
阿里国际Ovis2系列模型开源:多模态大语言模型的新突破
Ovis是阿里巴巴国际化团队提出的新型多模态大模型架构,通过巧妙地将视觉和文本嵌入进行结构化对齐,为解决模态间嵌入策略差异这一局限性提供了方案。
01.背景
Ovis是阿里巴巴国际化团队提出的新型多模态大模型架构,通过巧妙地将视觉和文本嵌入进行结构化对齐,为解决模态间嵌入策略差异这一局限性提供了方案。Ovis2作为Ovis系列模型的最新版本,相较于前序1.6版本,在数据构造和训练方法上都有显著改进。它不仅强化了小规模模型的能力密度,还通过指令微调和偏好学习大幅提升了思维链(CoT)推理能力。值得一提的是,Ovis2引入了视频和多图像处理能力,并增强了多语言能力和复杂场景下的OCR能力,这些进步显著提升了模型的实用性。
Ovis2现已开源1B、2B、4B、8B、16B和34B六个版本,各个参数版均达到同尺寸SOTA,为不同应用场景提供了丰富的选择。其中,Ovis2-34B在权威评测榜单OpenCompass上展现出了卓越的性能。在多模态通用能力榜单上,Ovis2-34B位列所有开源模型第二,以不到一半的参数尺寸超过了诸多70B开源旗舰模型。在多模态数学推理榜单上,Ovis2-34B位列所有开源模型第一,并且在其他尺寸上也展现出出色的推理能力。这些成绩不仅证明了Ovis架构的有效性,也展示了开源社区在推动多模态大模型发展方面的巨大潜力。
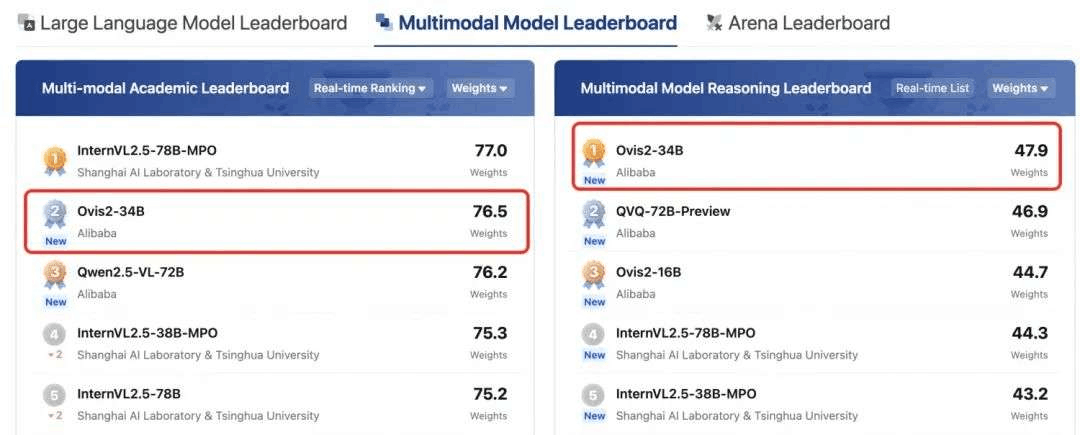
我们坚信,开源是推动AI技术进步的关键力量。通过公开分享Ovis研究成果,我们期待与全球开发者共同探索多模态大模型的前沿,激发更多创新应用。
代码:
https://github.com/AIDC-AI/Ovis
模型:
https://modelscope.cn/collections/Ovis2-1e2840cb4f7d45
Demo:
https://huggingface.co/spaces/AIDC-AI/Ovis2-16B
arXiv:
https://arxiv.org/abs/2405.20797
02.模型架构
多模态大模型通常基于预训练的LLM和视觉模块构建。这两个模块采用不同的嵌入策略:文本嵌入是从LLM的嵌入查找表中索引得到的,其中文本词表的每个“单词”通过独热文本token映射到一个嵌入向量。相比之下,视觉嵌入通常由视觉编码器经MLP连接器投影后以非结构化方式直接生成。这种模态间嵌入策略的结构性差异可能会限制模型的整体性能。为了克服这一潜在的局限性,我们提出了一种名为Ovis的创新架构,旨在实现结构化的嵌入对齐,进一步推动开源多模态大模型领域的发展。
