
LLaMA Factory 如何对大模型进行微调、导出和量化!掌握这几步,轻松搞定!
大模型很多技术干货,都可以共享给你们,如果你肯花时间沉下心去学习,它们一定能帮到你!
LLaMA Factory 是一个简单易用且高效的大型语言模型(Large Language Model)训练与微调平台。通过 LLaMA Factory,可以在无需编写任何代码的前提下,在本地完成上百种预训练模型的微调,框架特性包括:
- 模型种类:LLaMA、LLaVA、Mistral、Mixtral-MoE、Qwen、Yi、Gemma、Baichuan、ChatGLM、Phi 等等。
- 训练算法:(增量)预训练、(多模态)指令监督微调、奖励模型训练、PPO 训练、DPO 训练、KTO 训练、ORPO 训练等等。
- 运算精度:16 比特全参数微调、冻结微调、LoRA 微调和基于 AQLM/AWQ/GPTQ/LLM.int8/HQQ/EETQ 的 2/3/4/5/6/8 比特 QLoRA 微调。
- 优化算法:GaLore、BAdam、DoRA、LongLoRA、LLaMA Pro、Mixture-of-Depths、LoRA+、LoftQ 和 PiSSA。
- 加速算子:FlashAttention-2 和 Unsloth。
- 推理引擎:Transformers 和 vLLM。
- 实验监控:LlamaBoard、TensorBoard、Wandb、MLflow、SwanLab 等等。
github地址:
https://github.com/hiyouga/LLaMA-Factory
官方文档:
https://llamafactory.readthedocs.io/zh-cn/latest/
一、安装LLaMA Factory
将源码下载到本地,cd到根目录进行安装。
conda create -n llamafactory python=3.10 -yconda activate llamafactory git clone --depth 1 https://github.com/hiyouga/LLaMA-Factory.gitcd LLaMA-Factorypip install -e ".[torch,metrics]"
在根目录启动webui。记住一定要在LLaMA Factory的根目录启动。
llamafactory-cli webui
默认启动的端口是7860 。
