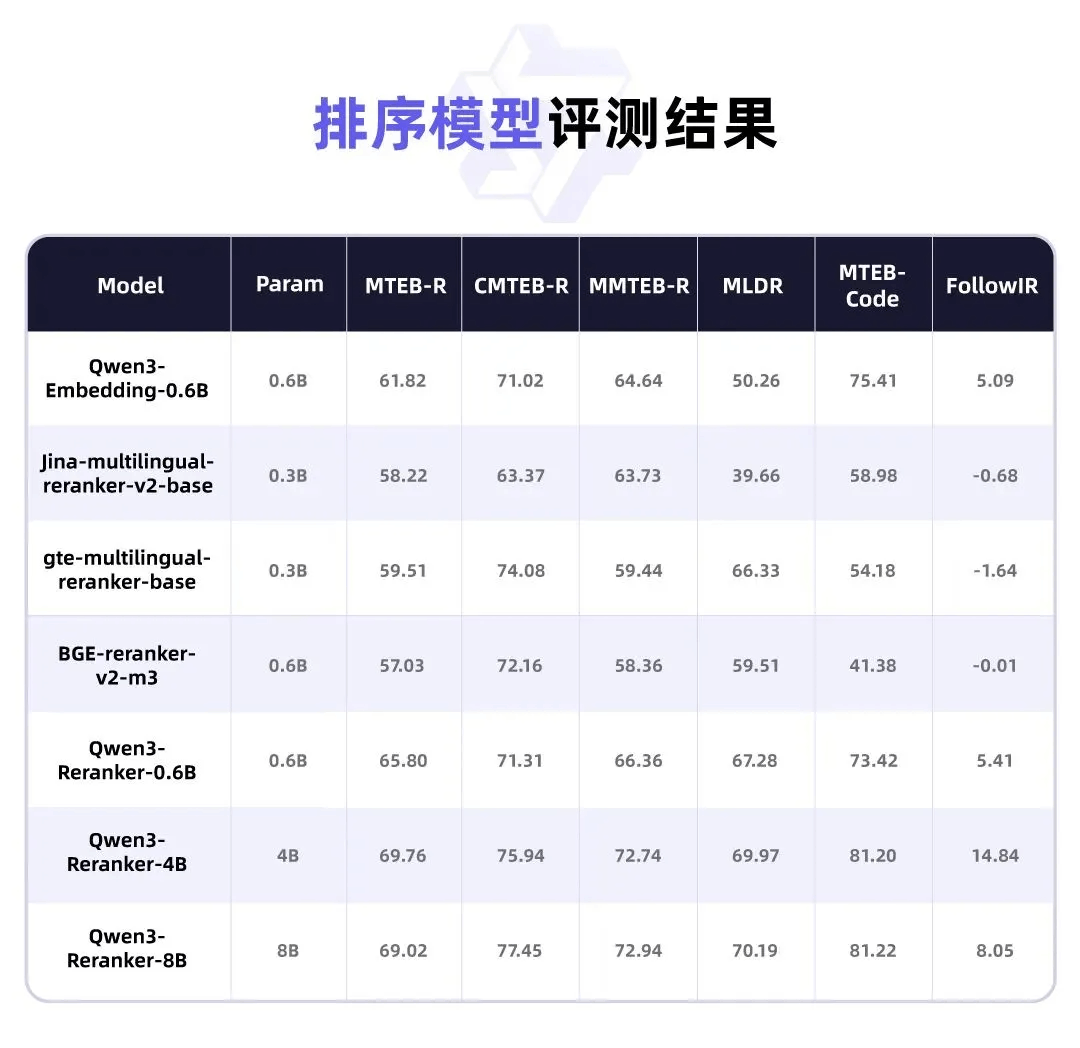
注:
使用MTEB(eng, v2), MTEB(cmn, v1), MTEB (Multilingual) 以及MTEB (Code)中的检索数据集进行测试, 分别记作MTEB-R, CMTEB-R, MMTEB-R, MTEB-Code.
排序结果基于Qwen3-Embedding-0.6B的top-100向量召回结果进行排序.
