
魔搭社区每周速递(12.15-12.21)
魔搭ModelScope本期社区进展:1914个模型,58个数据集,78个创新应用, 8篇内容

🙋魔搭ModelScope本期社区进展:
📟1914个模型:RWKV-7系列、浦语·灵笔 2.5(InternLM-XComposer2.5-OmniLive)、CosyVoice2-0.5B、Megrez-3B-Omni、FuseChat-3.0等;
📁58个数据集:aya_collection_language_split、Global-MMLU-Lite、m-ArenaHard等;
🎨78个创新应用:CosyVoice2-0.5B、Megrez-3B-Omni、fish-speech-1等;
📄 8篇内容:
-
RWKV-7:极先进的大模型架构,长文本能力极强
-
多模态实时交互大模型浦语·灵笔 2.5 OmniLive开源:能看、能听、会记、会说!
-
CompassArena上新!JudgeCopilot与新一代Bradley-Terry模型重塑大模型竞技体验
-
社区供稿 | 引入隐式模型融合技术,中山大学团队推出 FuseChat-3.0
-
温暖接力:“追星星的AI”再出发,志愿者招募令!
-
Megrez-3B-Omni: 首个端侧全模态理解开源模型
-
ModelScope魔搭12月版本发布月报
-
CosyVoice再升级,可扩展流式语音合成
01.精选模型
RWKV-7系列:
RWKV-7 是一个先进的最新大模型架构,超越 attention / linear attention 范式,拥有强大的 in-context-learning(上下文学习)能力,可真正持续学习,在保持 100% RNN 的同时,拥有极强的长文本能力。RWKV-7 采用了动态状态演化(Dynamic State Evolution),超越了 attention / linear attention 范式 TC0 表达能力的根本限制。同时,RWKV-7 拥有 NC1 的表达能力,使其可以解决许多 attention 无法解决的问题。
模型链接:
RWKV-7-World:
https://modelscope.cn/models/Blink_DL/rwkv-7-world
RWKV-7-Pile:
https://www.modelscope.cn/models/Blink_DL/rwkv-7-pile
浦语·灵笔 2.5(InternLM-XComposer2.5-OmniLive)
书生·浦语灵笔2.5-OL(InternLM-XComposer2.5-OmniLive)是一个多模态实时交互大模型,模型可以通过视觉和听觉实时观察和理解外部世界,自动形成对观察到内容的长期记忆,并可通过语音与人类用户进行对话交谈,提供更自然的大模型交互体验。
它基于书生·浦语2.5大语言模型(InternLM 2.5)研发,采用了多模块通专融合的架构方案,通过多模态实时感知及记忆编码的快系统和多模态复杂推理大模型的慢系统协同,实现多模态实时交互功能。
模型链接:
https://modelscope.cn/models/Shanghai_AI_Laboratory/internlm-xcomposer2d5-ol-7b
示例代码:
import torch
from modelscope import AutoModel, AutoTokenizer
torch.set_grad_enabled(False)
# init model and tokenizer
model = AutoModel.from_pretrained('Shanghai_AI_Laboratory/internlm-xcomposer2d5-ol-7b', model_dir='base', torch_dtype=torch.bfloat16, trust_remote_code=True).cuda().eval().half()
tokenizer = AutoTokenizer.from_pretrained('Shanghai_AI_Laboratory/internlm-xcomposer2d5-ol-7b', model_dir='base', trust_remote_code=True)
model.tokenizer = tokenizer更多推理、微调实战详见:
多模态实时交互大模型浦语·灵笔 2.5 OmniLive开源:能看、能听、会记、会说!
