
Kimi开源Moonlight-16B-A3B:基于Muon优化器的高效大模型,性能与效率双突破!
最近,Muon优化器在训练小规模语言模型方面展示了强大的效果,但其在大规模模型上的可扩展性尚未得到验证。
01.前言
最近,Muon优化器在训练小规模语言模型方面展示了强大的效果,但其在大规模模型上的可扩展性尚未得到验证。Kimi确定了两种扩展Muon的关键技术:
|
权重衰减:对划分更大模型至关重要 |
|
一致的RMS更新:在模型更新中保持一致的均方根 |
这些技术使Muon能够在大规模训练中开箱即用,消耗超参数调优。扩展调整实验表明,在计算最优化训练中,Muon因而通常默认使用的AdamW优化器,能够提供高约2倍的样本效率。
基于这些改进,Kimi基于Muon训练了Moonlight-16B-A3B系列模型。这是一个配备16B参数(激活参数为3B)的专家混合(MoE)模型,使用5.7T个token数据训练得到。该模型模型改进了当前累的帕托前沿,与的模型相比,使用更少的训练FLOPs可以在之前实现更好的性能。
同时Kimi开源了内存优化和通信效率高的Muon实现,还发布了预训练、配置配置和中间检查点,以支持未来的研究。
所有代码可在MoonshotAI/Moonlight获取。
代码链接:
https://github.com/MoonshotAI/Moonlight
模型链接:
-
月光-16B-A3B
https://modelscope.cn/models/moonshotai/Moonlight-16B-A3B
-
月光-16B-A3B-说明
https://modelscope.cn/models/moonshotai/Moonlight-16B-A3B-Instruct
体验链接:
https://www.modelscope.cn/studios/moonshotai/Moonlight-16B-Demo/summ ary
技术贡献包括:
|
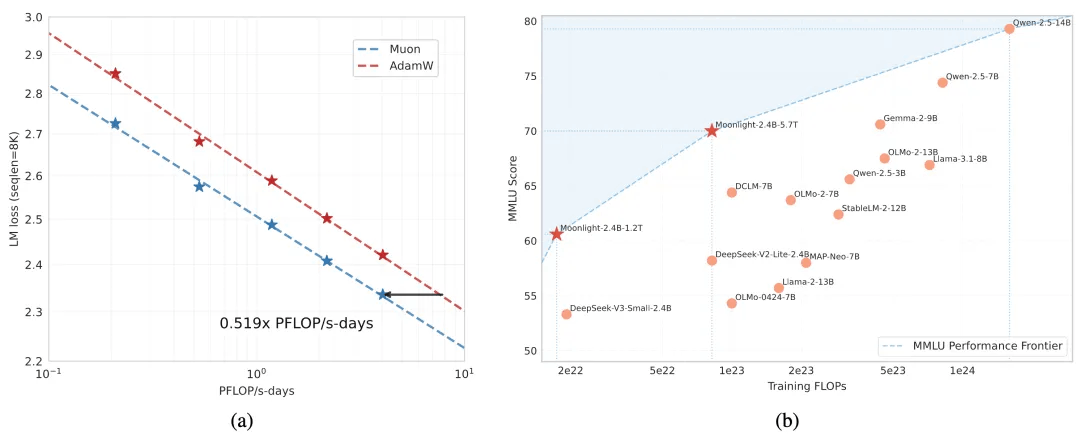
Muon的扩展
(a) 比较Muon和Adam的扩展动作实验,Muon的样本效率是Adam的2倍;
(b) Moonlight模型(使用Muon优化)与其他可比较模型在MMLU上的表现。
Moonlight在性能与训练FLOPs的权衡上推进了帕累托前沿。
02.特性
将Moonlight与类似规模的SOTA公开模型进行了比较:
-
LLAMA3-3B是一个使用9T个令牌训练的3B参数密集模型
-
Qwen2.5-3B是一个使用18T个代币训练的3B参数密集模型
-
Deepseek-v2-Lite是一个使用5.7T代币训练的2.4B/16B参数MOE模型
|
|
基准测试(指标) |
骆驼3.2-3B |
Qwen2.5-3B |
DSV2-Lite |
月光 |
|
|
啟動參數 † |
2.81亿 |
2.77亿 |
2.24B |
2.24B |
|
|
一般参数† |
2.81亿 |
2.77亿 |
15.29B |
15.29B |
|
|
训练token数 |
9T |
18T |
5.7T |
5.7T |
|
|
优化器 |
亚当·W |
* |
亚当·W |
介子 |
|
英语 |
莫尔登大学 |
54.75 |
65.6 |
58.3 |
70.0 |
|
|
MMLU-pro |
25.0 |
34.6 |
25.5 |
42.4 |
|
|
百比黑 |
46.8 |
56.3 |
44.1 |
65.2 |
|
|
琐事QA‡ |
59.6 |
51.1 |
65.1 |
66.3 |
|
代碼 |
人力评估 |
28.0 |
42.1 |
29.9 |
48.1 |
|
|
马来西亚公共服务局 |
48.7 |
57.1 |
43.2 |
63.8 |
|
数学 |
GSM8K |
34.0 |
79.1 |
41.1 |
77.4 |
|
|
数学 |
8.5 |
42.6 |
17.1 |
45.3 |
|
|
数学 |
- |
80.0 |
58.4 |
81.1 |
|
English 中文 |
C-评估 |
- |
75.0 |
60.3 |
77.2 |
|
|
加拿大蒙特利尔大学 |
- |
75.0 |
64.3 |
78.2 |
03.模型推理
思考代码
from modelscope import AutoModelForCausalLM, AutoTokenizer
model_name = "moonshotai/Moonlight-16B-A3B-Instruct"
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype="auto",
device_map="auto",
trust_remote_code=True,
)
tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)
prompt = "1+1=2, 1+2="
inputs = tokenizer(prompt, return_tensors="pt", padding=True, truncation=True).to(model.device)
generated_ids = model.generate(**inputs, max_new_tokens=100)
response = tokenizer.batch_decode(generated_ids)[0]
print(response)显存消耗:
04.Muon优化器微调
ms-swift第一时间提供了Muon优化器的对接。ms-swift是魔搭社区提供的,大模型训练部署框架,其开源地址为:https://github.com/modelscope/ms-swift
目前moonshotai/Moonlight-16B-A3B系列MoE模型不再支持进一步的扭矩(由于topk_method='noaux_tc'),我们选择使用由Moonshot改进的muon优化器,来实现密集模型的动作。具体而言,在以下示例中,我们采用了Qwen2.5-7B-Instruct,来验证通过swift进行基于Muon优化器的扭矩训练。
在开始之前,请确保您的环境已准备就绪。
# pip install git+https://github.com/modelscope/ms-swift.git
git clone https://github.com/modelscope/ms-swift.git
cd ms-swift
pip install -e .微脚本如下:
# 17GB
# ref: https://github.com/MoonshotAI/Moonlight/blob/master/examples/toy_train.py
CUDA_VISIBLE_DEVICES=0 \
swift sft \
--model Qwen/Qwen2.5-7B-Instruct \
--train_type lora \
--dataset 'AI-ModelScope/alpaca-gpt4-data-zh#500' \
'AI-ModelScope/alpaca-gpt4-data-en#500' \
'swift/self-cognition#500' \
--optimizer muon \
--torch_dtype bfloat16 \
--num_train_epochs 1 \
--per_device_train_batch_size 1 \
--per_device_eval_batch_size 1 \
--learning_rate 1e-4 \
--lora_rank 8 \
--lora_alpha 32 \
--target_modules all-linear \
--gradient_accumulation_steps 16 \
--eval_steps 50 \
--save_steps 50 \
--save_total_limit 5 \
--logging_steps 5 \
--max_length 2048 \
--output_dir output \
--system 'You are a helpful assistant.' \
--warmup_ratio 0.05 \
--dataloader_num_workers 4 \
--model_author swift \
--model_name swift-robot活动显存消耗:

如果要使用自定义数据集进行训练,可以参考以下格式,并指定`--dataset <dataset_path>`。
{"messages": [{"role": "user", "content": "浙江的省会在哪?"}, {"role": "assistant", "content": "浙江的省会在杭州。"}]}
{"messages": [{"role": "system", "content": "你是个有用无害的数学计算器"}, {"role": "user", "content": "1+1等于几"}, {"role": "assistant", "content": "等于2"}, {"role": "user", "content": "再加1呢"}, {"role": "assistant", "content": "等于3"}]}训练完成后,使用以下命令对训练后的权重进行推理:
提示:这里的`--adapters`需要替换生成训练生成的最后一个检查点文件夹。由于adapters文件夹中包含了训练的参数文件`args.json`,因此不需要额外指定`--model`,swift会自动读取这些参数。如果要关闭此行为,可以设置`--load_args false`。
CUDA_VISIBLE_DEVICES=0 \
swift infer \
--adapters output/vx-xxx/checkpoint-xxx \
--stream true \
--temperature 0训练效果:

扔模型到ModelScope:
CUDA_VISIBLE_DEVICES=0 \
swift export \
--adapters output/vx-xxx/checkpoint-xxx \
--push_to_hub true \
--hub_model_id '<your-model-id>' \
--hub_token '<your-sdk-token>'
点击链接体验~
https://www.modelscope.cn/studios/moonshotai/Moonlight-16B-Demo/summary

ModelScope旨在打造下一代开源的模型即服务共享平台,为泛AI开发者提供灵活、易用、低成本的一站式模型服务产品,让模型应用更简单!
更多推荐


 0
0 0
0- 0



 已为社区贡献651条内容
已为社区贡献651条内容

所有评论(0)