
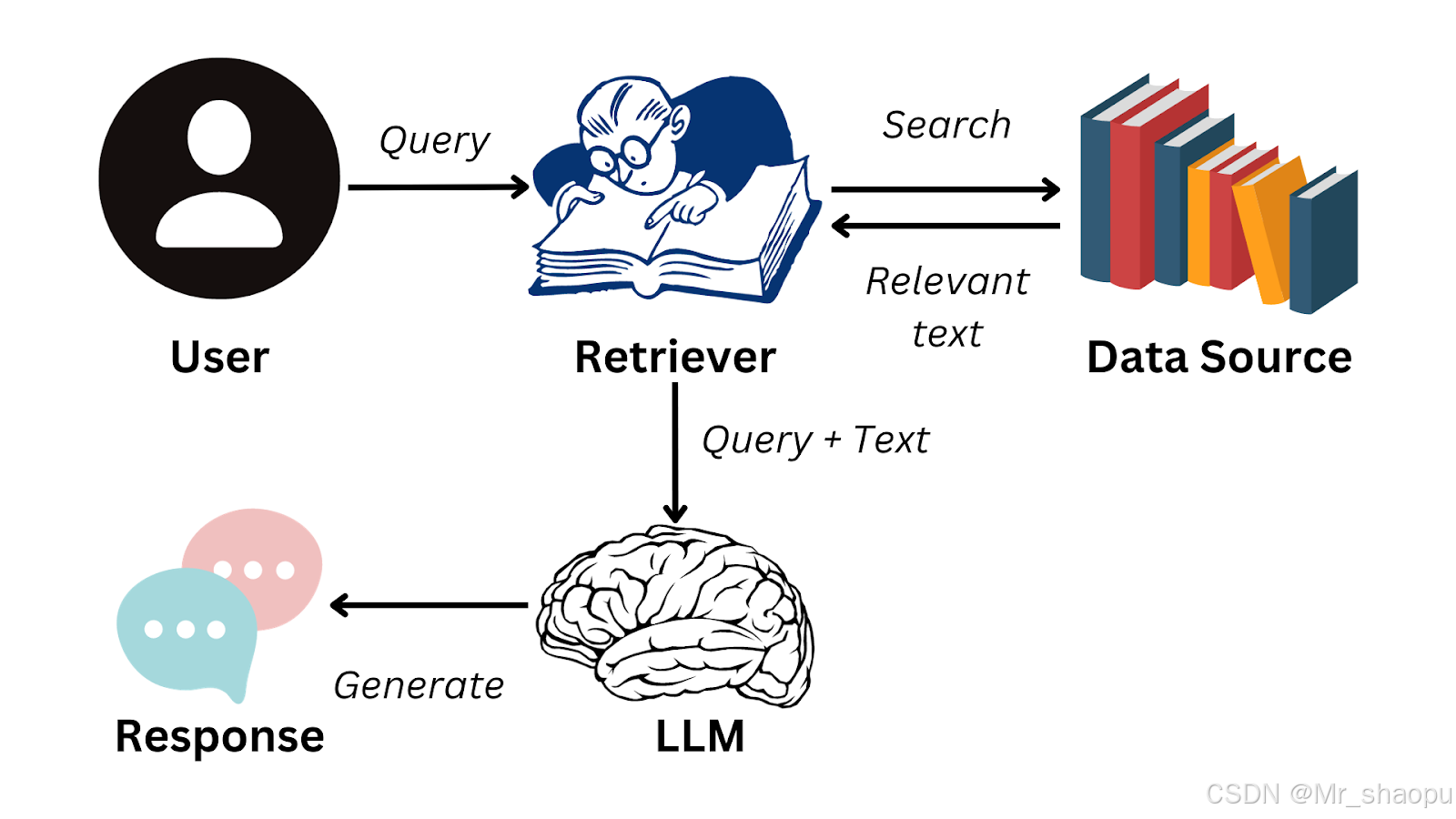
选择题型RAG检索增强实践——llamaindex_Qwen2.5-7B——(1)快速上手型
DataFountain比赛实践,使用Qwen2.5-7B-instruct 语言模型,结合RAG技术,实现基于规则集的选择题判断。
文章目录
实现目标
本次实践目标是借助RAG检索增强,通过外置知识库,辅助大模型完成选择题的回答,本代码是用于完成DataFountain的一场比赛,获得了较好的结果,现希望将实践的代码展示出来,在锻炼自身文案写作能力,重新梳理学习过程的同时,与大家共勉共同提高。
赛题简介
赛题题目:面向大语言模型的领域知识注入与推理
快速辅助决策在很多特定领域的应急处置中有广泛引用(如火灾、地震等)。传统方法依赖规则知识图谱推理方法,虽然在一定程度上保证了决策的逻辑性和可解释性,但也面临着诸多问题,包括误差传播、推理复杂度、以及知识更新的不便捷性。这些问题在快节奏的应急处置中尤为突出,影响了决策的效率和准确性。
随着人工智能技术的发展,大模型的出现为决策和处置提供了全新的思路。在民用领域,比如医学和法律,大模型通过知识注入的方式学习大量的实例数据(如病例、判决书),已经展现出了处理复杂推理任务的潜力。不依赖显式图谱,理解隐含在数据中的规则,从而提供合理的决策、处置方案。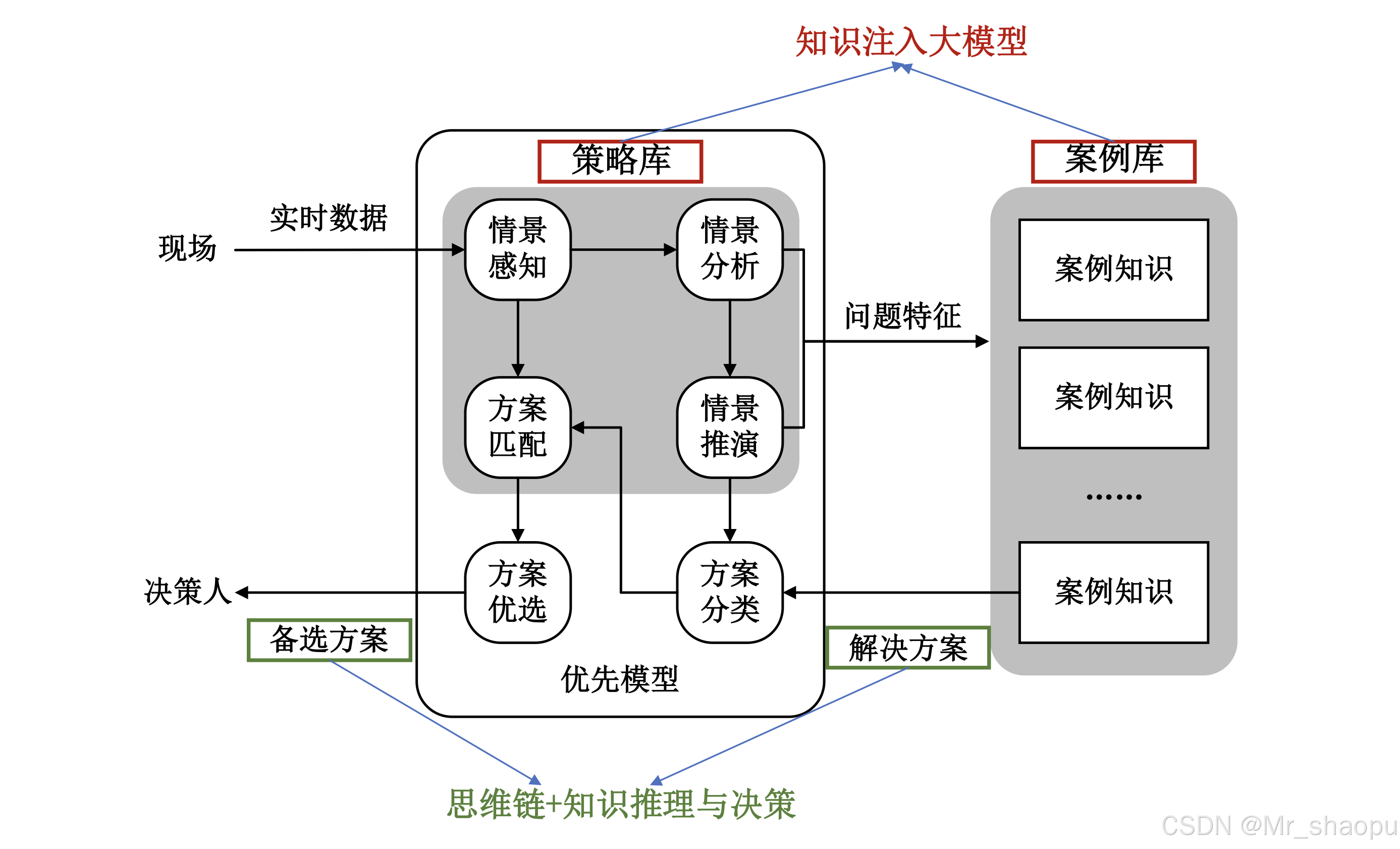 在特定场景中,尽管规则类知识体系较为完备,实例类数据却相对稀缺,难以获得大量的实例数据来完整覆盖所有可能的情况。这种数据的稀缺性直接导致了模型训练的困难,并在处理未见过的新实例时性能受限,难以泛化到未知的、新颖的场景中。
