
魔搭支持在阿里云人工智能平台PAI上进行模型训练、部署了!
现在,魔搭上的众多模型支持在阿里云人工智能平台PAI-Model Gallery上使用阿里云算力资源进行模型训练和部署啦!
现在,魔搭上的众多模型支持在阿里云人工智能平台PAI-Model Gallery上使用阿里云算力资源进行模型训练和部署啦!
PAI-Model Gallery是阿里云人工智能平台PAI的产品组件,它集成了国内外 AI 开源社区中优质的预训练模型,涵盖了包括LLM、AIGC、CV、NLP等各个领域。通过 PAI 对这些模型的适配,用户可以通过零代码的方式实现从训练到部署再到推理的全过程,大大简化了模型的开发流程,为开发者和企业用户带来了更快、更高效、更便捷的 AI 开发和应用体验。

01.入口
用户在魔搭的模型页可以找到使用阿里云PAI-Model Gallery进行模型训练/部署的入口。(文后附上了当前支持的模型列表)
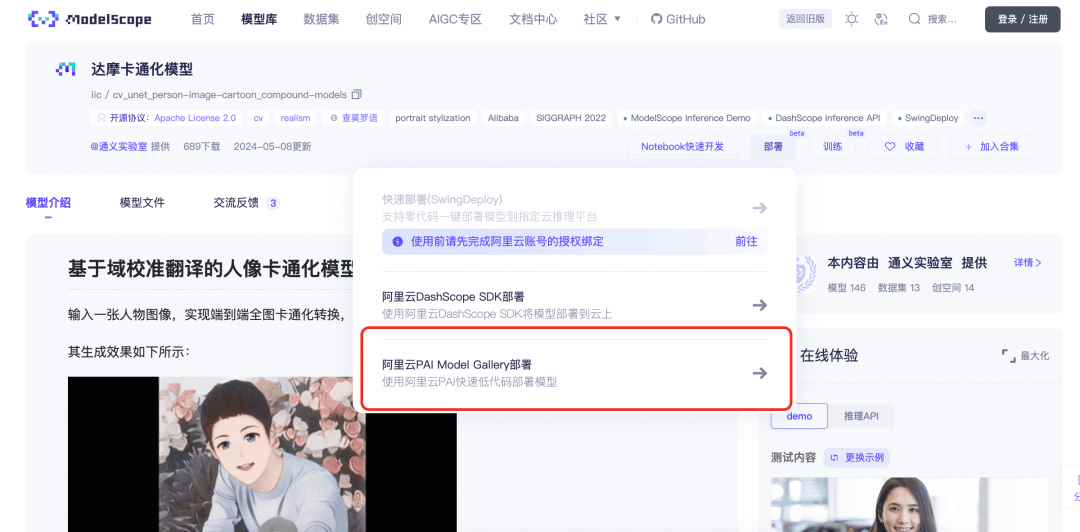
本文以当前很火的Qwen2.5-Coder模型(Qwen2.5-Coder-32B-Instruct)为例,介绍如何在 PAI-Model Gallery中进行模型的训练、部署,以及压缩和评测。
02.模型部署
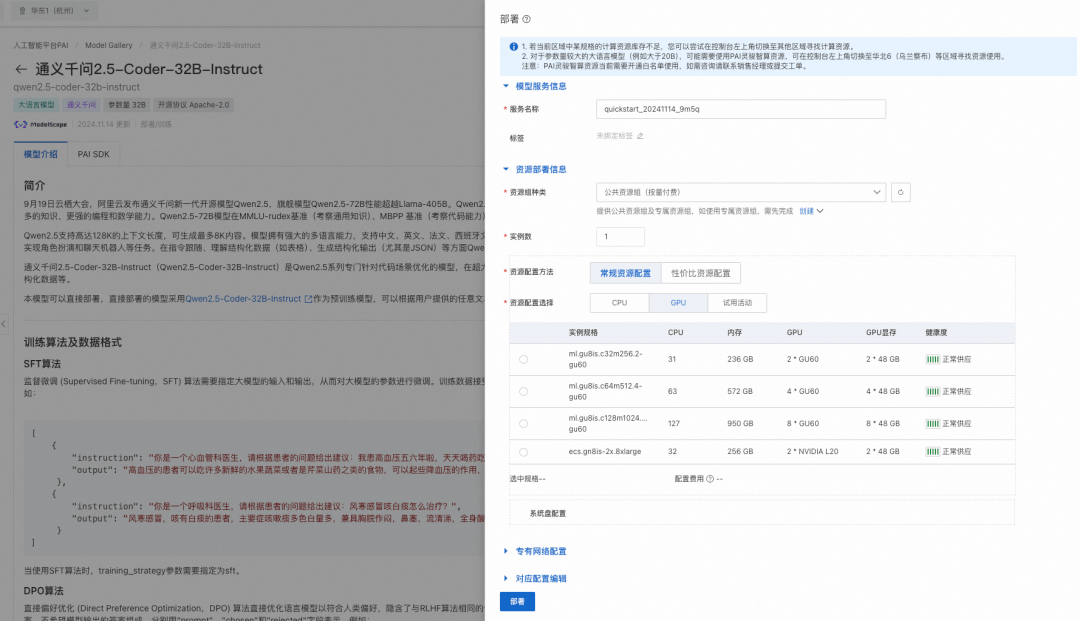
PAI 提供的 Qwen2.5-Coder-32B-Instruct 预置了模型的部署配置信息,用户仅需提供推理服务的名称以及部署配置使用的资源信息即可将模型部署成在线服务。当前模型需要使用公共资源组进行部署。
部署机型参考:
-
