


01Open NotebookLM
结合不同的开源模型,例如Qwen2.5-72B-Instruct, CosyVoice-300M)等,将PDF文件(比如论文paper),或者网页URL内容,转换成为有趣的播客😊。
魔搭提供了体验页面,支持一键构建PDF/URL到播客。
体验链接:
https://modelscope.cn/studios/modelscope/open-notebooklm-demo

02详细步骤
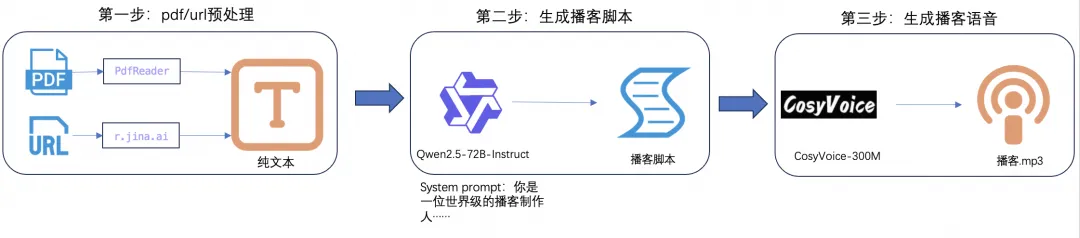
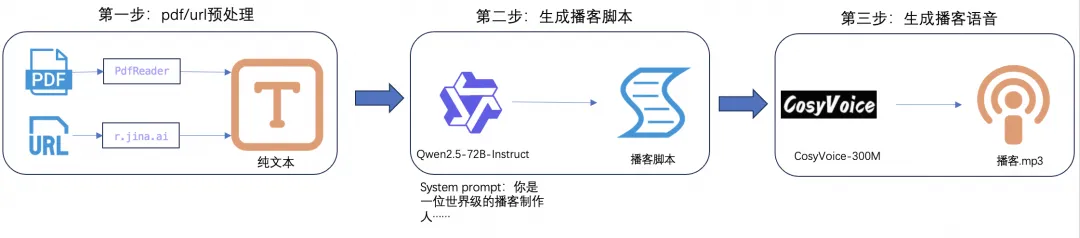
PDF/URL到播客任务的步骤:
步骤一:
数据预处理,首先检查输入的有效性,然后分别使用pdfreader和r.jina.ai处理PDF和URL,将其保存为纯文本格式。
输入链接:
https://mp.weixin.qq.com/s/Gn8kV04e_Y_BmXdxSMBiSQ
使用r.jina.ai,实现URL转纯文本:


步骤二:
生成播客脚本,首先检查总字符数是否超出限制(根据Qwen模型的上下文限制,此处输入总字符限制为10万字),然后使用Qwen模型根据输入文本输出播客脚本。
system prompt设计:
你是一位世界级的播客制作人,任务是将提供的输入文本转化为引人入胜且信息丰富的播客脚本。输入可能是无结构或杂乱的,来源于PDF或网页。你的目标是从中提取最有趣和有洞察力的内容,以进行一次吸引人的播客讨论。
遵循步骤:
1. 分析输入内容:
仔细检查文本,识别能够推动吸引人播客对话的关键主题、要点以及有趣的事实或轶事。忽略不相关的信息或格式问题。
2. 头脑风暴创意:
在<草稿本>中创造性地思考如何以吸引人的方式呈现关键点。考虑
- 使用类比、讲故事技巧或假设情境使内容更加贴近听众
- 以让普通听众易于理解的方式来解释复杂话题的方法
- 在播客中探讨的发人深省的问题
- 填补信息空白的创新方法
3. 创作对话:
发展主持人(Jane)与嘉宾(作者或该主题专家)之间自然流畅的对话。包含:
- 从头脑风暴会话中得到的最佳想法
- 对复杂话题的清晰解释
- 一种能吸引听众的活泼语调
- 信息与娱乐之间的平衡
对话规则:
- 主持人(Jane)始终开启对话并对嘉宾进行访谈
- 包含来自主持人的深思熟虑的问题来引导讨论
- 结合自然的言语模式,包括偶尔的口头填充词(例如,“嗯”,“好”,“要知道”)
- 允许主持人与嘉宾之间自然的打断和互动
- 确保嘉宾的回答基于输入文本,避免没有根据的说法
- 维持适合所有观众的PG级对话
- 避免嘉宾进行任何形式的营销或自我宣传
- 主持人结束对话
4. 总结关键见解:
在对话接近尾声时自然地融入关键点总结。这应该像是随意的交谈而不是正式的回顾,以便在结束前再次强调主要收获。
5. 保持真实性:在整个脚本中力求对话的真实性。包括:
- 来自主持人的真实好奇心或惊讶时刻
- 当嘉宾试图表达一个复杂想法时可能短暂出现的困难
- 适时轻松幽默的时刻
- 与话题相关的简短个人故事或例子(在输入文本范围内)
6. 考虑节奏和结构:确保对话有一个自然的起伏:
- 以强有力的开场白抓住听众的注意力
- 随着对话推进逐渐增加复杂度
- 为听众提供简短的‘休息’时间以吸收复杂信息
- 以高潮结尾,也许是一个发人深省的问题或对听众的行动呼吁
7. 格式要求:请按照严格的JSON格式要求返回结果,主持人和作者说的话,严格按照段落分开,并分别以“Host (Jane):” 和 “Guest:” 开头。
内容json格式{"title": "", "hosts":"", "guests":"", "Dialogue": [{"speaker": "", "text":""}],}
重要规则:每句对话不得超过100个字符(例如,可以在5-8秒内完成)。
注意:直接以JSON格式回复,不要包含代码块。并通过参数化配置prompt,动态调整输出的脚本的长度,情绪,语言等:
TONE_MODIFIER = "语调:这个播客的语调应该是:"
LANGUAGE_MODIFIER = "输出语言 <重要>: 输出的播客语言应该是"
LENGTH_MODIFIERS = {
"Short (1-2 min)": "保持播客的的简单,长度在1-2分钟左右。",
"Medium (3-5 min)": "争取维持播客中等长度,大概在3-5分钟左右。",
}输出的脚本示例:


步骤三:
文本转语音:使用Cosyvoice生成每个对话行的音频。合并所有音频片段。导出合并后的音频并播放。
处理函数介绍
generate_podcast分解
1.上传PDF文件
获取 gr.File的组件输入PDF文件,通过Path和PdfReader解析出PDF文件内容,并存储在text的字符串中
from pathlib import Path
from pypdf import PdfReader
if files:
for file in files:
if not file.lower().endswith(".pdf"):
raise gr.Error(ERROR_MESSAGE_NOT_PDF)
try:
with Path(file).open("rb") as f:
reader = PdfReader(f)
text += "\n\n".join([page.extract_text() for page in reader.pages])
except Exception as e:
raise gr.Error(f"{ERROR_MESSAGE_READING_PDF}: {str(e)}")
2.输入URL(可选)
获取 gr.Textbox的组件输入URL链接,通过调用parse_url函数解析出HTML文本内容,并存储在text的字符串中
from utils import parse_url
if url:
try:
url_text = parse_url(url)
text += "\n\n" + url_text
except ValueError as e:
raise gr.Error(str(e))parse_url函数是通过requests发送请求,提取URL对应的网页内容。
import requests
JINA_READER_URL = "https://r.jina.ai/"
JINA_RETRY_ATTEMPTS = 3
JINA_RETRY_DELAY = 5
def parse_url(url: str) -> str:
"""Parse the given URL and return the text content."""
for attempt in range(JINA_RETRY_ATTEMPTS):
try:
full_url = f"{JINA_READER_URL}{url}"
response = requests.get(full_url, timeout=60)
response.raise_for_status() # Raise an exception for bad status codes
return response.text
except requests.RequestException as e:
if attempt == JINA_RETRY_ATTEMPTS - 1: # Last attempt
raise ValueError(
f"Failed to fetch URL after {JINA_RETRY_ATTEMPTS} attempts: {e}"
) from e
time.sleep(JINA_RETRY_DELAY) # Wait for X second before retrying3.特定问题或话题、选择情绪、选择长度
通过将特定问题或话题、选择情绪、选择长度的选中项,叠加给SYSTEM_PROMPT
modified_system_prompt = SYSTEM_PROMPT
if question:
modified_system_prompt += f"\n\n{QUESTION_MODIFIER} {question}"
if tone:
modified_system_prompt += f"\n\n{TONE_MODIFIER} {tone}."
if length:
modified_system_prompt += f"\n\n{LENGTH_MODIFIERS[length]}"
modified_system_prompt += f"\n\n{LANGUAGE_MODIFIER} 中文."4.通义千问模型调用
通过将SYSTEM_PROMPT、解析出的text传递给generate_script,用于通义千问模型的模型调用函数。
if length == "Short (1-2 min)":
qwen_output = generate_script(modified_system_prompt, text, ShortDialogue)
else:
qwen_output = generate_script(modified_system_prompt, text, MediumDialogue)generate_script函数,用于传递system_prompt、input_text、output_model,通过调用call_llm实现对q wen的模型输出和内容校验。
def generate_script(
system_prompt: str,
input_text: str,
output_model: Union[ShortDialogue, MediumDialogue],
) -> Union[ShortDialogue, MediumDialogue]:
response = call_qwen(system_prompt, input_text)
response_json = response.choices[0].message.content
first_draft_dialogue = ""
# Validate the response
for attempt in range(DASHSCOPE_JSON_RETRY_ATTEMPTS):
try:
first_draft_dialogue = output_model.model_validate_json(response_json)
break
except ValidationError as e:
if attempt == DASHSCOPE_JSON_RETRY_ATTEMPTS - 1: # Last attempt
raise ValueError(
f"Failed to parse dialogue JSON after {DASHSCOPE_JSON_RETRY_ATTEMPTS} attempts: {e}"
) from e
error_message = (
f"Failed to parse dialogue JSON (attempt {attempt + 1}): {e}"
)
# Re-call the Qwen with the error message
system_prompt_with_error = f"{system_prompt}\n\n请返回一个有效的JSON格式。这是之前的报错信息{error_message}"
response = call_qwen(system_prompt_with_error, input_text)
response_json = response.choices[0].message.content
first_draft_dialogue = output_model.model_validate_json(response_json)
system_prompt_with_dialogue = f"{system_prompt}\n\n这里是您提供的对话的第一稿:\n\n{first_draft_dialogue}."
for attempt in range(DASHSCOPE_JSON_RETRY_ATTEMPTS):
