
from modelscope import AutoModelForCausalLM, AutoTokenizer
model_name = "Qwen/Qwen2.5-Coder-32B-Instruct-GPTQ-Int4"
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype="auto",
device_map="auto"
)
tokenizer = AutoTokenizer.from_pretrained(model_name)
prompt = "write a quick sort algorithm."
messages = [
{"role": "system", "content": "You are Qwen, created by Alibaba Cloud. You are a helpful assistant."},
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
generated_ids = model.generate(
**model_inputs,
max_new_tokens=512
)
generated_ids = [
output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)
]
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]

魔搭社区每周速递(11.10-11.16)
1435个模型、43个数据集、39个创新应用、7篇应用文章
·

🙋魔搭ModelScope本期社区进展:
📟1435个模型:Qwen2.5-Coder系列、In-Context-LoRA、RMBG-2.0等;
📁43个数据集:LaTeX_OCR、test_latex_ocr等;
🎨39个创新应用:通义千问2.5-代码系列、OmniGen等;
📄 7 篇文章:
-
ModelScope魔搭11月版本发布月报
-
基于开源技术的数字人实时对话:形象可自定义,支持语音输入,对话首包延迟可低至3s
-
智源行业应用大模型挑战赛开启报名!挖掘数据潜能,共创行业新篇
-
Qwen2.5-Coder深夜开源炸场,Prompt编程的时代来了!
-
Open NotebookLM,一键PDF/URL转播客!
-
AI+硬件最新资讯合集(2024-11-11第3期)
-
魔搭社区创空间全新支持 Gradio 5
01精选模型
Qwen2.5-Coder
通义千问团队开源「强大」、「多样」、「实用」的 Qwen2.5-Coder 全系列,致力于持续推动 Open Code LLMs 的发展。
-
强大:Qwen2.5-Coder-32B-Instruct 成为目前 SOTA 的开源代码模型,代码能力追平 GPT-4o。在展现出强大且全面的代码能力的同时,具备良好的通用和数学能力;
-
多样:在之前开源的两个尺寸 1.5B/7B 的基础上,本次开源共带来四个尺寸的模型,包括 0.5B/3B/14B/32B。截止目前 Qwen2.5-Coder 已经覆盖了主流的六个模型尺寸,以满足不同开发者的需要;
-
实用:在两种场景下探索 Qwen2.5-Coder 的实用性,包括代码助手和 Artifacts,一些样例展示出 Qwen2.5-Coder 在实际场景中应用的潜力;
合集模型链接:
https://modelscope.cn/collections/Qwen25-Coder-9d375446e8f5814a
推理代码:
transformers: 单卡运行Qwen2.5-32B-Instrtuct量化模型。
更多信息请看最佳实践:
Qwen2.5-Coder深夜开源炸场,Prompt编程的时代来了!
RMBG-2.0
RMBG v2.0 是一个优秀的背景移除模型,可有效分离各种类别和图像类型的前景和背景。该模型在精心挑选的数据集上进行了训练,包括:通用库存图片、电子商务、游戏和广告内容,使其适合商业用途,支持大规模企业内容创作。目前的准确性、效率和多功能性可与领先的开源模型相媲美。它非常适合重视内容安全、合法授权数据集和偏见缓解的场景。
模型链接:
https://modelscope.cn/models/AI-ModelScope/RMBG-2.0
使用方法:
from PIL import Image
import matplotlib.pyplot as plt
import torch
from torchvision import transforms
from transformers import AutoModelForImageSegmentation
from modelscope import snapshot_download
model_dir = snapshot_download('AI-ModelScope/RMBG-2.0')
model = AutoModelForImageSegmentation.from_pretrained(model_dir, trust_remote_code=True)
torch.set_float32_matmul_precision(['high', 'highest'][0])
model.to('cuda')
model.eval()
# Data settings
image_size = (1024, 1024)
transform_image = transforms.Compose([
transforms.Resize(image_size),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
])
image = Image.open('cat.png')
input_images = transform_image(image).unsqueeze(0).to('cuda')
# Prediction
with torch.no_grad():
preds = model(input_images)[-1].sigmoid().cpu()
pred = preds[0].squeeze()
pred_pil = transforms.ToPILImage()(pred)
mask = pred_pil.resize(image.size)
image.putalpha(mask)
image.save("no_bg_image.png")
02数据集推荐
LaTeX_OCR
一个专注于LaTeX文档的光学字符识别数据集,旨在支持和改进OCR技术在学术和科学文档数字化领域的应用。
数据集链接:
https://modelscope.cn/datasets/AI-ModelScope/LaTeX_OCR
test_latex_ocr
test_latex_ocr是一个LaTeX文档光学字符识别测试数据集。
5个数据集
-
small 是小数据集,样本数 110 条,用于测试
-
full 是印刷体约 100k 的完整数据集。实际上样本数略小于 100k,因为用 LaTeX 的抽象语法树剔除了很多不能渲染的 LaTeX。
-
synthetic_handwrite 是手写体 100k 的完整数据集,基于 full 的公式,使用手写字体合成而来,可以视为人类在纸上的手写体。样本数实际上略小于 100k,理由同上。
-
human_handwrite 是手写体较小数据集,更符合人类在电子屏上的手写体。主要来源于 CROHME。我们用 LaTeX 的抽象语法树校验过了。
-
human_handwrite_print 是来自 human_handwrite 的印刷体数据集,公式部分和 human_handwrite 相同,图片部分由公式用 LaTeX 渲染而来。
数据集链接:
https://modelscope.cn/datasets/wangxingjun778/test_latex_ocr
03精选应用
通义千问2.5-代码
通义千问团队开源了功能强大、多样化、实用的 Qwen2.5-Coder 系列,支持在线体验,推动 Open Code LLMs 发展。
模型集合demo体验:
https://www.modelscope.cn/studios/Qwen/Qwen2.5-Coder-demo