Qwen2.5-Coder-0.5B/1.5B需要的最低卡型配置为单卡P4,推荐部署机型为单卡GU30、单卡A10、单卡V100、单卡T4等
-
Qwen2.5-Coder-3B/7B需要的最低卡型配置为单卡P100、单卡T4、单卡V100(gn6v)等,推荐部署机型为单卡GU30、单卡A10等
-
Qwen2.5-Coder-14B需要的最低卡型配置为单卡L20、单卡GU60、双卡GU30等,推荐部署机型为双卡GU60、双卡L20等
-
Qwen2.5-Coder-32B需要的最低卡型配置为双卡GU60、双卡L20、四卡A10等,推荐部署机型为四卡GU60、四卡L20、8卡V100-32G
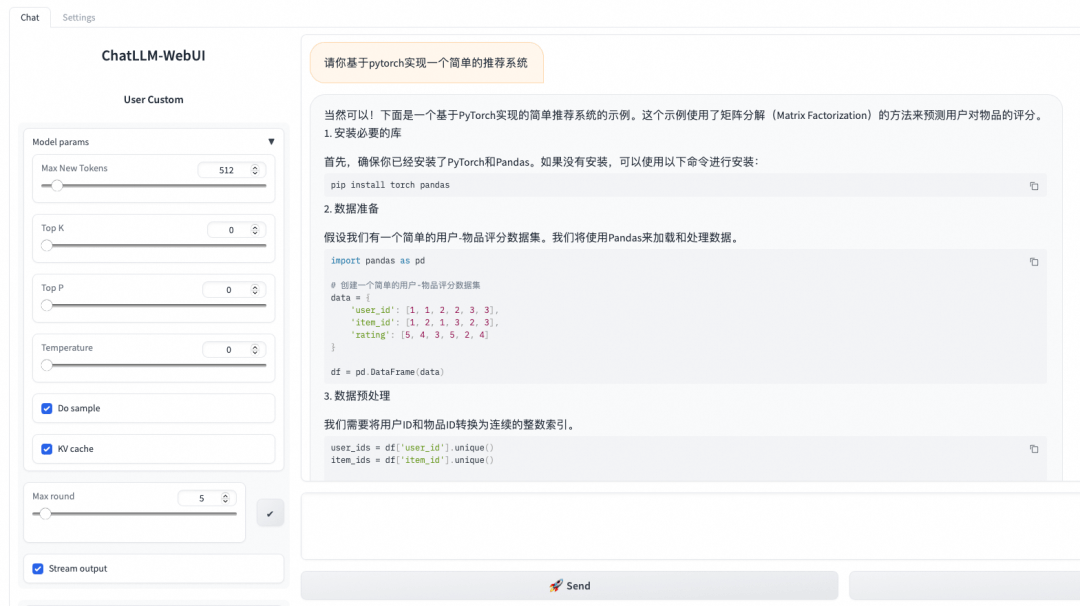
部署的推理服务支持使用 ChatLLM WebUI 进行实时交互,示例如下:
推理服务支持以 OpenAI API 兼容的方式调用。
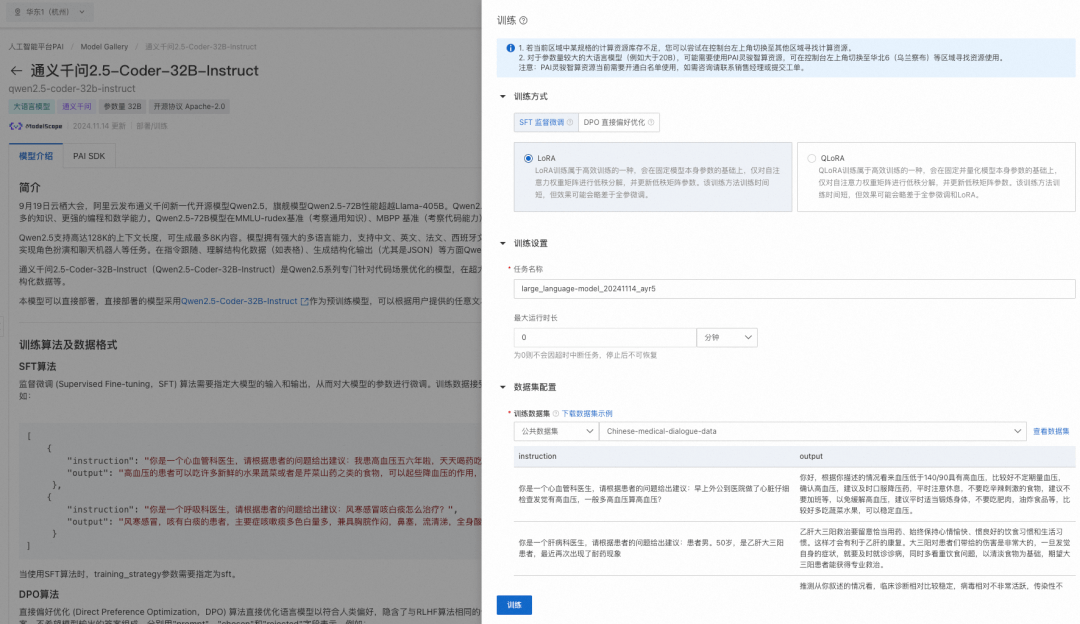
03.模型微调训练
PAI-Model Gallery为 Qwen2.5-Coder 模型配置了 SFT(监督微调) 和 DPO(直接偏好优化) 两种微调算法,支持用户以开箱即用的方式对模型进行微调。SFT 训练算法支持使用 Json 格式的训练数据集,每条数据由问题、答案组成,分用“instruction”、“output”字段表示,例如:
[
{
"instruction": "Create a function to calculate the sum of a sequence of integers.",