CosyVoice2-0.5B
CosyVoice 2是通义实验室推出的改进型流式语音合成模型,通过有限标量量化、简化模型架构和块感知的因果流匹配,实现了高质量的多语言语音合成,具有低延迟和实时性,相较1.0版本,存在以下优势:
-
超低延迟:结合离线与流式建模技术,支持双向流式语音合成,首包合成延迟仅150ms,几乎无音质损失。
-
高准确率:相较于1.0版本,发音错误率降低30%-50%,在Seed-TTS评估集上实现了最低字符错误率。
-
稳定性强:确保零样本语音生成及跨语言合成时的音色一致性,跨语言性能大幅提升。
-
自然体验:音频韵律、音质和情感对齐显著改进,MOS评分从5.4提升至5.53(商用模型可比得分5.52)。此外,增强了可控音频生成能力,提供更精细的情感表达和方言口音调整。
模型链接:
https://modelscope.cn/models/iic/CosyVoice2-0.5B
示例代码:
cli下载
modelscope download --model iic/CosyVoice2-0.5Bpython SDK下载
#模型下载
from modelscope import snapshot_download
model_dir = snapshot_download('iic/CosyVoice2-0.5B')模型推理
clone代码repo
git clone --recursive https://github.com/FunAudioLLM/CosyVoice.git
# If you failed to clone submodule due to network failures, please run following command until success
cd CosyVoice
git submodule update --init --recursive
pip install -r requirements.txt下载模型到对应路径
from modelscope import snapshot_download
snapshot_download('iic/CosyVoice2-0.5B', local_dir='pretrained_models/CosyVoice2-0.5B')指定python路径
export PYTHONPATH=third_party/Matcha-TTSCosyVoice2模型推理
from cosyvoice.cli.cosyvoice import CosyVoice, CosyVoice2
from cosyvoice.utils.file_utils import load_wav
import torchaudio
cosyvoice = CosyVoice2('pretrained_models/CosyVoice2-0.5B', load_jit=True, load_onnx=False, load_trt=False)
# zero_shot usage
prompt_speech_16k = load_wav('zero_shot_prompt.wav', 16000)
for i, j in enumerate(cosyvoice.inference_zero_shot('收到好友从远方寄来的生日礼物,那份意外的惊喜与深深的祝福让我心中充满了甜蜜的快乐,笑容如花儿般绽放。', '希望你以后能够做的比我还好呦。', prompt_speech_16k, stream=False)):
torchaudio.save('zero_shot_{}.wav'.format(i), j['tts_speech'], cosyvoice.sample_rate)
# fine grained control, for supported control, check cosyvoice/tokenizer/tokenizer.py#L248
prompt_speech_16k = load_wav('zero_shot_prompt.wav', 16000)
for i, j in enumerate(cosyvoice.inference_cross_lingual('在他讲述那个荒诞故事的过程中,他突然[laughter]停下来,因为他自己也被逗笑了[laughter]。', prompt_speech_16k, stream=False)):