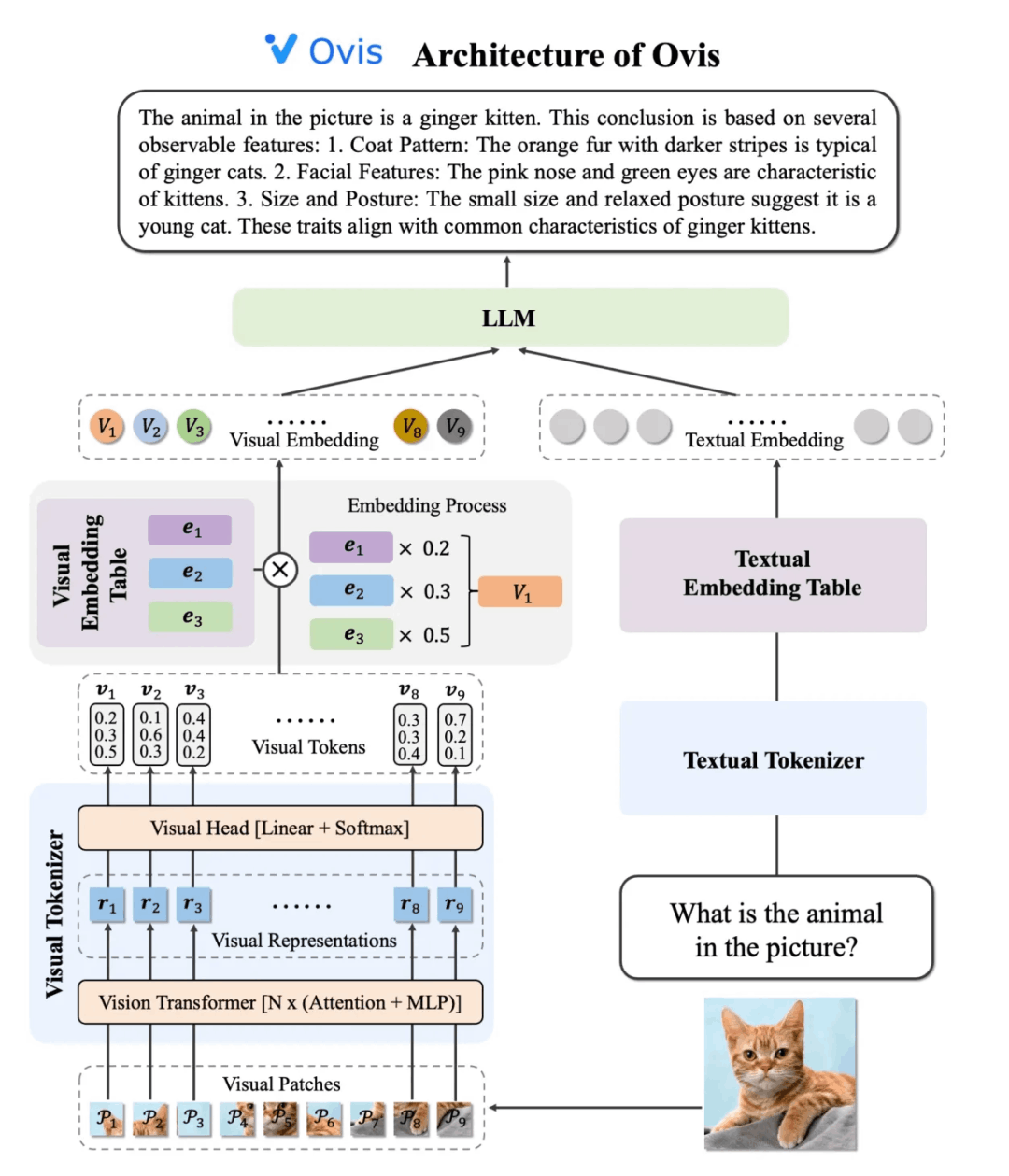
Ovis架构由三个关键组件构成:视觉tokenizer、视觉嵌入表和LLM。
1. 视觉tokenizer:首先,Ovis将输入图像分割成多个图像块 (patch),利用视觉Transformer提取每个图像块的特征表示。随后,通过视觉头层将每个图像块的特征匹配到各个“视觉单词”上,得到其在整个视觉词表上的概率分布,即概率化的视觉token。
2. 视觉嵌入表:类似于LLM中的文本嵌入表,Ovis的视觉嵌入表存储着每个视觉单词对应的嵌入向量。由于视觉token中的每个元素代表采样某个视觉单词的概率,因此视觉token的嵌入向量自然地定义为所有视觉单词嵌入向量的加权平均,权重即为对应的概率。
3. LLM:Ovis使用LLM的文本tokenizer将输入文本转化为独热文本token(独热token也是概率化token的退化情形),并根据文本嵌入表查找到每个文本token对应的嵌入向量。最后,Ovis将所有视觉嵌入向量与文本嵌入向量拼接起来,送入LLM中进行处理,生成文本输出,完成多模态任务。
03.训练策略
Ovis2采用了四阶段的训练策略,以充分激发其多模态理解能力。
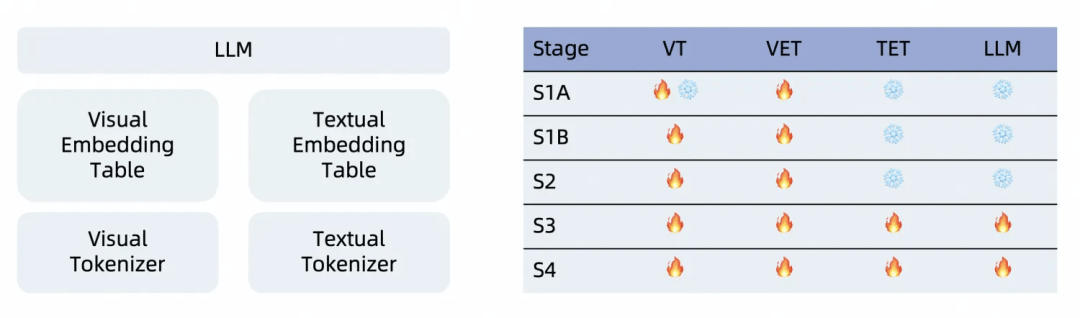
Stage 1A:VET预训练。在这一阶段,我们冻结了大部分LLM和ViT参数,仅对ViT的最后一层、视觉头和视觉嵌入词表进行训练。此阶段多模态数据不使用对话模版,直接在图像后接上文本。这一阶段的主要目标是学习视觉特征到嵌入的转化,并优化视觉嵌入以激发文本信息。
Stage 1B:视觉理解增强。冻结LLM,训练视觉模块,提升最大子图切分数。数据格式和Stage 1A一致。通过增大子图切分数和逐步开放ViT,我们提高了视觉模块的特征提取和转化能力,增强了高分辨率图像理解、多语言和OCR能力。
Stage 2:对话指令对齐。冻结LLM,训练视觉模块。使用对话形式的视觉Caption数据。此阶段旨在使视觉嵌入对齐LLM的对话格式,为后续的指令训练奠定基础。
Stage 3:多模态指令训练。训练整个Ovis,包含视觉模块与LLM。训练数据包含多模态(纯文本、单图、多图、视频)指令数据。经过前两个阶段的训练,Ovis已经具备较强的视觉理解能力,本阶段的目标是提升Ovis在多种模态下对用户指令的遵循能力。