"output": "# Python code\ndef sum_sequence(sequence):\n sum = 0\n for num in sequence:\n sum += num\n return sum"
},
{
"instruction": "Generate a Python code for crawling a website for a specific type of data.",
"output": "import requests\nimport re\n\ndef crawl_website_for_phone_numbers(website):\n response = requests.get(website)\n phone_numbers = re.findall('\\d{3}-\\d{3}-\\d{4}', response.text)\n return phone_numbers\n \nif __name__ == '__main__':\n print(crawl_website_for_phone_numbers('www.example.com'))"
}
]DPO 训练算法支持使用 Json 格式输入,每条数据由问题、预期模型输出的答案、不希望模型输出的答案组成,分别用"prompt"、"chosen"和"rejected"字段表示,例如:
[
{
"prompt": "Create a function to calculate the sum of a sequence of integers.",
"chosen": "# Python code\ndef sum_sequence(sequence):\n sum = 0\n for num in sequence:\n sum += num\n return sum",
"rejected": "[x*x for x in [1, 2, 3, 5, 8, 13]]"
},
{
"prompt": "Generate a Python code for crawling a website for a specific type of data.",
"chosen": "import requests\nimport re\n\ndef crawl_website_for_phone_numbers(website):\n response = requests.get(website)\n phone_numbers = re.findall('\\d{3}-\\d{3}-\\d{4}', response.text)\n return phone_numbers\n \nif __name__ == '__main__':\n print(crawl_website_for_phone_numbers('www.example.com'))",
"rejected": "def remove_duplicates(string): \n result = \"\" \n prev = '' \n\n for char in string:\n if char != prev: \n result += char\n prev = char\n return result\n\nresult = remove_duplicates(\"AAABBCCCD\")\nprint(result)"