在特定场景中,尽管规则类知识体系较为完备,实例类数据却相对稀缺,难以获得大量的实例数据来完整覆盖所有可能的情况。这种数据的稀缺性直接导致了模型训练的困难,并在处理未见过的新实例时性能受限,难以泛化到未知的、新颖的场景中。
这些挑战要求研究新的方法论和技术,以弥补规则知识与实例数据之间的鸿沟。本赛题旨在探索基于大语言模型知识注入技术,实现特定领域规则知识与实例数据相统一。通过将实例推理结果与规则进行映射,提升军事决策的准确性和效率,增强推理结果的可解释性,将具体的决策过程与背后的规则知识紧密联系起来,进一步提高决策过程的透明度和可靠性。
针对上述挑战和现有方法的不足,本赛题设置基于规则知识的应急处置推理任务,全面考察参赛选手模型的泛化性和可解释性。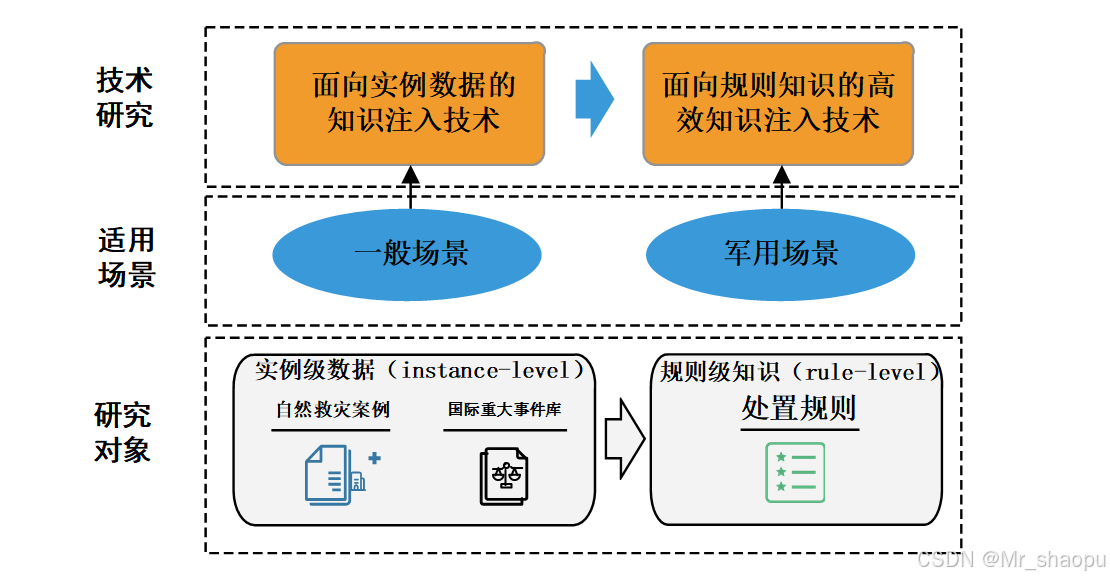
对此,本小组希望使用RAG技术进行尝试。RAG的全称是Retrieval-Augmented Generation,中文翻译为检索增强生成。它是一个为大模型提供外部知识源的概念,这使它们能够生成准确且符合上下文的答案,同时能够减少模型幻觉。
任务要求
以规则文本的形式给定1000条应急处置规则知识和对应的实例类数据。其中规则类知识表达精准,实例类数据表达多样,要求大模型能够注入规则类数据后,具有面向下游实例类数据的推理能力。规则类知识格式为{规则ID,规则文本}。参赛者可以选择对中文大模型进行规则知识注入的方法,如LoRA或者RAG。训练完成后,选手需要提交相关的模型文件和结果文件,由主办方进行测试。测试数据为基于规则知识构造的实例问题,需要选手给出答案和做出该处置所参考的规则ID。