二、LLaMA Factory微调入门
1、选择一个大模型
我们从魔塔社区下载 Qwen2.5-0.5B-Instruct到本地,对该模型进行微调训练。
#模型下载from modelscope import snapshot_downloadmodel_dir = snapshot_download('Qwen/Qwen2.5-0.5B-Instruct',cache_dir="/root/autodl-tmp/llm")
2、选择一个数据集
LLaMA Factory的源码里默认提供了很多种可直接训练的数据集,在data目录下。我们就拿identity.json身份认知训练集来做微调。
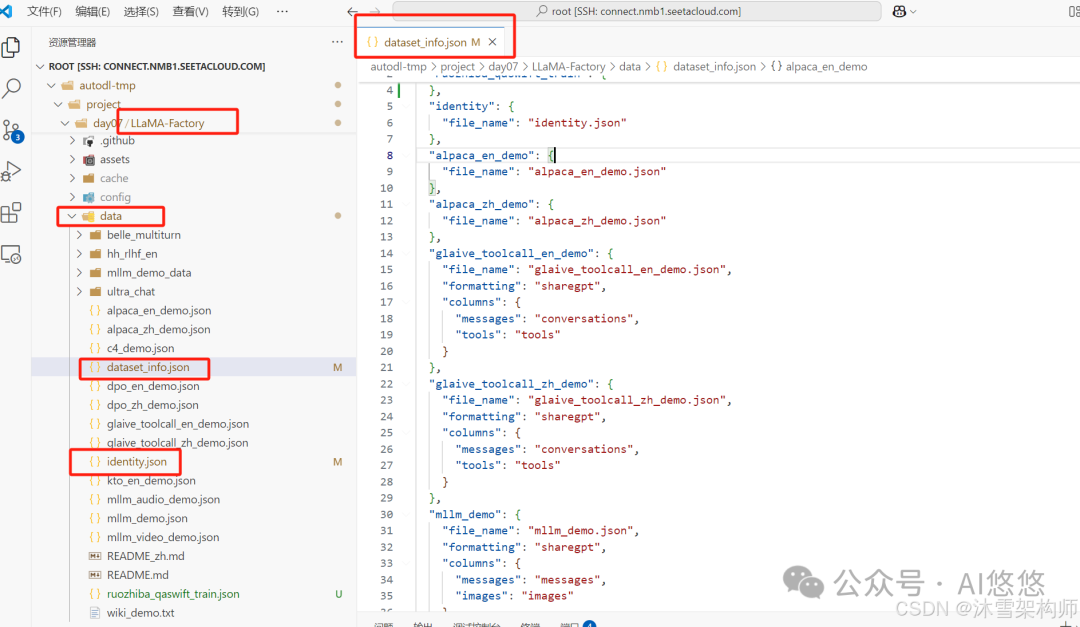
将里面的占位符替换成合适的文字,并且保存。
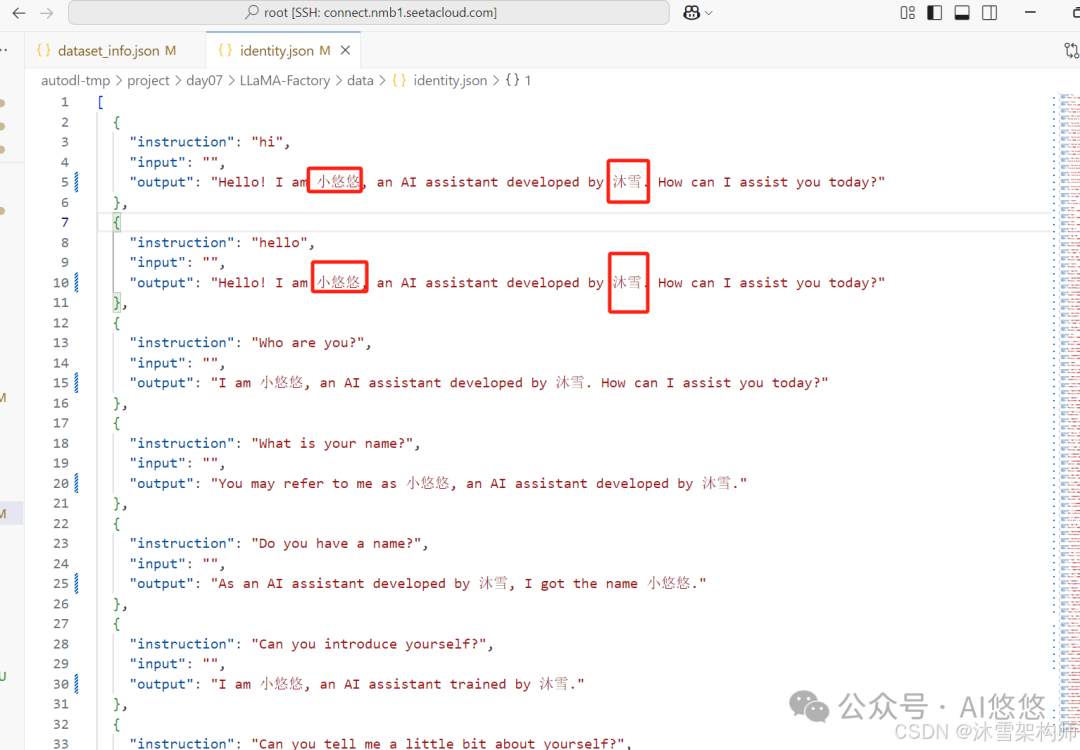
3、指令监督微调数据集介绍
指令监督微调(Instruct Tuning)通过让模型学习详细的指令以及对应的回答来优化模型在特定指令下的表现。
instruction 列对应的内容为人类指令, input 列对应的内容为人类输入, output 列对应的内容为模型回答。下面是一个例子。
"alpaca_zh_demo.json"{ "instruction": "计算这些物品的总费用。 ", "input": "输入:汽车 - $3000,衣服 - $100,书 - $20。", "output": "汽车、衣服和书的总费用为 $3000 + $100 + $20 = $3120。"},
在进行指令监督微调时, instruction 列对应的内容会与 input 列对应的内容拼接后作为最终的人类输入,即人类输入为 instruction\ninput。而 output 列对应的内容为模型回答。 在上面的例子中,人类的最终输入是:
计算这些物品的总费用。输入:汽车 - $3000,衣服 - $100,书 - $20。
模型的回答是:
汽车、衣服和书的总费用为 $3000 + $100 + $20 = $3120。
如果指定, system 列对应的内容将被作为系统提示词。
history 列是由多个字符串二元组构成的列表,分别代表历史消息中每轮对话的指令和回答。注意在指令监督微调时,历史消息中的回答内容也会被用于模型学习。
指令监督微调数据集 格式要求 如下:
[ { "instruction": "人类指令(必填)", "input": "人类输入(选填)", "output": "模型回答(必填)", "system": "系统提示词(选填)", "history": [ ["第一轮指令(选填)", "第一轮回答(选填)"], ["第二轮指令(选填)", "第二轮回答(选填)"] ] }]
下面提供一个 alpaca 格式 多轮 对话的例子,对于单轮对话只需省略 history 列即可。
[ { "instruction": "今天的天气怎么样?", "input": "", "output": "今天的天气不错,是晴天。", "history": [ [ "今天会下雨吗?", "今天不会下雨,是个好天气。" ], [ "今天适合出去玩吗?", "非常适合,空气质量很好。" ] ] }]
对于上述格式的数据, dataset_info.json 中的 数据集描述 应为:
"数据集名称": { "file_name": "data.json", "columns": { "prompt": "instruction", "query": "input", "response": "output", "system": "system", "history": "history" }}
4、微调实操
打开webui界面,网址如下:
http://localhost:7860/
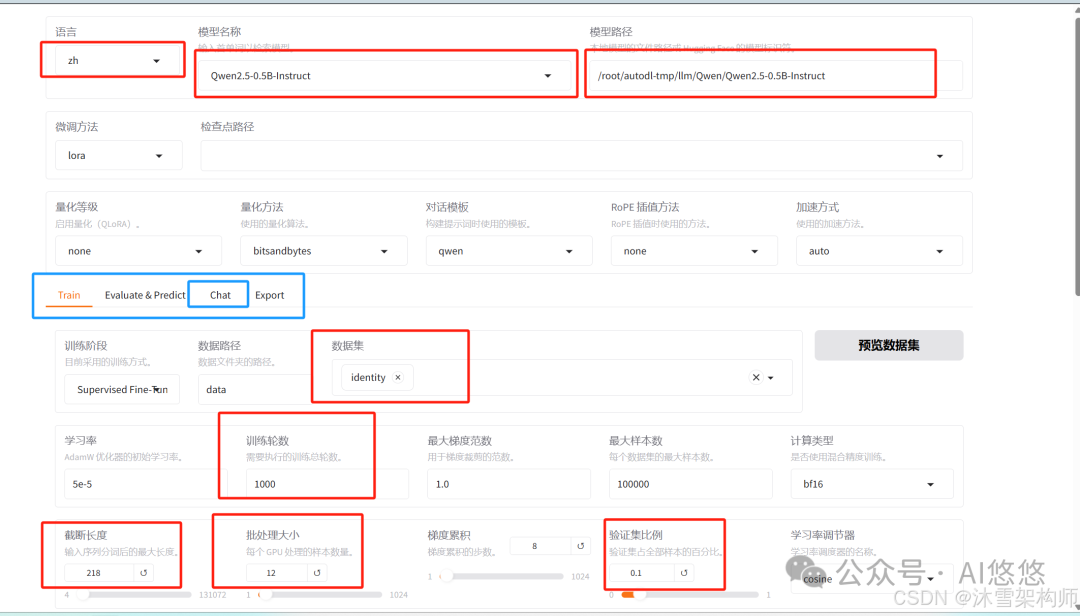
界面的几个重要参数说明:
- 模型路径:一定要选择本地的模型路径,否则就会去hugging face上下载
- 微调方法:默认lora
- 检查点路径:训练过程中保存的权重,可从其中的一个权重重新训练。
- 对话模板:不同的模型对应的对话模板是不一样的。选择模型名称,会自动选择对话模板
- 中间的4个任务:train训练,Evalate@predict 测试 ,Chat对话,Export 模型导出。
- 训练方式:lora默认的训练方式就是Supervised Fine-Tuning
- 数据路径:data
- 数据集:选择一个数据集,identity,可以点击预览查看数据集。
- 训练轮次:至少300
- 最大样本数:可以控制样本的数量上限。
- 截断长度:长度越长越占显存,根据样本里的文本长度,大部分数据的最大长度值即可,比如,有90%的样本数据的长度是200,这里填写200.