Stage 4:偏好学习。训练整个Ovis,包含视觉模块与LLM,并进一步提升最大子图切分数。训练数据包含多模态(纯文本、单图、多图、视频)偏好数据。通过直接和CoT采样合成偏好数据,提升模型输出质量和COT能力;同时增大子图切分数,进一步提升视觉高分处理能力。
04.视频能力增强
为了在有限的视觉上下文中提升视频理解能力,我们开发了一种创新的关键帧选择算法——。的核心是****基于帧与文本的相关性、帧之间的组合多样性以及帧的序列性来挑选最有用的视频帧。具体流程如下:
Step 1:高维条件相似度计算 我们利用预训练的视觉语言模型(VLM),将视频帧和问题语句映射到同一空间中,并通过条件多核高斯函数(CMGK)在无限维的再生核希尔伯特空间(RKHS)中计算帧之间的条件相似度。该相似度条件于帧与文本的相关性,既考虑了帧与问题的相关性,也兼顾了帧之间的组合多样性,为后续选帧提供了基础。
Step 2:行列式点过程(DPP) DPP最初用于描述泡利不相容中两个费密子的量子态互斥性,后来被广泛应用于机器学习中以衡量元素之间的组合多样性。在上一步的条件相似度矩阵上应用DPP算法,确保选出的帧既与问题相关,又具有丰富的组合多样性,从而最大化信息量。
Step 3:马尔可夫决策过程(MDP) 为了让选帧过程符合视频的序列性,我们扩展了原始的序列行列式点过程(SeqDPP)算法。将视频分割成多个片段,然后在每个片段内应用DPP,同时考虑前一个片段的选帧结果。从而在保持连续性的同时,确保局部片段内的列表式多样性。将该过程建模成马尔可夫决策过程(MDP),通过动态规划算法,在高效的时间复杂度内确定每个片段的最优选帧数量。
MDP3算法论文:MDP3: A Training-free Approach for List-wise Frame Selection in Video-LLMs
05.性能评测
下面是Ovis2在OpenCompass多模态评测榜单的评测结果,Ovis2系列6个尺寸模型在多个Benchmark同级别均取得了SOTA。
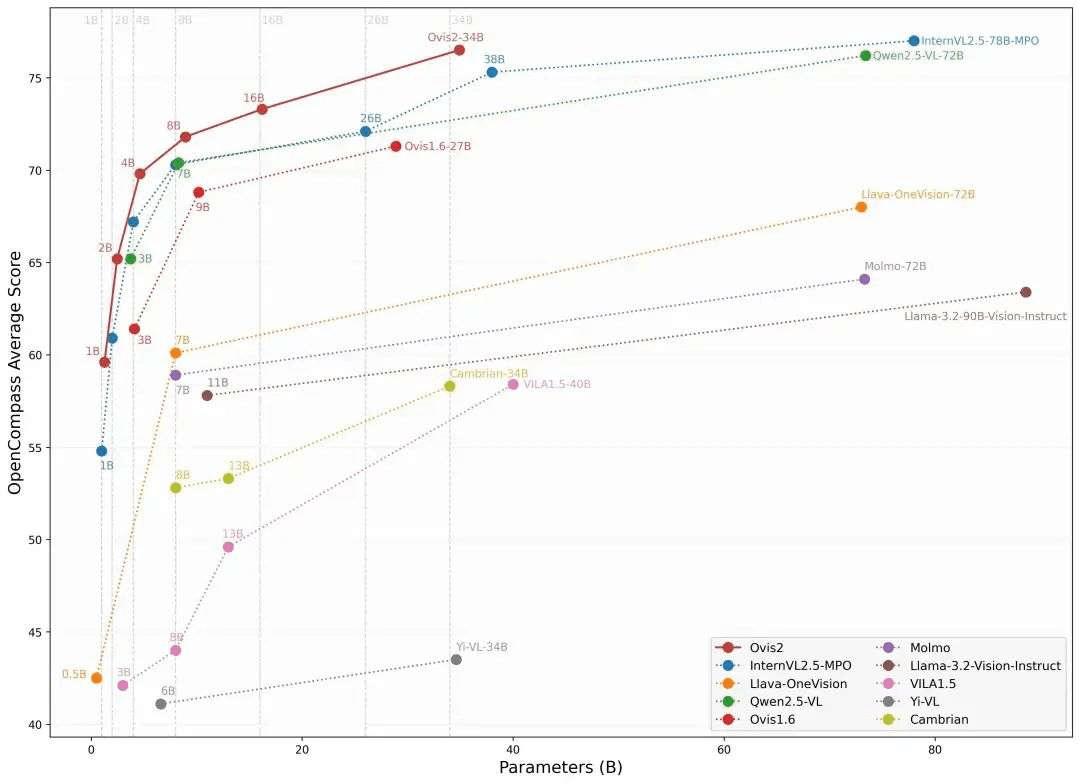
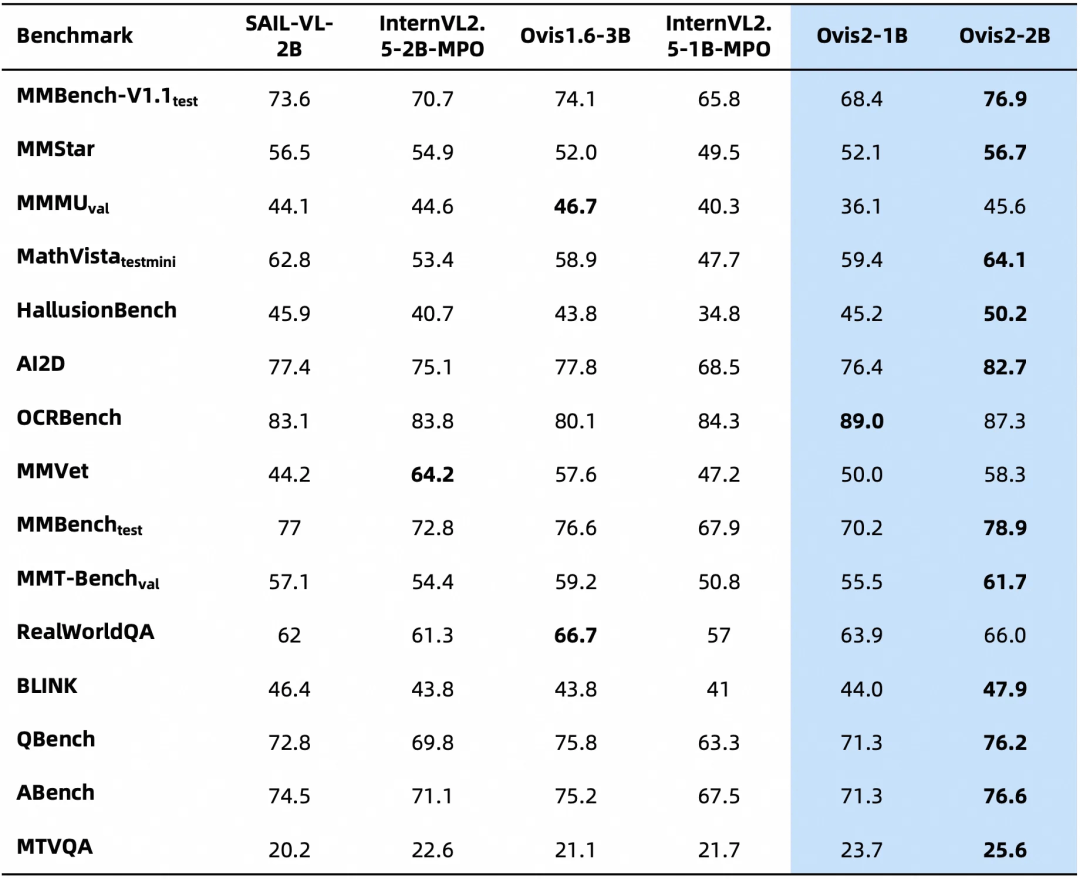
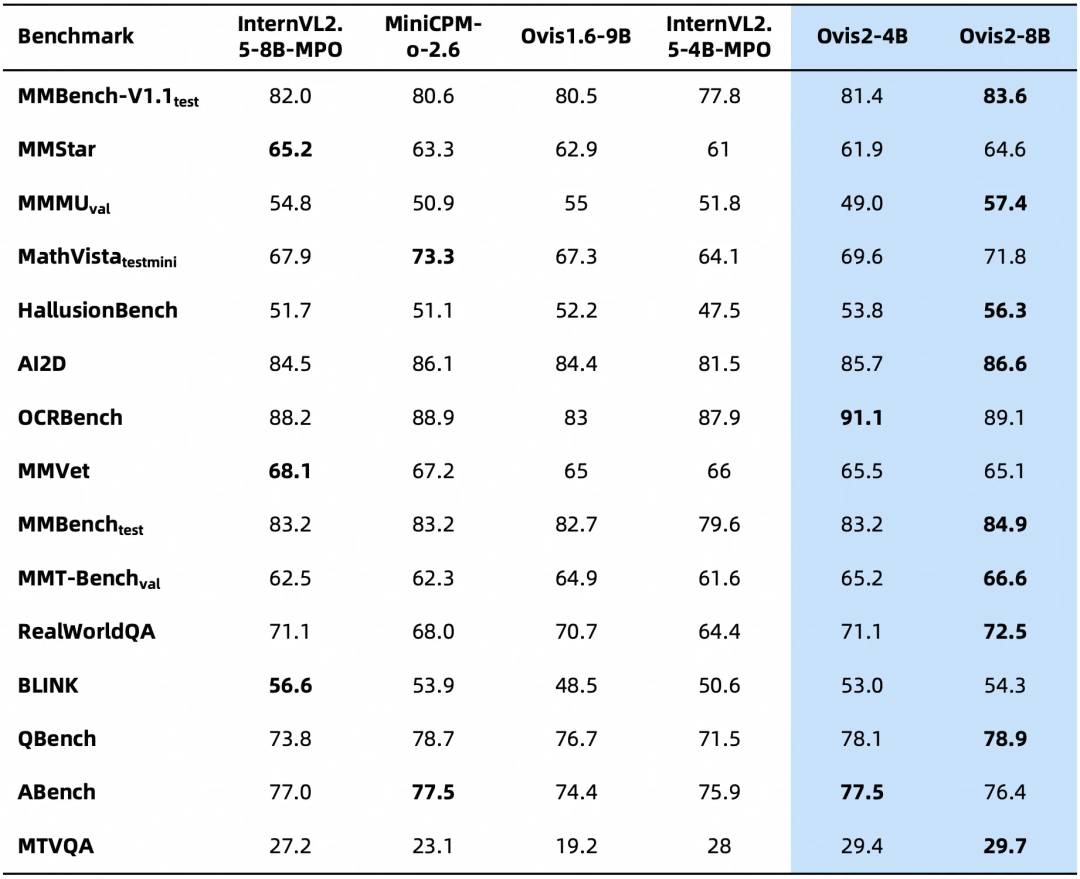
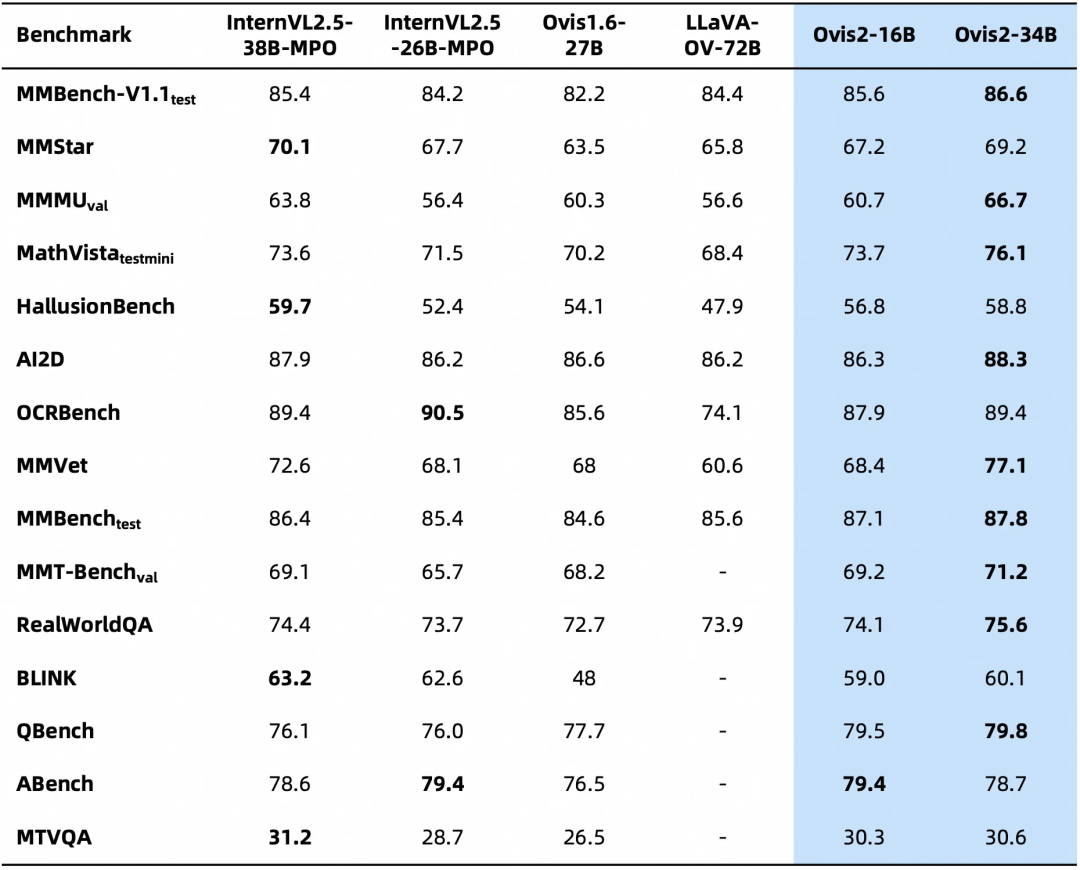
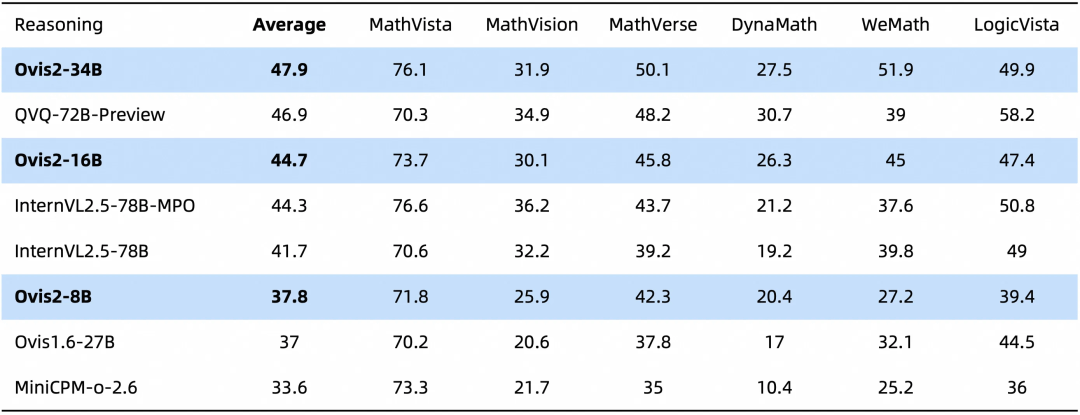
下面是在多模态模型数学推理榜单的评测结果,综合评分开源第一。