torchaudio.save('fine_grained_control_{}.wav'.format(i), j['tts_speech'], cosyvoice.sample_rate)
# instruct usage
for i, j in enumerate(cosyvoice.inference_instruct2('收到好友从远方寄来的生日礼物,那份意外的惊喜与深深的祝福让我心中充满了甜蜜的快乐,笑容如花儿般绽放。', '用四川话说这句话', prompt_speech_16k, stream=False)):
torchaudio.save('instruct_{}.wav'.format(i), j['tts_speech'], cosyvoice.sample_rate)更多部署实战详见:
Megrez-3B-Omni
Megrez-3B-Omni 是由无问芯穹(Infinigence AI)开发的端侧全模态理解模型,基于 Megrez-3B-Instruct 扩展,具备图片、文本和音频三种模态数据的理解分析能力,并在各模态上均达到最优精度:
-
图像理解:利用 SigLip-400M 构建图像 Token,在 OpenCompass 榜单(涵盖8个主流多模态评测基准)上平均得分66.2,超越了参数规模更大的 LLaVA-NeXT-Yi-34B 等模型。它还在 MME、MMMU 和 OCRBench 等测试集中表现出色,尤其擅长场景理解和OCR。
-
语言理解:保持与单模态版本(Megrez-3B-Instruct)相近的文本处理精度,变化小于2%,在 C-EVAL、MMLU/MMLU Pro 和 AlignBench 等多个测试集上持续领先,超过上一代14B模型的表现。
-
语音理解:采用 Qwen2-Audio/whisper-large-v3 的编码器支持中英文语音输入及多轮对话,允许用户通过语音对输入图片提问并获得文本响应,在多项基准任务中取得优异成绩。
模型链接:
https://modelscope.cn/models/InfiniAI/Megrez-3B-Omni
示例代码:
cli下载
modelscope download --model InfiniAI/Megrez-3B-Omnipython SDK下载
#模型下载
from modelscope import snapshot_download
model_dir = snapshot_download('InfiniAI/Megrez-3B-Omni')模型推理
如下是一个使用transformers进行推理的例子,通过在content字段中分别传入text、image和audio,可以图文/图音等多种模态和模型进行交互。
import torch
from modelscope import AutoModelForCausalLM
model = (
AutoModelForCausalLM.from_pretrained(
"InfiniAI/Megrez-3B-Omni",
trust_remote_code=True,
torch_dtype=torch.bfloat16,
attn_implementation="flash_attention_2",
)
.eval()
.cuda()
)
# Chat with text and image
messages = [
{
"role": "user",
"content": {
"text": "Please describe the content of the image.",
"image": "./data/sample_image.jpg",
},
},
]
# Chat with audio and image
messages = [
{
"role": "user",
"content": {
"image": "./data/sample_image.jpg",
"audio": "./data/sample_audio.m4a",
},
},
]
MAX_NEW_TOKENS = 100
response = model.chat(
messages,
sampling=False,
max_new_tokens=MAX_NEW_TOKENS,
