
MiniMax开源超长文本处理神器,魔搭社区助力开发者推理部署
Transfermor架构与生俱来的二次计算复杂度,及其所带来的上下文窗口瓶颈,一直为业界所关注。此前,MiniMax开源了MiniMax-01系列模型,采用创新的线性注意力架构,使得模型能够在100
00.前言
Transfermor架构与生俱来的二次计算复杂度,及其所带来的上下文窗口瓶颈,一直为业界所关注。此前,MiniMax开源了MiniMax-01系列模型,采用创新的线性注意力架构,使得模型能够在100万个token长度的上下文窗口上进行预训练;而在推理时,实现了高效处理全球最长400万token的上下文,是目前最长上下文窗口的20倍。
今天,MiniMax-01系列模型,包括包括文本大模型MiniMax-Text-01 和视觉多模态大模型MiniMax-VL-01,正式上架魔搭社区。
本次上架MiniMax-01全系列模型 ,为开发者提供“开箱即用”的体验,未来双方将进一步深化:
-
工具链优化 :魔搭推出定制化工具,简化模型推理,微调和部署流程;
-
生态共建 :通过教程、案例分享及开发者大赛,推动MiniMax模型在更多行业落地。
论文链接:
https://modelscope.cn/papers/107533
代码链接:
https://github.com/MiniMax-AI
合集链接:
https://modelscope.cn/collections/MiniMax-01-72e71e58917747
体验小程序:
链接:https://modelscope.cn/studios/MiniMax/MiniMax-Text-01
链接:https://modelscope.cn/studios/MiniMax/MiniMax-VL-01
01.最佳实践
使用MS-Swift对MiniMax-01模型推理和部署
环境准备:
pip install optimum-quanto
pip install git+https://github.com/modelscope/ms-swift.git使用swift对MiniMax-Text-01进行推理:
from swift.llm import PtEngine, RequestConfig, InferRequest
from transformers import QuantoConfig
model = 'MiniMax/MiniMax-Text-01'
# 加载推理引擎
quantization_config = QuantoConfig(weights='int8')
engine = PtEngine(model, max_batch_size=2, quantization_config=quantization_config)
request_config = RequestConfig(max_tokens=512, temperature=0)
# 这里使用了2个infer_request来展示batch推理
infer_requests = [
InferRequest(messages=[
{"role": "system", "content": "You are a helpful assistant created by MiniMax based on MiniMax-Text-01 model."},
{'role': 'user', 'content': 'who are you?'}]),
InferRequest(messages=[
{'role': 'user', 'content': '浙江的省会在哪?'},
{'role': 'assistant', 'content': '浙江省的省会是杭州。'},
{'role': 'user', 'content': '这里有什么好玩的地方'}]),
]
resp_list = engine.infer(infer_requests, request_config)
query0 = infer_requests[0].messages[0]['content']
print(f'response0: {resp_list[0].choices[0].message.content}')
print(f'response1: {resp_list[1].choices[0].message.content}')使用swift对MiniMax-VL-01进行推理:
from swift.llm import PtEngine, RequestConfig, InferRequest
from transformers import QuantoConfig
model = 'MiniMax/MiniMax-VL-01'
# 加载推理引擎
quantization_config = QuantoConfig(weights='int8')
engine = PtEngine(model, max_batch_size=2, quantization_config=quantization_config)
request_config = RequestConfig(max_tokens=512, temperature=0, stream=True)
query = '<image><image>两张图的区别是什么?'
