
HelloMeme:充分利用 SD1.5 基模的理解能力,实现表情与姿态的迁移
为了利用最新的 Diffusion 生成技术实现表情迁移
演示视频 :
https://developer.aliyun.com/live/254739?spm=a2c6h.26396819.creator-center.6.404f3e18lbecg1
项目主页 :
https://songkey.github.io/hellomeme
论文链接 :
https://arxiv.org/abs/2410.22901
在线体验链接 :
https://www.modelscope.cn/studios/songkey/HelloMeme
01.论文解读
为了利用最新的 Diffusion 生成技术实现表情迁移,本文作者经过实践并试图回答三个问题:
-
如何实现夸张而丰富的表情迁移,且保证生成效果的自然感和物理合理性?
-
如何利用 StableDiffusion 基座模型的理解能力以及 SD1.5 开源社区的模型库,实现更多样化的内容创造?
-
该方案是否具有扩展到全身以及半身构图的潜力?
对于第一个问题,作者提出了一种代表全局的头部姿态和代表局部的面部表情相解耦的条件注入方法;为了解决第二个问题, 作者设计了一个生成框架,引入了业界常用的 ReferenceNet 结构, 使用具有创新性的空间交织注意力机制 (Spatial Knitting Attentions) 将参考图像信息与控制信息融合到去噪网络,它使得整个框架在基座模型权重固定的情况下, 依旧可以收敛得到高质量的生成效果;最后一个问题,因为使用了基于 StableDiffusion 的生成框架, 业界已经有相似的工作实现了全身和半身构图的可控生成,所以作者认为这个方案同样具有扩展到全身和半身构图的潜力。
框架概览