02.开源地址
模型:
-
Qwen3-Embedding
https://modelscope.cn/collections/Qwen3-Embedding-3edc3762d50f48
-
Qwen3-Reranker
https://modelscope.cn/collections/Qwen3-Reranker-6316e71b146c4f
GitHub:
https://github.com/QwenLM/Qwen3-Embedding
技术报告:
https://github.com/QwenLM/Qwen3-Embedding/blob/main/qwen3_embedding_technical_report.pdf
03.核心创新
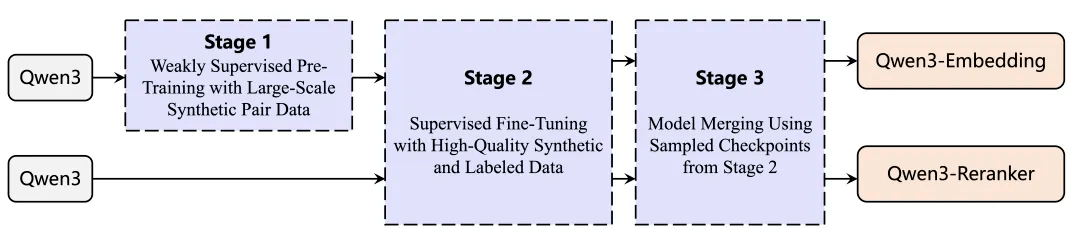
Qwen3 Embedding 系列最核心的创新,在于基于 Qwen3 LLM 强大的文本合成能力,设计了“合成数据驱动的弱监督 + 高质量数据的有监督微调 + 模型合并”的多阶段训练(multi-stage training)的pipeline。
阶段一:大规模弱监督预训练(Weakly Supervised Pre-Training)
-目标:利用大规模“合成”数据进行初始训练,以提升模型的泛化能力与多任务适应性。
-合成数据来源:基于 Qwen3-32B LLM,通过精心设计的模板与提示(prompt),将原始多语种文档转化为“查询-文档”对。例如,先在“Configuration”阶段为每段文档挑选角色(Character)、问题类型(Question_Type)、难度(Difficulty);再在“Query Generation”阶段根据上述配置生成用户角度的查询句。
-数据规模:最终合成约 1.5 亿 对多任务弱监督训练数据,涵盖信息检索、比对挖掘(bitext mining)、分类、语义相似度等多种任务类型。
-训练目标:采用改进的 InfoNCE 对比损失,将正例与多种负例(包括硬负样本、批内负样本、文本对负样本)纳入考量,具体公式见报告中式 (1),借助动态 Mask 策略(当某个批内示例与正例的相似度过高或本身就是正例时,将相应相似度置为 0,以减小“伪负例”对模型的干扰)。
Insight 1:与以往从开源社区爬取弱监督数据不同,合成数据具有高度可控性,可指定生成任务维度(包括任务类型、语言、查询长度、难度等),从而有效覆盖低资源语言场景与多样化需求。
阶段二:高质量数据有监督微调(Supervised Fine-Tuning)
-目标:在弱监督预训练模型的基础上,利用“小而精”的有监督数据进一步提升模型性能。
-数据来源:
-
① 公开高质量数据集:如 MS MARCO、Natural Questions、HotpotQA、NLI、DuReader、T2-Ranking、SimCLUE、MIRACL、MLDR、Mr.TyDi、Multi-CPR、CodeSearchNet 等多种问答、检索和比对挖掘数据集。
-
② 筛选后的合成数据:在弱监督阶段合成的 1.5 亿对数据中,先对每对样本计算余弦相似度(cosine similarity),保留相似度大于 0.7 的高质量样本,约 1200 万 对,作为辅助有监督训练数据。
-训练目标:同样沿用 InfoNCE 损失(式 (1))对嵌入模型进行微调;重排序模型直接采用 SFT(二分类交叉熵)损失(式 (2))。
Insight 2:由于 Qwen3‐32B 生成的数据质量较高,筛选后的合成数据在微调阶段注入适量噪声,可有效提升模型的泛化能力,并与真实标注数据形成互补。
阶段三:模型合并(Model Merging)
-目标:在有监督微调阶段保存的多个检查点(checkpoints)之间,通过**球面线性插值(slerp)**技术,将不同阶段或不同任务偏好模型进行“合并”,提高最终模型的鲁棒性与稳健性。
-关键作法:
-
① 检查点采样:在微调过程中,每隔若干 step 或达到一定验证集效果时保存模型参数。
-
② 球面线性插值:根据 slerp 算法,将多个检查点的参数按一定权重合成,生成新的“混合”模型。
-效果对比:如果不进行合并(不 merge),Qwen3-Embedding-0.6B 在 MMTEB、MTEB (Eng)、CMTEB、MTEB (Code) 等基准上的表现会明显下降;而仅使用弱监督合成数据进行训练,也无法达到最终融合后的高水平。
04.模型架构
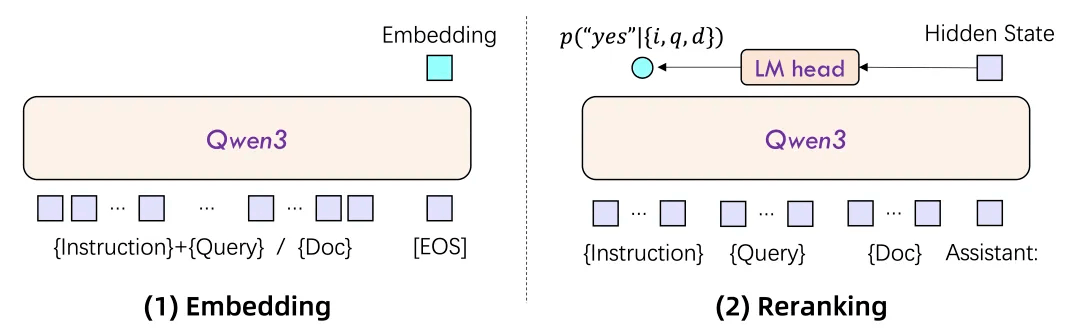