本赛题采用的规则知识来源于中国应急处置库中预案文档,经过整理划分得到1000条明确的规则知识。而具体的应急实例问题采用基于隐马尔可夫链约束的受控文本生成方法构造获得,对应于特定的若干条规则知识。
规则格式如下:
[
{
"rule_id": "1",
"rule_text": "危险化学品事故是指危险化学品生产、经营、储存、运输、使用和废弃危险化学品处置等过程中由危险化学品造成人员伤害、财产损失和环境污染的事故(矿山开采过程中发生的有毒、有害气体中毒、爆炸事故、放炮事故除外)。"
},
{
"rule_id": "2",
"rule_text": "协调指挥机构与职责:在国务院及国务院安委会统一领导下,安全监管总局负责统一指导、协调危险化学品事故灾难应急救援工作,国家安全生产应急救援指挥中心(以下简称应急指挥中心)具体承办有关工作。安全监管总局成立危险化学品事故应急工作领导小组(以下简称领导小组)。领导小组的组成及成员单位主要职责:组长:安全监管总局局长;副组长:安全监管总局分管调度、应急管理和危险化学品安全监管工作的副局长。成员单位:办公厅、政策法规司、安全生产协调司、调度统计司、危险化学品安全监督管理司、应急救援指挥中心、机关服务中心、通信信息中心、化学品登记中心。"
}...
]
问题格式如下:
[
{
"question_id": "1",