网格框架的结构如下图所示,由 HMControlNet、HMReferenceNet、HMDenosingNet 三个部分组成。从功能上看HMControlNet 用于编码头部姿态和面部表情相关的控制信息, HMReferenceNet 用于编码参考图像信息,HMDenosingNet 接收前二者提供的特征,实现可控持去噪生成;从实现的角度看,HMReferenceNet 和 HMDenosingNet 均是在 SD1.5 Unet 的基础上,做了轻量的修改, 且保持基座模型的权重不变。
HMControlNet 是全新设计的结构,下文会详细介绍;更具体地,从代码角度看, 这个工作继承了 Diffusers 库的基础类,使用清晰紧凑的代码(其中核心框架代码 hellomeme/models/*.py 共 1200 行左右) 实现了一个完整的生成框架。作者在最新的源码更新了 HelloMemeV2,其中对网络结构进行了大幅的调整, 可以推测简单代码结构使得框架调整成本更低。
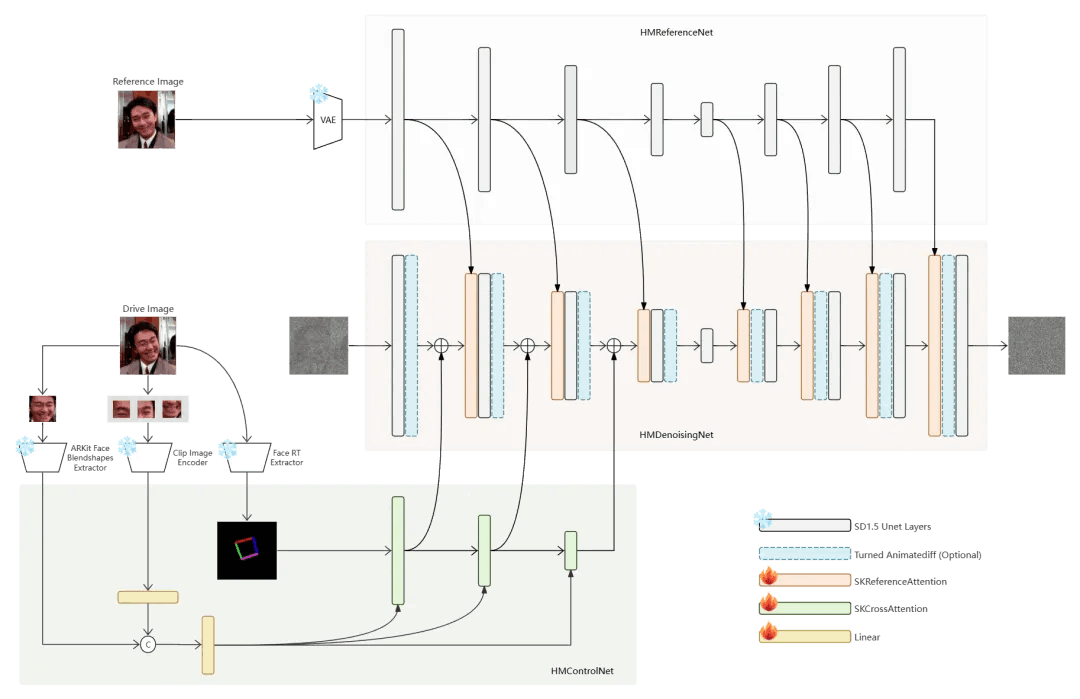
图1. 网格框架的结构
空间交织注意力机制
文章中提到 2D FeatureMap 做 SelfAttention 或者与线性特征做 Cross Attention 时, 一般会将 FeatureMap 逐行拉长为线性特征,做完 Attention 后再 reshape 为 2D FeatureMap。即使 FeatureMap 拉长后可以加上 2d position encodding, 但这个操作还是会在一定程度上破坏 2d 的空间结构信息。
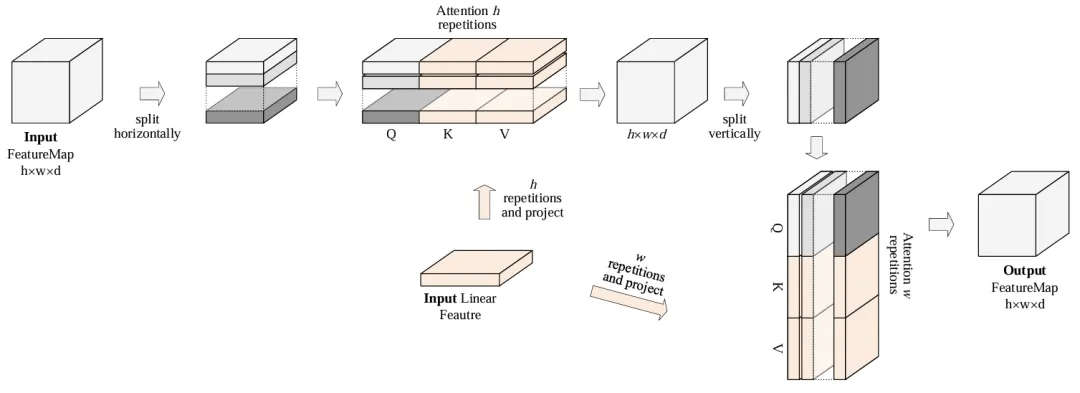
图2. 空间交织注意力的第一种实现
