

智源研究院发布中文高质量数据集CCI3.0-HQ技术报告
智源研究院发布CCI3.0-HQ:中文预训练数据集的新里程碑
01.摘要
近年来,自然语言基础模型(LLM)取得了显著进展,训练数据的规模扩展以及数据质量的提升是提升模型性能的关键因素。目前英文开源语料的质量过滤已经从基础的规则方法转向了模型驱动的方法。然而,中文开源语料相对稀缺,同时针对中文网络数据进行质量分类提升的研究较少,导致数据质量尚未达到理想水平,进而影响模型中文性能。
为解决以上问题,进一步缓解中文预训练语料规模和质量上的差距,2024年9月20日,智源研究院发布并开源了中文预训练数据集CCI3.0和高质量子集CCI3.0-HQ。2024年10月25日,智源研究院发布中文高质量预训练数据集CCI3.0-HQ技术报告,全面解析数据集的构建过程。
主要贡献总结如下:
-
发布CCI3.0-HQ,这是一个突破性的500GB中文预训练数据集,采用了先进的混合质量过滤方法,显著提升了数据完整性。
-
进行严格的实验评估,结果表明CCI3.0-HQ在性能上显著优于原版CCI3.0数据集和其他主流开源中文语料库,从而建立了新的性能基准。
-
推出并开源CCI3-HQ分类器,这是一种先进的质量分类工具,大幅改进大语言模型训练中的数据选择流程。
数据集下载地址:
-
https://www.modelscope.cn/datasets/BAAI/CCI3-HQ
-
http://open.flopsera.com/flopsera-open/data-details/BAAI-CCI3-HQ
-
https://data.baai.ac.cn/details/BAAI-CCI3-HQ
质量分类器下载地址:
https://www.modelscope.cn/models/BAAI/CCI3-HQ-Classifier
技术报告地址:
https://arxiv.org/abs/2410.18505
02.CCI3.0-HQ 构建

