
Deepseek开源R1系列模型,纯RL助力推理能力大跃升!
近期Deepseek正式发布 DeepSeek-R1,并同步开源模型权重。DeepSeek-R1 遵循 MIT License,允许用户通过蒸馏技术借助 R1 训练其他模型。
近期Deepseek正式发布 DeepSeek-R1,并同步开源模型权重。DeepSeek-R1 遵循 MIT License,允许用户通过蒸馏技术借助 R1 训练其他模型。
01.模型介绍
性能对齐OpenAI-o1正式版
DeepSeek-R1 在后训练阶段大规模使用了强化学习技术,在仅有极少标注数据的情况下,极大提升了模型推理能力。在数学、代码、自然语言推理等任务上,性能比肩 OpenAI o1 正式版。

在此,DeepSeek将 DeepSeek-R1 训练技术全部公开,以期促进技术社区的充分交流与创新协作。
论文链接:
https://github.com/deepseek-ai/DeepSeek-R1/blob/main/DeepSeek_R1.pdf
模型链接:
https://modelscope.cn/collections/DeepSeek-R1-c8e86ac66ed943
蒸馏小模型超越 OpenAI o1-mini
DeepSeek在开源 DeepSeek-R1-Zero 和 DeepSeek-R1 两个 660B 模型的同时,通过 DeepSeek-R1 的输出,蒸馏了 6 个小模型开源给社区,其中 32B 和 70B 模型在多项能力上实现了对标 OpenAI o1-mini 的效果。
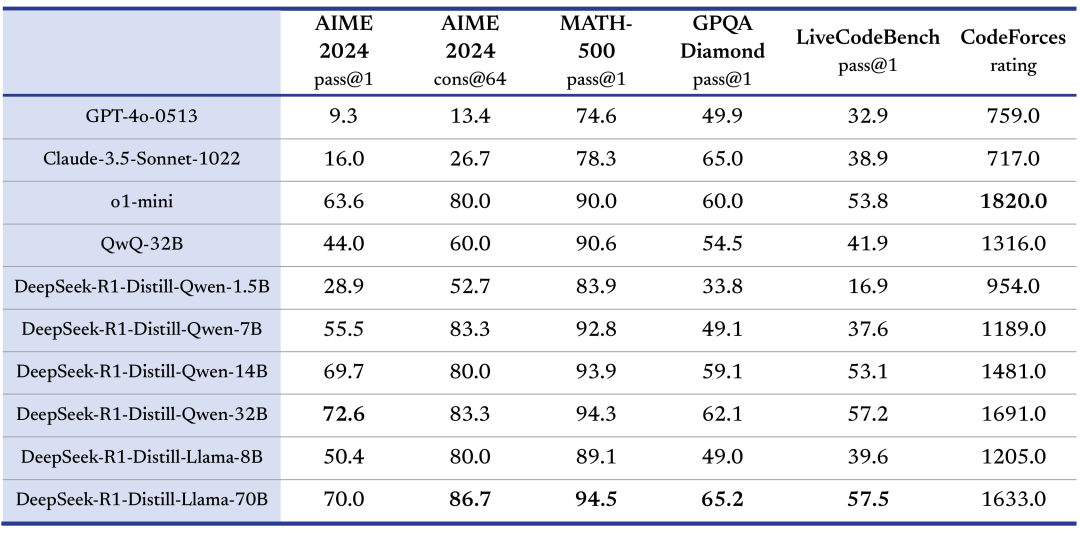
02.模型推理
使用vLLM推理
在魔搭社区免费算力上(单卡24G显存),使用vLLM推理deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B
在vLLM上使用魔搭的模型只需要在任何vLLM命令之前设置一个环境变量:
export VLLM_USE_MODELSCOPE=True使用vLLM启动服务
vllm serve deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B --tensor-parallel-size 1 --max-model-len 1024 --enforce-eager
模型推理
curl http://localhost:8000/v1/completions -H "Content-Type: application/json" -d '{
"model": "deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B",
"prompt": "which is bigger, 9.11 or 9.9",
"max_tokens": 512,
"temperature": 0
}'使用ollama推理
设置ollama下启用
ollama serve
ollama run DeepSeek-R1任意GGUF模型
ollama run modelscope.cn/unsloth/DeepSeek-R1-Distill-Qwen-7B-GGUF运行结果
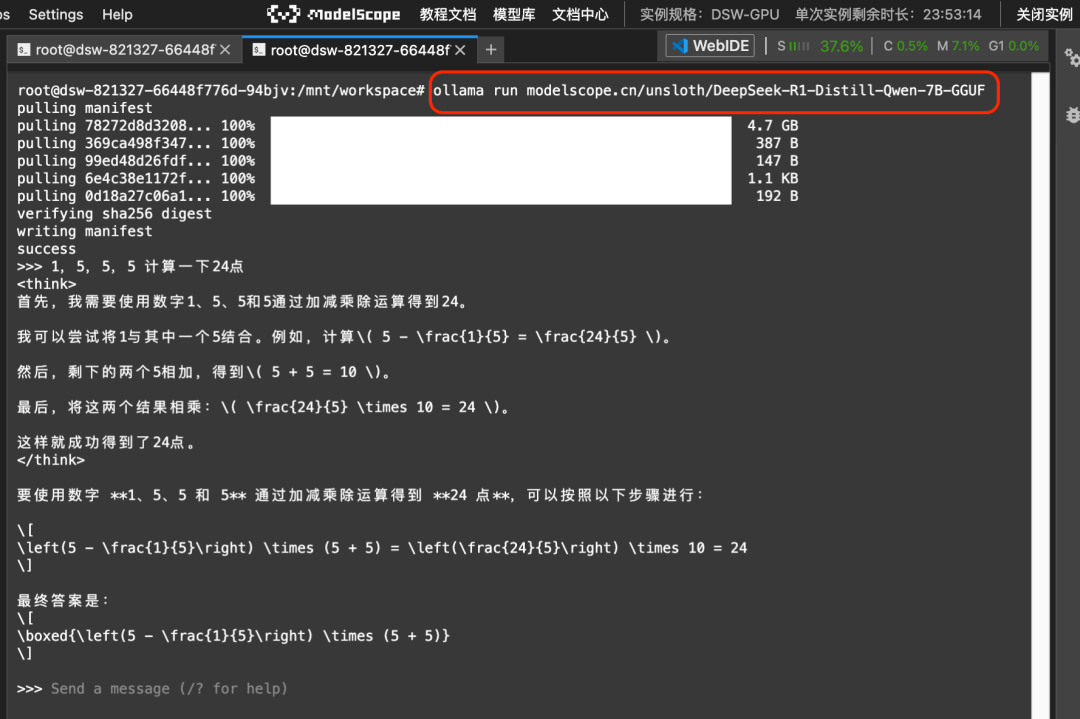
03.模型微调
这里我们介绍使用ms-swift3对deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B进行微调。