}
]当完成数据的准备,用户可以将数据上传到对象存储 OSS Bucket 中。由于32B模型较大,算法需要使用 A800/H800(80GB显存)的 GPU 资源,请确保选择使用的资源配额内有充足的计算资源。
对于各尺寸模型,训练资源可参考:
-
Qwen2.5-Coder-0.5B/1.5B量级模型:最低使用16GB显存(例如T4、P100、V100)及以上卡型运行训练任务
-
Qwen2.5-Coder-3B/7B量级模型:最低使用24GB显存(例如A10、T4)及以上卡型运行训练任务
-
Qwen2.5-Coder-14B量级模型:最低使用32GB显存(例如V100)及以上卡型运行训练任务
-
Qwen2.5-Coder-32B量级模型:最低使用80GB显存(例如A800/H800)及以上卡型运行训练任务
训练算法支持的超参信息如下,用户可以根据使用的数据,计算资源等调整超参,或是使用算法默认配置的超参。
|
超参数 |
默认值 |
类型 |
含义 |
|
training_strategy |
sft |
string |
训练算法,可以为sft或者dpo |
|
learning_rate |
5e-5 |
float |
模型训练的学习率 |
|
num_train_epochs |
1 |
int |
训练轮次 |
|
per_device_train_batch_size |
1 |
int |
每张GPU卡在一次训练迭代的数据量 |
|
seq_length |
128 |
