
今日AI论文推荐:ReCamMaster、PLADIS、SmolDocling、FlowTok
由浙江大学、快手科技等机构提出的ReCamMaster是一个相机控制的生成式视频重渲染框架,可以使用新的相机轨迹重现输入视频的动态场景。该工作的核心创新在于利用预训练的文本到视频模型的生成能力,通过一

作者:InternLM、Qwen 等 LLM每日一览热门论文版,顶会选题投稿不迷惘。开来看看由「机智流」和「ModelScope」社区今天推荐的论文吧!!!
ReCamMaster: Camera-Controlled Generative Rendering from A Single Video
论文链接:
https://www.modelscope.cn/papers/127016
简要介绍:由浙江大学、快手科技等机构提出的ReCamMaster是一个相机控制的生成式视频重渲染框架,可以使用新的相机轨迹重现输入视频的动态场景。该工作的核心创新在于利用预训练的文本到视频模型的生成能力,通过一种简单但强大的视频条件机制。为克服高质量训练数据的稀缺问题,研究者使用虚幻引擎5构建了一个全面的多相机同步视频数据集,涵盖多样化的场景和相机运动。
核心图片:

PLADIS: Pushing the Limits of Attention in Diffusion Models at Inference Time by Leveraging Sparsity
论文链接:
https://modelscope.cn/papers/125501
简要介绍:由三星研究院提出的PLADIS是一种新颖高效的方法,通过利用稀疏注意力提升预训练模型(U-Net/Transformer)性能。该方法在推理过程中使用softmax及其稀疏对应物在交叉注意力层中外推查询-键相关性,无需额外训练或神经函数评估(NFEs)。PLADIS通过利用稀疏注意力的噪声鲁棒性,释放了文本到图像扩散模型的潜在潜力,使其在曾经表现不佳的领域中也能展现新的有效性。
核心图片:

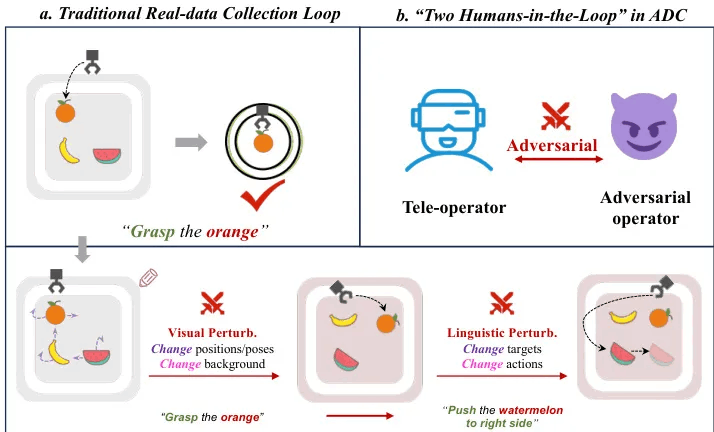
Adversarial Data Collection: Human-Collaborative Perturbations for Efficient and Robust Robotic Imitation Learning
论文链接:
https://www.modelscope.cn/papers/126948
简要介绍:这项研究提出了对抗性数据收集(ADC),一种人在环(HiL)框架,通过实时双向人机互动重新定义机器人数据获取。与传统被动记录静态演示的管道不同,ADC采用协作扰动范式:在单个场景中,对抗操作员动态改变物体状态、环境条件和语言命令,而远程操作员适应性地调整行动以克服这些不断变化的挑战。这个过程将多样化的失败-恢复行为、组合任务变化和环境扰动压缩到最少的演示中。
核心图片:
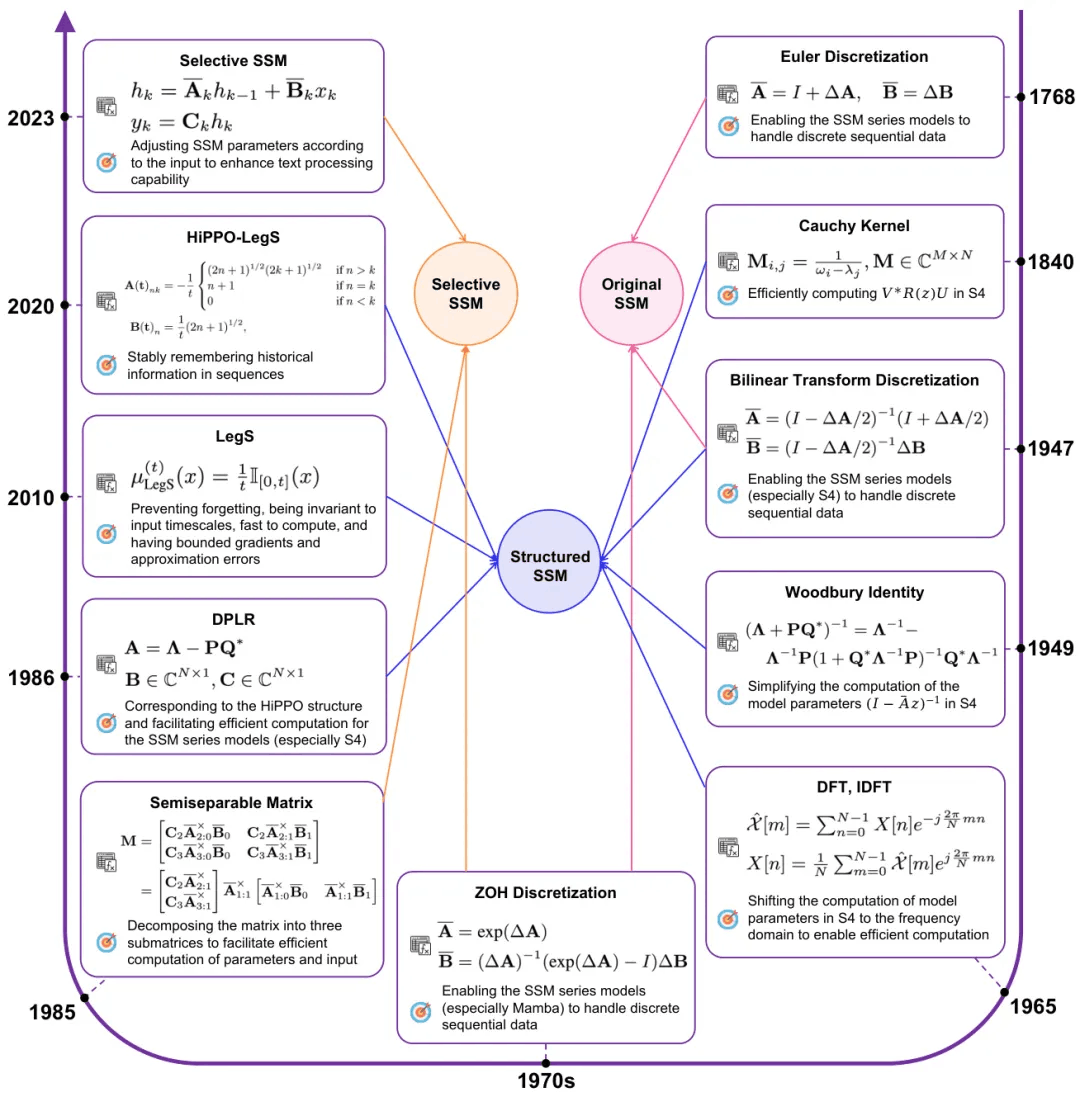
Technologies on Effectiveness and Efficiency: A Survey of State Spaces Models
论文链接:
https://www.modelscope.cn/papers/126955
简要介绍:由清华大学等机构提出的这项调查研究系统地总结了状态空间模型(SSMs)。SSMs已成为流行的Transformer模型的有前景的替代方案,并受到越来越多的关注。与Transformer相比,SSMs在处理序列数据或更长上下文的任务上表现出色,在保持相当性能的同时显著提高了效率。该调查将SSM系列分为三个主要部分:原始SSM、由S4代表的结构化SSM和以Mamba为代表的选择性SSM。
核心图片:
API Agents vs. GUI Agents: Divergence and Convergence
论文链接:
https://www.modelscope.cn/papers/126771
简要介绍:由微软研究团队提出的这项研究是首个API代理和GUI代理的全面比较研究,系统分析了它们的分歧和潜在融合。大型语言模型(LLMs)已经超越了简单的文本生成,为直接将自然语言命令转换为实际行动的软件代理提供动力。虽然基于API的LLM代理因其强大的自动化能力和与编程端点的无缝集成而最初崭露头角,但多模态LLM研究的最新进展促成了基于GUI的LLM代理,它们以类似人类的方式与图形用户界面交互。
核心图片:

Exploring the Vulnerabilities of Federated Learning: A Deep Dive into Gradient Inversion Attacks
论文链接:
https://huggingface.co/papers/2503.11514
简要介绍:该研究全面系统地回顾了梯度反演攻击(GIA),并将现有方法分为三类:基于优化的GIA(OP-GIA)、基于生成的GIA(GEN-GIA)和基于分析的GIA(ANA-GIA)。联邦学习(FL)作为一种有前景的隐私保护协作模型训练范式已经崭露头角,无需共享原始数据。然而,最近的研究表明,私人信息仍然可以通过共享梯度信息泄漏,并受到梯度反演攻击(GIA)的攻击。

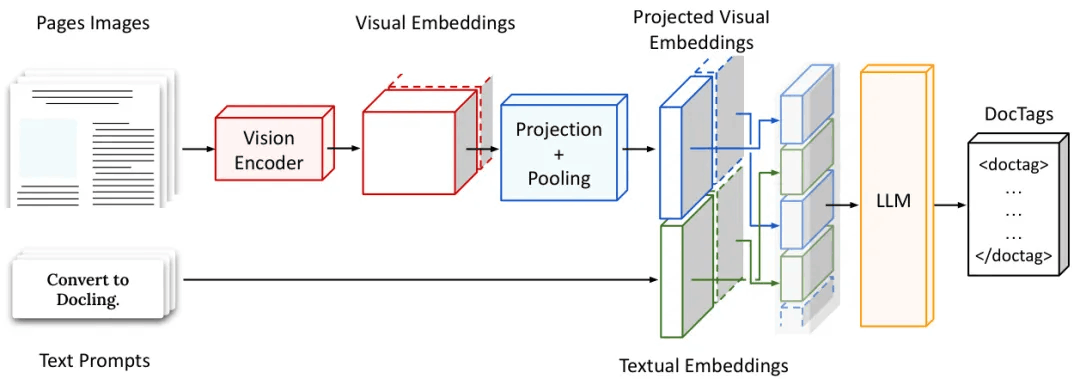
SmolDocling: An ultra-compact vision-language model for end-to-end multi-modal document conversion
论文链接:
https://www.modelscope.cn/papers/127088
简要介绍:由IBM Research和HuggingFace团队提出的SmolDocling是一个超紧凑视觉语言模型,专注于端到端文档转换。该模型通过生成DocTags(一种新的通用标记格式)来全面处理整个页面,捕捉所有页面元素及其完整上下文和位置信息。与现有的依赖大型基础模型的方法不同,SmolDocling提供了一个端到端的转换解决方案,在256M参数的视觉语言模型中准确捕捉文档元素的内容、结构和空间位置。
核心图片:
FlowTok: Flowing Seamlessly Across Text and Image Tokens
论文链接:
https://www.modelscope.cn/papers/126758
简要介绍:由字节跳动和约翰霍普金斯大学研究团队提出的FlowTok是一个最小化框架,通过将图像编码成紧凑的1D标记表示,实现文本和图像之间的无缝流动。与传统方法将文本视为条件信号逐渐引导从高斯噪声到目标图像的去噪过程不同,FlowTok探索了一种更简单的范式——通过流匹配直接在文本和图像模态之间演化,这需要将两种模态投影到共享潜空间中。
核心图片:

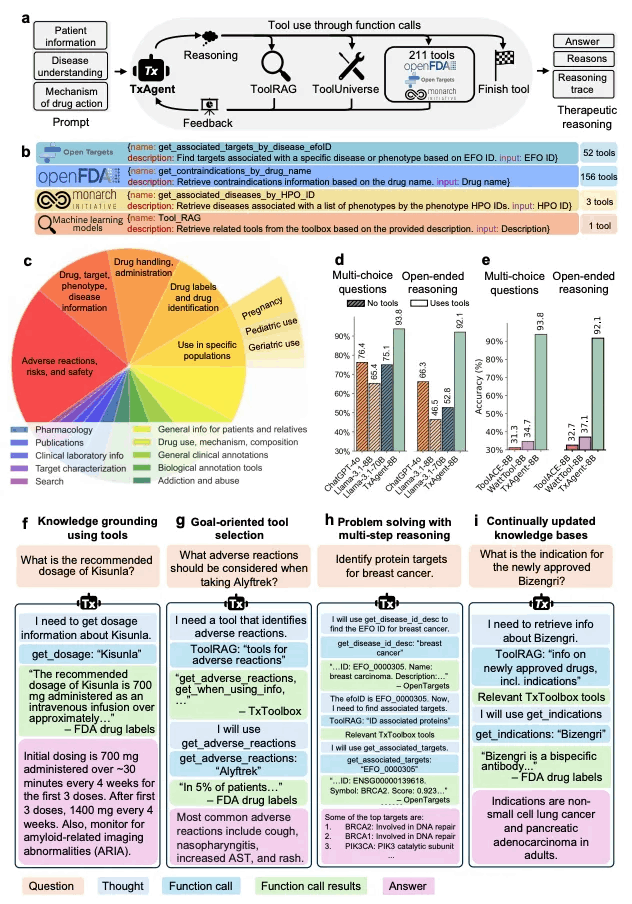
TxAgent: An AI Agent for Therapeutic Reasoning Across a Universe of Tools
论文链接:
https://www.modelscope.cn/papers/127064
简要介绍:由哈佛医学院等机构提出的TxAgent是一个AI代理,利用多步推理和实时生物医学知识检索,跨211个工具的工具箱分析药物相互作用、禁忌症和患者特定治疗策略。TxAgent在分子、药代动力学和临床层面评估药物相互作用,根据患者合并症和并发药物识别禁忌症,并根据个体患者特征(包括年龄、遗传因素和疾病进展)量身定制治疗策略。
Large-scale Pre-training for Grounded Video Caption Generation
论文链接:
https://www.modelscope.cn/papers/126916
简要介绍:用于视频中的字幕和对象定位,其中字幕中的对象通过时间密集的边界框在视频中被定位。研究者提出了一种大规模自动标注方法,将带有边界框的字幕从单个帧聚合到时间密集且一致的边界框标注中。他们将这种方法应用于HowTo100M数据集,构建了一个大规模预训练数据集HowToGround1M,并提出了一个名为GROVE的视频字幕生成模型。
核心图片:

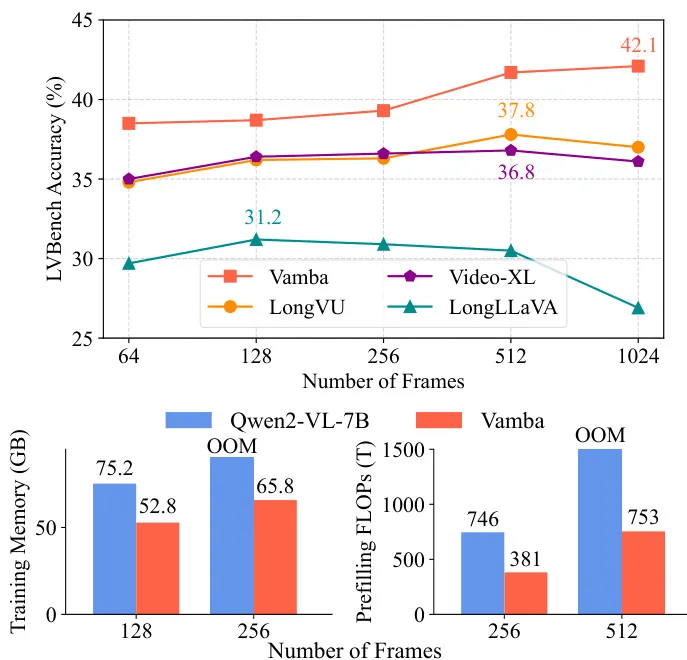
Vamba: Understanding Hour-Long Videos with Hybrid Mamba-Transformers(9票)
论文链接:
https://www.modelscope.cn/papers/126998
简要介绍:由滑铁卢大学、多伦多大学和01.AI联合提出的VAMBA是一种混合Mamba-Transformer模型,采用线性复杂度的Mamba-2块来编码视频标记。不需要任何标记减少,VAMBA可以在单个GPU上编码超过1024帧(640×360)的视频,而基于transformer的模型只能编码256帧。在长视频输入方面,VAMBA在训练和推理过程中实现了至少50%的GPU内存使用量减少,并且每个训练步骤的速度几乎是基于transformer的LMMs的两倍。
核心图片:
-- 完 --

ModelScope旨在打造下一代开源的模型即服务共享平台,为泛AI开发者提供灵活、易用、低成本的一站式模型服务产品,让模型应用更简单!
更多推荐



 2
2 0
0- 0



 已为社区贡献652条内容
已为社区贡献652条内容

所有评论(0)