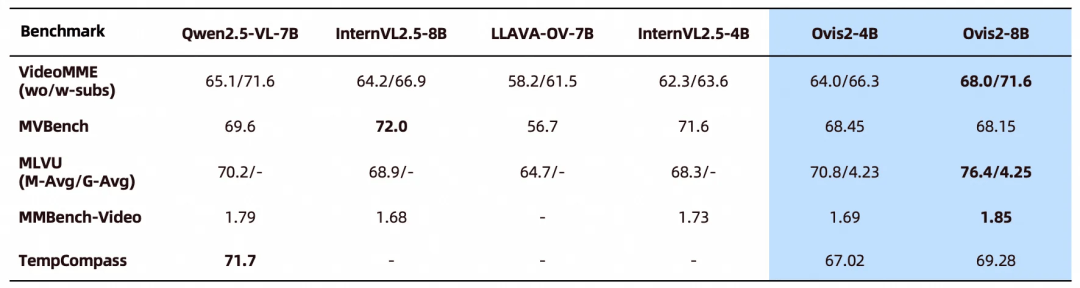
Ovis2在多项视频榜单上也取得了领先性能:


06.典型示例
小尺寸模型通用能力



大尺寸模型通用能力



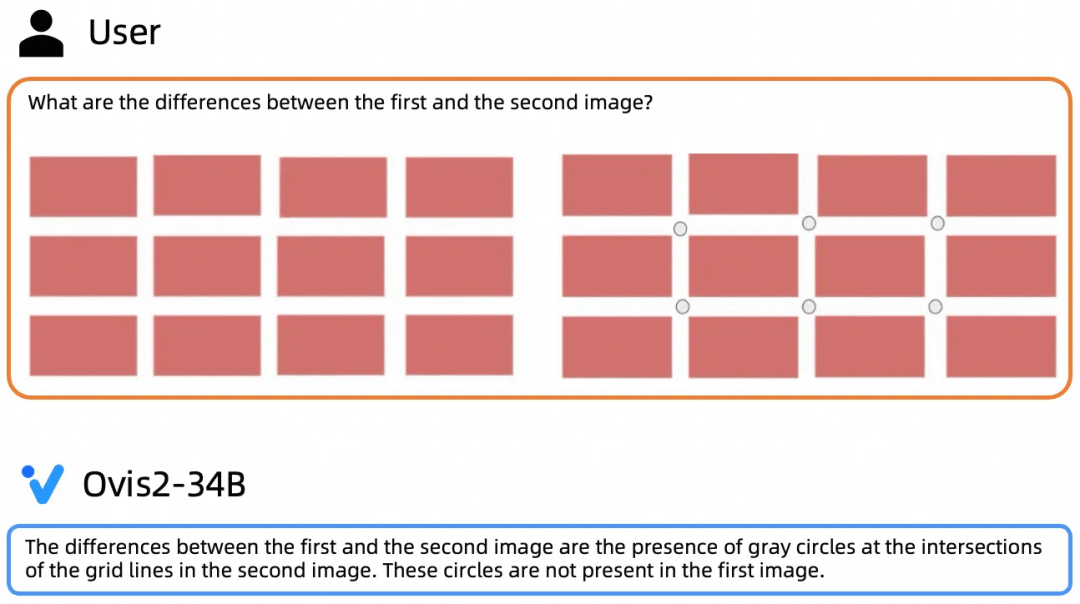
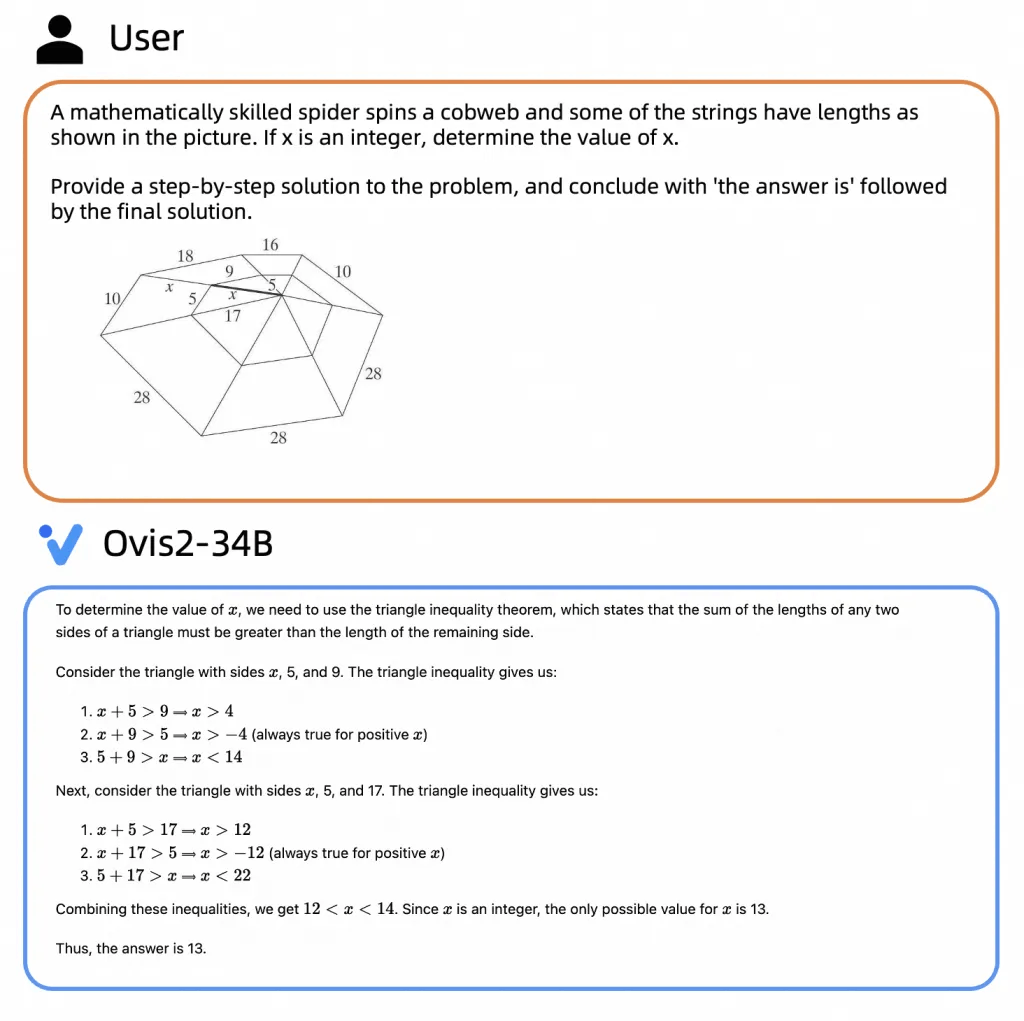
大尺寸模型推理能力

07.模型推理
在魔搭社区的免费GPU算力上推理Ovis 4B版本
安装依赖
!pip install flash-attn==2.7.0.post2 --no-build-isolation推理代码
import torch
from PIL import Image
from modelscope import AutoModelForCausalLM
# load model
model = AutoModelForCausalLM.from_pretrained("AIDC-AI/Ovis2-4B",
torch_dtype=torch.bfloat16,
multimodal_max_length=32768,
trust_remote_code=True).cuda()
text_tokenizer = model.get_text_tokenizer()
visual_tokenizer = model.get_visual_tokenizer()
# single-image input
image_path = './data/example.jpg'
images = [Image.open(image_path)]
max_partition = 9
text = 'Describe the image.'
query = f'<image>\n{text}'
## cot-style input
# cot_suffix = "Provide a step-by-step solution to the problem, and conclude with 'the answer is' followed by the final solution."
# image_path = '/data/images/example_1.jpg'
# images = [Image.open(image_path)]
# max_partition = 9
# text = "What's the area of the shape?"
