
爆了,阿里 Qwen2.5 问鼎全球Top10...
阿里云近期开源了通义Qwen2.5最新模型,距离上个版本发布,仅仅三个月,更新迭代速度让人感叹,新版本一经发布,便迅速在最新大模型盲测榜单(基准测试平台Chatbot Arena)中,新发布的。其大语言模型 Qwen2.5-72B-Instruct 排名大语言模型榜单第十,居于闭源 OpenAI 的 o1、GPT-4o 等模型之后,是前十唯一的中国大模型。并且其性能超越开源模型 Llama 405
阿里云近期开源了通义Qwen2.5最新模型,距离上个版本发布,仅仅三个月,更新迭代速度让人感叹,新版本一经发布,便迅速登顶全球最强开源模型王座。
在最新大模型盲测榜单(基准测试平台Chatbot Arena)中,新发布的 Qwen2.5 开源模型再次闯入全球十强。
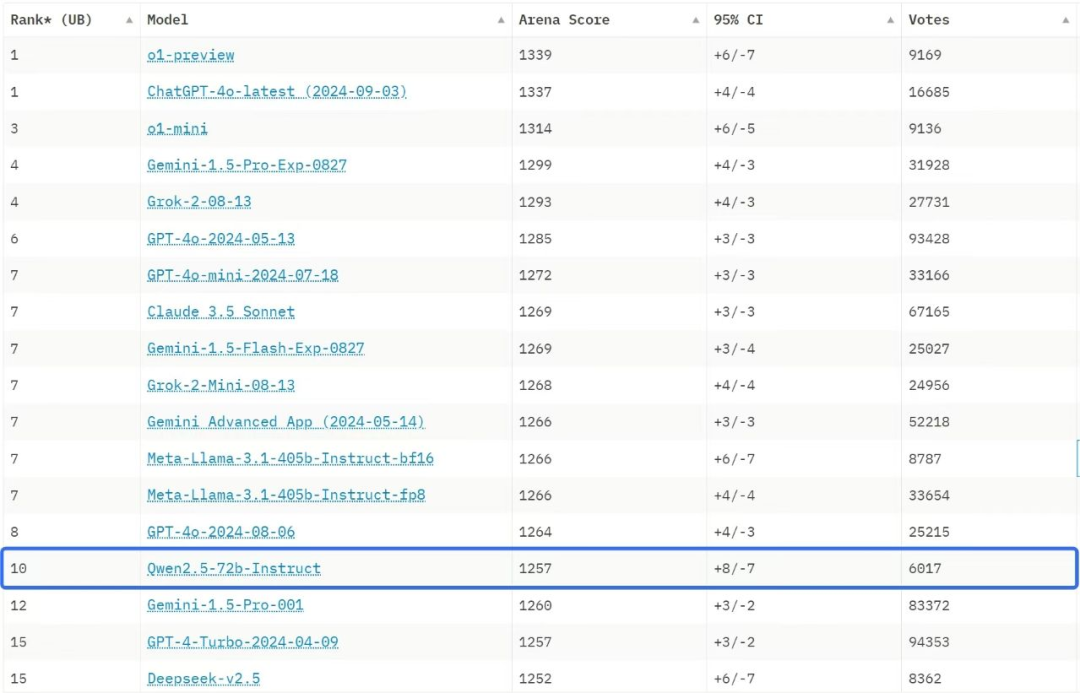
其大语言模型 Qwen2.5-72B-Instruct 排名大语言模型榜单第十,居于闭源 OpenAI 的 o1、GPT-4o 等模型之后,是前十唯一的中国大模型。并且其性能超越开源模型 Llama 405B。