基于Qwen3基础模型,Embedding模型和Reranker模型分别采用了双塔结构和单塔结构的设计。通过LoRA微调,最大限度地保留并继承了基础模型的文本理解能力。
具体实现如下:
① Embedding模型接收单段文本作为输入,取模型最后一层「EOS」标记对应的隐藏状态向量,作为输入文本的语义表示;
② Reranker模型则接收文本对(例如用户查询与候选文档)作为输入,利用单塔结构计算并输出两个文本的相关性得分。
05.模型推理
使用modelscope推理
import torch
import torch.nn.functional as F
from torch import Tensor
from modelscope import AutoTokenizer, AutoModel
def last_token_pool(last_hidden_states: Tensor,
attention_mask: Tensor) -> Tensor:
left_padding = (attention_mask[:, -1].sum() == attention_mask.shape[0])
if left_padding:
return last_hidden_states[:, -1]
else:
sequence_lengths = attention_mask.sum(dim=1) - 1
batch_size = last_hidden_states.shape[0]
return last_hidden_states[torch.arange(batch_size, device=last_hidden_states.device), sequence_lengths]
def get_detailed_instruct(task_description: str, query: str) -> str:
return f'Instruct: {task_description}\nQuery:{query}'
def tokenize(tokenizer, input_texts, eod_id, max_length):
batch_dict = tokenizer(input_texts, padding=False, truncation=True, max_length=max_length-2)
for seq, att in zip(batch_dict["input_ids"], batch_dict["attention_mask"]):
seq.append(eod_id)
att.append(1)
batch_dict = tokenizer.pad(batch_dict, padding=True, return_tensors="pt")
return batch_dict
# Each query must come with a one-sentence instruction that describes the task
task = 'Given a web search query, retrieve relevant passages that answer the query'
queries = [
get_detailed_instruct(task, 'What is the capital of China?'),
get_detailed_instruct(task, 'Explain gravity')
]
# No need to add instruction for retrieval documents
documents = [
"The capital of China is Beijing.",
"Gravity is a force that attracts two bodies towards each other. It gives weight to physical objects and is responsible for the movement of planets around the sun."
]
input_texts = queries + documents
tokenizer = AutoTokenizer.from_pretrained('Qwen/Qwen3-Embedding-8B', padding_side='left')
model = AutoModel.from_pretrained('Qwen/Qwen3-Embedding-8B')