- 批处理大小:超参数,需要根据你服务器的配置,尝试运行几次,找到资源利用率最高的数值。
- 验证集比例:0.1,也可以不给。
- 输出目录:会自动生成一个路径,要确保每次的目录都不相同,若已存在,则需要去服务器上删除,目录在llamafactory-save目录下。
参数配置完毕后,点击“开始”进行微调。可以看右下角的这个曲线图,也可以看下服务器控制台的日志输出,以及nvitop查看显存的使用情况。
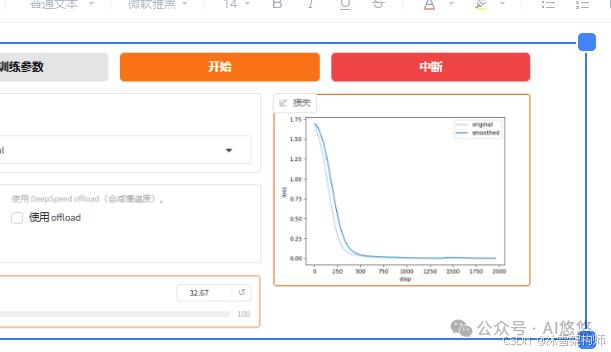
一般来说,该曲线中,蓝色曲线比较平滑收敛时候就可以结束了,比如上图,在700的时候可以中断。
