
魔搭社区模型速递(1.19-2.15)
魔搭ModelScope本期社区进展:6205个模型,823个数据集,333个创新应用, 26篇内容。

🙋魔搭ModelScope本期社区进展:
📟6205个模型:DeepSeek-R1-Distill-Qwen系列、Qwen2.5 VL系列、VITA-1.5、Janus-Pro、Qwen2.5-1M、UI-TARS、InspireMusic、RWKV-7 2.9B等;
📁823个数据集:R1蒸馏模型数学推理能力测试集、smoltalk中文数据集、大模型IQ/EQ评测集、codeforces problemset等;
🎨333个创新应用:DeepSeek-R1 游乐场、Qwen2.5-Max展示、Qwen2.5-VL-72B-Instruct展示、Janus-Pro-7B多模态、Qwen2.5-1M-Demo等;
📄 26篇内容:
-
C-3PO:多智能体强化学习赋能检索增强生成
-
R1类模型推理能力评测手把手实战
-
RWKV-7 2.9B 开源发布!纯 RNN 无 KV cache,支持世界所有语言
-
通义音乐生成技术InspireMusic开源!
-
AAAI 2025| S5VH: 基于选择性状态空间的高效自监督视频哈希
-
又又又上新啦!魔搭免费模型推理API支持DeepSeek-R1,Qwen2.5-VL,Flux.1 dev及Lora等
-
0元!使用魔搭免费算力,基于Qwen基座模型,复现DeepSeek-R1
-
可控文生图:EliGen控制实体的位置细节变化
-
DeepSeek开源Janus-Pro多模态理解生成模型,魔搭社区推理、微调最佳实践
-
阿里通义等提出Chronos:慢思考RAG技术助力新闻时间线总结
-
浙大通义联手推出慢思考长文本生成框架OmniThink,让AI写作突破知识边界
-
Qwen2.5-VL Cookbook来啦!手把手教你怎么用好视觉理解模型!
-
Qwen2.5 VL! Qwen2.5 VL! Qwen2.5 VL! 重要的模型说三遍!
-
Qwen2.5-1M: 支持100万Tokens上下文的开源Qwen模型
-
开源版Operator原生AI智能体来了?字节跳动开源UI-TARS模型
-
春节来司南大模型对战竞技场,pick你的专属大模型搭档
-
魔搭AIGC 2月赛超前开题:联动麦橘超然,诠释AI梦一丹一世界
-
MustDrop:多阶段去除冗余视觉token,提升多模态大模型推理效率
-
通义实验室提出WebWalker:让大模型“冲浪”互联网,解锁复杂信息检索新技能!
-
统一多模态Embedding, 通义实验室开源GME系列模型
-
Deepseek开源R1系列模型,纯RL助力推理能力大跃升!
-
OpenCSG开源SmolTalk Chinese数据集
-
VITA-1.5: 迈向GPT-4o级实时视频-语音交互
-
基于Gradio的AI应用搭建实践课④:前后端联调及应用发布:打通前后端的任督二脉,就是完整的AI应用!
-
基于Gradio的AI应用搭建实践课⑤:通过AI应用案例来实践,先做出你自己的第一个AI应用!
