

CLIPer:开创性框架提升CLIP空间表征,实现开放词汇语义分割突破
对比语言-图像预训练(CLIP)在多种图像级任务上表现出强大的零样本分类能力,促使研究行人尝试将CLIP应用于像素级开放词汇语义分割,而无需额外训练。关键在于提升图像级CLIP的空间表征能力,例如,用
论文链接:
https://arxiv.org/abs/2411.13836
模型链接:
https://modelscope.cn/studios/sunlin449/CLIPer
01.论文解读
对比语言-图像预训练(CLIP)在多种图像级任务上表现出强大的零样本分类能力,促使研究行人尝试将CLIP应用于像素级开放词汇语义分割,而无需额外训练。关键在于提升图像级CLIP的空间表征能力,例如,用自-自注意力图或基于视觉基础模型的自注意力图替换最后一层的自注意力图。本文提出了一种新颖的分层框架CLIPer,该框架分层提升了CLIP的空间表征能力。
CLIPer包括浅层融合模块和精细补偿模块。浅层融合模块包括嵌入浅层特征和注意力图以保留空间结构信息,生成具有更好空间一致性的分割图。精细补偿模块利用扩散模型的自注意力图来补偿局部细节。本文在七个分割数据集上进行了实验,并在这些数据集上实现了最先进的性能。在不采用使用滑动窗口的策略下,使用ViT-L模型,CLIPer在VOC和COCO Object任务上的mIoU分别达到69.8%和43.3%,分别高出ProxyCLIP模型9.2%和4.1%。
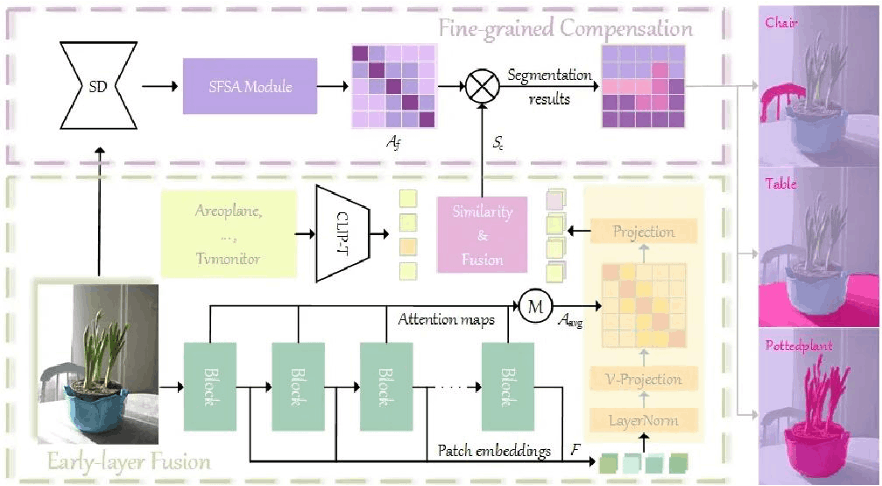
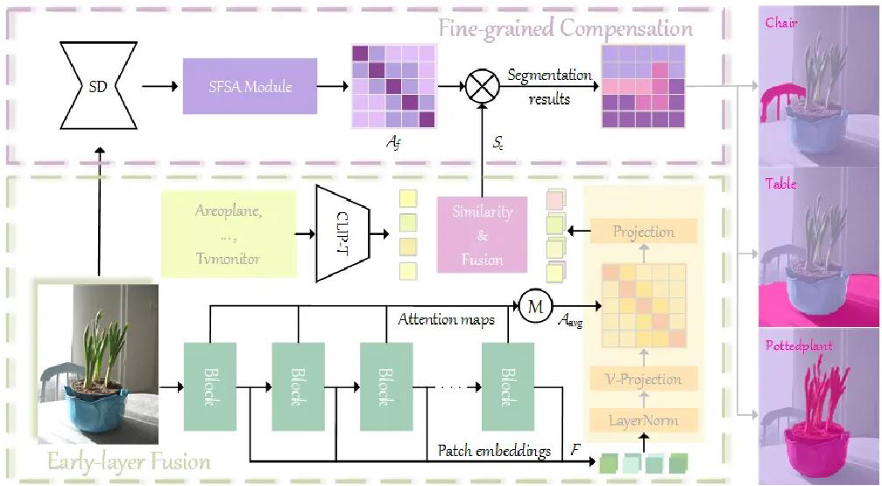
方法描述
CLIPer方法有以下几个关键步骤:
1.最后一层注意力机制的弥补:原始的CLIP图像编码器最后一层缺乏空间特性,CLIPer通过利用浅层空间连续性强的特性,将浅层的多头注意力图直接融合至最后一层中,并去掉了残差连接以及前向传播网络,以提高最终分割的连续性。
2.浅层特征的提取:在每次经过CLIP图像编码时,CLIPer会记录所有Transformer块的特征,并将这些特征送入到修改后的最后一层,并分别与文本特征计算相似度,得到分割结果。
3.精细补偿机制:CLIPer提出将扩散模型中的细节融入到分割中。该模块利用扩散模型中的多头自注意力头蕴含的细节信息,通过矩阵链乘法的形式去优化粗糙的分割结果。
论文实验
本文对CLIPer与一些最先进的方法在各种数据集上的表现进行了比较。当使用ViT-B和ViT-L两种框架时,CLIPer几乎在所有这些数据集上都达到了最佳性能。
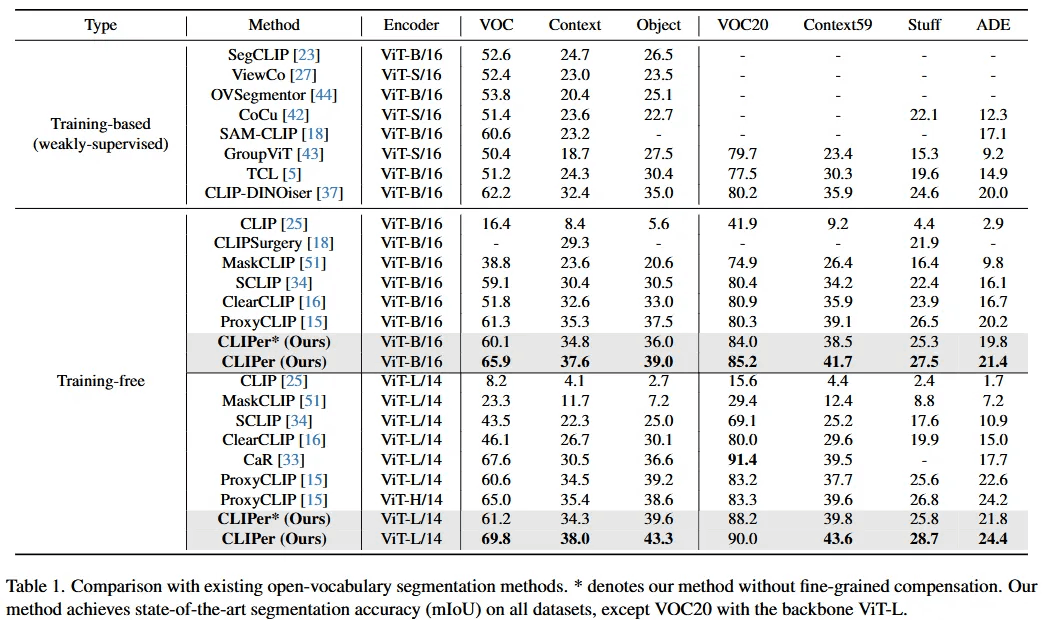
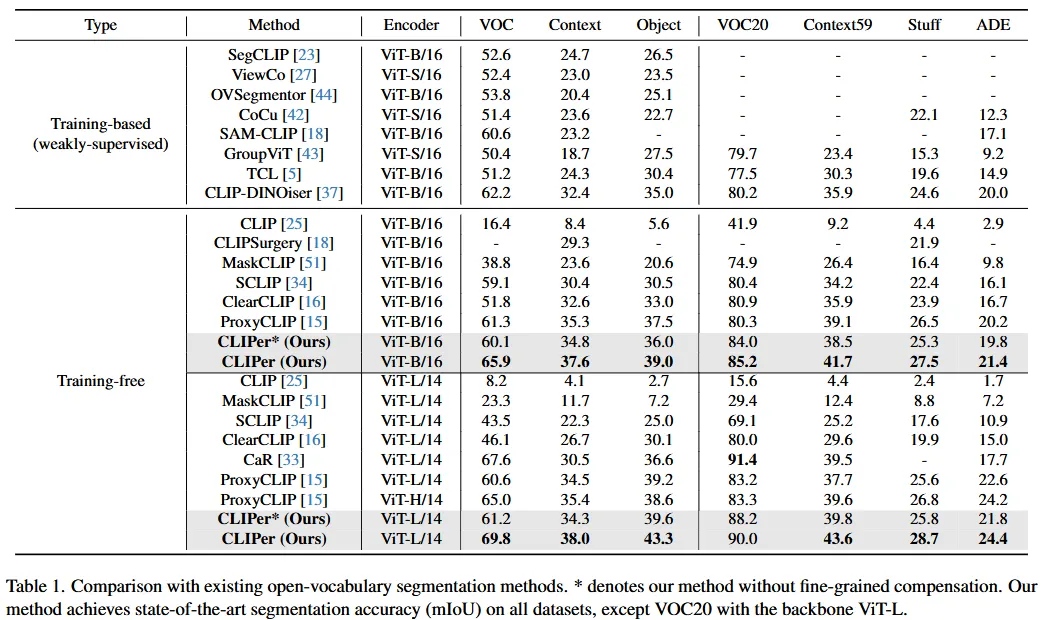
另外,本文还将开放词汇语义分割可以看作是两个方面:类别分类和掩码预测。为了深入展示CLIPer在这两个方面上的优势,本文通过两个实验与其他方法进行了更多比较。
正在上传…重新上传取消
正在上传…重新上传取消
正在上传…重新上传取消
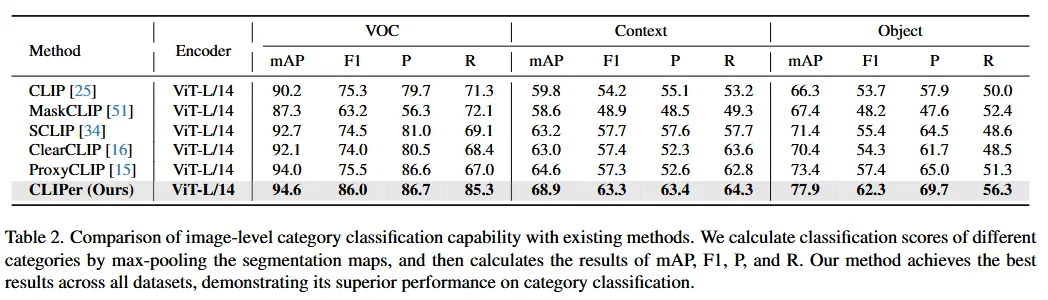
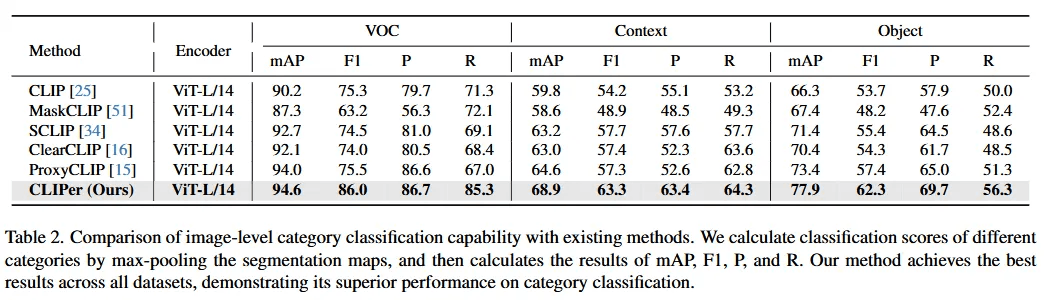
本文第一个实验结果的图像级分类的形式展示了CLIPer的分类能力,通过表二可以得出CLIPer取得更优的mAP、F1、P和R分数,表明在类别分类上表现更好,这对于开放词汇语义分割非常有用。