# query = f'<image>\n{text}\n{cot_suffix}'
## multiple-images input
# image_paths = [
# '/data/images/example_1.jpg',
# '/data/images/example_2.jpg',
# '/data/images/example_3.jpg'
# ]
# images = [Image.open(image_path) for image_path in image_paths]
# max_partition = 4
# text = 'Describe each image.'
# query = '\n'.join([f'Image {i+1}: <image>' for i in range(len(images))]) + '\n' + text
## video input (require `pip install moviepy==1.0.3`)
# from moviepy.editor import VideoFileClip
# video_path = '/data/videos/example_1.mp4'
# num_frames = 12
# max_partition = 1
# text = 'Describe the video.'
# with VideoFileClip(video_path) as clip:
# total_frames = int(clip.fps * clip.duration)
# if total_frames <= num_frames:
# sampled_indices = range(total_frames)
# else:
# stride = total_frames / num_frames
# sampled_indices = [min(total_frames - 1, int((stride * i + stride * (i + 1)) / 2)) for i in range(num_frames)]
# frames = [clip.get_frame(index / clip.fps) for index in sampled_indices]
# frames = [Image.fromarray(frame, mode='RGB') for frame in frames]
# images = frames
# query = '\n'.join(['<image>'] * len(images)) + '\n' + text
## text-only input
# images = []
# max_partition = None
# text = 'Hello'
# query = text
# format conversation
prompt, input_ids, pixel_values = model.preprocess_inputs(query, images, max_partition=max_partition)
attention_mask = torch.ne(input_ids, text_tokenizer.pad_token_id)
input_ids = input_ids.unsqueeze(0).to(device=model.device)
attention_mask = attention_mask.unsqueeze(0).to(device=model.device)
if pixel_values is not None:
pixel_values = pixel_values.to(dtype=visual_tokenizer.dtype, device=visual_tokenizer.device)
pixel_values = [pixel_values]
# generate output
with torch.inference_mode():
gen_kwargs = dict(
max_new_tokens=1024,
do_sample=False,
top_p=None,
top_k=None,
temperature=None,
repetition_penalty=None,
eos_token_id=model.generation_config.eos_token_id,
pad_token_id=text_tokenizer.pad_token_id,
use_cache=True
)
output_ids = model.generate(input_ids, pixel_values=pixel_values, attention_mask=attention_mask, **gen_kwargs)[0]
output = text_tokenizer.decode(output_ids, skip_special_tokens=True)