-
基于Gradio的AI应用搭建实践课⑥:0代码基础0门槛在线编程做应用
01.精选模型
DeepSeek-R1系列
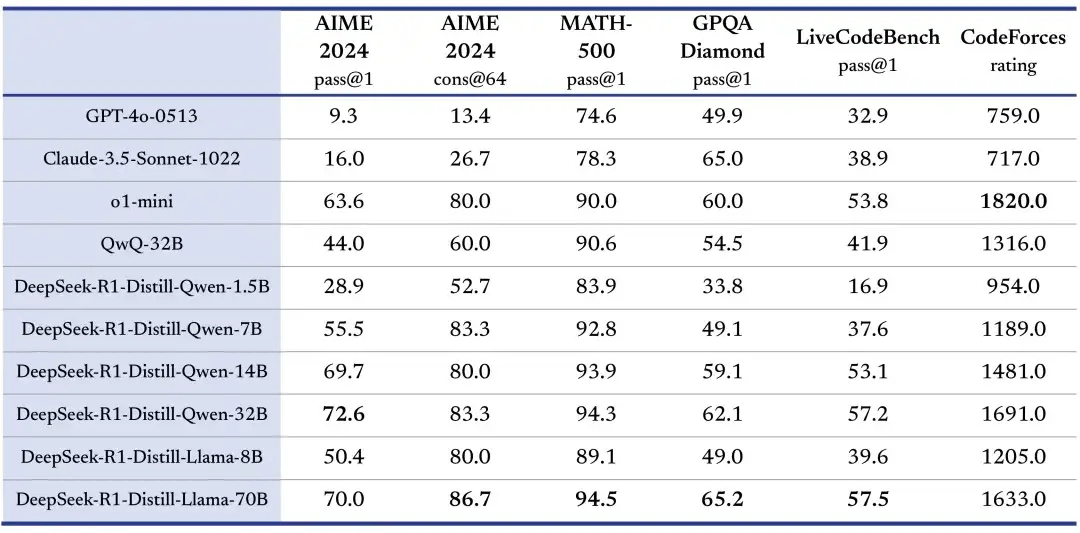
Deepseek发布并开源 DeepSeek-R1,遵循 MIT License,允许用户通过蒸馏技术借助 R1 训练其他模型。同步,DeepSeek官方蒸馏了 6 个小模型开源给社区,其中 32B 和 70B 模型在多项能力上实现了对标 OpenAI o1-mini 的效果,同时显著降低了资源消耗,适合企业内部部署和研究社区使用,尤其在数学、逻辑推理和编程任务上表现优异。
模型链接:
https://modelscope.cn/collections/DeepSeek-R1-c8e86ac66ed943
示例代码:
使用ollama推理
设置ollama下启用
ollama serve
ollama run DeepSeek-R1任意GGUF模型
ollama run modelscope.cn/unsloth/DeepSeek-R1-Distill-Qwen-7B-GGUF运行结果

使用魔搭社区API-Inference推理:
from openai import OpenAI
client = OpenAI(
base_url='https://api-inference.modelscope.cn/v1/',
api_key='Your_SDK_Token', # ModelScope Token
)
response = client.chat.completions.create(
model='deepseek-ai/DeepSeek-R1', # ModelScope Model-Id
messages=[
{
'role': 'system',
'content': 'You are a helpful assistant.'
},
{
'role': 'user',
'content': '你好'
}
],
stream=True
)
reasoning_content = ''
answer_content = ''
done_reasoning = False
for chunk in response:
# for reaonsing model, output may include both reasoning_content and content
reasoning_chunk = chunk.choices[0].delta.reasoning_content
answer_chunk = chunk.choices[0].delta.content
if reasoning_chunk != '':
print(reasoning_chunk, end='',flush=True)
elif answer_chunk != '':
if not done_reasoning:
print("\n\n === Final Answer ===\n")
done_reasoning = True
print(answer_chunk, end='',flush=True)
好的,用户用中文打招呼“你好”,我需要回应。首先,确定用户的需求是什么。可能只是简单的问候,或者有后续问题。考虑到用户之前可能切换了语言,现在用中文,可能需要中文回答。我应该保持友好,询问有什么可以帮助的,同时保持简洁。避免使用复杂的句子,让用户感到轻松。另外,检查是否有拼写错误,确保回应自然。最后,确保符合OpenAI的内容政策,不涉及敏感话题。准备好回应后,发送即可。
=== Final Answer ===
你好!很高兴见到你,有什么我可以帮忙的吗?Qwen2.5 VL系列
Qwen团队推出最新视觉语言模型Qwen2.5-VL,具备强大的视觉语言理解和生成能力。
能力增强部分包括:
-
超强视觉理解:不仅能识别常见物体,还能分析图像中的文本、图表、图标和布局。
-
智能代理能力:可作为视觉Agent,推理并动态指挥工具,支持多平台操作。
-
长视频理解:能够理解超过1小时的视频内容,并精准定位关键事件。
-
精准物体定位:通过边界框和点定位技术,输出稳定的JSON格式坐标和属性。
-
结构化输出:支持对发票、表格等数据的结构化输出,适用于金融和商业领域。
Qwen2.5-VL有3B、7B和72B三种参数规模版本,适用于不同的应用场景。其在文档理解、视频分析和视觉代理任务上表现优异,无需针对特定任务进行微调。
模型链接:
通义千问2.5-VL-3B-Instruct
https://modelscope.cn/models/Qwen/Qwen2.5-VL-3B-Instruct
通义千问2.5-VL-7B-Instruct
https://modelscope.cn/models/Qwen/Qwen2.5-VL-7B-Instruct
通义千问2.5-VL-72B-Instruct
https://modelscope.cn/models/Qwen/Qwen2.5-VL-72B-Instruct
示例代码:
使用transformers推理:
pip install git+https://github.com/huggingface/transformers官方提供了一个工具包,可帮助更方便地处理各种类型的视觉输入,就像使用 API 一样。这包括 base64、URL 以及交错的图像和视频。可以使用以下命令安装它:
pip install qwen-vl-utils[decord]==0.0.8推理代码:
from transformers import Qwen2_5_VLForConditionalGeneration, AutoTokenizer, AutoProcessor
from qwen_vl_utils import process_vision_info
from modelscope import snapshot_download
model_dir = snapshot_download("Qwen/Qwen2.5-VL-3B-Instruct")
# default: Load the model on the available device(s)
model = Qwen2_5_VLForConditionalGeneration.from_pretrained(
model_dir, torch_dtype="auto", device_map="auto"
)
# We recommend enabling flash_attention_2 for better acceleration and memory saving, especially in multi-image and video scenarios.
# model = Qwen2_5_VLForConditionalGeneration.from_pretrained(
# "Qwen/Qwen2.5-VL-3B-Instruct",
# torch_dtype=torch.bfloat16,
# attn_implementation="flash_attention_2",
# device_map="auto",
# )
# default processer
processor = AutoProcessor.from_pretrained(model_dir)
# The default range for the number of visual tokens per image in the model is 4-16384.
# You can set min_pixels and max_pixels according to your needs, such as a token range of 256-1280, to balance performance and cost.
# min_pixels = 256*28*28
# max_pixels = 1280*28*28
# processor = AutoProcessor.from_pretrained("Qwen/Qwen2.5-VL-3B-Instruct", min_pixels=min_pixels, max_pixels=max_pixels)
messages = [
{
"role": "user",
"content": [
{
"type": "image",
"image": "https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen-VL/assets/demo.jpeg",
},
{"type": "text", "text": "Describe this image."},
],
}
]
# Preparation for inference
text = processor.apply_chat_template(
messages, tokenize=False, add_generation_prompt=True
)
image_inputs, video_inputs = process_vision_info(messages)
inputs = processor(
text=[text],
images=image_inputs,
videos=video_inputs,
padding=True,
return_tensors="pt",
)
inputs = inputs.to("cuda")
# Inference: Generation of the output
generated_ids = model.generate(**inputs, max_new_tokens=128)
generated_ids_trimmed = [
out_ids[len(in_ids) :] for in_ids, out_ids in zip(inputs.input_ids, generated_ids)
]
output_text = processor.batch_decode(
generated_ids_trimmed, skip_special_tokens=True, clean_up_tokenization_spaces=False
)
print(output_text)更多详情请查看文章:
Qwen2.5 VL! Qwen2.5 VL! Qwen2.5 VL! 重要的模型说三遍!