在开始微调之前,请确保您的环境已正确安装:
# 安装ms-swift
git clone https://github.com/modelscope/ms-swift.git
cd ms-swift
pip install -e . -i https://mirrors.aliyun.com/pypi/simple/我们给出可运行的微调demo和自定义数据集的样式,微调脚本如下:
nproc_per_node=2
NPROC_PER_NODE=$nproc_per_node \
CUDA_VISIBLE_DEVICES=0,1 \
swift sft \
--model deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B \
--train_type full \
--dataset 'PowerInfer/QWQ-LONGCOT-500K#2000' swift/self-cognition \
--torch_dtype bfloat16 \
--num_train_epochs 10 \
--per_device_train_batch_size 2 \
--per_device_eval_batch_size 2 \
--learning_rate 1e-5 \
--gradient_accumulation_steps $((16 / $nproc_per_node)) \
--eval_steps 100 \
--save_steps 100 \
--save_total_limit -1 \
--logging_steps 5 \
--max_length 8192 \
--output_dir output \
--system 'You are a helpful and harmless assistant. You should think step-by-step.' \
--warmup_ratio 0.05 \
--dataloader_num_workers 4 \
--deepspeed zero2 \
--model_author 魔搭 ModelScope \
--model_name 小黄 'Xiao Huang' \
--dataset_num_proc 16训练显存占用:

自定义数据集格式:(直接使用`--dataset <dataset_path>`指定即可)
{"messages": [{"role": "user", "content": "问题..."}, {"role": "assistant", "content": "<think>\n\n思考的内容...(可选)</think>\n\回答..."}, {"role": "user", "content": "问题..."}, {"role": "assistant", "content": "<think>\n\n思考的内容...(可选)</think>\n\n回答..."}]}推理脚本:
CUDA_VISIBLE_DEVICES=0 \
swift infer \
--model output/vx-xxx/checkpoint-xxx \
--stream true \
--max_new_tokens 2048点击阅读原文:DeepSeek-R1

ModelScope旨在打造下一代开源的模型即服务共享平台,为泛AI开发者提供灵活、易用、低成本的一站式模型服务产品,让模型应用更简单!
更多推荐



 0
0 1
1- 0



 已为社区贡献652条内容
已为社区贡献652条内容

所有评论(0)