temperature=0,
)
print(response)FuseChat-3.0
FuseChat-3.0是一个新推出的模型,通过隐式融合四个强大的源LLM和五个目标LLM,实现了在对话、指令遵循、数学和编码任务中的显著性能提升,特别在Llama-3.1-8B-Instruct目标模型上取得了平均6.8分的提升,并在AlpacaEval-2和Arena-Hard测试集上分别实现了37.1分和30.1分的大幅改进,现已在魔搭modelscope社区发布。
模型链接:
https://www.modelscope.cn/models/FuseAI/FuseChat-Llama-3.2-3B-Instruct
参数表
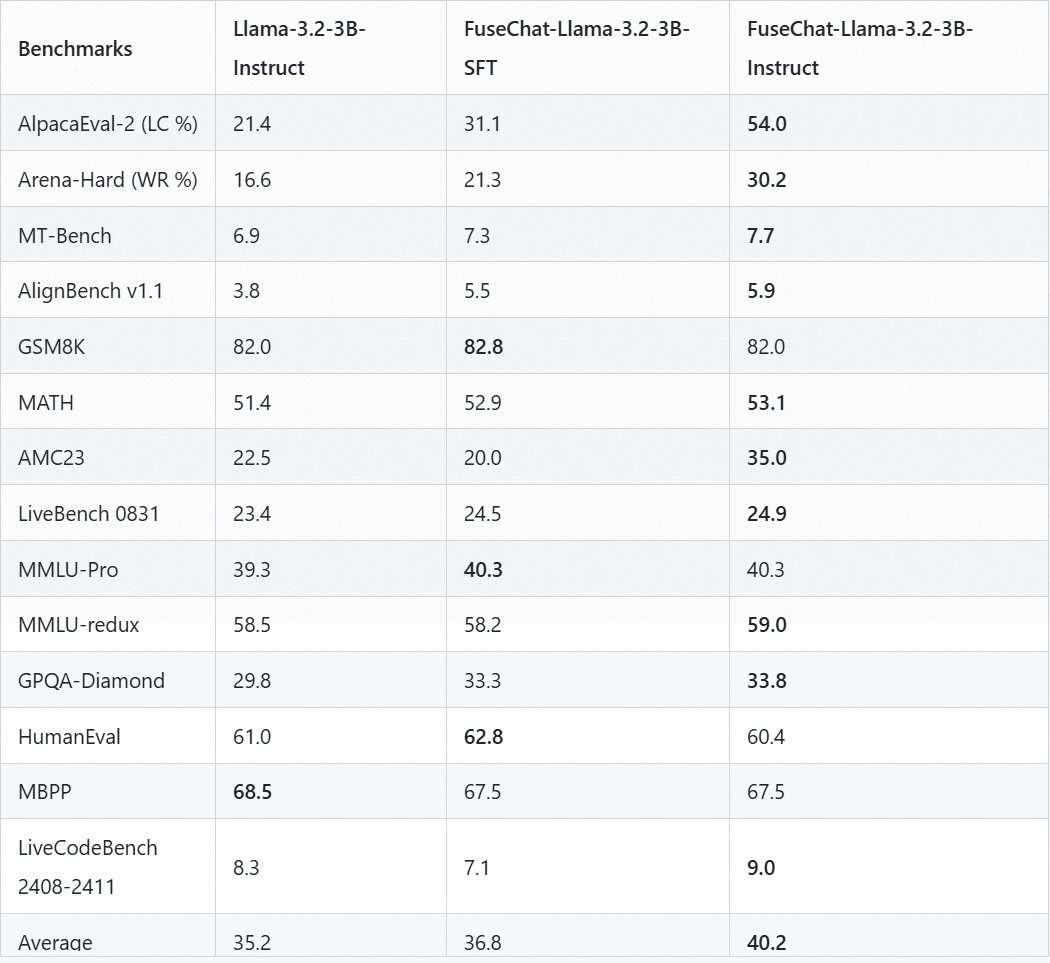
更多详情详见:
社区供稿 | 引入隐式模型融合技术,中山大学团队推出 FuseChat-3.0
02.数据集推荐
aya_collection_language_split
Aya Collection 是一个庞大的多语言集合,包含 5.13 亿个提示和完成实例,涵盖各种任务。该集合整合了来自流利说话者的指令式模板,并将其应用于精选的数据集列表,以及将指令式数据集翻译成 101 种语言。Aya 数据集是人工精选的多语言指令和响应数据集,也是该集合的一部分
数据集链接:
https://modelscope.cn/datasets/CohereForAI/aya_collection_language_split
Global-MMLU-Lite
Global-MMLU-Lite是多语言理解数据集,旨在评估和提升AI系统对不同语言和文化背景的理解能力。
数据集链接:
https://modelscope.cn/datasets/CohereForAI/Global-MMLU-Lite
m-ArenaHard
m-ArenaHard 数据集是一个多语言 LLM 评估集。该数据集是通过使用 Google Translate API v3 将最初仅英语的 LMarena (以前称为 LMSYS) arena-hard-auto-v0.1 测试数据集中的提示翻译成 22 种语言而创建的。最初的仅英语的提示由 Li 等人 (2024) 创建,包含来自 Chatbot Arena 的 500 个具有挑战性的用户查询。作者表明,这些可用于执行自动 LLM 评委评估,这与 Chatbot Arena 排名具有高度相关性。此数据集中包含的 23 种语言
数据集链接:
https://modelscope.cn/datasets/CohereForAI/m-ArenaHard
03.精选应用
RWKV-Gradio-1:
RWKV-7 系列,作为仅 0.1B 参数的 L12-D768 小模型,RWKV-7-World-0.1B 拥有超越其尺寸的综合能力
体验直达:
https://modelscope.cn/studios/Blink_DL/RWKV-Gradio-1
CosyVoice2-0.5B
CosyVoice2-0.5B是语音合成模型,拥有5亿参数,旨在生成自然语音,支持文本的输入+音频文件的输入,生成对应的音频。
体验直达:
https://modelscope.cn/studios/iic/CosyVoice2-0.5BMegrez-3B-Omni
Megrez-3B-Omni是无问芯穹研发的端侧全模态理解模型,具备图像、文本、音频三种模态数据的理解分析能力,在图像理解、语言理解和语音理解三个方面均取得最优精度,表现出色,支持各类问答。
体验直达:
https://modelscope.cn/studios/AI-ModelScope/Megrez-3B-Omnifish-speech-1
由 Fish Audio 研发的基于 VQ-GAN 和 Llama 的多语种语音合成.
体验直达:
https://modelscope.cn/studios/fishaudio/fish-speech-104.社区精选文章

ModelScope旨在打造下一代开源的模型即服务共享平台,为泛AI开发者提供灵活、易用、低成本的一站式模型服务产品,让模型应用更简单!
更多推荐



 0
0 0
0- 0



 已为社区贡献652条内容
已为社区贡献652条内容

所有评论(0)