
微软phi-4来啦!小模型之光,14B科学、代码等能力超70B模型效果!
微软研究院的最新成果——Phi-4来啦!近日,微软公布了Phi家族的最新一代模型Phi-4的技术报告,模型同步开源,Phi-4建立在合成数据集、过滤后的公共领域网站数据以及获得的学术书籍和问答数据集的
01.引言
微软研究院的最新成果——Phi-4来啦!近日,微软公布了Phi家族的最新一代模型Phi-4的技术报告,模型同步开源,Phi-4建立在合成数据集、过滤后的公共领域网站数据以及获得的学术书籍和问答数据集的基础上,训练数据量为9.8 T tokens, 目标是确保小模型使用专注于高质量和高级推理的数据进行训练。
本次推出的phi-4的模型参数量为14B,是一个稠密的Decoder-Only的Transformers模型, 上下文长度为16K tokens,开源协议为MIT。
phi-4经过严格的增强和调整过程,结合了监督微调和直接偏好优化,以确保精确的指令遵守和强大的安全措施。
模型链接:
https://modelscope.cn/models/LLM-Research/phi-4/summary
技术报告:
https://arxiv.org/pdf/2412.08905
预期用途
|
主要用例 |
Phi-4模型旨在加速语言模型的研究,作为生成式人工智能功能的构建模块。它为通用人工智能系统和应用程序(主要是英语)提供用途,这些系统和应用程序需要:1. 内存/计算受限环境。2. 延迟受限场景。3. 推理和逻辑。 |
|
超出范围的用例 |
Phi-4并非专门为所有下游目的而设计或评估,因此:1. 开发人员在选择用例时应考虑语言模型的常见限制,并在特定下游用例(尤其是高风险场景)中使用之前评估和缓解准确性、安全性和公平性。2. 开发人员应了解并遵守与其用例相关的适用法律或法规(包括隐私、贸易合规法律等),包括该模型对英语的关注。3. 本模型卡中包含的任何内容均不应解释为或视为对模型发布所依据的许可证的限制或修改。 |
数据概览
训练数据集
Phi-4训练数据是用于 Phi-3 的数据的扩展,包括来自以下各种来源的数据:
-
对公开的文档进行了严格的质量筛选,选取了高质量的教育数据和代码。
-
新创建的合成“类似教科书”的数据,目的是教授数学、编码、常识推理、世界常识(科学、日常活动、心理理论等)。
-
获得学术书籍和问答数据集。
-
高质量聊天格式的监督数据涵盖各种主题,以反映人类在遵循指示、真实性、诚实和乐于助人等不同方面的偏好。
多语言数据约占整体数据的 8%。研究团队专注于可能提高模型推理能力的数据质量,并筛选公开的文档以包含正确的知识水平。
基准数据集
phi-4使用OpenAI 的 SimpleEval和我们自己的内部基准进行了评估,以了解该模型的功能,更具体地说:
-
MMLU:用于多任务语言理解的流行聚合数据集。
-
MATH:具有挑战性的竞赛数学问题。
-
GPQA:复杂的、研究生级别的科学问题。
-
DROP:复杂的理解和推理。
-
MGSM:多语言小学数学。
-
HumanEval:功能代码生成。
-
SimpleQA:事实回应。
安全
方法
phi-4采用了强大的安全后训练方法。这种方法利用了各种开源和内部生成的合成数据集。进行安全调整所采用的整体技术是 SFT(监督微调)和迭代 DPO(直接偏好优化)的组合,包括关注有用性和无害性的公开数据集以及针对多个安全类别的各种问题和答案。