try:
response = call_qwen(
system_prompt_with_dialogue,
"请改进这段对话,让它更加自然和吸引人。",
)
response_json = response.choices[0].message.content
final_dialogue = output_model.model_validate_json(response_json)
return final_dialogue
except ValidationError as e:
if attempt == DASHSCOPE_JSON_RETRY_ATTEMPTS - 1: # Last attempt
raise ValueError(
f"Failed to improve dialogue after {DASHSCOPE_JSON_RETRY_ATTEMPTS} attempts: {e}"
) from e
error_message = f"Failed to improve dialogue (attempt {attempt + 1}): {e}"
system_prompt_with_dialogue += f"\n\n请返回一个有效的JSON 这是之前的报错信息{error_message}"call_qwen函数 封装了 OpenAI模块实现对qwen模型的调用,并返回符合json格式。
from openai import OpenAI
fw_client = OpenAI(base_url=FIREWORKS_BASE_URL, api_key=FIREWORKS_API_KEY)
def call_qwen(system_prompt: str, text: str) -> Any:
response = fw_client.chat.completions.create(
messages=[
{"role": "system", "content": system_prompt},
{"role": "user", "content": text},
],
model=DASHSCOPE_MODEL_ID,
response_format={
"type": "json_object",
},
)
return response5.CosyVoice模型调用
通过对qwen返回值的循环处理,实现区分主持人和作者的文本,并通过调用generate_podcast_audio函数,实现语音生成。
for line in qwen_output.Dialogue:
logger.info(f"Generating audio for {line.speaker}: {line.text}")
if line.speaker == "Host (Jane)":
speaker = f"**Host**: {line.text}"
audio_file_path = generate_podcast_audio(line.text, SOUND_COLOR_MAPPING[hostsound])
else:
speaker = f"**{qwen_output.guests}**: {line.text}"
audio_file_path = generate_podcast_audio(line.text, SOUND_COLOR_MAPPING[guestsound])
transcript += speaker + "\n\n"
total_characters += len(line.text)
audio_segment = AudioSegment.from_file(audio_file_path)
audio_segments.append(audio_segment)generate_podcast_audio函数 封装了语音大模型CosyVoice的调用方法,区分不同角色的音色,返回音频存储路径。
import dashscope
from dashscope.audio.tts_v2 import *
dashscope.api_key = FIREWORKS_API_KEY
def generate_podcast_audio(text: str, sound: str) -> str:
synthesizer = SpeechSynthesizer(model=COSYVOICE_MODEL, voice=sound)
for attempt in range(COSYVOICE_RETRY_ATTEMPTS):
try:
audio = synthesizer.call(text)
full_path = create_temp_file(audio)
return full_path
except Exception as e:
if attempt == COSYVOICE_RETRY_ATTEMPTS - 1:
raise
time.sleep(COSYVOICE_RETRY_DELAY)6.语音数据整合
通过对音频数据的整合,实现对话语音的生成。
combined_audio = sum(audio_segments)
temporary_directory = GRADIO_CACHE_DIR
os.makedirs(temporary_directory, exist_ok=True)
temporary_file = NamedTemporaryFile(
dir=temporary_directory,
delete=False,
suffix=".mp3",
)
combined_audio.export(temporary_file.name, format="mp3")7.函数输出
通过generate_podcast函数的输出,对话音频的地址和输出文本,传递给输出组件,实现页面展示。
调用API参考文档
-
通义千问API:
https://help.aliyun.com/zh/model-studio/developer-reference/use-qwen-by-calling-api?spm=a2c4g.11186623.help-menu-2400256.d_3_3_0.54e11a84JrdCGu
-
语音合成CosyVoice大模型:
https://help.aliyun.com/zh/model-studio/developer-reference/cosyvoice-api-reference?spm=a2c4g.11186623.0.0.c7a56d5eb1Nijr
03最佳实践
注意:魔搭社区的demo从稳定性角度,使用了Qwen和Cosyvoice的API,需要配置AK环境变量(https://bailian.console.aliyun.com/?apiKey=1#/api-key)
export DASHSCOPE_API_KEY = "YOUR_API_KEY"
git clone https://www.modelscope.cn/studios/modelscope/open-notebooklm-demo.git
cd open-notebooklm-demo
pip install -r requirements.txt
python app.py
点击链接👇,即可跳转体验~
https://modelscope.cn/studios/modelscope/open-notebooklm-demo?from=csdnzishequ_text?from=csdnzishequ_text







 已为社区贡献609条内容
已为社区贡献609条内容

所有评论(0)