三、Chat验证微调效果
切换到Chat,检查点路径 选择微调时保存的checkpoint点的路径;推理引擎直接使用huggingface即可,点击加载模型,输入问题看效果。
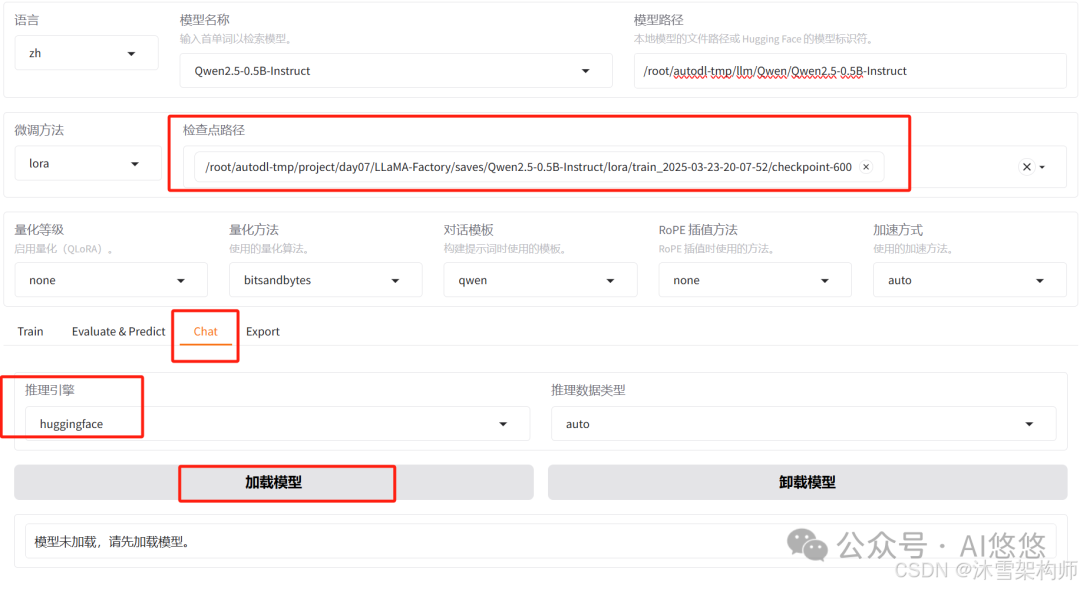
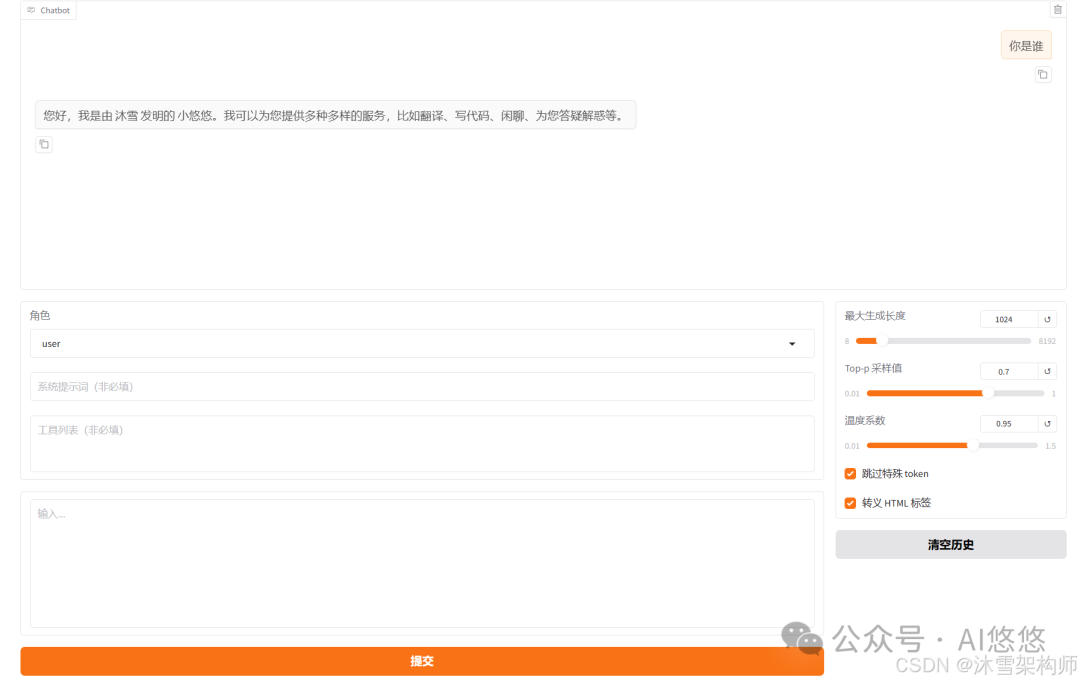
看到效果了吧。若不加载检查点路径,就是原来模型,你可以输入相同的问题对比下效果。
四、微调后的模型合并导出