"question_text": "问题:在某大型国际机场,一架注册号为B-7389的民用航空客机,在进行长途飞行任务中,遇到突发的恶劣天气。该航班原计划从城市A直飞城市B,总飞行距离达到2000公里。由于飞行过程中进入了一个不稳定的气候区,导致航班严重颠簸,并伴随有短时间的失速迹象,乘客和机组人员感到极度不安。尽管最终航班安全降落,但该事件在乘客、机组人员中引起了极大恐慌,并在社会媒体上引发广泛关注。根据民用航空器飞行事故应急处置规则中的条例。请问,根据上述描述,该事件应被分类为何种应急响应级别?\n选择:A. 不启动任何应急响应 B. 启动Ⅰ级应急响应 C. 启动Ⅱ级应急响应 D. 启动Ⅲ级应急响应"
},
{
"question_id": "2",
"question_text": "问题:在关于风暴潮、海浪、海啸和海冰灾害的应急响应启动前期工作中,某海洋管理机构收到了关于预计即将到来的海洋灾害的警报。为确保所辖海区的安全与响应效率,这个机构计划立即执行规定的预防措施。根据相关规则,该机构必须在收到海洋灾害消息后的确定时间内完成特定任务。这项任务包括组织开展观测和数据传输设施设备的巡检工作,并及时排除发现的隐患。在以下选项中,请指出这个机构应在收到海洋灾害消息后多长时间内完成这项关键的巡检工作?\n选择:A. 6 小时内 B. 12 小时内 C. 24 小时内 D. 48 小时内"
}...
]
输出答案格式要求:
[
{
"question_id": "1",
"answer": "C",
"rule_id": [
"74",
"92"
]
},
{
"question_id": "2",
"answer": "C",
"rule_id": [
"74",
"92"
]
}...