int |
文本序列长度 |
|
lora_dim |
32 |
int |
LoRA维度(当lora_dim>0时,使用LoRA/QLoRA轻量化训练) |
|
lora_alpha |
32 |
int |
LoRA权重(当lora_dim>0时,使用LoRA/QLoRA轻量化训练,该参数生效) |
|
load_in_4bit |
true |
bool |
模型是否以4比特加载(当lora_dim>0,load_in_4bit为true且load_in_8bit为false时,使用4比特QLoRA轻量化训练) |
|
load_in_8bit |
false |
bool |
模型是否以8比特加载(当lora_dim>0,load_in_4bit为false且load_in_8bit为true时,使用8比特QLoRA轻量化训练) |
|
gradient_accumulation_steps |
8 |
int |
梯度累积步数 |
|
apply_chat_template |
true |
bool |
算法是否为训练数据加上模型默认的chat template以DistilQwen2系列模型为例,格式为问题:<|im_end|>\n<|im_start|>user\n + instruction + <|im_end|>\n答案:<|im_start|>assistant\n + output + <|im_end|>\n |
|
system_prompt |
true |
string |
模型训练使用的系统提示语,默认为You are a helpful assistant |
点击“训练”按钮,开始进行训练,用户可以查看训练任务状态和训练日志。
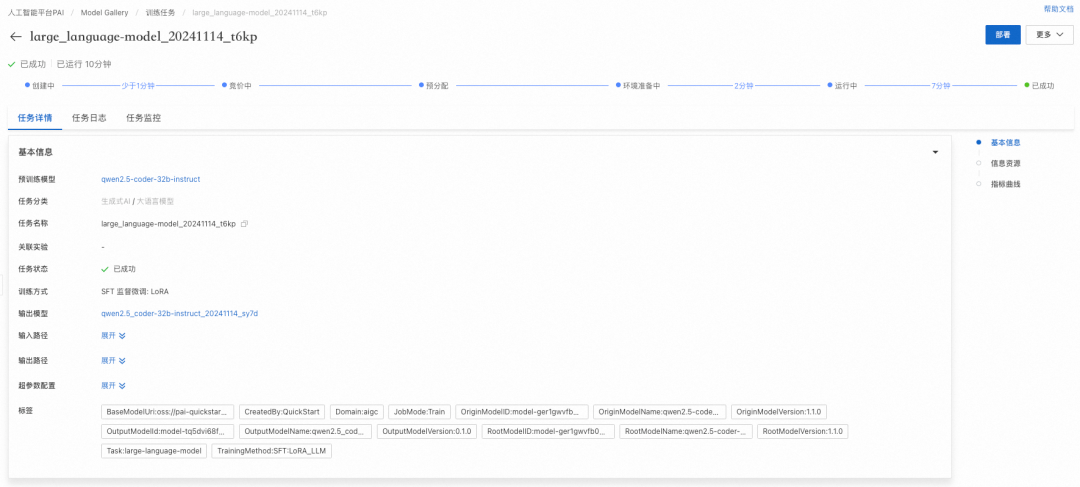
训练完成的模型同样可以部署成在线服务。
04.其他功能
PAI-Model Gallery除提供模型训练和模型部署功能外,还提供了模型压缩、模型评测功能。下面简要介绍一下。
模型评测
PAI-Model Gallery内置了常见评测算法,支持用户以开箱即用得方式对预训练模型以及微调后的模型进行评测。通过评测能帮助用户评估模型性能,同时支持多模型的评测对比,指导用户精准地选择合适的模型。
模型评测入口:
|
直接对预训练模型进行评测 |
|
|
在训练任务详情页对微调后的模型进行评测 |
|
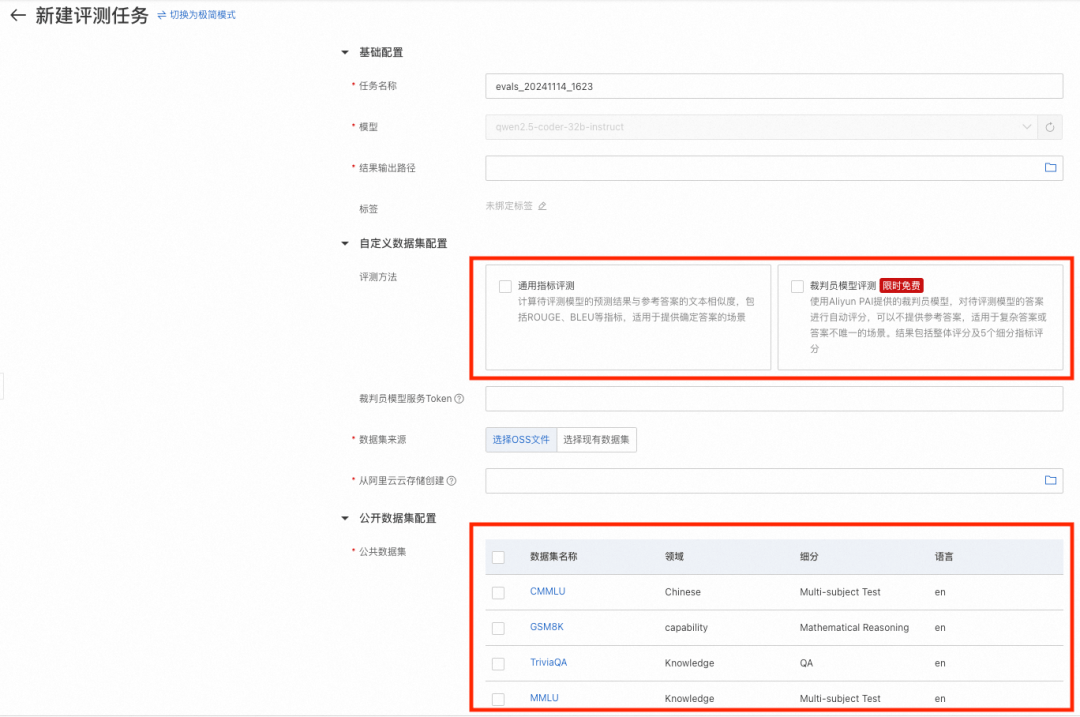
模型评测支持自定义数据集评测和公开数据集评测:
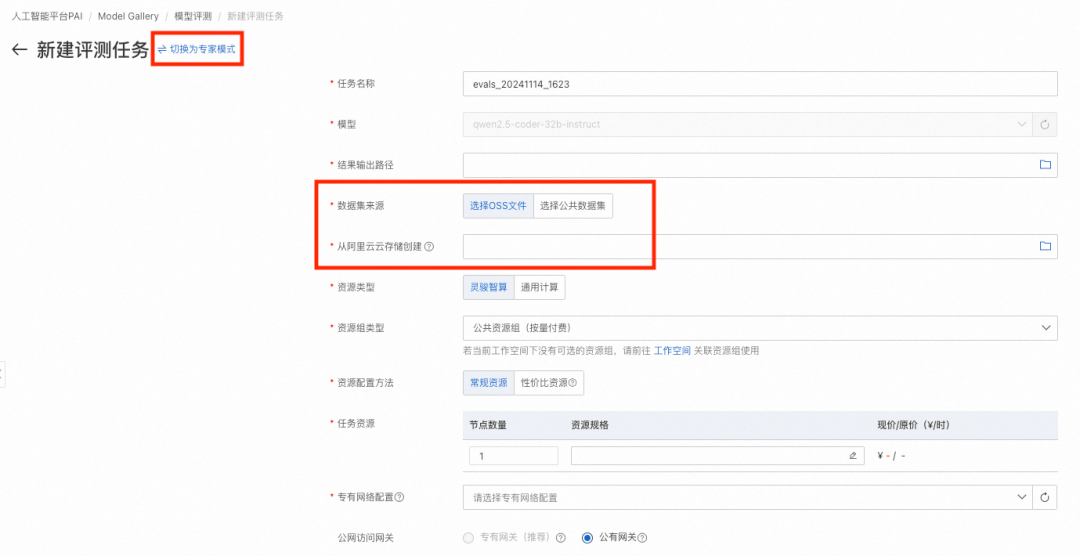
-
自定义数据集评测
-
模型评测支持文本匹配指标BLEU/ROUGLE,以及裁判员模型评测(专家模式)。用户可以基于自己场景的独特数据,评测所选模型是否适合自己的场景。
-
评测需要提供JSONL格式的评测集文件,每行数据是一个List,使用question标识问题列,answer标识答案列。示例文件:evaluation_test.jsonl
-
公开数据集评测
-
通过对开源的评测数据集按领域分类,对大模型进行综合能力评估。目前PAI维护了MMLU、TriviaQA、HellaSwag、GSM8K、C-Eval、TruthfulQA,其他公开数据集陆续接入中。