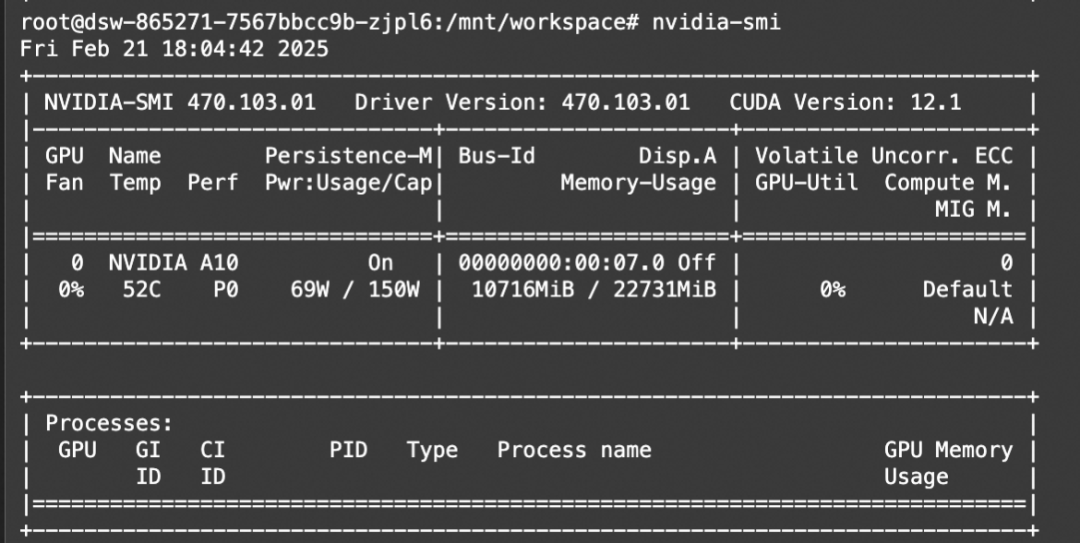
print(f'Output:\n{output}')显存占用:
08.模型微调
使用ms-swift对Ovis2-2B进行微调。ms-swift是魔搭社区官方提供的大模型与多模态大模型训练部署框架。
ms-swift开源地址:
https://github.com/modelscope/ms-swift
在这里,我们将展示可运行的微调demo,并给出自定义数据集的格式。
在开始微调之前,请确保您的环境已准备妥当。
# pip install git+https://github.com/modelscope/ms-swift.git
git clone https://github.com/modelscope/ms-swift.git
cd ms-swift
pip install -e .微调脚本如下:
CUDA_VISIBLE_DEVICES=0 \
swift sft \
--model AIDC-AI/Ovis2-2B \
--dataset 'AI-ModelScope/LaTeX_OCR#2000' \
--train_type lora \
--torch_dtype bfloat16 \
--num_train_epochs 1 \
--per_device_train_batch_size 1 \
--per_device_eval_batch_size 1 \
--learning_rate 1e-4 \
--lora_rank 8 \
--lora_alpha 32 \
--target_modules all-linear \
--freeze_vit true \
--gradient_accumulation_steps 16 \
--eval_steps 100 \
--save_steps 100 \
--save_total_limit 2 \
--logging_steps 5 \
--max_length 2048 \
--output_dir output \
--warmup_ratio 0.05训练显存占用:

如果要使用自定义数据集进行训练,你可以参考以下格式,并指定`--dataset <dataset_path>`。
{"messages": [{"role": "user", "content": "浙江的省会在哪?"}, {"role": "assistant", "content": "浙江的省会在杭州。"}]}