]
实践过程
环境配置
本实践均在本地服务器上实现,所使用的模型均部署在本地
import torch
from llama_index.core import Settings,StorageContext,VectorStoreIndex,Document,load_index_from_storage
from llama_index.core.node_parser import SentenceSplitter
from llama_index.llms.huggingface import HuggingFaceLLM
from llama_index.embeddings.huggingface import HuggingFaceEmbedding
import time
import json
import re
上图为实践所需要用到的所有依赖库。
pip install llama-index
pip install llama-index-llms-huggingface
pip install llama-index-core
pip install llama-index-embeddings-huggingface
上述命令是对后面要用到的 llamaindex 进行配置,针对 torch 的配置需要根据自身 CUDA 的情况进行配置,网上有很多帖子,这里就不再赘述。
模型下载
本实践所用到的有两个模型,分别是用于实现问答的语言模型 Qwen2.5-7B-Instruct 和用于支持中文文档检索的嵌入模型 bge-base-zh-v1.5
Qwen2.5-7B-Instruct 下载链接:
https://huggingface.co/Qwen/Qwen2.5-7B-Instruct
https://www.modelscope.cn/models/qwen/Qwen2.5-7B-Instruct
https://ai.gitee.com/hf-models/Qwen/Qwen2.5-7B-Instruct
bge-base-zh-v1.5 下载链接:
https://huggingface.co/BAAI/bge-base-zh
https://www.modelscope.cn/models/AI-ModelScope/bge-base-zh-v1.5/summary
https://gitee.com/hf-models/bge-base-zh-v1.5
提示模板
定义生成提示模板,以增强模型的回答生成能力:
def completion_to_prompt(completion):
return f"<|im_start|>system\n<|im_end|>\n<|im_start|>user\n{completion}<|im_end|>\n<|im_start|>assistant\n"
def messages_to_prompt(messages):
prompt = ""
for message in messages:
if message.role == "system":
prompt += f"<|im_start|>system\n{message.content}<|im_end|>\n"
elif message.role == "user":
prompt += f"<|im_start|>user\n{message.content}<|im_end|>\n"
elif message.role == "assistant":
prompt += f"<|im_start|>assistant\n{message.content}<|im_end|>\n"
if not prompt.startswith("<|im_start|>system"):
prompt = "<|im_start|>system\n" + prompt
prompt = prompt + "<|im_start|>assistant\n"
return prompt
加载语言模型
if __name__ == '__main__':
# HuggingFaceLLM 中包含多种参数
Settings.llm = HuggingFaceLLM(
model_name="./qwen/Qwen2.5-7B-Instruct",
tokenizer_name="./qwen/Qwen2.5-7B-Instruct",
# 定义模型在生成文本时考虑的上下文长度,即上下问窗口
context_window=30000,
# 定义了模型在生成回复时可以产生的最大token数量
max_new_tokens=2000,
# 包含了生成文本时使用的关键参数:生成文本随机性、只考虑概率最高的标记数、核采样来控制生成文本的多样性
generate_kwargs={"temperature": 0.7, "top_k": 50, "top_p": 0.95},
# 两个函数定义了如何将对话消息转换成模型的输入提示
messages_to_prompt=messages_to_prompt,
completion_to_prompt=completion_to_prompt,
device_map="auto",
)
加载嵌入模型并设置分块大小
# Set embedding model
Settings.embed_model = HuggingFaceEmbedding(
model_name = "/home/wangshaopu/wangshaopu/model/bge-base-zh-v1.5"
)
# Set the size of the text chunk for retrieval
Settings.transformations = [SentenceSplitter(chunk_size=1024)]
构建RAG知识库,完成向量化并构建索引
'''
在定义完模型相关信息之后,下面首先是构建RAG外置知识库,首先就是处理获得的文档数据,之后对构建好的Document格式格式转为向量与构建索引。
在完成之后,可以将其存储到文件之中,之后就可以直接从存储文件中读取,并完成向量与索引的构建。
'''
all_text = []
with open('./面向大语言模型的领域知识注入与推理/rules1.json','r',encoding='UTF-8') as f:
data = json.load(f)
for dict_data in data:
all_text.append(dict_data['rule_text'])
documents = [Document(text=t) for t in all_text]
# 对documents 元组的id进行修改
for id,data in enumerate(documents):
data.id_ = str(id + 1)
# 构建索引
index = VectorStoreIndex.from_documents(
documents,
embed_model=Settings.embed_model,
transformations=Settings.transformations
)