图1. CCI3.0-HQ数据集构建流程概述
如图1所示,数据处理流程包括两个主要阶段:基础处理和高质量处理。原始数据涵盖了丰富的中文语料来源,包括新闻、社交媒体和博客,从而增强了数据集的覆盖面和代表性。经过基础处理,获得CCI3.0数据集。接着通过基于模型的高质量处理进一步优化,最终得到CCI3.0-HQ数据集。CCI3.0-HQ数据集的关键是高质量处理阶段,具体由高质量样本自动标注和高质量分类器训练两个主要步骤组成。
2.1 高质量样本自动标注
高质量处理的主要关注点是在预训练的背景下精确定义“高质量”。在探索和比较了2种领先方法后,采用了FineWeb-edu方法来定义高质量样本,专注于筛选中文的高质量教育内容,以提升中文语料的整体质量。在质量标准确定后,接下来的挑战是高效地构建数大量符合标准的样本。为此,使用本地部署的大尺寸开源模型对CCI3.0数据集中随机抽取的145,000个网页样本进行评分,评分范围为0(非教育性)到5(高度教育性)。最后,对部分标注结果进行了人工和GPT-4评估,达到了超过80%的一致率。
2.2 高质量分类器训练
通过上面的自动化流程累计了数十万个标注样本,随后训练了一个较小的质量分类模型以实现大规模高效标注。该方法在确保正确识别高质量样本的同时显著降低了成本,从而以实用的资源投入完成数据集的全面标注。质量分类模型由BGE-M3模型和扩展分类头组成。基于模型调优实验,训练期间,嵌入层和编码器层保持冻结,以专注于分类头的优化。最后,将模型转换为二元分类器,使用评分阈值为3,并将该分类器应用于约15亿样本,该过程耗费9700小时的A100 GPU算力。
03.CCI3.0-HQ 实验
3.1模型预训练实验
使用相同的模型架构并且数据集总量100B进行从头预训练,主要设计了两项主要实验来评估不同数据集性能:
-
混合数据集实验:该数据集包括60%的英文、10%的代码和30%的中文内容。在英文部分,使用了FineWeb-edu数据集;代码数据则来自StarCoder。
-
中文数据集实验:该实验使用了100%中文内容的数据集,对比目前开源规模较大的数据集比如Wanjuan-v1、SkyPile、CCI3.0和CCI3.0-HQ数据集。
-
实验结果如表1所示:在混合数据集实验和中文数据集实验中,CCI3.0-HQ数据集在大多数指标上表现优异,显著超过了其他数据集。与CCI3.0数据集相比的显著提升也证明了对中文预训练语料进行高质量过滤的重要性。另外如图2所示,在模型训练过程进行阶段评测,CCI3.0-HQ数据集表现稳定胜出。
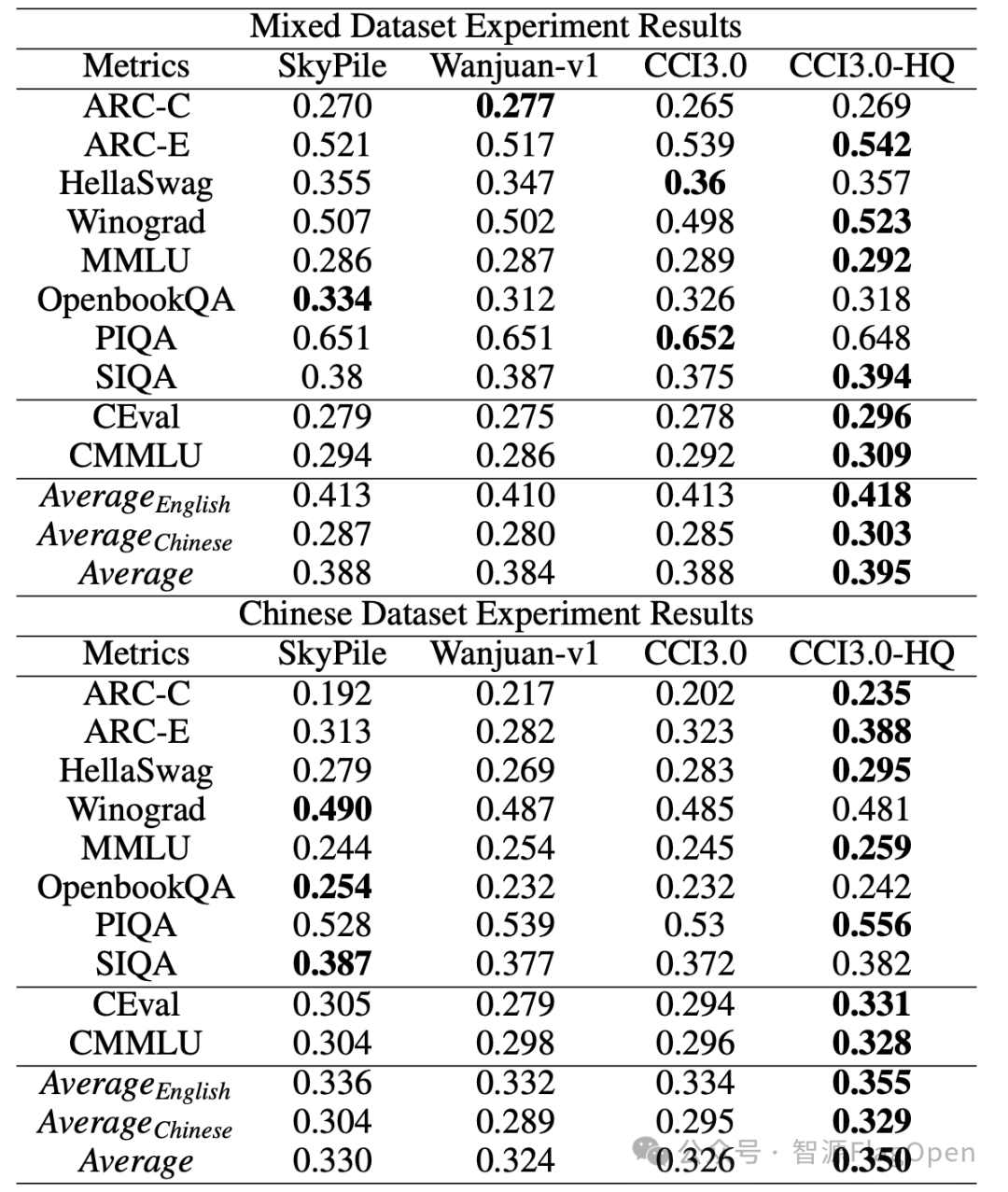
表1. 混合数据集实验和中文数据集实验中数据集对模型性能的影响对比
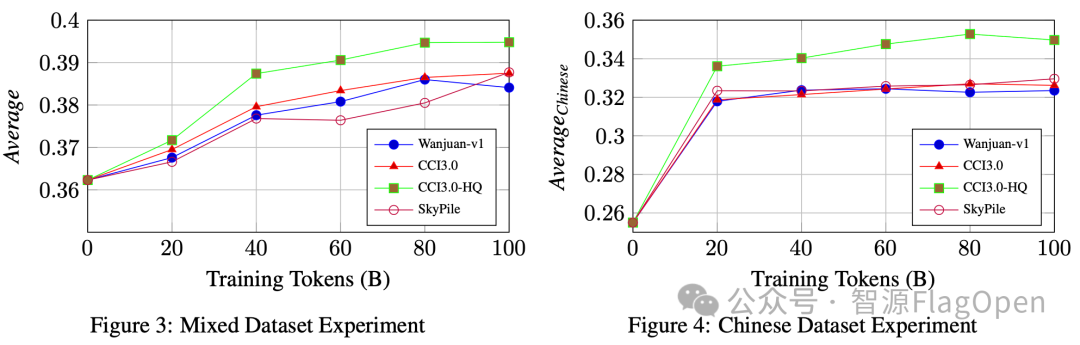
图2. 训练过程中不同数据集对模型性能的影响对比
3.2 质量分类器实验
如表2结果所示,与现有开源的分类器相比,自主训练的CCI3.0-HQ-Classifier在处理多样化数据和区分高质量内容方面表现出显著提升。这一结果突显了合理质量过滤在预训练中的关键作用,也是CCI3.0-HQ数据集相较于原始CCI3.0数据集性能更优的关键因素。

表2.不同质量分类器的评估
04.总结&未来工作
在本工作中,智源研究院发布并开源CCI3.0-HQ数据集,该数据集采用了复杂的混合质量过滤方法,以提升数据的完整性。通过从头开始训练小规模模型的对比实验和严格的实验评估,CCI3.0-HQ显著优于现有知名的中文开源数据集。同时,智源还推出并开源了CCI3-HQ分类器,与现有的中英文开源质量分类器相比,其表现更为优越。CCI3.0-HQ数据集也充分展示了高质量过滤在中文大语言模型预训练中的重要性。
之后研究团队还会从以下几方面对工作进行改进:
1、进一步完善数据质量分类,增加质量数据的多样性和复杂性。
2、进一步增加中文高质量预训练语料的规模。

ModelScope旨在打造下一代开源的模型即服务共享平台,为泛AI开发者提供灵活、易用、低成本的一站式模型服务产品,让模型应用更简单!
更多推荐



 0
0 1
1- 0



 已为社区贡献456条内容
已为社区贡献456条内容

所有评论(0)