# We recommend enabling flash_attention_2 for better acceleration and memory saving.
# model = AutoModel.from_pretrained('Qwen/Qwen3-Embedding-8B', attn_implementation="flash_attention_2", torch_dtype=torch.float16).cuda()
eod_id = tokenizer.convert_tokens_to_ids("<|endoftext|>")
max_length = 8192
# Tokenize the input texts
batch_dict = tokenize(tokenizer, input_texts, eod_id, max_length)
batch_dict.to(model.device)
outputs = model(**batch_dict)
embeddings = last_token_pool(outputs.last_hidden_state, batch_dict['attention_mask'])
# normalize embeddings
embeddings = F.normalize(embeddings, p=2, dim=1)
scores = (embeddings[:2] @ embeddings[2:].T)
print(scores.tolist())
使用ollama推理
ollama pull modelscope.cn/Qwen/Qwen3-Embedding-0.6B-GGUF查看运行结果
curl http://localhost:11434/api/embed -d '{
"model": "modelscope.cn/Qwen/Qwen3-Embedding-0.6B-GGUF:latest",
"input": "Hello, World!"
}'06.模型微调
可以使用SWIFT框架进行Embedding模型的进一步微调,以适应特定领域的embedding数据需求。
训练可以使用的脚本如下:
INFONCE_MASK_FAKE_NEGATIVE=true \
CUDA_VISIBLE_DEVICES=0,1,2,3,4,5,6,7 \
NPROC_PER_NODE=8 \