安全评估和红队
在发布之前,phi-4我们采用了多方面的评估方法。定量评估是使用多个开源安全基准和内部工具利用对抗性对话模拟进行的。对于定性安全评估,我们与微软的独立 AI Red Team (AIRT) 合作,评估phi-4普通用户场景和对抗性用户场景带来的安全风险。在普通用户场景中,AIRT 模拟了典型的单轮和多轮交互以识别潜在的危险行为。对抗性用户场景测试了旨在故意破坏模型安全训练的各种技术,包括越狱、基于编码的攻击、多轮攻击和对抗性后缀攻击。
模型质量
为了了解这些功能,phi-4与 OpenAI 的 SimpleEval 基准上的一组模型进行了比较。
在代表性基准上对模型质量进行高层次概述。对于下表,数字越高表示性能越好:
|
类别 |
基准 |
phi-4(14B) |
phi-3(14B) |
Qwen 2.5(14B instruct) |
GPT-4o-mini |
Llama-3.3(70B instruct) |
Qwen 2.5(72B instruct) |
GPT-4o |
|
热门综合基准 |
MMLU |
84.8 |
77.9 |
79.9 |
81.8 |
86.3 |
85.3 |
88.1 |
|
科学 |
GPQA |
56.1 |
31.2 |
42.9 |
40.9 |
49.1 |
49.0 |
50.6 |
|
数学 |
MGSMMATH |
80.680.4 |
53.544.6 |
79.675.6 |
86.573.0 |
89.166.3* |
87.380.0 |
90.474.6 |
|
代码生成 |
HumanEval |
82.6 |
67.8 |
72.1 |
86.2 |
78.9* |
80.4 |
90.6 |
|
事实知识 |
SimpleQA |
3.0 |
7.6 |
5.4 |
9.9 |
20.9 |
10.2 |
39.4 |
|
推理 |
DROP |
75.5 |
68.3 |
85.5 |
79.3 |
90.2 |
76.7 |
80.9 |
* 这些分数低于 Meta 报告的分数,可能是因为 simple-evals 具有严格的格式要求,而 Llama 模型尤其难以遵循。Phi-4使用 simple-evals 框架是因为它具有可重复性,但 Meta 在 Llama-3.3-70B 上报告 MATH 为 77,HumanEval 为 88。
用法
输入格式
考虑到训练数据的性质,phi-4最适合使用以下聊天格式的提示:
<|im_start|>system<|im_sep|>
You are a medieval knight and must provide explanations to modern people.<|im_end|>
<|im_start|>user<|im_sep|>
How should I explain the Internet?<|im_end|>
<|im_start|>assistant<|im_sep|>和transformers
import transformers
from modelscope import snapshot_download
model_dir = snapshot_download("LLM-Research/phi-4")
pipeline = transformers.pipeline(