本文的第二个实验通过弱监督的设置展示了CLIPer的分割能力,通过表三可以得出,CLIPer在弱监督设置中较其他方式取得更优的mIoU分数,说明具备更好的分割能力。
对于推理时间,与ClearCLIP相比,CLIPer*具有更快的速度和更高的mIoU。与ProxyCLIP相比,CLIPer*具有更快的速度和可比的mIoU。此外,CLIPer通过细粒度补偿显著提升了CLIPer*的性能。
本文也有一系列的消融实验。具体包括:
1. 单独只使用浅层特征融合模块(CLIPer*),单独只使用精细补偿模块,以及两者同时具备(CLIPer)的情况,发现每一个模块均能单独提升分割结果,并且同时使用两者能更进一步的提升效果。
2. 进一步的消融浅层特征融合模块,展示了只融合浅层特征,只融合自注意力,以及同时融合两者同同条件下使用q-q,k-k,v-v的对比,得出这两种融合的有效性。
3. 在精细补偿中,本文也探讨了如何融合扩散模型自注意力图,包括选取其中一个自注意力图,平均所有自注意力图以及将所有自注意力图做矩阵链乘法,得出矩阵链乘法能显著的提升分割精度的结果。
02.最佳实践
CLIPer在魔搭社区上进行了部署,在魔搭社区免费提供的GPU免费算力上可体验CLIPer。
体验地址:
https://modelscope.cn/studios/sunlin449/CLIPer
运行结果:

点击链接即可跳转模型~

ModelScope旨在打造下一代开源的模型即服务共享平台,为泛AI开发者提供灵活、易用、低成本的一站式模型服务产品,让模型应用更简单!
更多推荐


 0
0 0
0- 0



 已为社区贡献602条内容
已为社区贡献602条内容

所有评论(0)