swift sft \
--model Qwen/Qwen3-Embedding-8B \
--task_type embedding \
--model_type qwen3_emb \
--train_type full \
--dataset sentence-transformers/stsb:positive \
--split_dataset_ratio 0.05 \
--eval_strategy steps \
--output_dir output \
--eval_steps 20 \
--num_train_epochs 5 \
--save_steps 70 \
--per_device_train_batch_size 4 \
--per_device_eval_batch_size 4 \
--gradient_accumulation_steps 4 \
--learning_rate 6e-6 \
--loss_type infonce \
--label_names labels \
--dataloader_drop_last true \
--deepspeed zero3在脚本中使用了--loss_type infonce,这也是原模型训练使用的loss类型。也可以使用其他loss类型,例如--loss_type cosine_similarity。infonce loss是一种对比学习loss,在上面的脚本中,我们默认将不同样例处理为负例,这可以通过INFONCE_USE_BATCH环境变量控制,该变量默认为True。上述脚本还有一个额外的环境变量:INFONCE_MASK_FAKE_NEGATIVE=true,该变量会忽略相似度值过高的负例(例如负例的相似度高于正例相似度+0.1),防止数据集重复或者假负例问题对训练造成干扰。
infonce loss对应的数据集格式如下:
{"query": "sentence1", "response": "sentence1-pos", "rejected_response": ["sentence1-neg1", "sentence1-neg2"]}本样例的负例和其他样本的正负例均会当做本样本的负例使用。
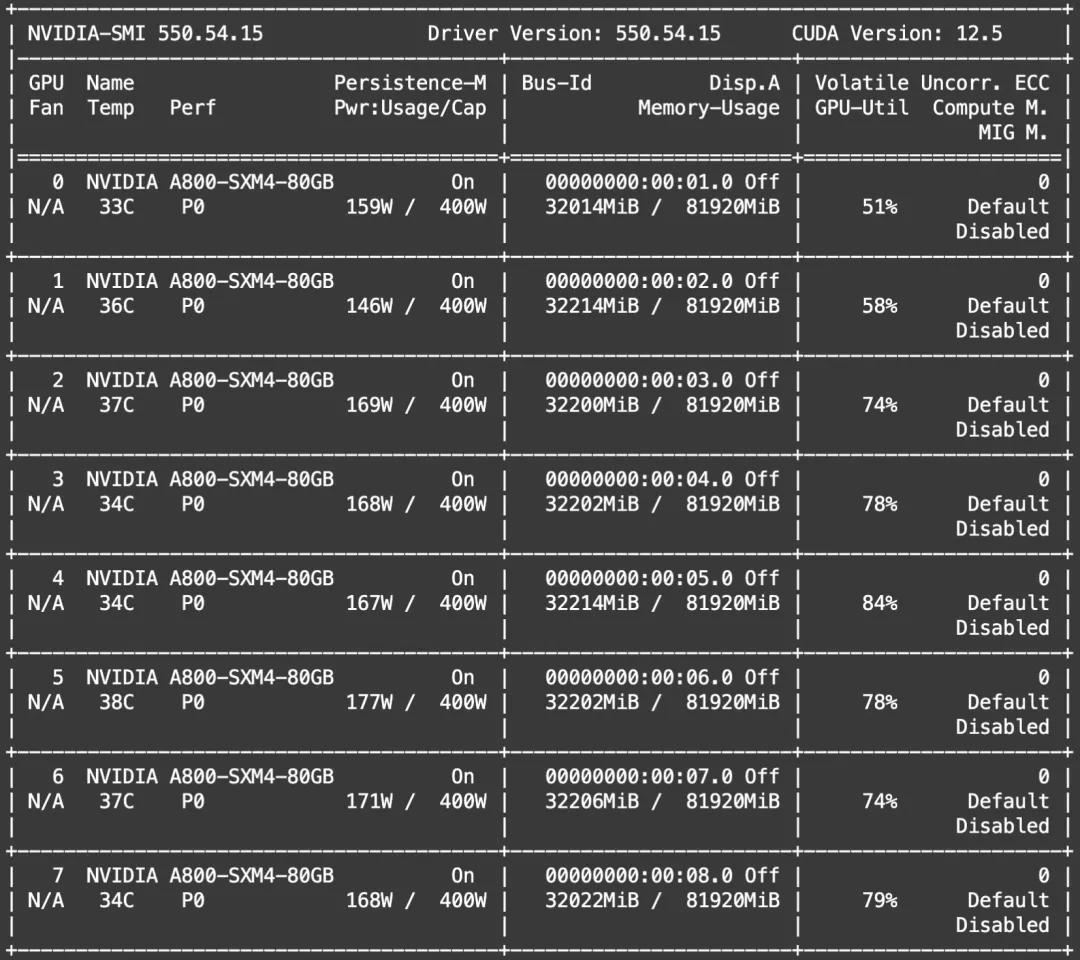
显存消耗如下:
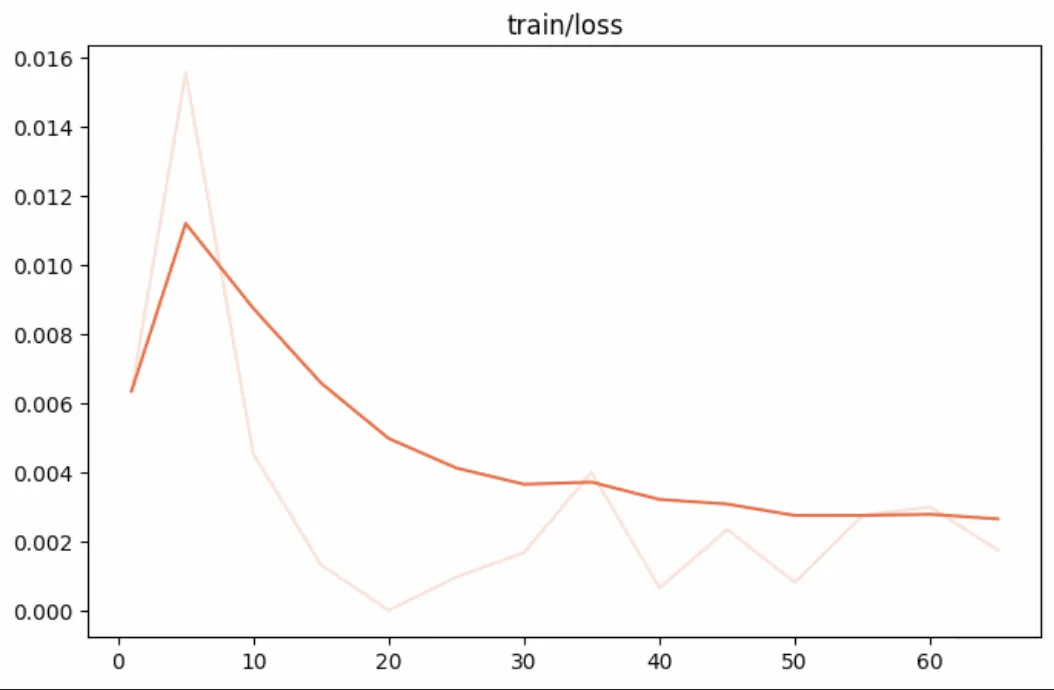