所以作者将 2D FeatureMap 直接线性化后做 Attention 的操作修改为先逐行做 Attention, 然后再逐列做 Attention。在解决表情包生成的任务中,作者发现使用前者要更新全部参数才能艰难地收敛, 而使用后者仅更新插入模块的有限参数就可以收敛到很好的结果。后者的操作过程类似纺织时经纬线交织的状态, 所以他把这种机制称为 空间交织注意力 (Spatial Knitting Attentions)。
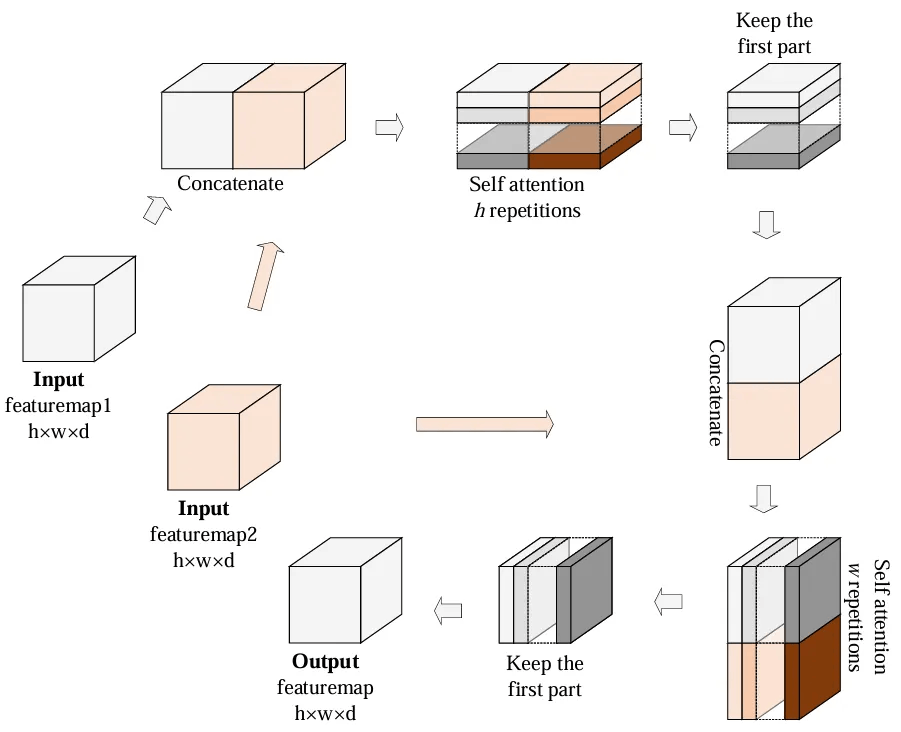
图3. 空间交织注意力的第二种实现
作者认为空间交织注意力机制之所以有效是因为它天然地保持了2D FeatureMap 的结构信息, 神经网络不必重新理解这一概念,同时作者在附录中详细讨论了这种机制的特点。
控制模块
作者认为控制模块重要创新在于将头部姿态和面部表情信息解耦。因为面部表情虽然是局部的运动, 但却传递了比头部姿态带宽更大的信息,且在训练时容易产生泄漏本来流言来自 Reference Image 的 ID 信息, 所以这部分的设计尤为关键。文章中作者提供了一种组合的面部表情编码方式,后续的源码更新时又提供了 PD-FGC 的编码方式。
运动模块
以上模块组合可以实现单张图像的可控生成。一个有意思的做法是,由于这个框架内基座模型参数未破坏兼容性较好, 作者直接为 HMDenosingNet 引入了同样兼容性不错的 Animatediff,便实现了低成本的视频生成。当然,为了提升生成质量,作者最终提供了微调后的 Animatediff。为了解决视频片断间的连续性问题, 作者又设计了两阶段的生成流程,实现了长视频的生成能力。
实验
作者分别对比了 HelloMeme 与其他方法的客观指标与主观效果,可以看到 HelloMeme 的生成效果更具优势。
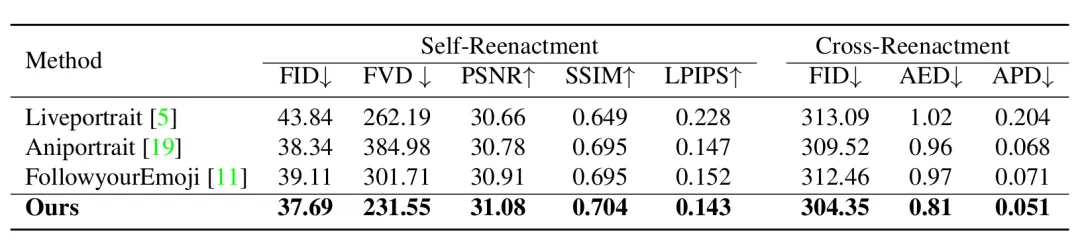
表1. 客观指标对比
但作者也提到 HelloMeme 生成的视频帧间连续性不够好仍有待提升,这个问题在客观指标上并不能体现。