Qwen2.5-VL Cookbook来啦!手把手教你怎么用好视觉理解模型!
UI-TARS
UI-TARS 是由字节跳到开源的新一代原生 GUI 代理模型,旨在利用类似人类的感知、推理和操作能力与图形用户界面 (GUI) 无缝交互。与传统的模块化框架不同,UI-TARS 将所有关键组件(感知、推理、基础和记忆)集成到单个视觉语言模型 (VLM) 中,无需预定义的工作流程或手动规则即可实现端到端任务自动化。
模型链接:
UI-TARS-2B-SFT
https://modelscope.cn/models/bytedance-research/UI-TARS-2B-SFT
UI-TARS-7B-SFT
https://modelscope.cn/models/bytedance-research/UI-TARS-7B-SFT
UI-TARS-72B-SFT
https://modelscope.cn/models/bytedance-research/UI-TARS-72B-SFT
UI-TARS-72B-DPO
https://modelscope.cn/models/bytedance-research/UI-TARS-72B-DPO
UI-TARS-7B-DPO
https://modelscope.cn/models/bytedance-research/UI-TARS-7B-DPO
使用指引:
开源版Operator原生AI智能体来了?字节跳动开源UI-TARS模型
02.数据集推荐
R1蒸馏模型数学推理能力测试集
用于评测R1类模型推理能力的数据集,包括MATH-500(高中数学竞赛问题)、GPQA-Diamond(物理、化学、生物硕士水平选择题)和AIME-2024(美国邀请数学竞赛题目),并展示了如何使用EvalScope框架进行模型性能评测和结果可视化。
数据集链接:
https://modelscope.cn/datasets/modelscope/R1-Distill-Math-Test/summary
更多详情请查看文章:
smoltalk中文数据集
是一个中文微调数据集,该数据集是参考Smoltalk数据集的。它旨在为培训大语言模型提供高质量的合成数据支持(LLMs )。该数据集完全由合成数据组成,包括700,000多个条目。它是专门设计的,以增强中文的性能LLMs在各种任务中,提高了它们的多功能性和适应性。
数据集链接:
https://modelscope.cn/datasets/opencsg/smoltalk-chinese
更多详情请查看文章:
大模型IQ/EQ评测集
大模型IQ/EQ评测集(IQuiz)是一个用于评估大语言模型智力(IQ)和情商(EQ)的多维度基准数据集,涵盖逻辑推理、常识问答、情感分析等多种任务,旨在全面评测模型的综合能力。
数据集链接:
https://modelscope.cn/datasets/AI-ModelScope/IQuiz
codeforces problemset
数据集包含了来自 Codeforces 编程竞赛平台的大量编程题目数据。这些题目涵盖了从基础到高级的算法和数据结构问题,适用于编程训练、算法研究以及开发相关竞赛辅助工具等场景。
数据集链接:
https://modelscope.cn/datasets/ysysn7/578424
03.精选应用
DeepSeek-R1 游乐场
体验直达:
https://modelscope.cn/studios/AI-ModelScope/deepseek-playground
Qwen2.5-Max展示
体验直达:
https://modelscope.cn/studios/Qwen/Qwen2.5-Max-Demo
Qwen2.5-VL-72B-Instruct展示
体验直达:
https://modelscope.cn/studios/Qwen/Qwen2.5-VL-72B-Instruct
Janus-Pro-7B多模态
体验直达:
https://modelscope.cn/studios/AI-ModelScope/Janus-Pro-7B
Qwen2.5-1M-Demo
体验直达:
https://modelscope.cn/studios/Qwen/Qwen2.5-1M-Demo
04.社区精选文章

ModelScope旨在打造下一代开源的模型即服务共享平台,为泛AI开发者提供灵活、易用、低成本的一站式模型服务产品,让模型应用更简单!
更多推荐



 0
0 0
0- 0



 已为社区贡献652条内容
已为社区贡献652条内容

所有评论(0)