-
开源地址:https://github.com/QwenLM/Qwen2.5
1、新模型特点
-
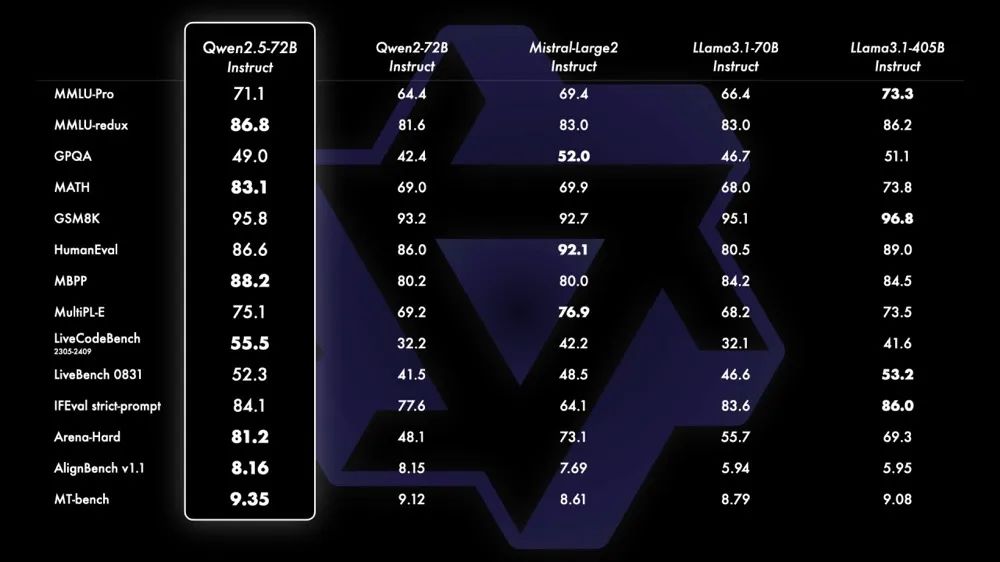
和上一代模型相比,新版本通义Qwen2.5模型训练参数量更大,全系列都在18T tokens数据上进行预训练,整体性能提升18%以上,拥有更多的知识、更强的编程和数学理解能力。
-
在指令跟踪、生成长文本、理解结构化数据以及生成机构化输出方面显著提升
-
文本分类、信息抽取、情感分析、润色纠错等文本处理任务更稳健
-
支持多达29种语言,包括中文、英语、日语、韩语等等,模型中英文能力显著提升
-
上下文长度支持高达128KB,可生产最多8K的内容
2、最强开源模型
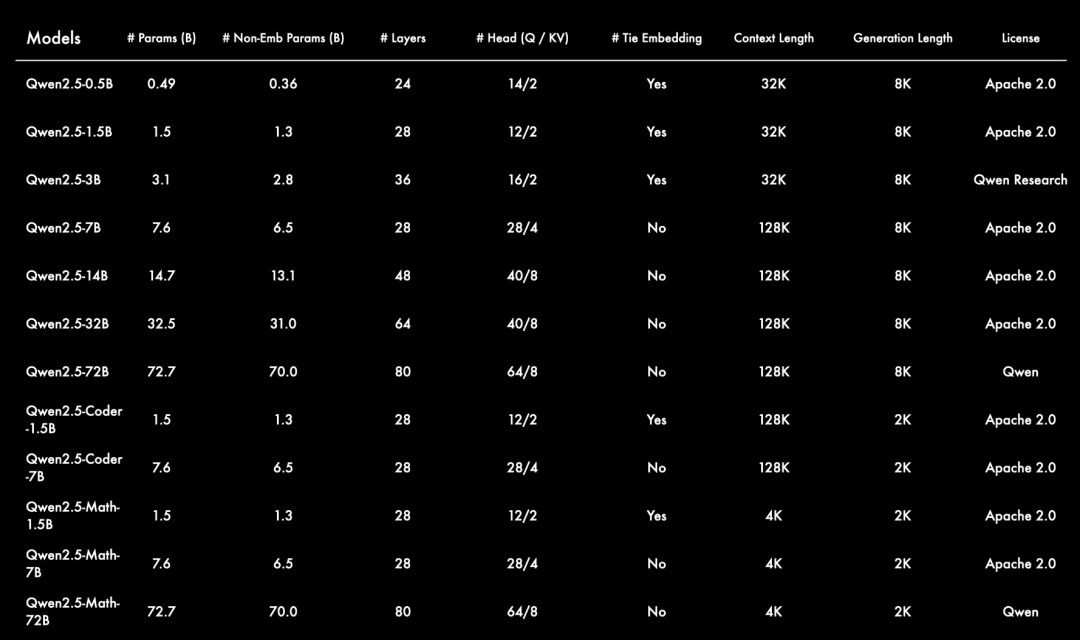
Qwen2.5 全系列涵盖多个尺寸的大语言模型、总计上架100多个模型,刷新业界纪录。
1、语言模型:Qwen2.5系列开源了七个不同尺寸的语言模型,从0.5B 到 72B,覆盖了从端侧设备到工业级场景的多种需求。