infer_requests = [
InferRequest(messages=[{'role': 'user', 'content': query}],
images=['http://modelscope-open.oss-cn-hangzhou.aliyuncs.com/images/cat.png',
'http://modelscope-open.oss-cn-hangzhou.aliyuncs.com/images/animal.png']),
]
# 流式推理
gen_list = engine.infer(infer_requests, request_config)
print(f'query: {query}\nresponse: ', end='')
for resp in gen_list[0]:
if resp is None:
continue
print(resp.choices[0].delta.content, end='', flush=True)
print()显存占用:
服务端部署:
CUDA_VISIBLE_DEVICES=0 swift deploy \
--model MiniMax/MiniMax-VL-01 \
--quant_method quanto \
--quant_bits 8 \
--infer_backend pt \
--served_model_name MiniMax-VL-01 \
--host 0.0.0.0 \
--port 8000 \
--max_new_tokens 2048客户端调用:
from openai import OpenAI
client = OpenAI(
api_key='EMPTY',
base_url=f'http://127.0.0.1:8000/v1',
)
model = client.models.list().data[0].id
print(f'model: {model}')
messages = [{'role': 'user', 'content': [
{'type': 'image', 'image': 'https://modelscope-open.oss-cn-hangzhou.aliyuncs.com/images/cat.png'},
{'type': 'text', 'text': 'describe the image'}
]}]
resp = client.chat.completions.create(model=model, messages=messages, max_tokens=512, temperature=0)
query = messages[0]['content']
response = resp.choices[0].message.content