"text-generation",
model=model_dir,
model_kwargs={"torch_dtype": "auto"},
device_map="auto",
)
messages = [
{"role": "system", "content": "You are a medieval knight and must provide explanations to modern people."},
{"role": "user", "content": "How should I explain the Internet?"},
]
outputs = pipeline(messages, max_new_tokens=128)
print(outputs[0]["generated_text"][-1])显存占用:
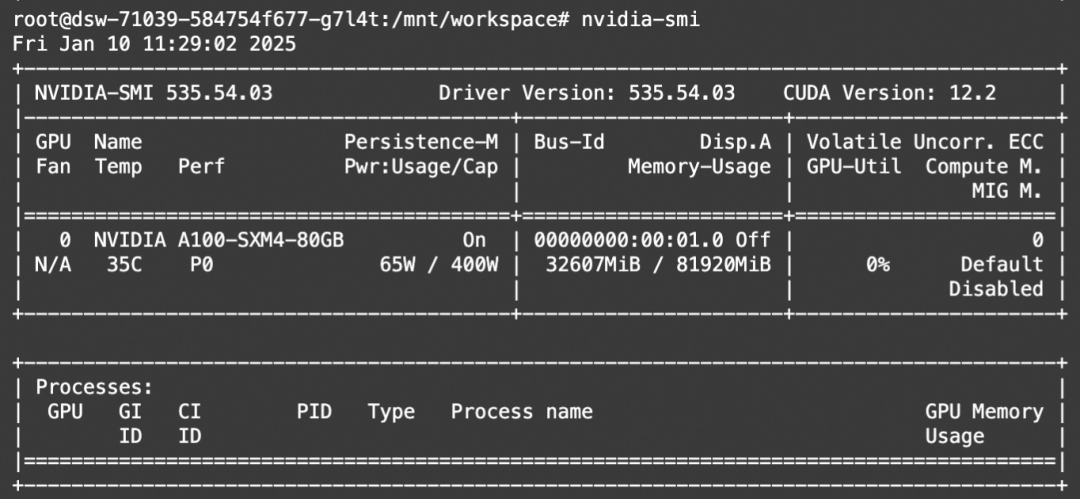
使用Ollama运行魔搭上的Phi-4模型
-
启动Ollama服务
ollama serve-
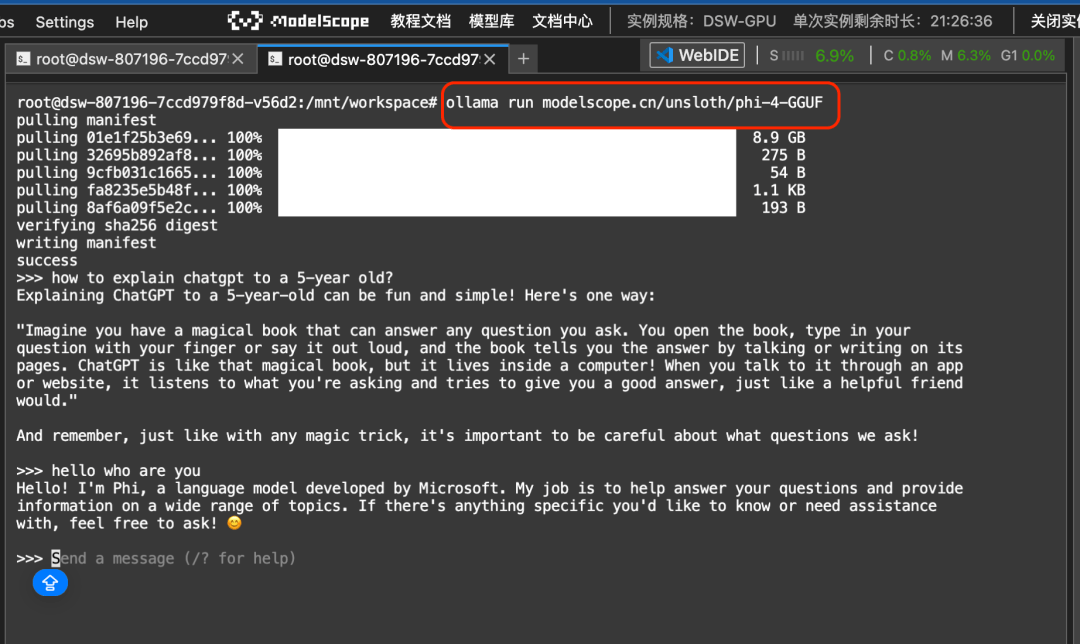
ollama run 可以运行ModelScope任意GGUF模型。比如对于Phi-4模型,这里选用的是unsloth/phi-4-GGUF
ollama run modelscope.cn/unsloth/phi-4-GGUF运行结果如下:
02.模型微调
这里我们介绍使用ms-swift 3.0对Phi-4进行自我认知微调。
在开始微调之前,请确保您的环境已正确安装
# 安装ms-swift
git clone https://github.com/modelscope/ms-swift.git
cd ms-swift
pip install -e .[llm]微调脚本如下:
CUDA_VISIBLE_DEVICES=0 \
swift sft \
--model LLM-Research/phi-4 \
--train_type lora \
--dataset 'AI-ModelScope/alpaca-gpt4-data-zh#500' \
'AI-ModelScope/alpaca-gpt4-data-en#500' \
'swift/self-cognition#500' \
--torch_dtype bfloat16 \
--num_train_epochs 1 \
--per_device_train_batch_size 1 \
--per_device_eval_batch_size 1 \
--learning_rate 1e-4 \
--lora_rank 8 \
--lora_alpha 32 \
--target_modules all-linear \
--gradient_accumulation_steps 16 \
--eval_steps 50 \
--save_steps 50 \
--save_total_limit 5 \
--logging_steps 5 \
--max_length 2048 \
--output_dir output \
--system 'You are a helpful assistant.' \
--warmup_ratio 0.05 \
--dataloader_num_workers 4 \