这些模型在各自的赛道上均实现了 SOTA(State-of-the-Art)成绩,满足了开发者在模型能力和成本之间的平衡需求。
例如,3B 模型适用于手机等端侧设备,32B 模型被誉为“性价比之王”,而 72B 模型则是工业级和科研级场景的性能王者。
2、多模态模型:Qwen2-VL-72B 是备受期待的大规模视觉语言模型,现已正式开源。该模型能够识别不同分辨率和长宽比的图片,理解超过 20 分钟的长视频,并具备调节手机和设备的视觉智能体能力,其视觉理解能力超越了 GPT-4o 水平。

此外,Qwen2-Audio 大规模音频语言模型也开源了,支持多达 8 种语言和方言,能够进行语音聊天和音频信息分析,在全球权威测评中表现领先。
3、垂直领域模型:Qwen2.5系列还包括用于编程的 Qwen2.5-Coder 和用于数学的Qwen2.5-Math的专属模型。
Qwen2.5-Math 是目前最先进的开源数学模型系列,旗舰模型Qwen2-Math-72B-Instruct 在数学相关任务中表现优于 GPT-4o 和 Claude 3.5。
Qwen2.5-Coder 则在 5.5T tokens 的编程数据上进行了训练,开源了 1.5B 和 7B 版本,未来还将开源 32B 版本。此外,通义千问旗舰模型 Qwen-Max 也实现了全面升级,在多个权威基准上接近甚至赶超 GPT-4o。
3、部署体验和测试
前面我们介绍了如何本地部署通义千问大模型,感兴趣的小伙伴可以看下之前的文章。