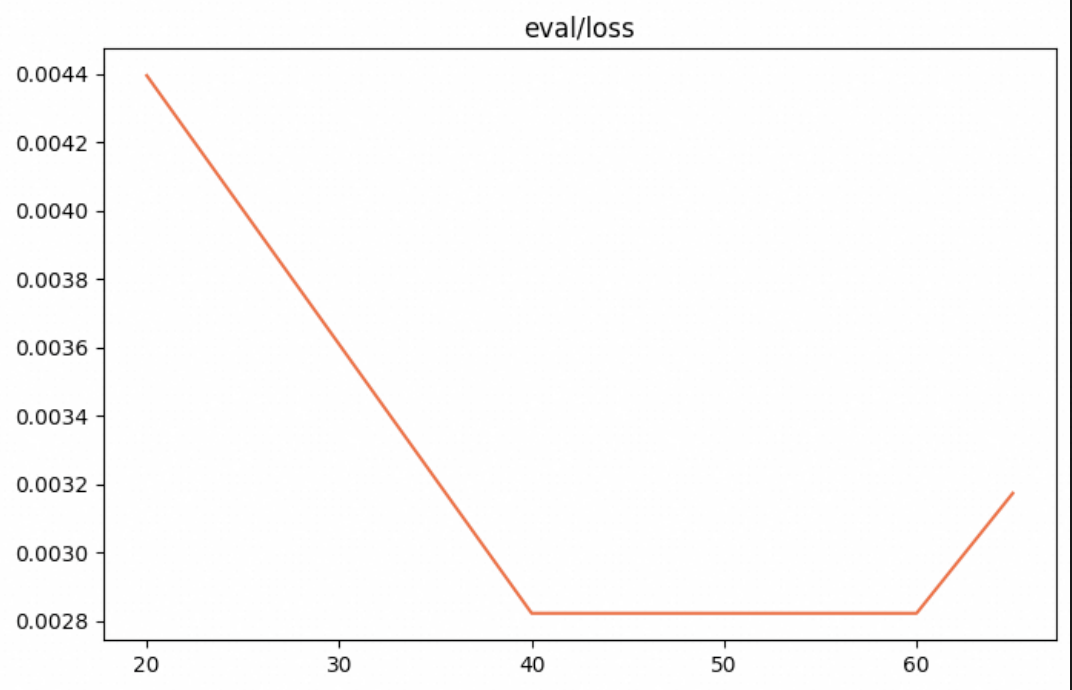
训练loss如下:
使用训练原模型(Qwen/Qwen3-Embedding-8B)和训练后模型进行推理(SWIFT尚不支持embedding模型的推理,请使用原模型README的推理代码):
样例1:
A man is playing a large flute.
A man is playing a flute.
样例2:
A man is spreading shreded cheese on a pizza.
A man is spreading shredded cheese on an uncooked pizza.
这两个样例均来自于训练数据集。进行推理后结果如下:
原模型:
样例1相似度:0.8023
样例2相似度:0.6426
训练后:
样例1相似度:0.9118
样例2相似度:0.957807.应用前景
-
多语言搜索与问答系统
-
在全球化应用场景下,跨语言信息检索需求旺盛。Qwen3-Embedding 在 MMTEB 中取得领先,而 Reranker 在复杂指令检索中也表现突出,可支持多语种混合检索、跨语言问答(Cross-lingual QA)。
-
代码检索与开发助手
-
MTEB(Code)成绩表明 Qwen3-Embedding-8B 在代码检索、代码相似度匹配等领域具有极佳效果,可用于构建代码搜索引擎、代码补全/重构助手等工具。
-
生成式检索与 RAG 系统
-
在 RAG 架构中,嵌入模型负责召回相关文档,随后 LLM 利用召回文档生成答案。Qwen3 Embedding 与 Qwen3 基础模型天然兼容,可无缝结合生成器端,提升生成式检索整体性能;
-
企业级知识库与智能客服
-
针对企业内部多语种文档、技术文档、FAQ 等进行检索与重排序;重排序模型可将检索结果与指令定制结合,为客服与问答系统提供精准答案排序。
点击链接,即可跳转模型链接~
https://modelscope.cn/collections/Qwen3-Embedding-3edc3762d50f48

ModelScope旨在打造下一代开源的模型即服务共享平台,为泛AI开发者提供灵活、易用、低成本的一站式模型服务产品,让模型应用更简单!
更多推荐



 0
0 0
0- 0



 已为社区贡献653条内容
已为社区贡献653条内容

所有评论(0)