Artifacts体验:
https://modelscope.cn/studios/Qwen/Qwen2.5-Coder-Artifacts
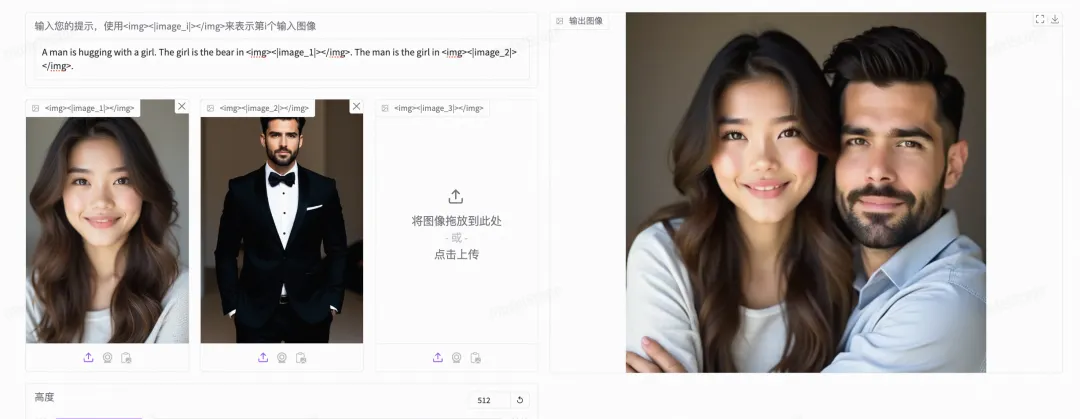
OmniGen
OmniGen 是一个多功能图像生成模型,支持文本到图像、主题驱动、身份保持和条件图像生成等多种任务,使用时需传入字符串提示和图像路径列表,支持多模态到图像生成,建议图像编辑任务时输出尺寸与输入一致,可自动设置,且提供内存和时间优化选项,能够调整图像饱和度和风格,编辑时需更换种子以避免重复。
体验直达:
https://modelscope.cn/studios/chuanSir/OmniGen

04社区精选文章

ModelScope旨在打造下一代开源的模型即服务共享平台,为泛AI开发者提供灵活、易用、低成本的一站式模型服务产品,让模型应用更简单!
更多推荐


 0
0 0
0- 0



 已为社区贡献410条内容
已为社区贡献410条内容

所有评论(0)