print(f'query: {query}')
print(f'response: {response}')
02.技术亮点:超长文本处理的“破局者”
MiniMax-Text-01:万亿参数+线性注意力架构
作为国内首个将线性注意力机制(Linear Attention)与 混合专家模型(MoE)结合的开源模型,MiniMax-Text-01参数量高达 4560亿 ,单次激活参数达459亿,专攻超长文本处理难题。
在 MiniMax-01系列模型中,MiniMax研究团队做了大胆创新:首次大规模实现线性注意力机制,传统 Transformer架构不再是唯一的选择。模型综合性能比肩海外顶尖模型,同时能够高效处理全球最长400万token的上下文,是GPT-4o的32倍,Claude-3.5-Sonnet的20倍。
性能突破 :通过创新架构,模型在长文本推理、续写、文案生成等任务中表现优异,效率较传统Transformer提升显著。
场景应用 :无论是复杂逻辑推理还是超长上下文理解,它都能“一气呵成”,为内容创作、智能客服等领域提供强力支持。
MiniMax-VL-01:多模态的“全能选手”
同步开源的视觉多模态模型MiniMax-VL-01,深度融合文本与图像能力,可实现多模态理解。
超长上下文、开启Agent时代
MiniMax研究团队相信2025年会是Agent高速发展的一年,不管是单Agent的系统需要持续的记忆,还是多Agent的系统中Agent之间大量的相互通信,都需要越来越长的上下文。在这个模型中,MiniMax研究团队走出了第一步,并希望使用这个架构持续建立复杂Agent所需的基础能力。
03.模型评测
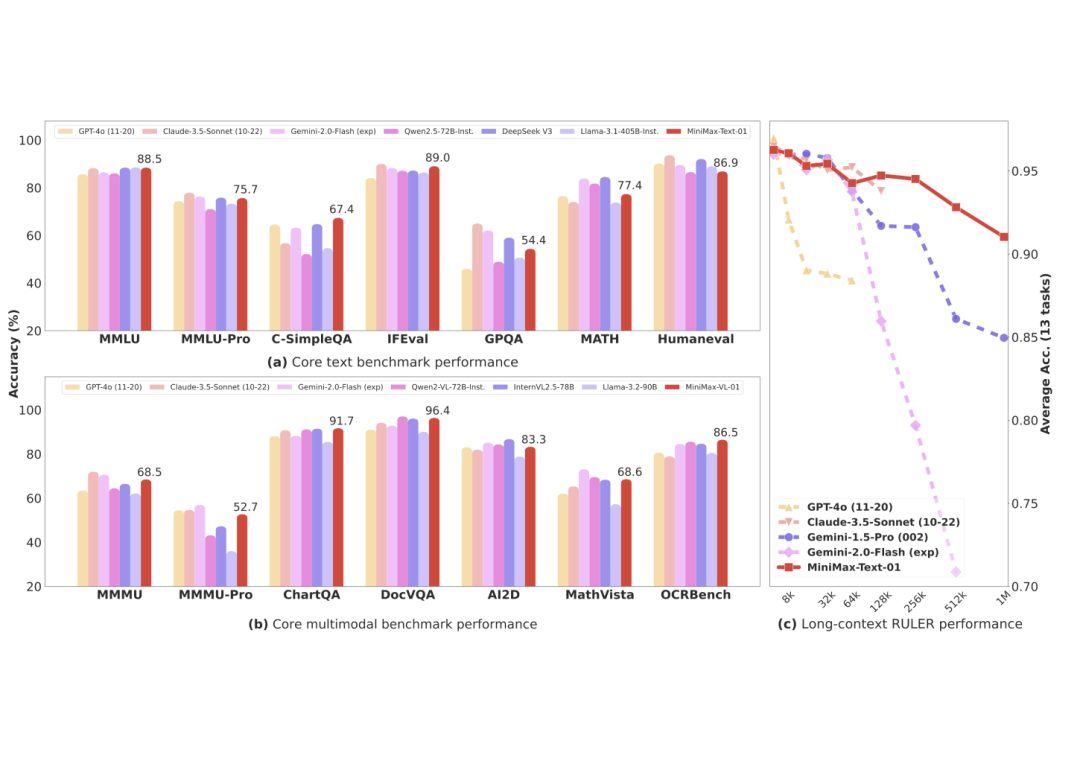
基于业界主流的文本和多模态理解测评结果如下图所示,MiniMax研究团队在大多数任务上追平了海外公认最先进的两个模型,GPT-4o-1120以及Claude-3.5-Sonnet-1022。在长文任务上,MiniMax研究团队对比了之前长文最好的模型 Google的Gemini。如图(c)所示,随着输入长度变长,MiniMax-Text-01 是性能衰减最慢的模型,显著优于Google Gemini。
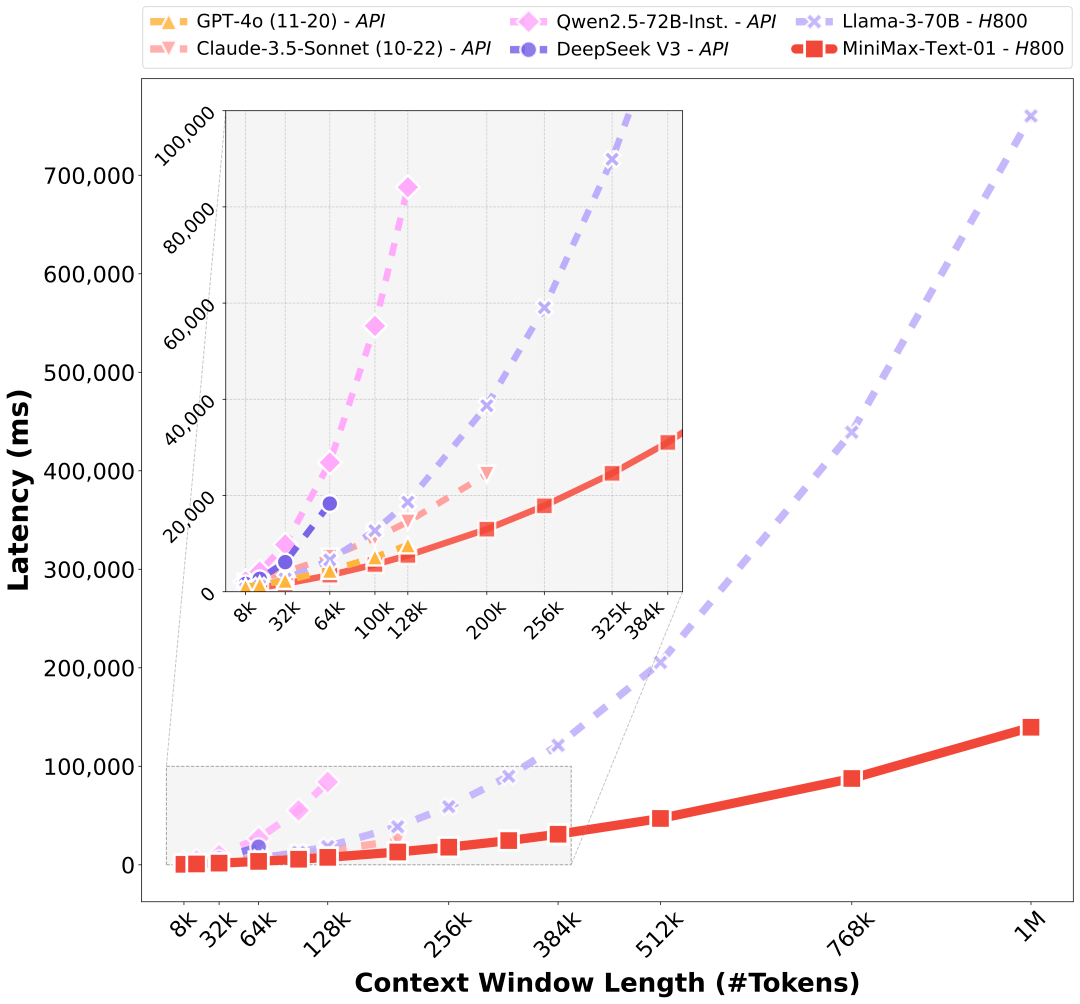
受益于MiniMax研究团队的架构创新,MiniMax研究团队的模型在处理长输入的时候有非常高的效率,接近线性复杂度。和其他全球顶尖模型的对比如下:
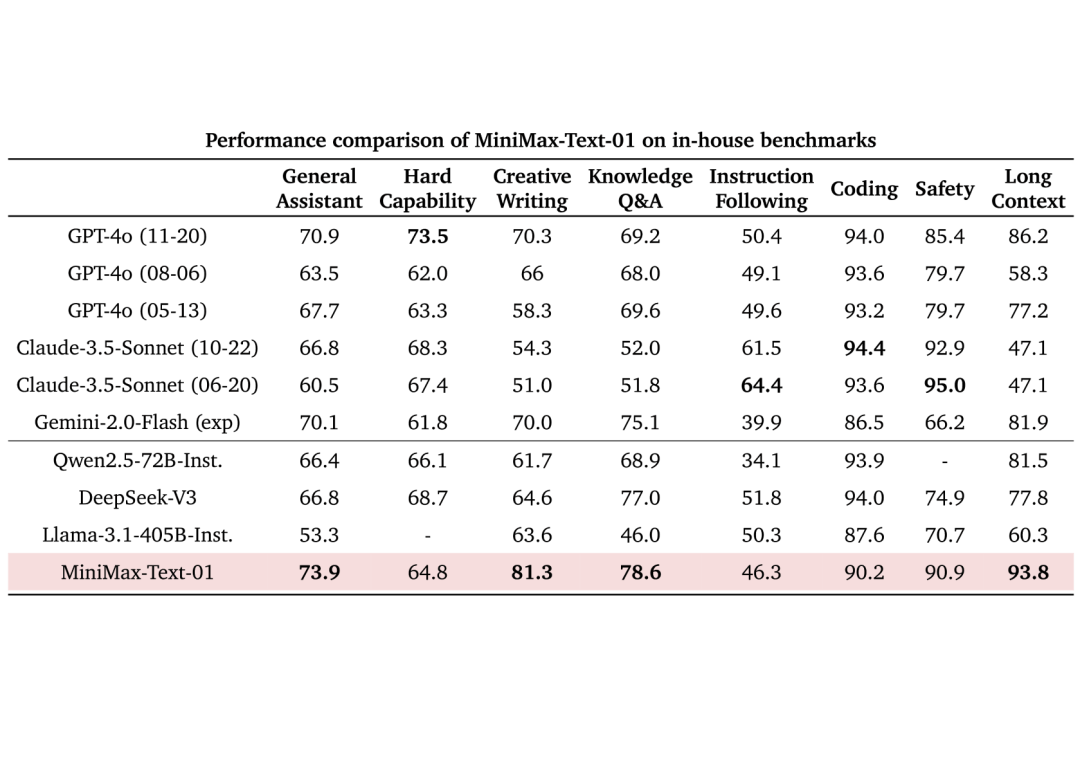
除了学术数据集,MiniMax研究团队构建了一个基于真实数据的助手场景中的测试集。在这个场景中,MiniMax-Text-01的模型表现显著领先,具体的对比如下:
在多模态理解的测试集中,MiniMax-VL-01的模型也较为领先:
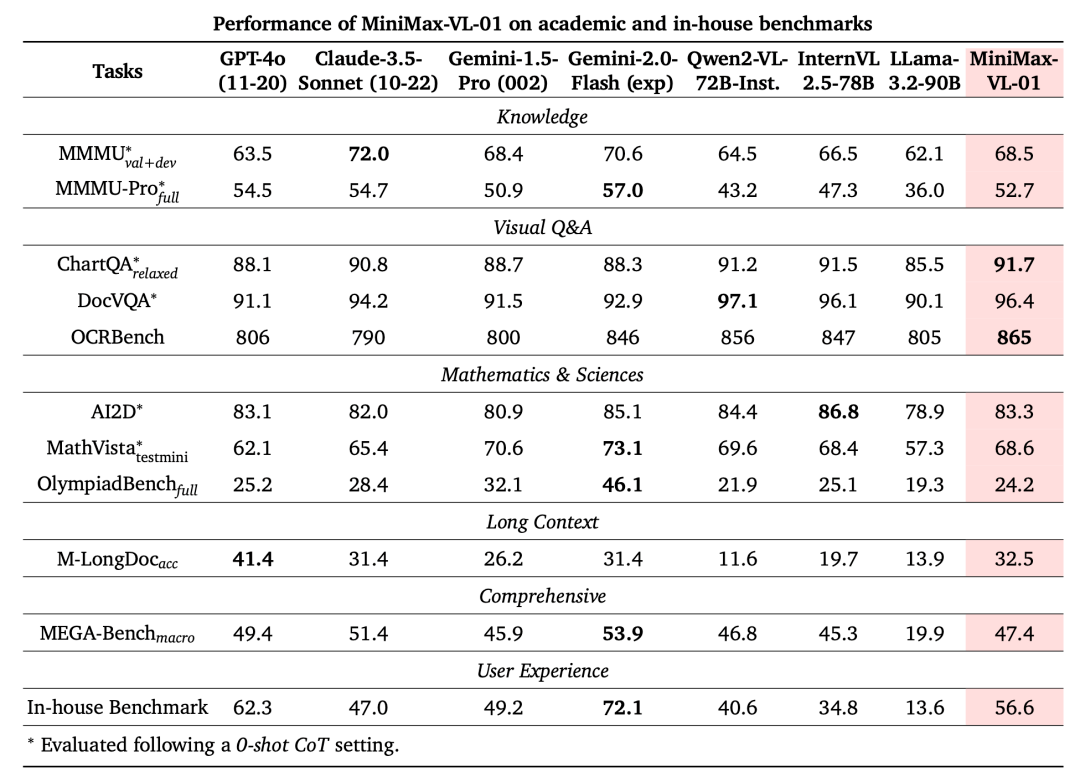
为方便开发者做更多的研究,MiniMax研究团队开源了两个模型的完整权重。这一系列模型的后续更新,包括代码和多模态相关的后续强化,MiniMax研究团队会第一时间上传魔搭社区。
04.模型结构
MiniMax研究团队使用的结构如下,其中每8层中有7个是基于Lightning Attention的线性注意力,有一层是传统的SoftMax注意力。
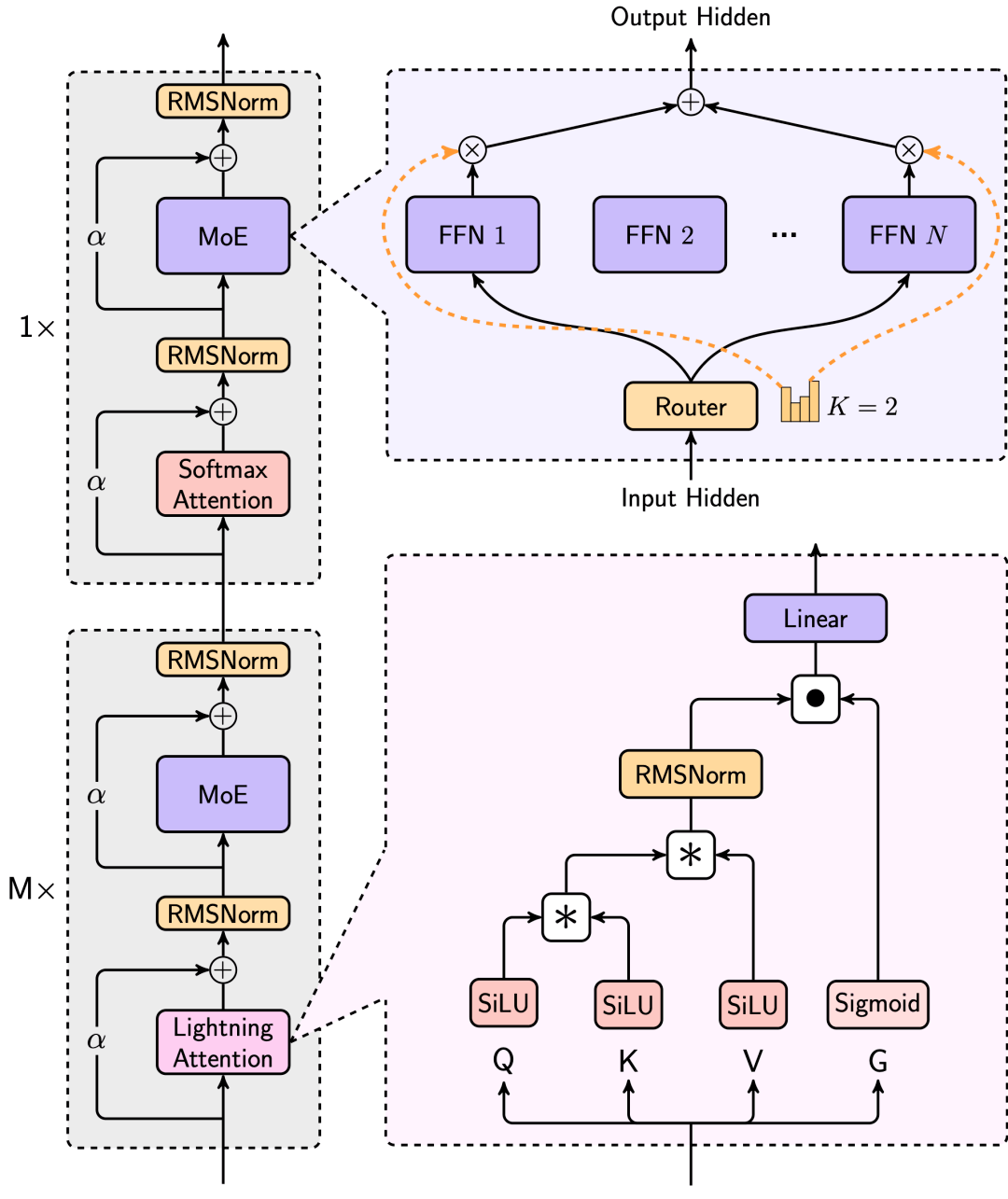
这是业内第一次把线性注意力机制扩展到商用模型的级别,MiniMax研究团队从Scaling Law、与MoE的结合、结构设计、训练优化和推理优化等层面做了综合的考虑。由于是业内第一次做如此大规模的以线性注意力为核心的模型,MiniMax研究团队几乎重构了训练和推理系统,包括更高效的MoE All-to-all通讯优化、更长的序列的优化,以及推理层面线性注意力的高效Kernel实现。
点击链接,即可跳转合集~

ModelScope旨在打造下一代开源的模型即服务共享平台,为泛AI开发者提供灵活、易用、低成本的一站式模型服务产品,让模型应用更简单!
更多推荐



 2
2 0
0- 0



 已为社区贡献652条内容
已为社区贡献652条内容

所有评论(0)