{"messages": [{"role": "user", "content": "<image><image>两张图片有什么区别"}, {"role": "assistant", "content": "前一张是小猫,后一张是小狗"}], "images": ["/xxx/x.jpg", "/xxx/x.png"]}
{"messages": [{"role": "system", "content": "你是个有用无害的助手"}, {"role": "user", "content": "<image><image><image><image>视频中是什么"}, {"role": "assistant", "content": "视频中是一只小狗在草地上奔跑"}], "images": ["/xxx/xxx/1.jpg", "/xxx/xxx/2.jpg", "/xxx/xxx/3.jpg", "/xxx/xxx/4.jpg"]}训练完成后,使用以下命令对训练后的权重进行推理:
提示:这里的`--adapters`需要替换成训练生成的last checkpoint文件夹。由于adapters文件夹中包含了训练的参数文件`args.json`,因此不需要额外指定`--model`,swift会自动读取这些参数。如果要关闭此行为,可以设置`--load_args false`。
CUDA_VISIBLE_DEVICES=0 \
swift infer \
--adapters output/vx-xxx/checkpoint-xxx \
--stream false \
--max_batch_size 1 \
--load_data_args true \
--max_new_tokens 2048推送模型到ModelScope:
CUDA_VISIBLE_DEVICES=0 \
swift export \
--adapters output/vx-xxx/checkpoint-xxx \
--push_to_hub true \
--hub_model_id '<your-model-id>' \
--hub_token '<your-sdk-token>'点击链接阅读原文,直达模型合集~

ModelScope旨在打造下一代开源的模型即服务共享平台,为泛AI开发者提供灵活、易用、低成本的一站式模型服务产品,让模型应用更简单!
更多推荐



 0
0 0
0- 0



 已为社区贡献652条内容
已为社区贡献652条内容

所有评论(0)