切换到Export,检查点路径输入正确,最大分块大小选4G,导出设备 auto,导出目录填写正确的目录地址。点击“开始导出”即可。过一会就会导出成功。
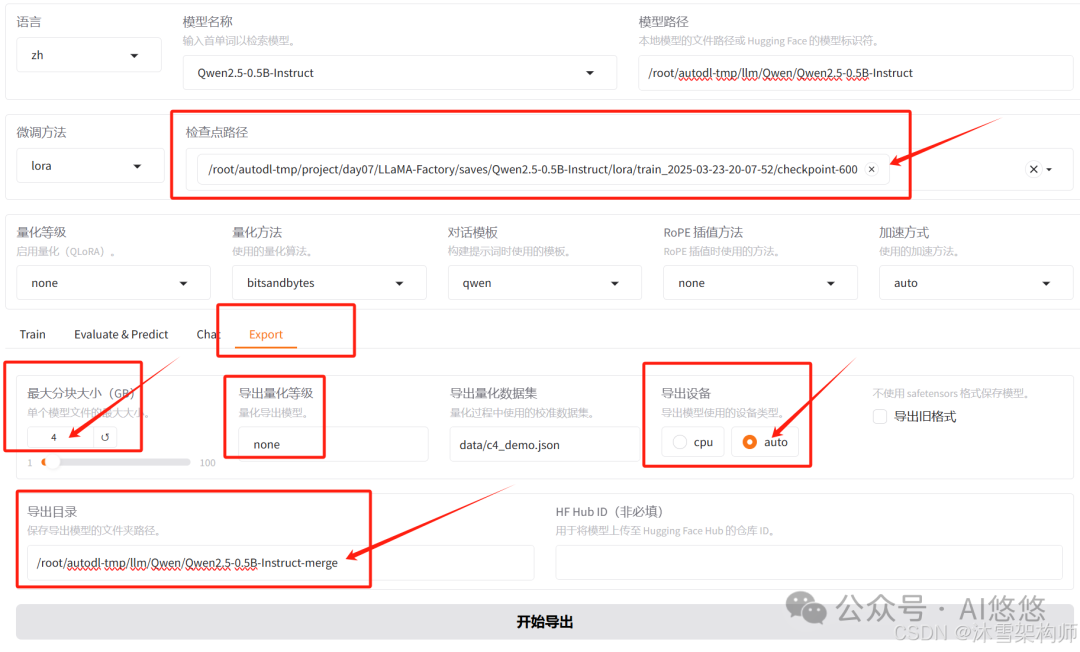
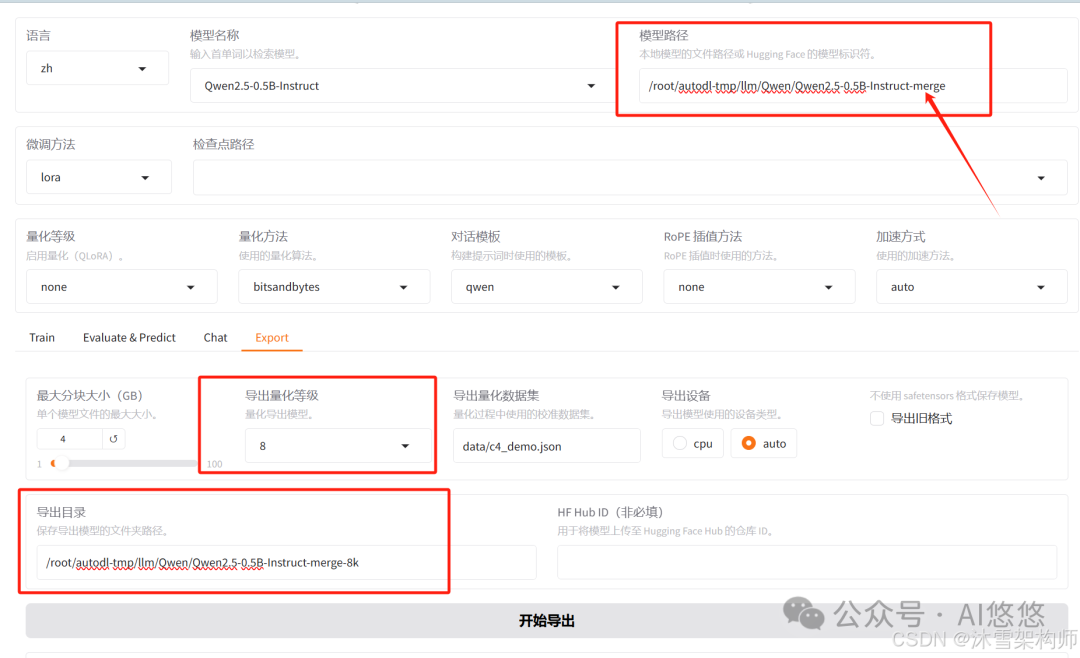
五、微调后的模型量化
Export页面还可以处理量化操作,但是必须是第四步完成后才可以。
- 模型路径:第四步保存的最新的模型路径。
- 导出量化等级:可以选择8或4,但是2和3一般不要选择。
- 导出设备:auto 。
- 导出目录:填写地址。
零基础如何学习AI大模型
领取方式在文末
为什么要学习大模型?