# 将embedding向量和向量索引存储到文件中
index.storage_context.persist(persist_dir='doc_emb')
# 存储完之后可以只调用这两段代码
# 从存储文件中读取embedding向量和向量索引
storage_context = StorageContext.from_defaults(persist_dir="doc_emb")
index = load_index_from_storage(storage_context)
构建查询引擎
llamaindex 库中有已经设计好了的查询引擎,本次实践初期,我们直接调用了llamaindex的查询引擎
# 构建查询引擎,其参数表示需要提取出前多少个知识给予大模型
query_engine_3 = index.as_query_engine(similarity_top_k=3)
数据的处理与保存
下面的代码用于提取出各个问题并实现大模型的问答,一同给出
# 正则表达用于判断大模型输出后的结果如何
pattern = r'[ABCD]'
p = re.compile(pattern,re.MULTILINE)
out_end = []
with open('./面向大语言模型的领域知识注入与推理/dev.json','r',encoding='UTF-8') as dev:
dev_data = json.load(dev)
for id,data in enumerate(dev_data):
time1 = time.time()
# 设计询问模型的问题,虽然这么设计,但大模型还是有可能会输出长串字符
your_query = data['question_text']+ '\n要求只输出A,B,C,D中的一个'
# 通过此代码可以将问题输入给RAG,RAG提出最相似的文档后一起输入给大模型,并获得回答response
response = query_engine_3.query(your_query)
# source是提取出回答的原始数据,可以从中提取出相似文档数据
source = response.source_nodes
id_list = []
id_text_list = []
for i in range(0,len(source)):
# 获取原先id方式
this_id = (dict(list((list(list(source[i])[0])[1].relationships).values())[0])['node_id'])
id_list.append(this_id)
# 获取原先文档方式
this_data = (list(source[i])[0])[1].text
id_text_list.append(this_data)
time2 = time.time()
# 比赛结果输出
output = {}
output['question_id'] = data['question_id']
end_answer = (str(response))
re_data = p.findall(end_answer)
if re_data:
# 使用Counter统计每个字母的出现次数
letter_counts = Counter(re_data)
# 找出出现次数最多的字母
most_common_letter, count = letter_counts.most_common(1)[0]
output['answer'] = most_common_letter
else:
# 如果大模型输出结果中一个字母都没有,统一设置为A不进行后处理
output['answer'] = 'A'
output['rule_id'] = id_list
out_end.append(output)
# 过程观测
print(f"question{id + 1}_time:{time2 - time1}-{str(output['answer'])}")
with open('./test1/test_3_10.json','w',encoding='UTF-8') as f:
json.dump(out_end,f, indent=4, ensure_ascii=False)
输出结果
完成全部问题的问答后json文件内容如下:
[
{
"question_id": "1",
"answer": "C",
"rule_id": [
"204",
"222",
"205"
]
},
{
"question_id": "2",
"answer": "B",
"rule_id": [
"466",
"464",
"500"
]
}...
]
源代码
import torch
from llama_index.core import Settings,PromptTemplate,StorageContext,VectorStoreIndex,Document,load_index_from_storage
from llama_index.core.node_parser import SentenceSplitter
from llama_index.llms.huggingface import HuggingFaceLLM
from llama_index.embeddings.huggingface import HuggingFaceEmbedding
import time
import json
# 定义生成提示模板,以增强模型的回答生成能力:1
def completion_to_prompt(completion):
return f"<|im_start|>system\n<|im_end|>\n<|im_start|>user\n{completion}<|im_end|>\n<|im_start|>assistant\n"
# 定义生成提示模板,以增强模型的回答生成能力:2
def messages_to_prompt(messages):
prompt = ""
for message in messages:
if message.role == "system":
prompt += f"<|im_start|>system\n{message.content}<|im_end|>\n"
elif message.role == "user":
prompt += f"<|im_start|>user\n{message.content}<|im_end|>\n"
elif message.role == "assistant":
prompt += f"<|im_start|>assistant\n{message.content}<|im_end|>\n"
if not prompt.startswith("<|im_start|>system"):
prompt = "<|im_start|>system\n" + prompt
prompt = prompt + "<|im_start|>assistant\n"
return prompt
if __name__ == '__main__':