图4. 主观效果对比
总结
本文设计了一种结构简约生成框架,利用 Diffusion 基座模型实现了表情迁移的任务。它也提供了一种有效的利用 T2I 基座模型在垂类场景下 Post-Training 以解决复杂问题思路。最后,作者认为基于 Diffusion 的生成框架未来会有更大的扩展潜力。
02.最佳实践
作者使用 魔搭社区(https://www.modelscope.cn/studios/songkey/HelloMeme) 免费提供的GPU免费算力部署了 HelloMeme 的 gradio 界面,可以在上面直接体验 HelloMeme 的生成效果。如 图5 所示,界面中包含了图像和视频生成的功能,用户可以上传自己的图片或视频,选择不同的模型版本。其中提供了两种不同风格的 checkpoint 可供体验。想试用更多的第三方模型,可以下载 源码(https://github.com/HelloVision/HelloMeme) 在本地试用。
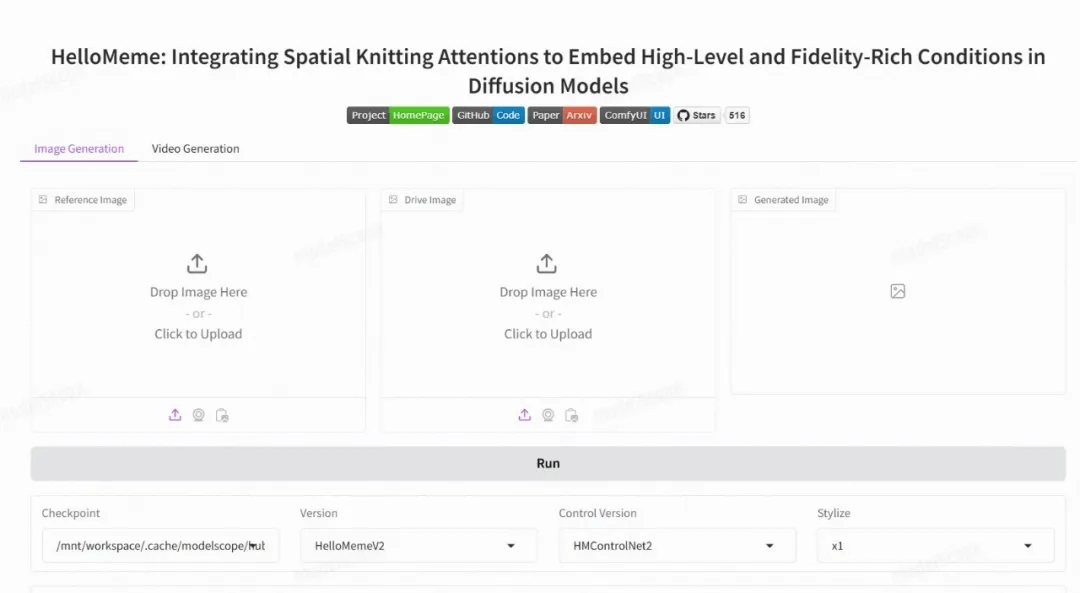
图5. modelscope interface
作者也提供了对应的 ComfyUI Node(https://github.com/HelloVision/ComfyUI_HelloMeme), 但目前仅支持本地部署,未来会考虑在 魔搭社区(https://www.modelscope.cn/aigc/workflows) 的 AIGC 专区部署。
点击链接阅读原文:HelloMem

ModelScope旨在打造下一代开源的模型即服务共享平台,为泛AI开发者提供灵活、易用、低成本的一站式模型服务产品,让模型应用更简单!
更多推荐


 0
0 0
0- 0



 已为社区贡献639条内容
已为社区贡献639条内容

所有评论(0)