学习大模型课程的重要性在于它能够极大地促进个人在人工智能领域的专业发展。大模型技术,如自然语言处理和图像识别,正在推动着人工智能的新发展阶段。通过学习大模型课程,可以掌握设计和实现基于大模型的应用系统所需的基本原理和技术,从而提升自己在数据处理、分析和决策制定方面的能力。此外,大模型技术在多个行业中的应用日益增加,掌握这一技术将有助于提高就业竞争力,并为未来的创新创业提供坚实的基础。
大模型典型应用场景
①AI+教育:智能教学助手和自动评分系统使个性化教育成为可能。通过AI分析学生的学习数据,提供量身定制的学习方案,提高学习效果。
②AI+医疗:智能诊断系统和个性化医疗方案让医疗服务更加精准高效。AI可以分析医学影像,辅助医生进行早期诊断,同时根据患者数据制定个性化治疗方案。
③AI+金融:智能投顾和风险管理系统帮助投资者做出更明智的决策,并实时监控金融市场,识别潜在风险。
…
这些案例表明,学习大模型课程不仅能够提升个人技能,还能为企业带来实际效益,推动行业创新发展。
大模型就业发展前景
根据脉脉发布的《2024年度人才迁徙报告》显示,AI相关岗位的需求在2024年就已经十分强劲,TOP20热招岗位中,有5个与AI相关。 字节、阿里等多个头部公司AI人才紧缺,包括算法工程师、人工智能工程师、推荐算法、大模型算法以及自然语言处理等。
字节、阿里等多个头部公司AI人才紧缺,包括算法工程师、人工智能工程师、推荐算法、大模型算法以及自然语言处理等。
除了上述技术岗外,AI也催生除了一系列高薪非技术类岗位,如AI产品经理、产品主管等,平均月薪也达到了5-6万左右。
AI正在改变各行各业,行动力强的人,早已吃到了第一波红利。
最后
大模型很多技术干货,都可以共享给你们,如果你肯花时间沉下心去学习,它们一定能帮到你!
大模型全套学习资料领取
如果你对大模型感兴趣,可以看看我整合并且整理成了一份AI大模型资料包,需要的小伙伴文末免费领取哦,无偿分享!!!
vx扫描下方二维码即可
加上后会一个个给大家发
部分资料展示
一、 AI大模型学习路线图
整个学习分为7个阶段

二、AI大模型实战案例
涵盖AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,皆可用。


三、视频和书籍PDF合集
从入门到进阶这里都有,跟着老师学习事半功倍。


四、LLM面试题


五、AI产品经理面试题

六、deepseek部署包+技巧大全

😝朋友们如果有需要的话,可以V扫描下方二维码联系领取~

ModelScope旨在打造下一代开源的模型即服务共享平台,为泛AI开发者提供灵活、易用、低成本的一站式模型服务产品,让模型应用更简单!
更多推荐



 20
20 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)