# HuggingFaceLLM 中包含多种参数
Settings.llm = HuggingFaceLLM(
model_name="/mnt/PublicStoreA/zb2025/AImodels/nlp/llama/Qwen/qwen/Qwen2.5-7B-Instruct",
tokenizer_name="/mnt/PublicStoreA/zb2025/AImodels/nlp/llama/Qwen/qwen/Qwen2.5-7B-Instruct",
# 定义模型在生成文本时考虑的上下文长度,即上下问窗口
context_window=30000,
# 定义了模型在生成回复时可以产生的最大token数量
max_new_tokens=2000,
# 包含了生成文本时使用的关键参数:生成文本随机性、只考虑概率最高的标记数、核采样来控制生成文本的多样性
generate_kwargs={"temperature": 0.7, "top_k": 50, "top_p": 0.95},
# 两个函数定义了如何将对话消息转换成模型的输入提示
messages_to_prompt=messages_to_prompt,
completion_to_prompt=completion_to_prompt,
device_map="auto",
)
# Set embedding model
Settings.embed_model = HuggingFaceEmbedding(
model_name = "/home/wangshaopu/wangshaopu/model/bge-base-zh-v1.5"
)
# Set the size of the text chunk for retrieval
Settings.transformations = [SentenceSplitter(chunk_size=1024)]
'''
在定义完模型相关信息之后,下面首先是构建RAG外置知识库,首先就是处理获得的文档数据,之后对构建好的Document格式格式转为向量与构建索引。
在完成之后,可以将其存储到文件之中,之后就可以直接从存储文件中读取,并完成向量与索引的构建。
'''
all_text = []
with open('./面向大语言模型的领域知识注入与推理/rules1.json','r',encoding='UTF-8') as f:
data = json.load(f)
for dict_data in data:
all_text.append(dict_data['rule_text'])
documents = [Document(text=t) for t in all_text]
# 对documents 元组的id进行修改
for id,data in enumerate(documents):
data.id_ = str(id + 1)
# 构建索引
index = VectorStoreIndex.from_documents(
documents,
embed_model=Settings.embed_model,
transformations=Settings.transformations
)
# 将embedding向量和向量索引存储到文件中
index.storage_context.persist(persist_dir='doc_emb')
# 存储完之后可以只调用这两段代码
# 从存储文件中读取embedding向量和向量索引
storage_context = StorageContext.from_defaults(persist_dir="doc_emb")
index = load_index_from_storage(storage_context)
# 构建查询引擎
query_engine_3 = index.as_query_engine(similarity_top_k=3)
out_end = []
with open('./面向大语言模型的领域知识注入与推理/dev.json','r',encoding='UTF-8') as dev:
dev_data = json.load(dev)
for id,data in enumerate(dev_data):
time1 = time.time()
# 设计询问模型的问题
your_query = data['question_text']+ '\n要求只输出A,B,C,D中的一个'
# 通过此代码可以将问题输入给RAG,RAG提出最相似的文档后一起输入给大模型,并获得回答response
response = query_engine_3.query(your_query)
# source是提取出回答的原始数据,可以从中提取出相似文档数据
source = response.source_nodes
id_list = []
id_text_list = []
for i in range(0,len(source)):
# 获取原先id方式
this_id = (dict(list((list(list(source[i])[0])[1].relationships).values())[0])['node_id'])
id_list.append(this_id)
# 获取原先文档方式
this_data = (list(source[i])[0])[1].text
id_text_list.append(this_data)
time2 = time.time()
# 结果输出
output = {}
output['question_id'] = data['question_id']
output['answer'] = (str(response))[:1]
output['rule_id'] = id_list
out_end.append(output)
# 过程观测
print(f"question{id + 1}_time:{time2 - time1}-{str(output['answer'])}")
with open('./test1/test_3_10.json','w',encoding='UTF-8') as f:
json.dump(out_end,f, indent=4, ensure_ascii=False)
小结
此文章是我第一次尝试在CSDN上创作交流,格式上尚未成熟,上述内容是我们工作的一部分,llamaindex的搜索引擎是可以自定义的,虽然效果上不如官方,但是在实践的过程中仍能学到一些知识,那部分仍需消化一下,后面再完成创作
源代码与比赛数据集分享已转移至公众号,搜索:网安小木屋,回复关键词:知识注入
声明
此次实践学习,参考了很多大佬们的CSDN文章,与此文章最为相近也加以借鉴的是寻道AI小兵
【RAG检索增强生成】LlamaIndex与Qwen2的高效检索增强生成实践 的文章,加以声明。

ModelScope旨在打造下一代开源的模型即服务共享平台,为泛AI开发者提供灵活、易用、低成本的一站式模型服务产品,让模型应用更简单!
更多推荐



 22
22 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)