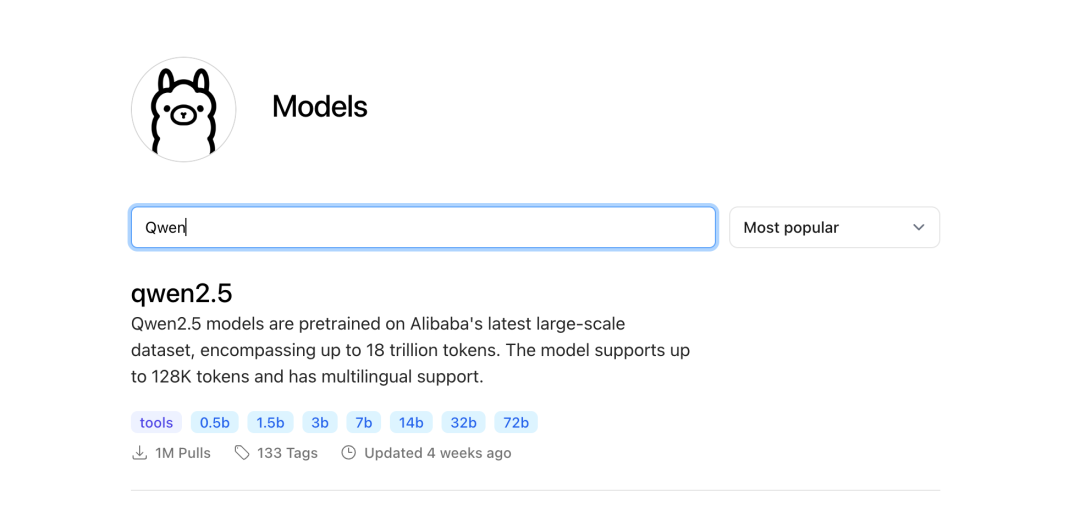
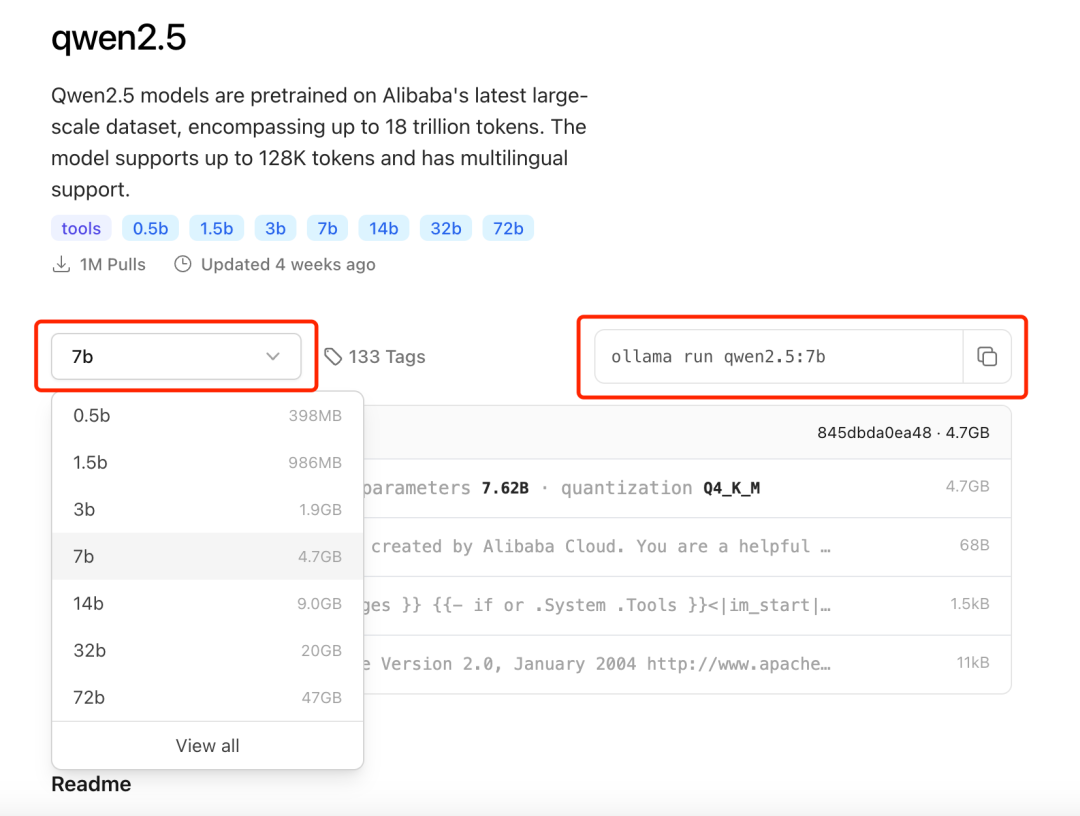
安装流程非常简单,本次测试,我们还是通过Ollama工具来安装,进入到官网,搜索「Qwen」,可以看到最新模型,点击进去,可以看到不同尺寸大小的模型,其中72B是旗舰版,占资源较大,我们本次安装测试Qwen2.5-7B。
-
官网:https://ollama.com
-
Github:https://github.com/ollama/ollama
|
|
|
打开终端,直接执行如下命令:
ollama run qwen2.5:7b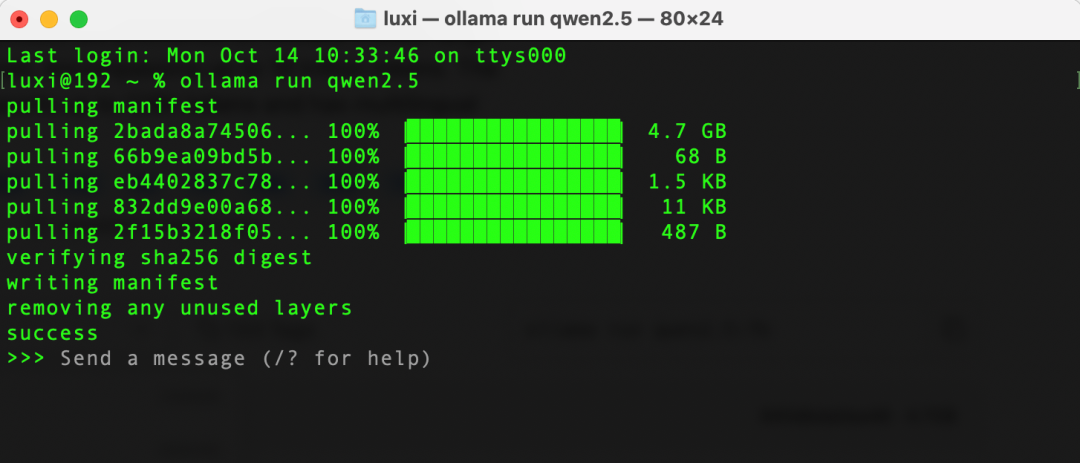
安装完毕,启动Docker,浏览器访问:http://localhost:3000/auth/,进入Web Ui页面,就可以提问了。
建议大家可以本地部署下,这样每次模型更新,我们都可以第一时间免费安装体验。并且使用非常方便,也不容担心数据安全性问题。
安装好,我们从多个角度来提问测试,通过对比ChatGPT-4o和Qwen2.5的回答,看看谁的回答更专业更精准:
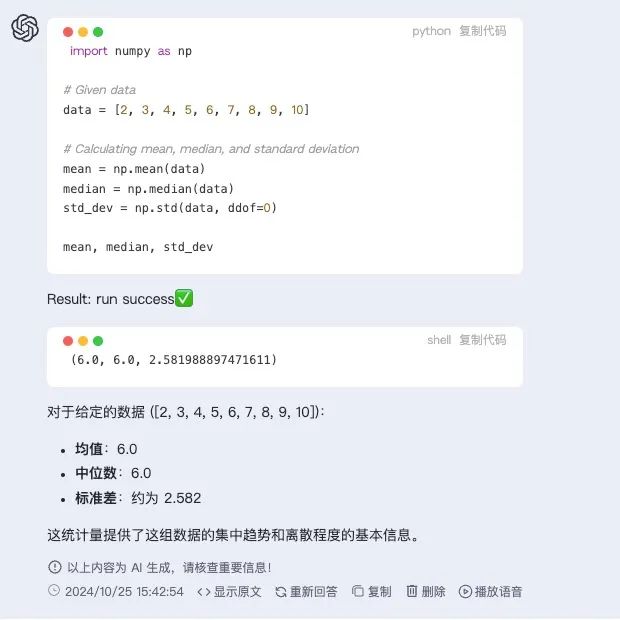
第一题:给定一组数据:2, 3, 4, 5, 6, 7, 8, 9, 10。计算这组数据的均值、中位数和标准差。
Qwen2.5回答:

ChatGPT-4o回答:
第二题:小明的妻子生了一对双胞胎。以下哪个推论是正确的?
A.小明家里一共有三个孩子
B.小明家里一共有两个孩子。
C.小明家里既有男孩子也有女孩子
D.无法确定小明家里孩子的具体情况
通义Qwen2.5回答:

ChatGPT-4o回答:

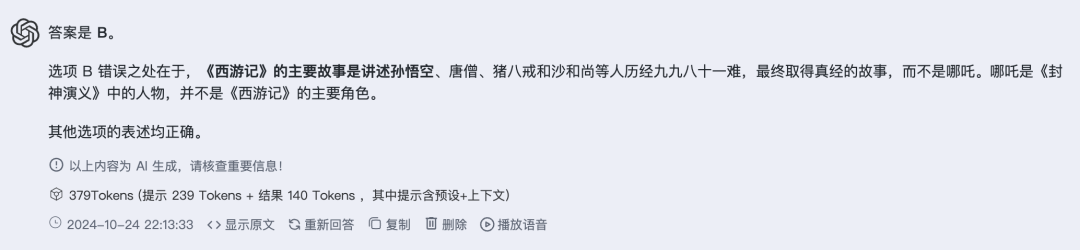
第三题:下列有关名著的表述有误的一项是
A.《红楼梦》是中国古代小说中的巅峰之作以其瑰丽的语言和丰富的人物形象而闻名于世。
B.《西游记》是中国古代四大名著之一,讲述了哪吒等人历经九九八十一难,最终取得真经的故事。
C.《孔乙己》是鲁迅的代表作之一,以其深刻的社会洞察力和优美的文学风格而广受好评。
D.《围城》是钱钟书的代表作之一,以其独特的文学语言和深刻的社会洞察力而成为现代中国文学的经典之作。
通义Qwen2.5回答:

ChatGPT-4o回答:
第四题:选出下列句子中成语使用错误的一项
A.这个项目时间紧任务重,大家都在马不停蹄地奔波劳碌。
B.他常常口是心非,让人难以相信他说的话。
C.两人是同学三年,一直保持着良好的关系,相互尊重、相敬如宾。
D.当地突发大火,整个村庄都鸡犬不宁局势十分危急。
通义Qwen2.5回答:

ChatGPT-4o回答:

测试内容较多,不再一一展示,通过整体测试:Qwen2.5和ChatGPT-4o除了在中文上部分表现不一致之外,其他编程、数学和物理上回答基本都一样,这也说明目前通义Qwen2.5的能力已经达到了ChatGPT-4o的专业水平,同时,在中文理解方面更加专业,回答更加精准,这也再次证明了国产大模型在中文方面的先天优势。
好了,今天就给大家分享到这里。最后,祝愿国产大模型越来越好,也希望越来越多的企业能有阿里的担当和前瞻,把核心技术掌握在自己人手中。

ModelScope旨在打造下一代开源的模型即服务共享平台,为泛AI开发者提供灵活、易用、低成本的一站式模型服务产品,让模型应用更简单!
更多推荐



 27
27 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)