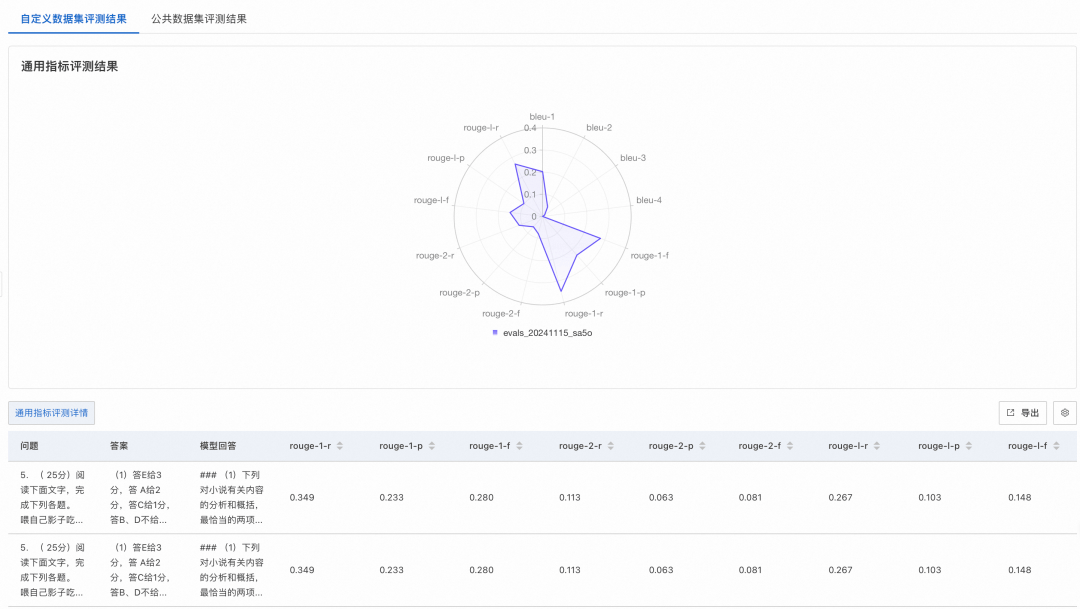
之后选择评测结果输出路径,并根据系统推荐选择相应计算资源,最后提交评测任务。等待任务完成,在任务页面查看评测结果。自定义数据集和公开数据集评测结果示例如下:
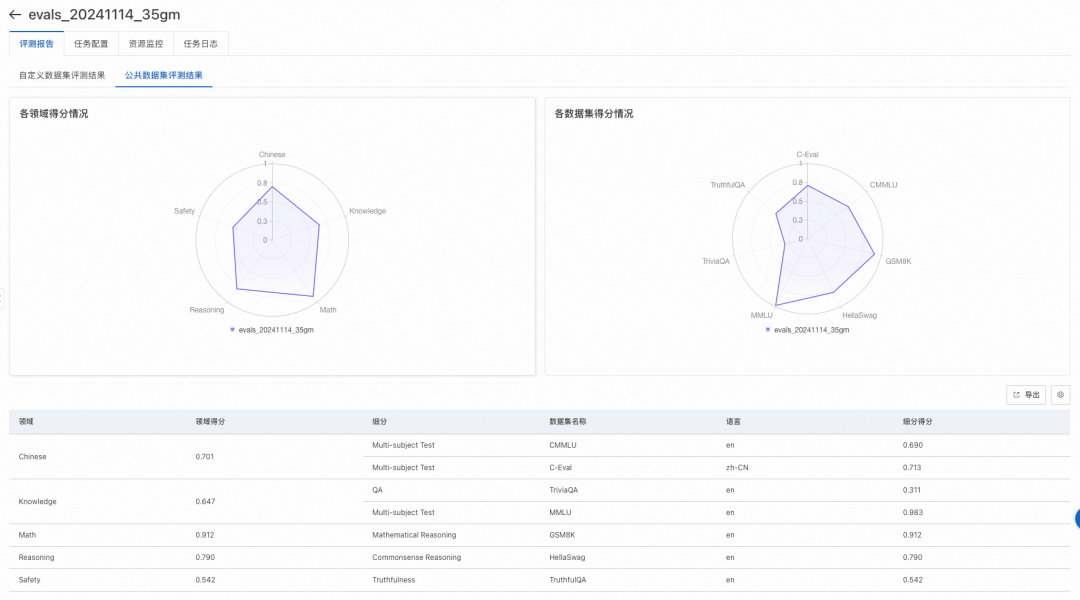
模型压缩
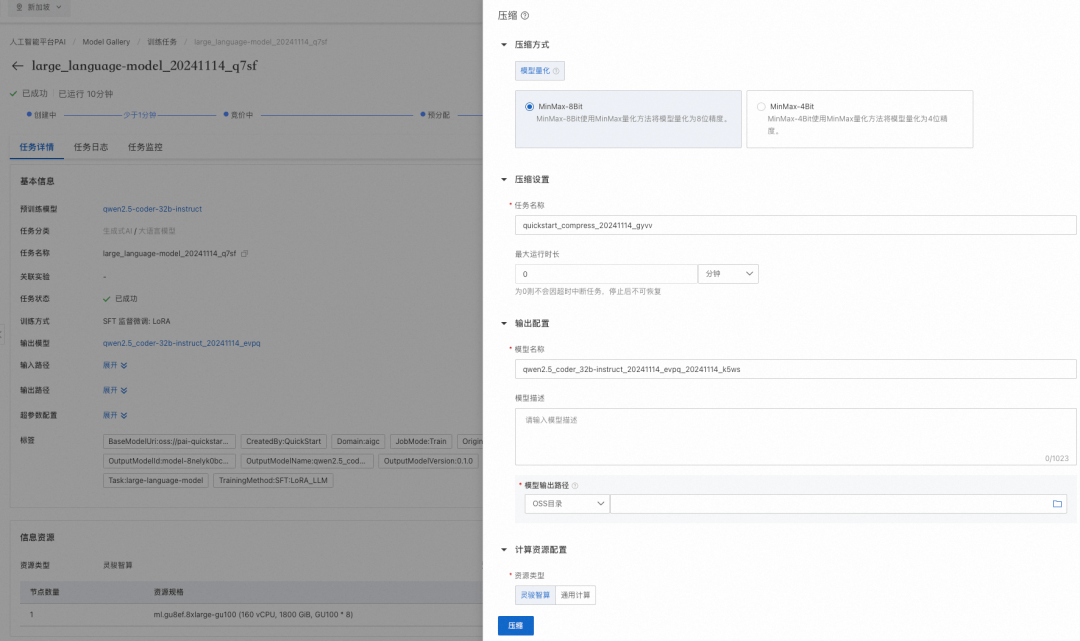
经过训练后的模型在部署之前可以对模型进行量化压缩以减小模型部署资源占用量,在模型训练任务界面可以创建模型压缩任务。和模型训练相同,配置压缩方式、压缩设置、输出配置以及计算资源后,创建压缩任务:
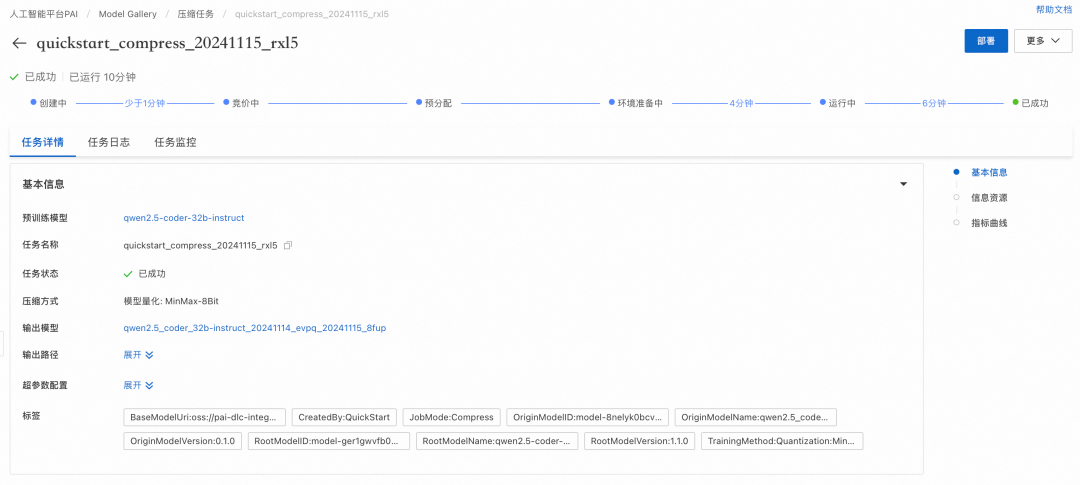
开始压缩之后可以看到压缩任务界面。当压缩完成后,点击部署即可对压缩后的模型进行一键部署。
05.One more thing
阿里重磅开源的模型 QwQ-32B-Preview、Marco-o1,也已经在PAI-Model Gallery上支持训练、部署了,欢迎社区的小伙伴使用体验~
06.相关参考
-
PAI-Model Gallery介绍:
https://help.aliyun.com/zh/pai/user-guide/quick-start-overview

ModelScope旨在打造下一代开源的模型即服务共享平台,为泛AI开发者提供灵活、易用、低成本的一站式模型服务产品,让模型应用更简单!
更多推荐


 0
0 0
0- 0



 已为社区贡献650条内容
已为社区贡献650条内容

所有评论(0)