--model_author 魔搭 \
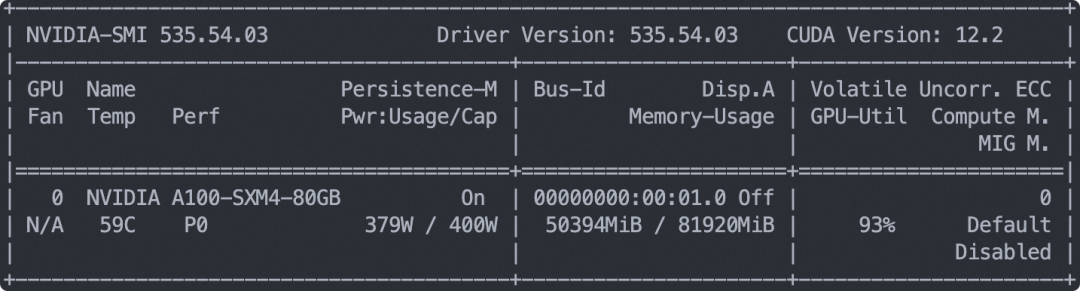
--model_name 狗蛋训练显存占用:
推理脚本:
CUDA_VISIBLE_DEVICES=0 \
swift infer \
--adapters output/vx-xxx/checkpoint-xxx \
--stream true \
--temperature 0 \
--max_new_tokens 2048推理效果:

负责任的 AI 考量
与其他语言模型一样,phi-4可能会出现不公平、不可靠或令人反感的行为。需要注意的一些限制行为包括:
-
服务质量:该模型主要针对英语文本进行训练。除英语之外的其他语言的性能会更差。训练数据中代表性较低的英语语言变体的性能可能会比标准美式英语差。phi-4不支持多语言使用。
-
危害的呈现和刻板印象的延续:这些模型可能会过度或过低地代表某些群体,抹去某些群体的代表性,或强化贬低或负面的刻板印象。尽管训练后是安全的,但由于不同群体的代表性水平不同,或训练数据中反映现实世界模式和社会偏见的负面刻板印象示例普遍存在,这些限制可能仍然存在。
-
不适当或冒犯性内容:这些模型可能会产生其他类型的不适当或冒犯性内容,如果没有针对用例的额外缓解措施,这可能使其不适合在敏感环境中部署。
-
信息可靠性:语言模型可能会生成无意义的内容或捏造听起来合理但不准确或过时的内容。
-
代码范围有限:大多数训练数据基于 Python,并使用常见软件包,例如、、、、、。phi-4如果typing模型生成的Python 脚本使用其他语言的软件包或脚本,我们强烈建议用户手动验证所有 API 的使用。mathrandomcollectionsdatetimeitertools
开发人员应采用负责任的 AI 最佳实践,并负责确保特定用例符合相关法律法规(例如隐私、贸易等)。强烈建议使用具有高级护栏的安全服务(如Azure AI Content Safety ) 。需要考虑的重要领域包括:
-
分配:如果没有进一步的评估和额外的去偏技术,模型可能不适用于可能对法律地位或资源或生活机会(例如住房、就业、信贷等)分配产生重大影响的情景。
-
高风险场景:开发人员应评估在高风险场景中使用模型的适用性,在这些场景中,不公平、不可靠或令人反感的输出可能会造成极大的成本或造成伤害。这包括在敏感或专家领域提供建议,准确性和可靠性至关重要(例如:法律或健康建议)。应根据部署环境在应用程序级别实施额外的保护措施。
-
错误信息:模型可能会产生不准确的信息。开发人员应遵循透明度最佳实践,并告知最终用户他们正在与 AI 系统交互。在应用程序级别,开发人员可以构建反馈机制和管道,以根据用例特定的上下文信息来制定响应,这种技术称为检索增强生成 (RAG)。
-
有害内容的生成:开发人员应根据其背景评估输出,并使用适合其用例的可用安全分类器或自定义解决方案。
-
滥用:可能存在欺诈、垃圾邮件或恶意软件制作等其他形式的滥用,开发人员应确保其应用程序不违反适用的法律法规。
点击链接阅读原文:phi-4

ModelScope旨在打造下一代开源的模型即服务共享平台,为泛AI开发者提供灵活、易用、低成本的一站式模型服务产品,让模型应用更简单!
更多推荐



 0
0 0
0- 0



 已为社区贡献652条内容
已为社区贡献652条内容

所有评论(0)